在学习爬虫之前,翻过知乎上的一个回答:利用爬虫技术能做到哪些很酷很有趣很有用的事情?,这大概是我学习爬虫最初的动力。现在也想开始做这样的事情,结合数据分析或是其他的,做一些有趣的东西。
第一个项目是爬取豆瓣华语电影,后面将对这部分数据进行分析。
1. 爬取思路
在观察了豆瓣每个影片的链接地址后,写下了主要思路:
(1)在豆瓣电影的选片页面,筛选所有华语(即中国大陆、香港、台湾)的影片,并获取其id;
(2)通过id构建并爬取该影片链接,获得其导演、主演、类型、片长、评分等信息。
2. 爬取分析
那这个思路能否实现呢?我们可以打开chrome,打开豆瓣影视筛选的页面,筛选电影、中国大陆。首先查看网页源代码,可以发现这个页面是JavaScript实现的动态页面。如果直接用requests等库来抓取原页面,是无法获得数据的。那接着分析网页后台向接口发送的请求,看是否有Ajax请求。键盘快捷键f12调出开发者工具,选择Network,重新刷新页面,在Fillter输入框下面的筛选中选择XHR,筛选出Ajax请求。可以发现有个new_search_subject开头的请求,点击Preview的选项,发现这就是页面上显示的影片信息。双击该请求,查看具体的数据。
可以看到页面数据是JSON格式,且没有加密,适合通过模拟Ajax请求来获取数据。下面分析该请求的参数:
https://movie.douban.com/j/new_search_subjects?sort=U&range=0,10&tags=电影&start=0&countries=中国大陆

sort是排序方式,range是评分数范围,tags、countries是筛选的参数,而start是控制页面的参数。每个页面有20部电影,每部电影有标题、id等信息。页数从0开始,每隔20整体变化一次。不过看不到最大的页数,只能先尝试大的数字,看最多能到多少页。大致看下,中国大陆、香港目前最大是9960,台湾是6500。
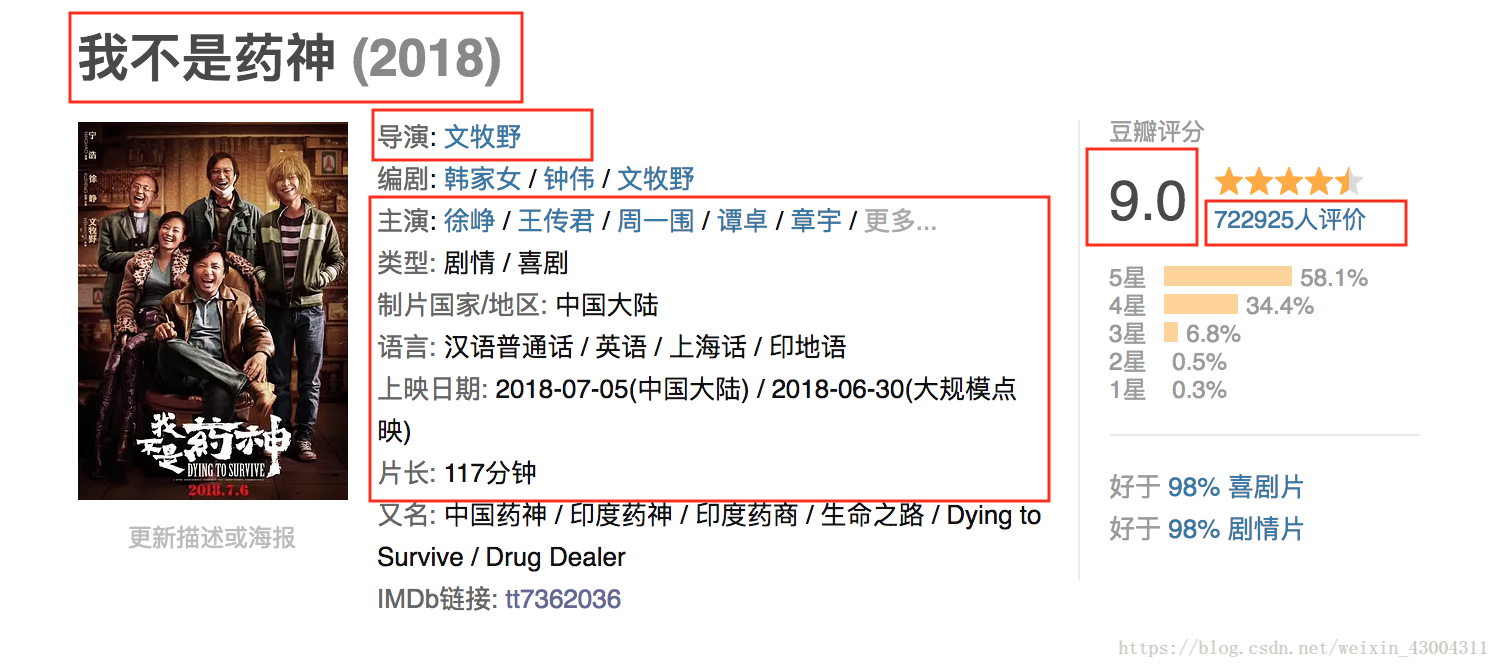
获取id解决了,接着来看单个页面,比如https://movie.douban.com/subject/26752088/。
页面中方框圈出的信息,是我爬取的信息。在Elements观察了多个页面后,可以发现除了制片国家/地区和语言这两项需要用正则解析外,其他都可以用xpath解析。最后将这些信息存入数据库即可。
3. 实现过程
使用scrapy框架爬取和MongoDB数据库存储数据。
3.1 准备工作
确保已经安装Redis和MongoDB数据库并启动服务,另外python中还需要安装aiohttp、requests、pyquery、Flask、pymongo、Scrapy等库。
3.2 具体实现
3.2.1 页面解析
使用scrapy自带的数据提取方法,即Selector,对页面进行解析。Selector是基于lxml来构建的,支持XPath选择器、CSS选择器以及正则表达式,解析速度和准确度都非常高。电影详细页面信息解析中,用到XPath选择器和正则表达式。
3.2.2 数据存储
使用redis数据库存储proxy数据,MongoDB数据库存储电影数据。
3.2.3 反反爬虫策略
为了防止被ban,设置了以下方法:
(1) 随机User Agent (middleware.py中的RandomUserAgentMiddleware)
(2) 使用代理池,随机IP(ProxyPool,middleware.py中的ProxyMiddleware)
(3) 禁用cookie(settings.py中,COOKIES_ENABLED = False)
3.2.4 提高速度
(1)使用付费代理
网上有很多免费代理,但ip质量很低,大部分都不可用。为了提高proxy可用率,避免冗余,只使用付费代理。先通过代理池对ip进行初步筛选,剔除不可用代理。然后用WEB API的形式暴露可用代理,在爬取过程中,通过访问接口获取一个随机可用代理。
(2)settings.py设置
- 因为已经有随机UA和随机IP的防ban措施,因此可以将下载延迟设置为0:DOWNLOAD_DELAY = 0
- scrapy网络请求是基于Twisted,Twisted默认支持多线程,而且scrapy默认也是通过多线程请求的,并且支持多核CPU的并发,通过一些设置提高scrapy的并发数:
CONCURRENT_REQUESTS = 100
CONCURRENT_REQUESTS_PER_DOMAIN = 100
CONCURRENT_REQUESTS_PER_IP = 100 - 设置下载超时时间:DOWNLOAD_TIMEOUT=30
3.2.5 具体代码
具体代码放在我的github上:douban-spider
4. 爬取结果
总共爬取电影33133部,存在Mongo的数据格式如下:
{
"_id" : ObjectId("5bb96351fd21815bdbe90124"),
"id" : "24719063",
"title" : "烈日灼心",
"year" : "2015",
"region" : [ "中国大陆"],
"language" : [ "汉语普通话"],
"director" : [ "曹保平"],
"type" : [ "剧情", "悬疑", "犯罪"],
"actor" : [ "邓超", "段奕宏", "郭涛", "王珞丹", "吕颂贤", "高虎", "白柳汐", "杜志国"],
"date" : [ "2015-08-27(中国大陆)", "2015-06-15(上海电影节)"],
"runtime" : [ "139分钟"],
"rate" : "7.9",
"rating_num" : "290209"
}
5. 后记
接下来会对刚刚爬取这33133部电影数据进行清洗并分析。完成后会把文章链接附上。
关于代码,如果各位看了之后,有错误或者可以改进的地方,一定要告诉我!!!
6. reference
- 《Python3网络爬虫开发实战》
本文同步发布在我的github.io