概要
引入新的网络概念——OdeNet,常微分方程,连续的深度神经网络。
1. 介绍
残差模块 
假设当我们添加更多的层,会发生什么?
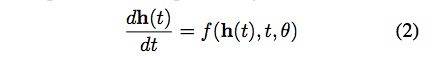
不储存任何前向传播的参数。在第2节,我们展示了如何依靠ODE输入计算标量值损失的梯度。
Euler 方法是解决Ode最简单的方法
当隐藏单元参数化为时间的连续函数时,附近“层”的参数自动地绑定在一起。 在第3节中,我们展示了这一点这减少了监督学习任务所需的参数数量。
使连续变量变得容易计算。在第4节中,我们推导出这个结果并用它构建了一类新的可逆密度模型,避免了单个单元规范化流量的瓶颈,可以通过最大可能性直接训练。
与循环神经网络的离散观察和时间间隔不同的是,ODE可以引用任何时间的数据。
在第5节证明了我们的模型。
2. Reverse-mode automatic differentiation of ODE solutions
主要技术难点是反向传播,前向传播虽然容易,但也引入了高的存储成本和额外的数值误差
在与 ResNet 的类比中,我们基本上已经了解了 ODEnet 的前向传播过程。首先输入数据 Z(t_0),我们可以通过一个连续的转换函数(神经网络)对输入进行非线性变换,从而得到 f。随后 ODE Solver 对 f 进行积分,再加上初值就可以得到最后的推断结果。如下所示,残差网络只不过是用一个离散的残差连接代替 ODE Solver。

若我们的损失函数为 L(),且它的输入为 ODE Solver 的输出:

梯度计算方法 ,绕过ODE Solver
,绕过ODE Solver


我们的目的是利用 ODESolver 从 z(t_1) 求出 z(t_0)、从 a(t_1) 按照方程 4 积出 a(t_0)、从 0 按照方程 5 积出 dL/dθ。最后我们只需要使用 dL/dθ 更新神经网络 f(z(t), t, θ) 就完成了整个反向传播过程。