A Self-Training Approach for Short Text Clustering
这是一篇关于短文本聚类的文章。
“因为随着社交媒体的广泛使用,短文本已经成为web上流行的文本形态。然而与长文本不同,使用词袋模型和TF-IDF表示的短文本存在着稀疏的问题。”
短文本的稀疏问题
假设有短文本数据集X={x1,x2…xn}。
对于xi∈X,假设xi中的词汇数为ni,那么数据集X的词汇数量V为
如果用词袋模型表示 xi ,记为 xi ,xi ∈ ,那么xi 的“稀疏率”可以表示为 ,通常ni << V 。所以短文本使用词袋模型表示是非常稀疏的,换言之,向量xi 中有很多维度上的值为0。
如果使用TF-IDF来表示xi ,对于wj ∈ xi , j = 1、2、…ni,我们计算
因为对于xi中任意的wj出现的次数一般为1,所以他们的TF值难以区分。所以计算出的TF-IDF值不能准确的反映wj的特征。
“过去解决短文本稀疏问题的方法是引入额外的资源丰富文本的表示。最近,低维度的表示展示了解决短文本稀疏向量的潜能。Word embedding、sentence embedding以及documents embedding已经在众多NLP任务中有了良好的表现。”
SIF Embedding
论文使用了SIF Embedding,SIF来自《A Simple but Tough-to-Beat Baseline for Sentence Embeddings》。
SIF的计算分为两步:
1、对句子中的每个词向量,乘以一个权重 a/(a+p(w)),其中 a 是一个超参数,p(w) 为该词的词频(在整个数据集中的频率)。
2、计算句向量矩阵的第一个主成分 u,让每个句向量减去它在 u 上的投影。

“我们的短文本聚类模型包含三步:1、使用SIF得到短文本向量;2、使用一个autoencoder重构短文本向量;3、(Self-training)将聚类作为辅助的目标分布,联合微调encoder。”

Self-training
使用autoencoder将SIF embedding的结果降维后作为self-training的初始化。然后初始化聚类中心(文章在实验阶段使用100次Kmeans初始化不同的中心,然后选择最好的中心)。然后交替以下两个步骤:
1、计算一个向量(文本)放入每个簇的概率
2、计算辅助的概率分布,作为encoder的目标
步骤1:向量zi放入uj簇的概率符合自由度为1的学生T分布。
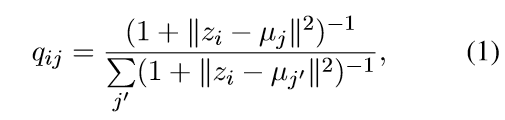
步骤2:辅助目标分布P相较于相似度qij是有更严格的概率计算。目的是提高簇的纯度、提高置信度。这阻止了大簇扭曲隐藏的特征空间。
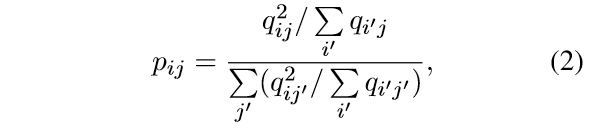
训练的loss:
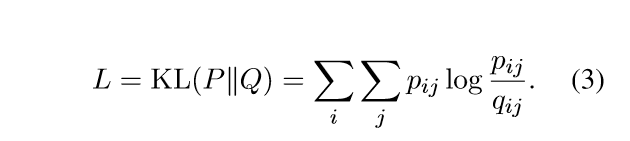
实验结果

我的总结
之所以这个self-training取得了较好的效果,是因为它将聚类的目标函数作为了encoder的辅助目标融进了训练当中。这意味着聚类任务和embedding、降维过程不是割裂的。
在以往的聚类研究当中,研究者都遵循着下图的结构:
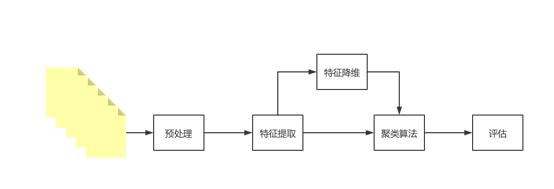
这意味着聚类任务的提升只能依靠预处理技术、特征提取、特征降维技术的提升。这也就是作者写道的:“最近,低维度的表示展示了解决短文本稀疏向量的潜能。Word embedding、sentence embedding以及documents embedding已经在众多NLP任务中有了良好的表现。”
但是本文将聚类的目标和encoder的训练目标相融合,就意味着聚类算法与特征提取不是割裂的两个任务,可以通过聚类算法影响encoder的效果,从而使其成为更符合聚类任务的encoder。
参考文献
Amir Hadifar , Lucas Sterckx , Thomas Demeester and Chris Develder . 2019 . A Self-Training Approach for Short Text Clustering.
