介绍
自注意力机制在序列模型中取得了很大的进步,另一方面,上下文信息对于很多视觉任务都很关键,如语义分割、目标检测。自注意力机制通过(key、query、value)的三元组提供了一种有效的捕捉全局上下文信息的建模方式。
attention通常可以进行如下描述,表示为将query(Q)和key-value pairs映射到输出上,其中query、每个key、每个value都是向量,输出是V中所有values的加权,其中权重是由Query和每个key计算出来的。计算方法分为三步:
- 计算比较Q和K的相似度,用f表示;
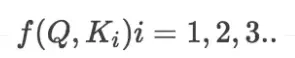
- 将得到的相似度进行softmax归一化:
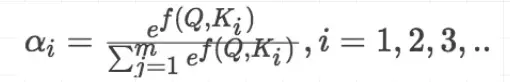
- 针对计算出来的权重,对所有的values进行加权求和,得到Attention向量:
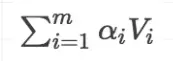
计算相似度的方法有一下4中:

query、k、v的意义
以翻译为例:
source:我 是 中国人
target: I am Chinese
比如翻译目标单词为 I 的时候,Q为I
而source中的 “我” “是” “中国人”都是K,
那么Q就要与每一个source中的K进行对齐(相似度计算);"I"与"我"的相似度,"I"与"是"的相似度;"I"与"中国人"的相似度;
相似度的值进行归一化后会生成对齐概率值(“I"与source中每个单词的相似度(和为1)),也可以注意力值;
而V代表每个source中输出的context vector;如果为RNN模型的话就是对应的状态向量;即key与value相同;
然后相应的V与相应的P进行加权求和,就得到了context vetor;
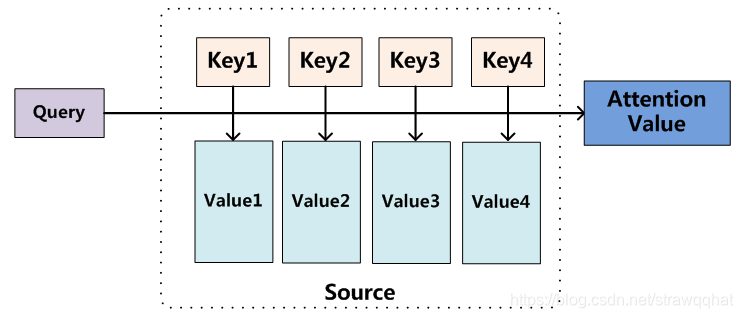
可以这样进一步解释注意力机制:将source中的构成元素想象成是由一系列的数据对构成,此时给定target中的某个元素query,通过计算query和各个key的相似性或者相关性,得到每个key对应value的权重系数,然后对value进行加权求和,即得到了最终的attention数值。所以本质上attention机制是对source中元素的value值进行加权求和,而query和key用来计算对应value的权重系数。
