1 摘要
- 综述了近年来差分隐私与公平交叉领域的成果
- 分析了差分隐私在决策问题和学习任务中可能加剧不公平性的原因
- 在差分隐私系统中缓解不公平性的措施
- 在公平的条件下部署隐私模型面临的挑战
2 介绍
大型数据集和计算资源的可用性推动了人工智能的重大进展。
这些进展使得人工智能成为涉及个人的许多决策和政策操作的辅助工具:包括法律决策、贷款、招聘、福利分配等。
然而,机器学习模型是个黑盒。所以人们会担忧,这个系统是否公平?是否会泄露参与者的个人信息?
2.1 差分隐私
差分隐私是一种隐私保护技术,近年来逐渐成为隐私部署的首选技术。
它可以把参与计算的个人泄露敏感信息的风险限制在一定范围内。
然而,已有研究表明差分隐私会加剧不同群体间的不公平性。「对一个群体造成的影响大于另一个群体」
2.2 过去的观点
差分隐私会加剧不同群体间的不公平性,人们普遍认为不公平的出现与以下两个原因有关:
- 差分隐私包括后处理过程,后处理会引入偏差,减小误差
- 差分隐私对不同群体造成不成比例的影响是因为数据集本身就是不均衡的
3 公平
在这篇综述中,主要涉及两种公平:个体公平和群体公平。
这里主要参见 [The U.S. Census Bureau Adopts Differential Privacy](The U.S. Census Bureau Adopts Differential Privacy | Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining)
3.1 个体公平
定义:相似的个体应该被相似的对待。
对于一个将输入 x ∈ X x\in X x∈X 映射到 y ∈ Y y \in Y y∈Y的映射机制 M M M。对于任何输入 x , x ’ ∈ X x,x’ \in X x,x’∈X ,个体公平满足
d y ( M ( x ) , M ( x ′ ) ) < = d x ( x , x ′ ) (1) d_y(M(x),M(x'))<=d_x(x,x') \tag{1} dy(M(x),M(x′))<=dx(x,x′)(1)
其中 d x , d y d_x,d_y dx,dy 分别是两个个体 x , x ′ x,x' x,x′ 输入输出上的距离。
当公式(1)成立时,机制 M M M 为满足 d x , d y d_x,d_y dx,dy 的利普希兹条件。
个体公平的一个明显缺陷就是,对于特定问题的距离度量的要求,并不容易设计。
3.2 群体公平
定义:群体公平要求任何受保护的个人群体的某些统计性质与整个群体的统计性质相似。
两种经典的群体公平性规则有人口平价和机会均等。
4 设置
本综述主要聚焦于差分隐私在决策任务和学习任务中产生的不公平。
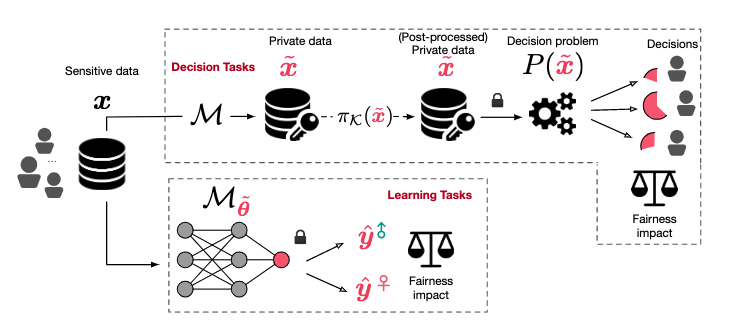
4.1 决策任务
机制 M M M 将输入 x x x 映射成隐私保护后的输入 x ~ \widetilde{x} x 。「这里可以理解为扰动数据集」
设决策任务为 P : X → Y ⊆ R P:X\rightarrow Y \subseteq \mathbb{R} P:X→Y⊆R。例如, P P P 可以表示为分配给不同学区的资金。
机制 M M M 可能会采用后处理 π K \pi_{\mathcal{K}} πK,来保证发布数据的非负性。
设个体为 i i i ,产生的偏差为 B B B,有
B P i ( M , x ) = E x ~ ∼ M ( x ) [ P i ( x ~ ) ] − P i ( x ) (2) B_{P}^i(M,x)=\mathbb{E}_{\widetilde{x}\sim M(x)}[P_i(\widetilde{x})]-P_i(x) \tag2 BPi(M,x)=Ex
∼M(x)[Pi(x
)]−Pi(x)(2)
这里的偏差表明了隐私保护决策的期望与基于真实数据得出的决策之间的距离。
4.2 学习任务
设分类器为 M M M,权重为 θ \theta θ,差分隐私扰动后的权重更为 θ ~ \widetilde{\theta} θ 。
输入由 ( x , a , y ) (x,a,y) (x,a,y)构成,其中 x x x 表示特征向量, a a a 表示保护属性, y y y 是标签。
损失函数为 L ( θ ; x ) \mathcal{L}(\theta;x) L(θ;x),隐私风险为 R ( θ ; x a ) R(\theta;x_a) R(θ;xa)。
隐私风险可表示为
R ( θ ; x a ) = E θ ~ [ L ( θ ~ , x a ) ] − L ( θ ∗ ; x a ) (3) R(\theta;x_a) =\mathbb{E}_{\widetilde{\theta}}[\mathcal{L}(\widetilde{\theta},x_a)]-\mathcal{L}(\theta ^*;x_a) \tag3 R(θ;xa)=Eθ
[L(θ
,xa)]−L(θ∗;xa)(3)
θ ∗ \theta ^* θ∗ 表示函数收敛时的最优权重, x a x_a xa 表示 x x x 中敏感属性为 a a a 的子集。
5 隐私和公平:是朋友还是敌人
目前有两种观点:一种观点认为公平和隐私相辅相成,另一种观点认为公平和隐私是对立的。
5.1 朋友
Dwork 认为个体公平是差分隐私的推广。—— Fairness through awareness
Mahdi 等发现在候选人选择问题中,但数据满足关于每个组的关键属性的一些限制时(资格分数的平均值、方差等),使用指数机制会产生公平的选择。——Improving Fairness and Privacy in Selection Problems
5.2 敌人
Bagdasaryan 等人发现差分隐私分类器的输出可能产生或加剧群体中个体之间的不公平性。——The U.S. Census Bureau Adopts Differential Privacy
Pujol 等人在人口普查数据集中发现了类似的现象。——Fair decision making using privacy-protected data | Proceedings of the 2020 Conference on Fairness, Accountability, and Transparency (acm.org)
6 为什么隐私会影响公平
6.1 决策任务
对于一个数据发布机制 M M M,通常包括以下两个步骤:
-
将噪声注入到数据集 x x x 中,将扰动后的数据集校准得到 发布数据 x ~ \widetilde{x} x 。某些属性是恒正的,扰动后变成了负数,需要对属性进行校准
-
将发布数据 x ~ \widetilde{x} x 作为决策问题 P P P 的输入。
P ( x ~ ) P(\widetilde{x}) P(x ) 在不同群体间造成的影响不同。
Zhu 等人认为差分隐私在决策任务中造成不公平,主要可以归咎于两个原因:
- 决策问题 P P P 的"形状"
- 后处理步骤中非负约束的存在
—— Post-processing of Differentially Private Data: A Fairness Perspective (arxiv.org)
6.1.1 决策问题的形状
Tran 等人发现,在线性变换的决策问题中使用无偏噪声(Laplace等)校准隐私数据后,得到的结果相较于真实结果是无偏见的。但是当决策问题使用的是非线性模型,就会出现公平问题。—— Differentially Private Empirical Risk Minimization under the Fairness Lens (neurips.cc)
6.1.2 后处理产生的影响
虽然后处理可以减少误差,但是这一过程也会引入偏见和公平问题。—— Post-processing of Differentially Private Data: A Fairness Perspective (arxiv.org) 和 Observations on the Bias of Nonnegative Mechanisms for Differential Privacy (arxiv.org)
越复制的后处理, 会带来越严重的方差和偏差差异。
6.2 学习任务
因为分类器 M M M 对于相邻数据集 X X X 和 X ′ X' X′ 无法做到完全公平,Cummeling 等人认为,在隐私模型中不可能实现纯公平。On the Compatibility of Privacy and Fairness | Adjunct Publication of the 27th Conference on User Modeling, Adaptation and Personalization (acm.org)
Bagdasaryan 等人发现 DPSGD 会对不同群体造成不成比例的影响,他们推测受保护群体的规模将在加剧隐私训练中的不公平性方面发挥关键作用。—— The U.S. Census Bureau Adopts Differential Privacy
Farrand 等人认为受保护群体的规模并不是导致不公平的关键因素,因为在样本数量轻微不平衡的数据集中,也会存在严重的公平问题。他们认为导致不公平的是训练数据的属性和模型的特征。
—— Differentially Private Empirical Risk Minimization under the Fairness Lens (neurips.cc) 和 A Fairness Analysis on Private Aggregation of Teacher Ensembles (arxiv.org)
6.2.1 训练数据的特征
输入范数和到达决策边界的距离是数据的两个关键特征,与加剧隐私模型的不公平性相关。
输入范数:具有较大输入范数的组可能具有较大的 Hessian losses。
到决策边界的距离: 样本到模型边界的距离与 hessian 值有关。接近(远离)决策边界的样本对差分隐私算法引起扰动的容忍度较低(高)
6.2.2 模型的特征
xu 等人发现,DPSGD 会加剧不同群体间的不公平性。DPSGD 需要对梯度进行裁剪,当个体产生的梯度大小超过裁剪边界 C 时,梯度裁剪会在这些群体中产生不同程度的损失,从而惩罚梯度较大的群体。—— Removing Disparate Impact on Model Accuracy in Differentially Private Stochastic Gradient Descent | Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining
Tran 等人发现,Hessian 损失较大的群体受到的不公平影响往往更大。 —— Differentially Private Empirical Risk Minimization under the Fairness Lens (neurips.cc)
7 缓解隐私模型中的不公平
7.1 决策任务
在向学区分配资金的背景下,Pujol 等人提出了一种机制,将额外的预算分配给目标群体,以便所有实体以很高的概率至少获得非隐私分配所需的资金。——Fair decision making using privacy-protected data | Proceedings of the 2020 Conference on Fairness, Accountability, and Transparency (acm.org)
Tran 等人提出了一种近似于原始任务但允许有界公平性的代理问题。—— Decision Making with Differential Privacy under a Fairness Lens (arxiv.org)
Zhu 等人提出了缓解后处理带来的不公平性的解决方案。作者提出了一种近似最优的投影算子,该算子在满足分配问题的可行性要求的同时,对不同公平度量下的不公平性提供了实质性影响。—— Post-processing of Differentially Private Data: A Fairness Perspective (arxiv.org)
7.2 学习任务
Xu 等 和 Ding 等在 Logistic 回归上应用函数机制同时实现了公平和 ( ϵ , δ ) − D P (\epsilon,\delta)-DP (ϵ,δ)−DP。—— Achieving Differential Privacy and Fairness in Logistic Regression | Companion Proceedings of The 2019 World Wide Web Conference (acm.org) 和 Differentially Private and Fair Classification via Calibrated Functional Mechanism | Proceedings of the AAAI Conference on Artificial Intelligence
Xu 等人将不同的裁剪边界与每个受保护群体相关联,以限制梯度裁剪对梯度较大组产生的影响。—— Removing Disparate Impact on Model Accuracy in Differentially Private Stochastic Gradient Descent | Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining
Zhang 等人指出,训练迭代的轮数是平衡效用、隐私和公平的关键因素。—— Balancing Learning Model Privacy, Fairness, and Accuracy With Early Stopping Criteria | IEEE Journals & Magazine | IEEE Xplore
上述方法用于保护数据集中的每一条数据。
是否有必要专门保护群体属性(例如性别或种族的问题)由 Jagielski 等人提出。—— Differentially Private Fair Learning (mlr.press)
在这种更宽松的隐私设置下,Hardt 等人提出了后处理方法的 DP 版本,它对不同的群体使用不同的决定阈值,以消除 DP 对不同群体造成的不成比例的影响。 —— Equality of Opportunity in Supervised Learning (neurips.cc)
Agarwal 等人增强了损失函数,加大了对违反公平行为的惩罚。——A Reductions Approach to Fair Classification (mlr.press)
以上两种方法引入了较大的隐私预算。为了解决这个痛点,Mozannar等人采用随机相应来保护敏感群体的标签。——Fair Learning with Private Demographic Data (mlr.press)
在联邦学习领域,也存在一些方法同时实现公平和隐私。
Abay 等人提出了几种前处理和处理中偏差缓解的解决方案,以在不影响数据隐私的情况下提高公平性。—— Mitigating Bias in Federated Learning (arxiv.org)
Padala 等人建议每个客户分两个阶段进行训练。用户首先训练一个非隐私模型,该模型在保证公平的前提下尽可能有较高的精度。
随后,使用 DPSGD 训练一个隐私模型来模仿第一个模型。将隐私模型获得的更新在每次迭代时广播到中央服务器。
8 挑战和研究方向
8.1 挑战
(1)没有一个同一的理论框架来描述一般决策任务中出现的公平问题并分析其原因。
(2)公平性还会受到关键超参数的影响。如批次大小,学习率,神经网络的深度。
8.2 研究方向
(1)隐私和公平会与模型鲁棒性有联系,但目前缺乏对这一联系的理解。
(2)生成隐私合成数据集的算法和生成模型可能出现不成比例的影响,应该如何消除这些影响?