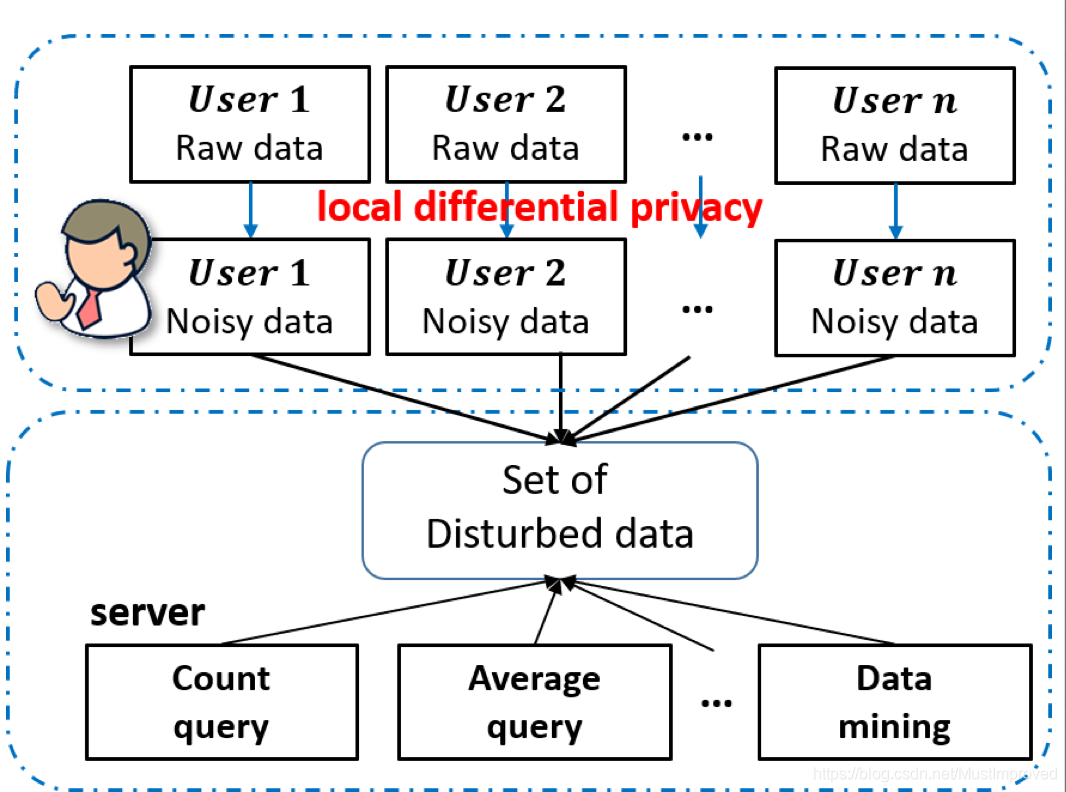
Local Differential Privacy(LDP)可以在收集用户的敏感数据时,保护用户的隐私信息。神奇的LDP,定义是任意两个输入
v
1
,
v
2
v_1,v_2
v 1 , v 2 输出同一个值
y
y
y 的概率的比值在
e
ε
e^\varepsilon
e ε 界里 :
如果一个算法
A
A
A
ε
\varepsilon
ε
ε
\varepsilon
ε
ε
≥
0
\varepsilon\geq0
ε ≥ 0
v
1
,
v
2
v_1,v_2
v 1 , v 2
∀
y
∈
R
a
n
g
e
(
A
)
:
P
r
[
A
(
v
1
)
=
y
]
≤
e
ε
P
r
[
A
(
v
2
)
=
y
]
,
\forall y\in Range(A): Pr[A(v_1)=y]\leq e^{\varepsilon}Pr[A(v_2)=y],
∀ y ∈ R a n g e ( A ) : P r [ A ( v 1 ) = y ] ≤ e ε P r [ A ( v 2 ) = y ] ,
R
a
n
g
e
(
A
)
Range(A)
R a n g e ( A )
A
A
A
LDP的基本应用是频度估计(即,从n个数据里,统计每个值的出现次数),它可以归结为下面的3个步骤:
Encode 即编码,由每个用户执行:
v
v
v
x
x
x
x
=
E
n
c
o
d
e
(
v
)
x=Encode(v)
x = E n c o d e ( v ) Perturb 即扰动,由每个用户执行:
x
x
x
y
y
y
y
=
P
e
r
t
u
r
b
(
x
)
=
P
e
r
t
u
r
b
(
E
n
c
o
d
e
(
v
)
)
y=Perturb(x)=Perturb(Encode(v))
y = P e r t u r b ( x ) = P e r t u r b ( E n c o d e ( v ) )
y
=
P
E
(
v
)
y=PE(v)
y = P E ( v ) Aggregate 即收集,由收集者(Aggregator)执行:
y
y
y 隐私保护程度
ε
\varepsilon
ε
频度估计(frequency estimation)的方差
V
a
r
(
c
~
(
i
)
)
Var(\tilde{c}(i))
V a r ( c ~ ( i ) )
规定输入
v
v
v
d
d
d
v
v
v
1
1
1
d
d
d
v
∈
[
1
,
d
]
,
v
∈
N
v\in[1, d],v\in N
v ∈ [ 1 , d ] , v ∈ N
Encoding: 将输入的整数转化成长度为
d
d
d
1
1
1
0
0
0
E
n
c
o
d
e
(
v
)
=
B
0
Encode(v)=B_0
E n c o d e ( v ) = B 0
B
0
B_0
B 0
d
d
d
B
0
[
v
]
=
1
,
B
0
[
i
]
=
0
,
i
≠
v
B_0[v]=1,B_0[i]=0, i\neq v
B 0 [ v ] = 1 , B 0 [ i ] = 0 , i = v
d
=
5
,
v
=
3
d=5, v=3
d = 5 , v = 3
B
0
=
00100
B_0=00100
B 0 = 0 0 1 0 0 Perturbing: (Rapper是有两次扰动的,此处简化仅考虑一次)01串
B
0
B_0
B 0
p
p
p
p
≥
1
2
p\geq \frac{1}{2}
p ≥ 2 1
q
=
1
−
p
q=1-p
q = 1 − p
B
1
B_1
B 1
P
r
[
B
1
[
i
]
=
1
]
=
{
p
,
i
f
B
0
[
i
]
=
1
,
q
=
1
−
p
,
i
f
B
0
[
i
]
=
0.
Pr[B_1[i]=1]=\left\{ \begin{array}{cr} p, &if B_0[i]=1, \\ q=1-p, &if B_0[i]=0. \end{array} \right.
P r [ B 1 [ i ] = 1 ] = { p , q = 1 − p , i f B 0 [ i ] = 1 , i f B 0 [ i ] = 0 . Aggregation: 收集者可以收集到所有用户(设有n个)扰动后的01串
B
1
B_1
B 1
i
i
i
1
1
1
c
(
i
)
c(i)
c ( i )
B
0
B_0
B 0
i
i
i
1
1
1
c
~
(
i
)
\tilde{c}(i)
c ~ ( i )
i
i
i
1
1
1
p
p
p
0
0
0
q
=
1
−
p
q=1-p
q = 1 − p
p
⋅
c
~
(
i
)
+
q
⋅
(
n
−
c
~
(
i
)
)
=
c
(
i
)
⇒
p
⋅
c
~
(
i
)
+
(
1
−
p
)
⋅
(
n
−
c
~
(
i
)
)
=
c
(
i
)
⇒
c
~
(
i
)
=
c
(
i
)
−
(
1
−
p
)
⋅
n
2
p
−
1
.
\begin{aligned} &\ p\cdot\tilde{c}(i)+q\cdot(n-\tilde{c}(i))=c(i) \\ \Rightarrow&\ p\cdot\tilde{c}(i)+(1-p)\cdot(n-\tilde{c}(i))=c(i) \\ \Rightarrow&\ \tilde{c}(i)=\frac{c(i)-(1-p)\cdot n}{2p-1}. \end{aligned}
⇒ ⇒ p ⋅ c ~ ( i ) + q ⋅ ( n − c ~ ( i ) ) = c ( i ) p ⋅ c ~ ( i ) + ( 1 − p ) ⋅ ( n − c ~ ( i ) ) = c ( i ) c ~ ( i ) = 2 p − 1 c ( i ) − ( 1 − p ) ⋅ n .
p
p
p
n
n
n
c
(
i
)
c(i)
c ( i )
c
~
(
i
)
\tilde{c}(i)
c ~ ( i )
Privacy: 要达到
ε
\varepsilon
ε
ε
=
ln
(
(
p
1
−
p
)
2
)
\varepsilon=\ln((\frac{p}{1-p})^2)
ε = ln ( ( 1 − p p ) 2 )
依然规定输入
v
v
v
d
d
d
Encoding: 正如其名,输入的整数编码成自身,即
E
n
c
o
d
e
(
v
)
=
v
Encode(v)=v
E n c o d e ( v ) = v Perturbing: 依然概率
p
p
p
v
v
v
v
v
v
q
=
1
−
p
d
−
1
q=\frac{1-p}{d-1}
q = d − 1 1 − p
d
−
1
d-1
d − 1
v
v
v
p
=
e
ε
q
p= e^{\varepsilon}q
p = e ε q
P
r
[
P
e
r
t
u
r
b
D
E
(
x
)
=
i
]
=
{
p
=
e
ε
e
ε
+
d
−
1
,
i
f
i
=
x
,
q
=
1
e
ε
+
d
−
1
,
i
f
i
≠
x
.
Pr[Perturb_{DE}(x)=i]=\left\{ \begin{array}{cr} p=\frac{e^{\varepsilon}}{e^{\varepsilon}+d-1}, &if i=x, \\ q=\frac{1}{e^{\varepsilon}+d-1}, &if i\neq x. \end{array} \right.
P r [ P e r t u r b D E ( x ) = i ] = { p = e ε + d − 1 e ε , q = e ε + d − 1 1 , i f i = x , i f i = x . Aggregation: 收集者可以收集到所有用户(设有n个)扰动后的值
v
′
v'
v ′
i
i
i
c
(
i
)
c(i)
c ( i )
i
i
i
c
~
(
i
)
\tilde{c}(i)
c ~ ( i )
i
i
i
p
p
p
i
i
i
q
=
1
−
p
d
−
1
q=\frac{1-p}{d-1}
q = d − 1 1 − p
p
⋅
c
~
(
i
)
+
q
⋅
(
n
−
c
~
(
i
)
)
=
c
(
i
)
⇒
c
~
(
i
)
=
c
(
i
)
−
q
⋅
n
p
−
q
⇒
c
~
(
i
)
=
c
(
i
)
⋅
(
e
ε
+
d
−
1
)
−
n
e
ε
−
1
,
\begin{aligned} &\ p\cdot\tilde{c}(i)+q\cdot(n-\tilde{c}(i))=c(i) \\ \Rightarrow &\ \tilde{c}(i)=\frac{c(i)-q\cdot n}{p-q} \\ \Rightarrow &\ \tilde{c}(i)=\frac{c(i)\cdot(e^{\varepsilon}+d-1)-n}{e^{\varepsilon}-1}, \end{aligned}
⇒ ⇒ p ⋅ c ~ ( i ) + q ⋅ ( n − c ~ ( i ) ) = c ( i ) c ~ ( i ) = p − q c ( i ) − q ⋅ n c ~ ( i ) = e ε − 1 c ( i ) ⋅ ( e ε + d − 1 ) − n ,
V
a
r
[
c
~
D
E
(
i
)
]
=
n
⋅
d
−
2
+
e
ε
(
e
ε
−
1
)
2
.
Var[\tilde{c}_{DE}(i)]=n\cdot \frac{d-2+e^{\varepsilon}}{(e^{\varepsilon}-1)^2}.
V a r [ c ~ D E ( i ) ] = n ⋅ ( e ε − 1 ) 2 d − 2 + e ε .
依然规定输入
v
v
v
d
d
d
Encoding: *将输入的整数转化成长度为
d
d
d
1.0
1.0
1 . 0
0.0
0.0
0 . 0
E
n
c
o
d
e
H
E
(
v
)
=
[
0.0
,
0.0
,
.
.
.
,
1.0
,
.
.
.
,
0.0
]
Encode_{HE}(v)=[0.0, 0.0, ..., 1.0, ..., 0.0]
E n c o d e H E ( v ) = [ 0 . 0 , 0 . 0 , . . . , 1 . 0 , . . . , 0 . 0 ] Perturbing:
P
e
r
t
u
r
b
H
E
(
B
)
Perturb_{HE}(B)
P e r t u r b H E ( B )
B
′
[
i
]
=
B
[
i
]
+
L
a
p
(
2
ε
)
B'[i]=B[i]+Lap(\frac{2}{\varepsilon})
B ′ [ i ] = B [ i ] + L a p ( ε 2 ) Aggregation: 有两类,分别为SHE, THE,如下:
Aggregate是求和,
c
~
(
i
)
=
∑
j
B
j
[
i
]
\tilde{c}(i)=\sum_{j}B^{j}[i]
c ~ ( i ) = ∑ j B j [ i ]
j
j
j
j
j
j
L
a
p
(
2
ϵ
)
Lap(\frac{2}{\epsilon})
L a p ( ϵ 2 )
0
0
0
V
a
r
[
c
~
S
H
E
(
i
)
]
=
n
8
ε
2
.
Var[\tilde{c}_{SHE}(i)]=n\frac{8}{\varepsilon^2}.
V a r [ c ~ S H E ( i ) ] = n ε 2 8 .
Aggregate是设定阈值
θ
\theta
θ
θ
\theta
θ
1
1
1
θ
\theta
θ
0
0
0
B
[
v
]
B[v]
B [ v ]
1.0
1.0
1 . 0
θ
\theta
θ
B
[
i
]
B[i]
B [ i ]
0.0
0.0
0 . 0
θ
\theta
θ
p
=
1
−
F
(
θ
−
1
)
,
q
=
1
−
F
(
θ
)
,
p=1-F(\theta-1),q=1-F(\theta),
p = 1 − F ( θ − 1 ) , q = 1 − F ( θ ) ,
F
(
x
)
F(x)
F ( x )
θ
∈
[
0
,
1
]
\theta\in[0,1]
θ ∈ [ 0 , 1 ]
p
=
1
−
1
2
e
ε
2
(
θ
−
1
)
,
q
=
1
−
1
2
e
−
ε
2
θ
,
p=1-\frac{1}{2}e^{\frac{\varepsilon}{2}(\theta-1)},q=1-\frac{1}{2}e^{-\frac{\varepsilon}{2}\theta},
p = 1 − 2 1 e 2 ε ( θ − 1 ) , q = 1 − 2 1 e − 2 ε θ ,
V
a
r
[
c
~
T
H
E
(
i
)
]
=
n
2
e
ε
θ
/
2
−
1
(
1
+
e
ε
(
θ
−
1
/
2
)
−
2
e
ϵ
θ
/
2
)
2
.
Var[\tilde{c}_{THE}(i)]=n\frac{2e^{\varepsilon\theta/2}-1}{(1+e^{\varepsilon(\theta-1/2)-2e^{\epsilon\theta/2}})^2}.
V a r [ c ~ T H E ( i ) ] = n ( 1 + e ε ( θ − 1 / 2 ) − 2 e ϵ θ / 2 ) 2 2 e ε θ / 2 − 1 .
在
θ
∈
(
1
2
,
1
)
\theta\in(\frac{1}{2},1)
θ ∈ ( 2 1 , 1 )
B
′
[
i
]
B'[i]
B ′ [ i ]
B
′
[
i
]
B'[i]
B ′ [ i ]
0
,
1
0,1
0 , 1
V
a
r
[
c
~
T
H
E
(
i
)
]
<
V
a
r
[
c
~
S
H
E
(
i
)
]
Var[\tilde{c}_{THE}(i)]<Var[\tilde{c}_{SHE}(i)]
V a r [ c ~ T H E ( i ) ] < V a r [ c ~ S H E ( i ) ]
和Basic RAPPOR简化版非常相似,Encoding相同,Perturbing(扰动)的时候,概率
p
p
p
q
q
q
p
>
q
p>q
p > q
p
+
q
p+q
p + q
1
1
1
ε
\varepsilon
ε
v
1
,
v
2
v_1,v_2
v 1 , v 2
v
1
v1
v 1
v
2
v2
v 2
ε
=
l
n
(
p
(
1
−
q
)
(
1
−
p
)
q
)
\varepsilon=ln(\frac{p(1-q)}{(1-p)q})
ε = l n ( ( 1 − p ) q p ( 1 − q ) )
Encoding: 将输入的整数转化成长度为
d
d
d
1
1
1
0
0
0
E
n
c
o
d
e
(
v
)
=
[
0
,
.
.
.
,
0
,
1
,
0
,
.
.
.
,
0
]
Encode(v)=[0,...,0,1,0,...,0]
E n c o d e ( v ) = [ 0 , . . . , 0 , 1 , 0 , . . . , 0 ] Perturbing: 01串
B
0
B_0
B 0
p
p
p
q
q
q
p
+
q
≠
1
p+q\neq 1
p + q = 1
B
1
B_1
B 1
P
r
[
B
1
[
i
]
=
1
]
=
{
p
,
i
f
B
0
[
i
]
=
1
,
q
,
i
f
B
0
[
i
]
=
0.
Pr[B_1[i]=1]=\left\{ \begin{array}{cr} p, &if B_0[i]=1, \\ q, &if B_0[i]=0. \end{array} \right.
P r [ B 1 [ i ] = 1 ] = { p , q , i f B 0 [ i ] = 1 , i f B 0 [ i ] = 0 . Aggregation: 略。
方差为:
V
a
r
[
c
~
U
E
(
i
)
]
=
n
⋅
(
(
e
ε
−
1
)
q
+
1
)
2
(
e
ε
−
1
)
2
(
1
−
q
)
q
.
Var[\tilde{c}_{UE}(i)]=n\cdot\frac{((e^{\varepsilon}-1)q+1)^2}{(e^{\varepsilon}-1)^2(1-q)q}.
V a r [ c ~ U E ( i ) ] = n ⋅ ( e ε − 1 ) 2 ( 1 − q ) q ( ( e ε − 1 ) q + 1 ) 2 .
取
p
+
q
=
1
p+q=1
p + q = 1
p
=
e
ε
/
2
e
ε
/
2
+
1
,
q
=
1
e
ε
/
2
+
1
,
p=\frac{e^{\varepsilon/2}}{e^{\varepsilon/2}+1},q=\frac{1}{e^{\varepsilon/2}+1},
p = e ε / 2 + 1 e ε / 2 , q = e ε / 2 + 1 1 ,
V
a
r
[
c
~
S
U
E
(
i
)
]
=
n
⋅
e
ε
/
2
(
e
ε
/
2
−
1
)
2
.
Var[\tilde{c}_{SUE}(i)]=n\cdot\frac{e^{\varepsilon/2}}{(e^{\varepsilon/2}-1)^2}.
V a r [ c ~ S U E ( i ) ] = n ⋅ ( e ε / 2 − 1 ) 2 e ε / 2 .
由UE的方差,对
q
q
q
0
0
0
p
=
1
2
,
q
=
1
e
ε
/
2
+
1
,
p=\frac{1}{2},q=\frac{1}{e^{\varepsilon/2}+1},
p = 2 1 , q = e ε / 2 + 1 1 ,
p
,
q
p,q
p , q
p
p
p
1
1
1
q
q
q
d
−
1
d-1
d − 1
0
0
0
0
0
0
V
a
r
[
c
~
O
U
E
(
i
)
]
=
n
⋅
4
e
ε
(
e
ε
−
1
)
2
.
Var[\tilde{c}_{OUE}(i)]=n\cdot\frac{4e^{\varepsilon}}{(e^{\varepsilon}-1)^2}.
V a r [ c ~ O U E ( i ) ] = n ⋅ ( e ε − 1 ) 2 4 e ε .
需要先了解一下universal hashing,可以参考我写的博客 。其他参考资料有Sarah Adel Bargal的介绍,用数学的角度来介绍,非常简洁也很清楚;另外wikipedia的universal hashing,用历史的角度来介绍。
universal hashing的基本思想:一个hash函数
y
=
h
(
x
)
y=h(x)
y = h ( x )
x
1
,
x
2
x_1,x_2
x 1 , x 2
1
g
\frac{1}{g}
g 1
g
g
g
如果我们选择值域
g
=
2
g=2
g = 2
0
,
1
0,1
0 , 1
Encoding: 随机均匀地从
H
\mathbb{H}
H
H
H
H
v
v
v
E
n
c
o
d
e
B
L
H
(
v
)
=
<
H
,
b
=
H
(
v
)
>
Encode_{BLH}(v)=<H,b=H(v)>
E n c o d e B L H ( v ) = < H , b = H ( v ) > Perturbing: 仅对结果
b
b
b
P
e
r
t
u
r
b
B
L
H
(
<
H
,
b
>
)
=
<
H
,
b
′
>
Perturb_{BLH}(<H,b>)=<H,b'>
P e r t u r b B L H ( < H , b > ) = < H , b ′ >
P
r
[
b
′
]
=
{
p
=
e
ε
e
ε
+
1
,
i
f
b
=
1
,
q
=
1
e
ε
+
1
,
i
f
b
=
0.
Pr[b']=\left\{ \begin{array}{cr} p=\frac{e^{\varepsilon}}{e^{\varepsilon}+1}, &if\ b=1, \\ q=\frac{1}{e^{\varepsilon}+1}, &if\ b=0. \end{array} \right.
P r [ b ′ ] = { p = e ε + 1 e ε , q = e ε + 1 1 , i f b = 1 , i f b = 0 . Aggregation: 结合Encoding和Perturbing,可得
p
∗
=
p
,
q
∗
=
1
2
,
p*=p,q*=\frac{1}{2},
p ∗ = p , q ∗ = 2 1 ,
V
a
r
[
c
~
B
L
H
(
i
)
]
=
n
⋅
(
e
ε
+
1
)
2
(
e
ε
−
1
)
2
.
Var[\tilde{c}_{BLH}(i)]=n\cdot\frac{(e^{\varepsilon}+1)^2}{(e^{\varepsilon}-1)^2}.
V a r [ c ~ B L H ( i ) ] = n ⋅ ( e ε − 1 ) 2 ( e ε + 1 ) 2 .
考虑到值域
g
=
2
g=2
g = 2
g
≥
2
g\geq 2
g ≥ 2
g
g
g
g
g
g
Encoding: 随机均匀地从
H
\mathbb{H}
H
H
H
H
v
v
v
E
n
c
o
d
e
B
L
H
(
v
)
=
<
H
,
x
=
H
(
v
)
>
Encode_{BLH}(v)=<H,x=H(v)>
E n c o d e B L H ( v ) = < H , x = H ( v ) > Perturbing: 仅对结果
b
b
b
P
e
r
t
u
r
b
B
L
H
(
<
H
,
x
>
)
=
<
H
,
y
>
Perturb_{BLH}(<H,x>)=<H,y>
P e r t u r b B L H ( < H , x > ) = < H , y >
∀
i
∈
[
g
]
P
r
[
y
=
i
]
=
{
p
=
e
ε
e
ε
+
g
−
1
,
i
f
x
=
i
,
q
=
1
e
ε
+
g
−
1
,
i
f
x
≠
i
.
_{\forall i\in[g]}Pr[y=i]=\left\{ \begin{array}{cr} p=\frac{e^{\varepsilon}}{e^{\varepsilon}+g-1}, &if\ x=i, \\ q=\frac{1}{e^{\varepsilon}+g-1}, &if\ x\neq i. \end{array} \right.
∀ i ∈ [ g ] P r [ y = i ] = { p = e ε + g − 1 e ε , q = e ε + g − 1 1 , i f x = i , i f x = i . Aggregation: 结合Encoding和Perturbing,可得
p
∗
=
p
,
q
∗
=
1
g
p
+
g
−
1
g
q
=
1
g
,
p*=p,q*=\frac{1}{g}p+\frac{g-1}{g}q=\frac{1}{g},
p ∗ = p , q ∗ = g 1 p + g g − 1 q = g 1 ,
V
a
r
[
c
~
L
P
(
i
)
]
=
n
⋅
(
e
ε
+
g
−
1
)
2
(
e
ε
−
1
)
2
(
g
−
1
)
,
Var[\tilde{c}_{LP}(i)]=n\cdot\frac{(e^{\varepsilon}+g-1)^2}{(e^{\varepsilon}-1)^2(g-1)},
V a r [ c ~ L P ( i ) ] = n ⋅ ( e ε − 1 ) 2 ( g − 1 ) ( e ε + g − 1 ) 2 ,
g
g
g
0
0
0
g
=
e
ε
+
1
g=e^{\varepsilon}+1
g = e ε + 1
p
∗
=
e
ε
e
ε
+
g
−
1
=
1
2
,
q
∗
=
1
g
=
1
e
ε
+
1
p*=\frac{e^{\varepsilon}}{e^{\varepsilon}+g-1}=\frac{1}{2},q*=\frac{1}{g}=\frac{1}{e^{\varepsilon}+1}
p ∗ = e ε + g − 1 e ε = 2 1 , q ∗ = g 1 = e ε + 1 1
V
a
r
[
c
~
O
L
H
(
i
)
]
=
n
⋅
4
e
ε
(
e
ε
−
1
)
2
,
Var[\tilde{c}_{OLH}(i)]=n\cdot\frac{4e^{\varepsilon}}{(e^{\varepsilon}-1)^2},
V a r [ c ~ O L H ( i ) ] = n ⋅ ( e ε − 1 ) 2 4 e ε ,
写这篇时,部分参考。第一次写论文相关的,内容比较多、杂,如果大家有什么不懂的,可以随时私信哦。