目录标题
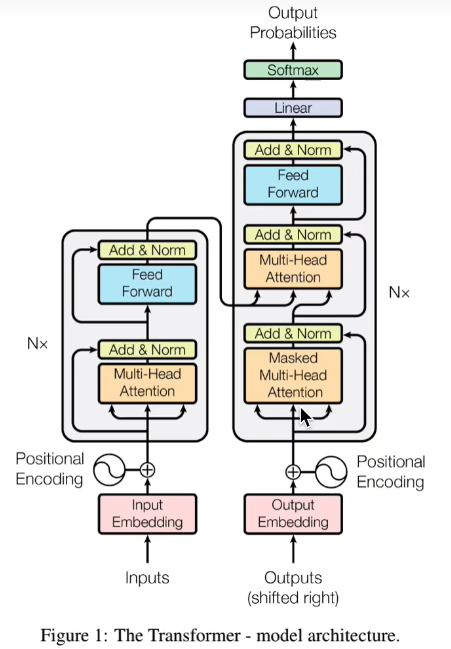
一、self-attention
attention就是权重的意思,从S到编码向量C的矩阵权重!
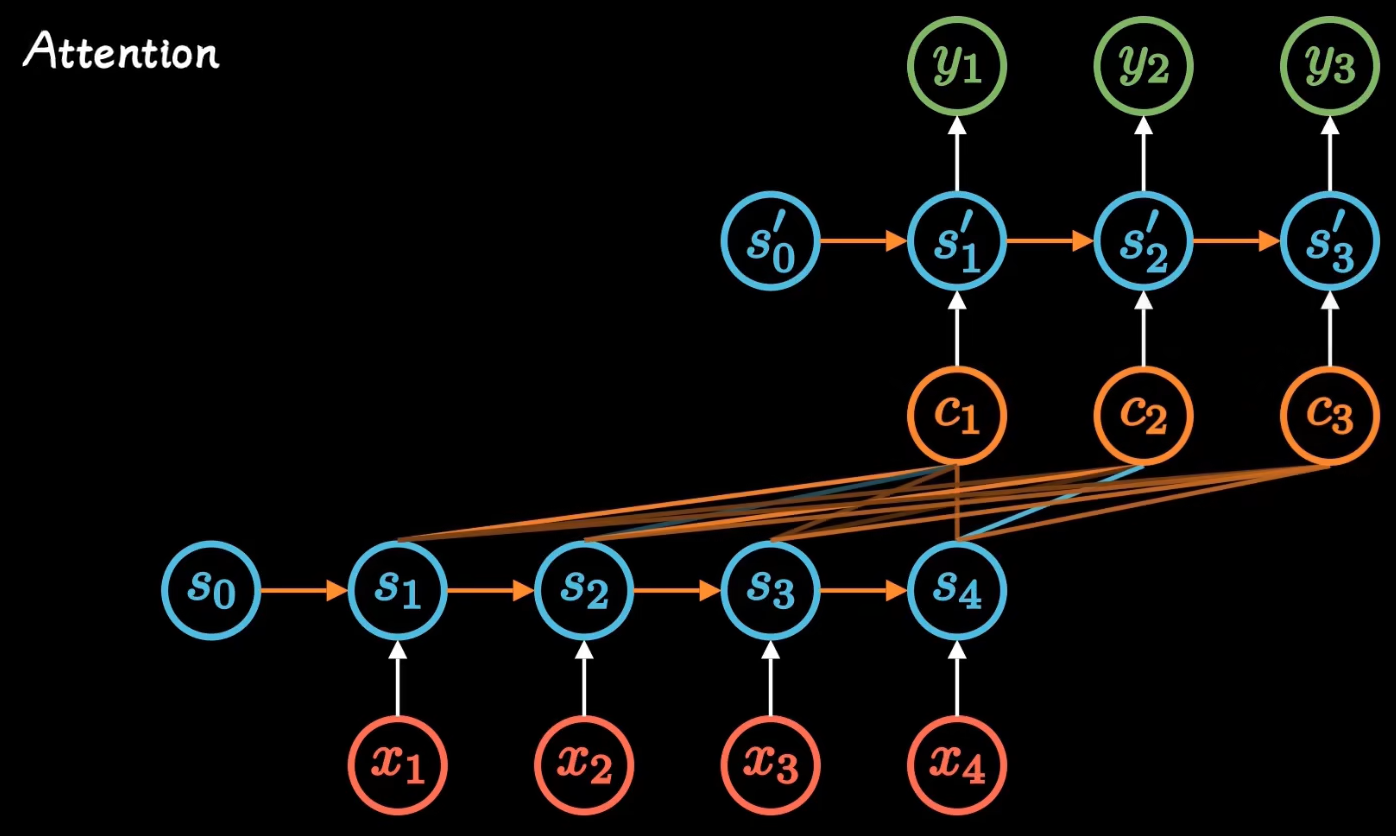
再继续简化:

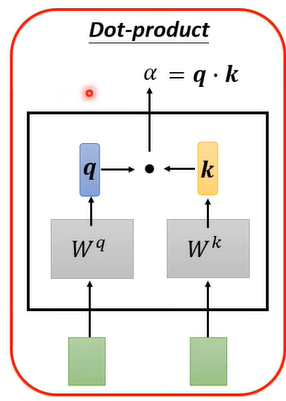
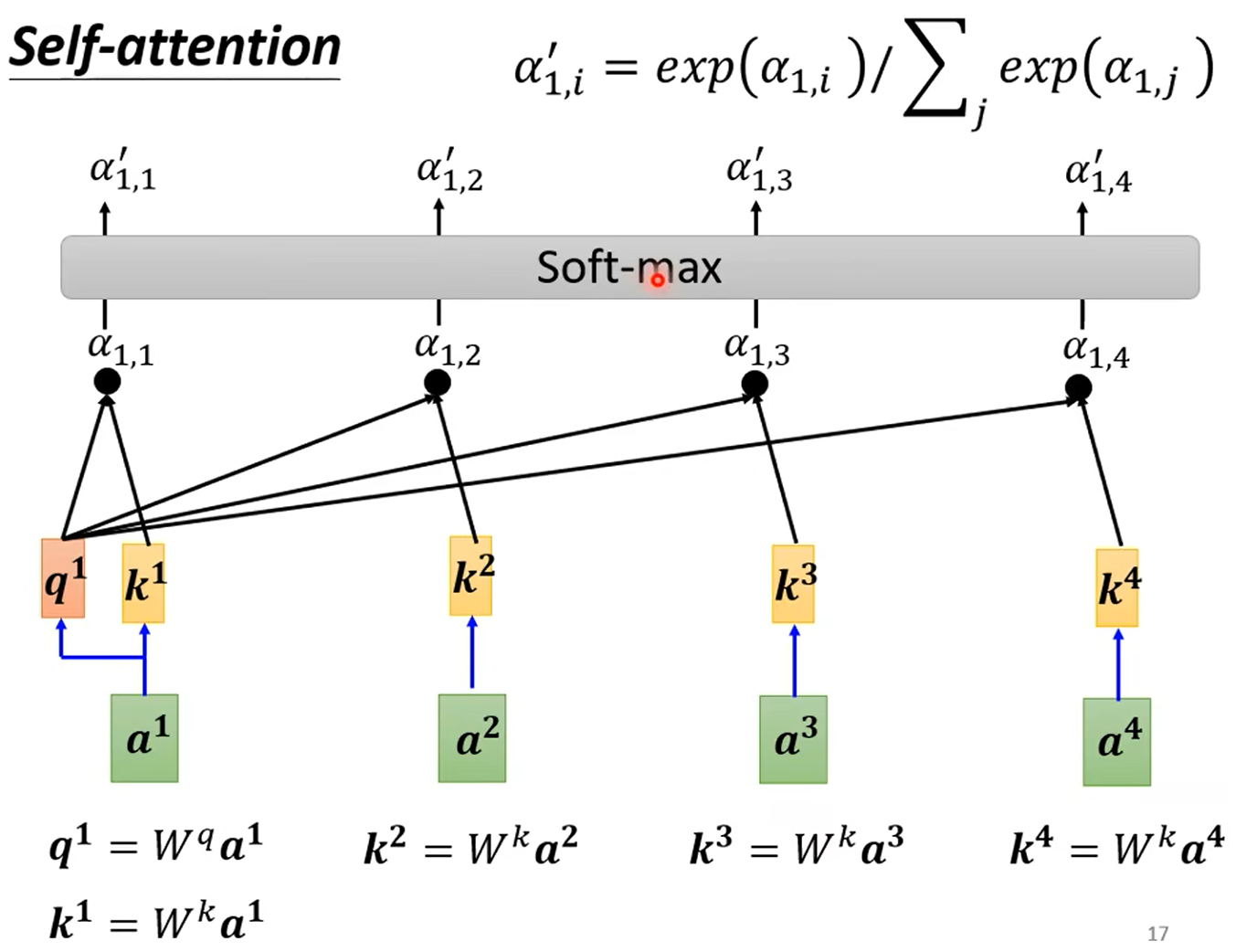
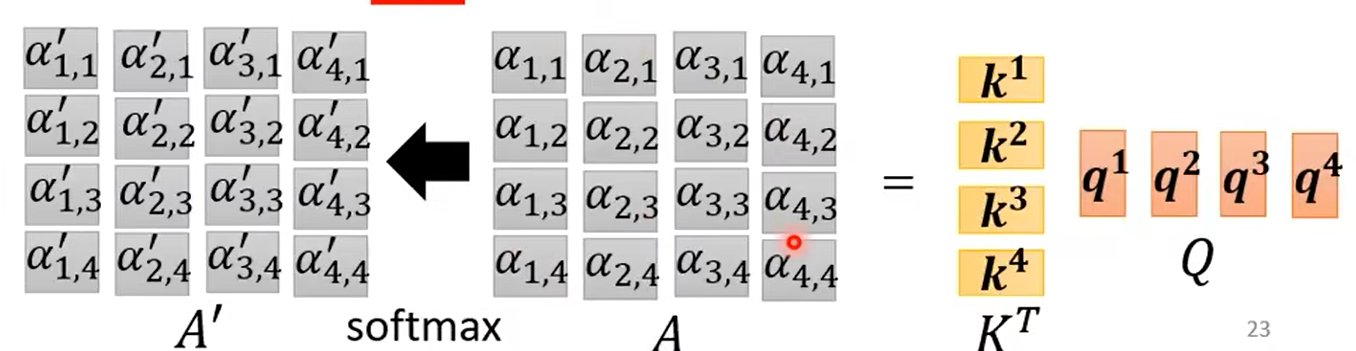
计算attention score,然后通过Soft-max层归一化(其他激活函数也行);
下一步是进一步从attention score提取信息,得到考虑了所有上下文的向量:
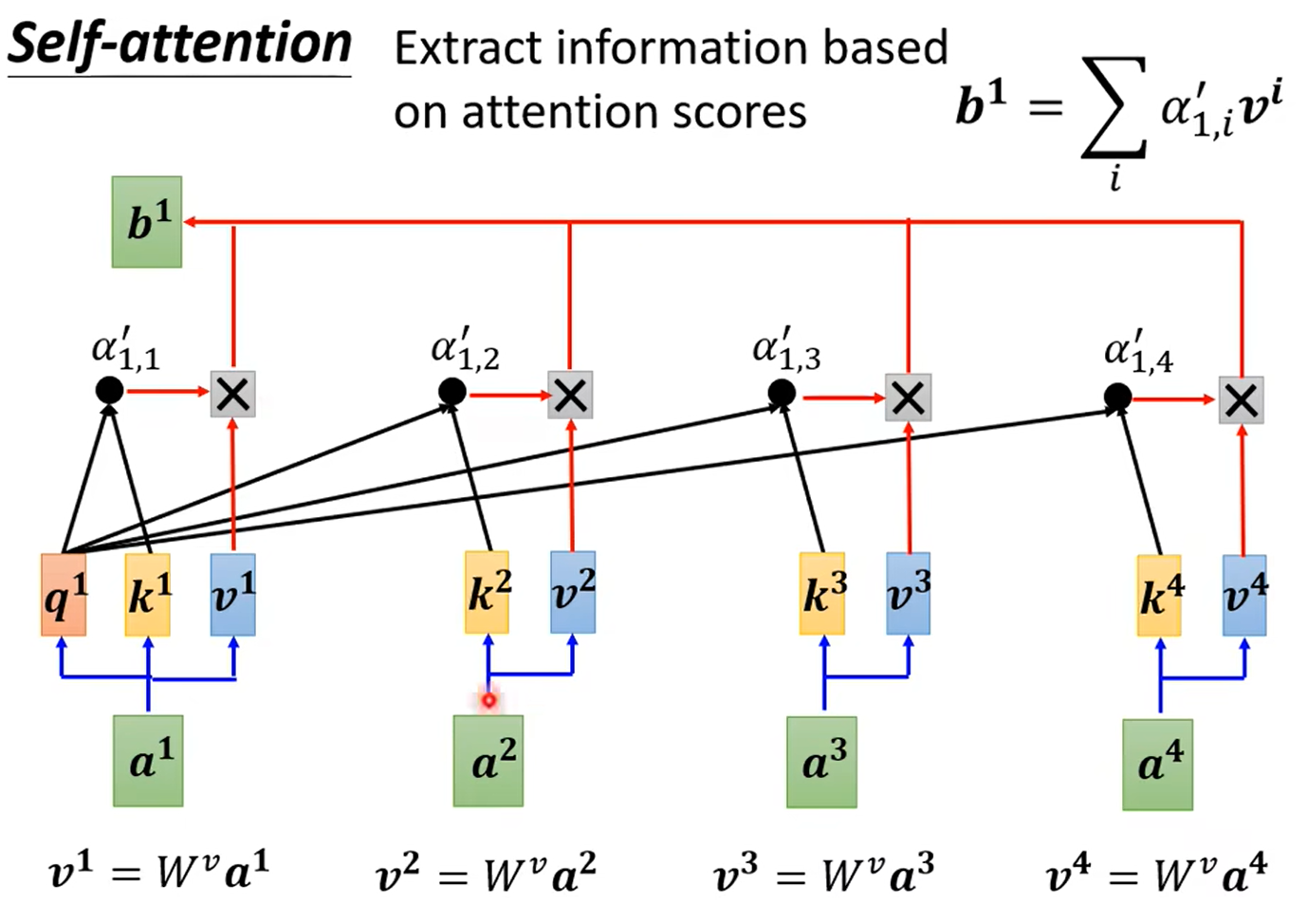
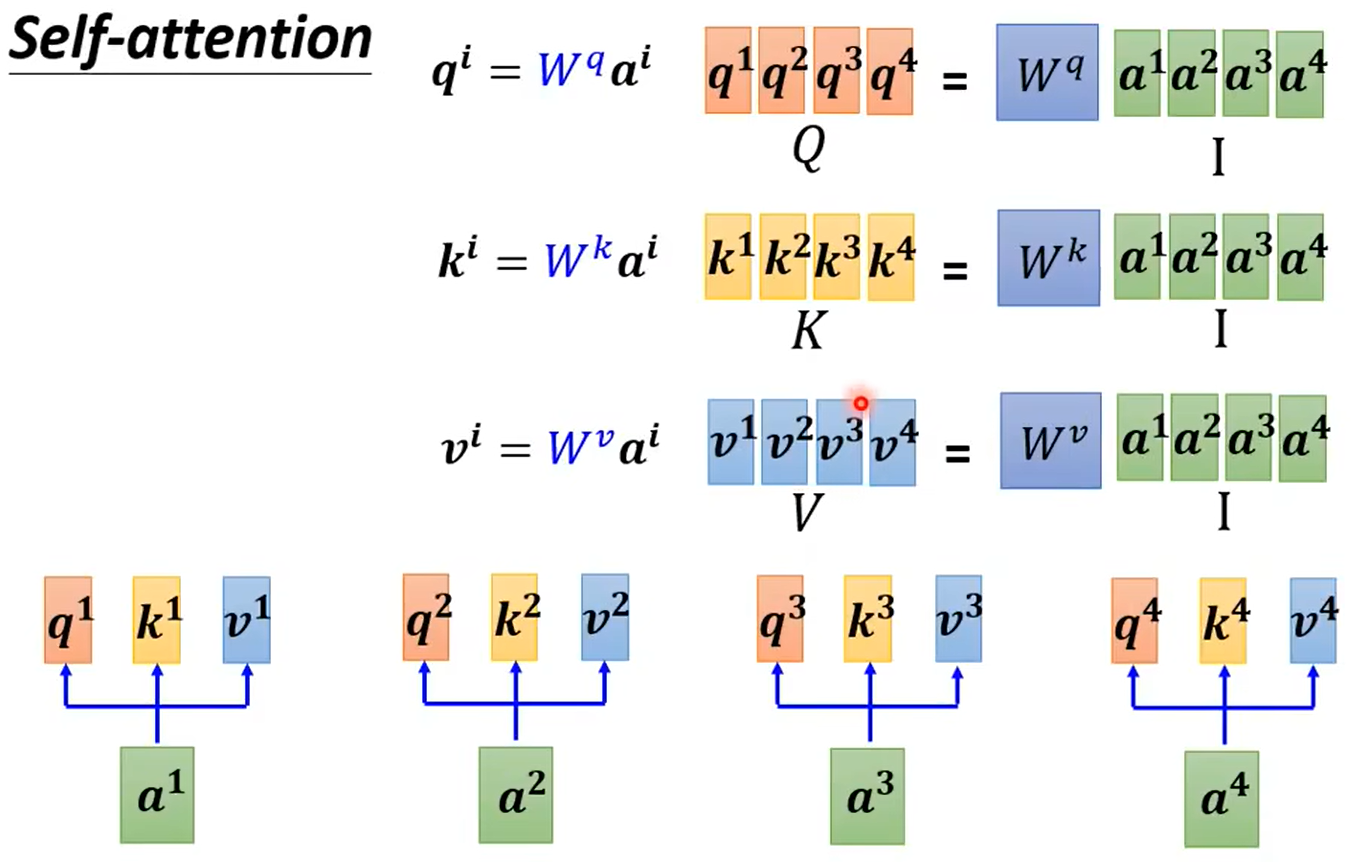
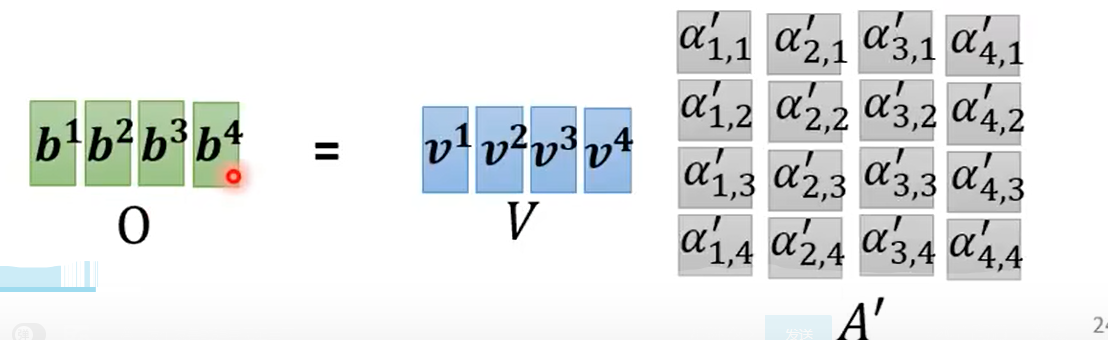
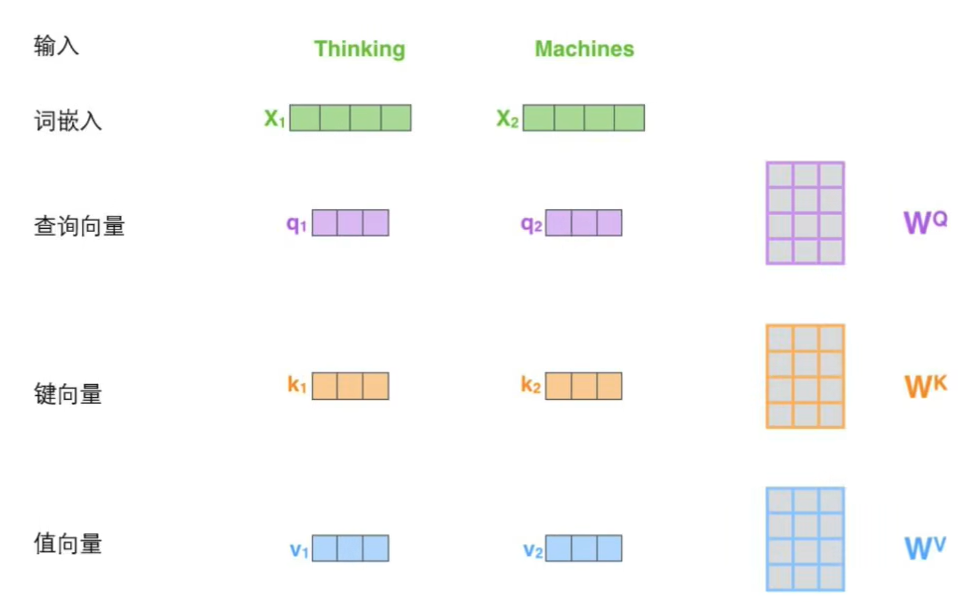
再来看看矩阵运算的过程:
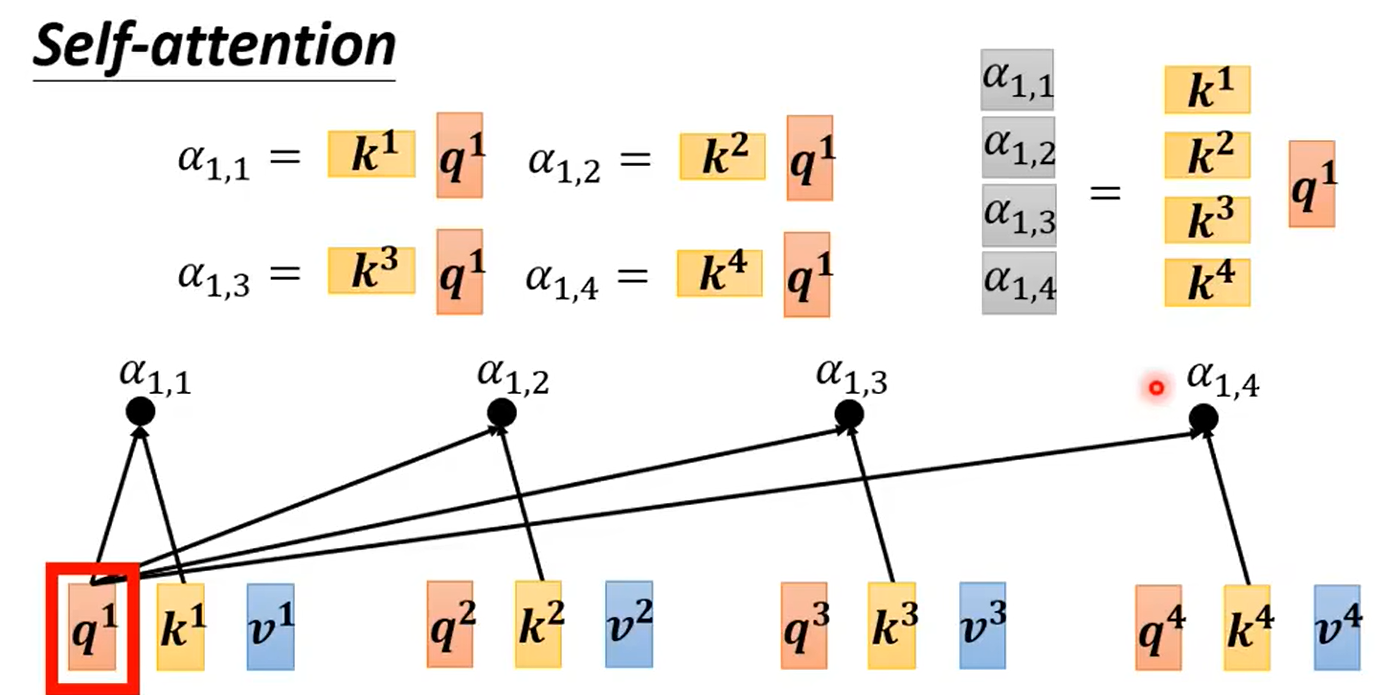
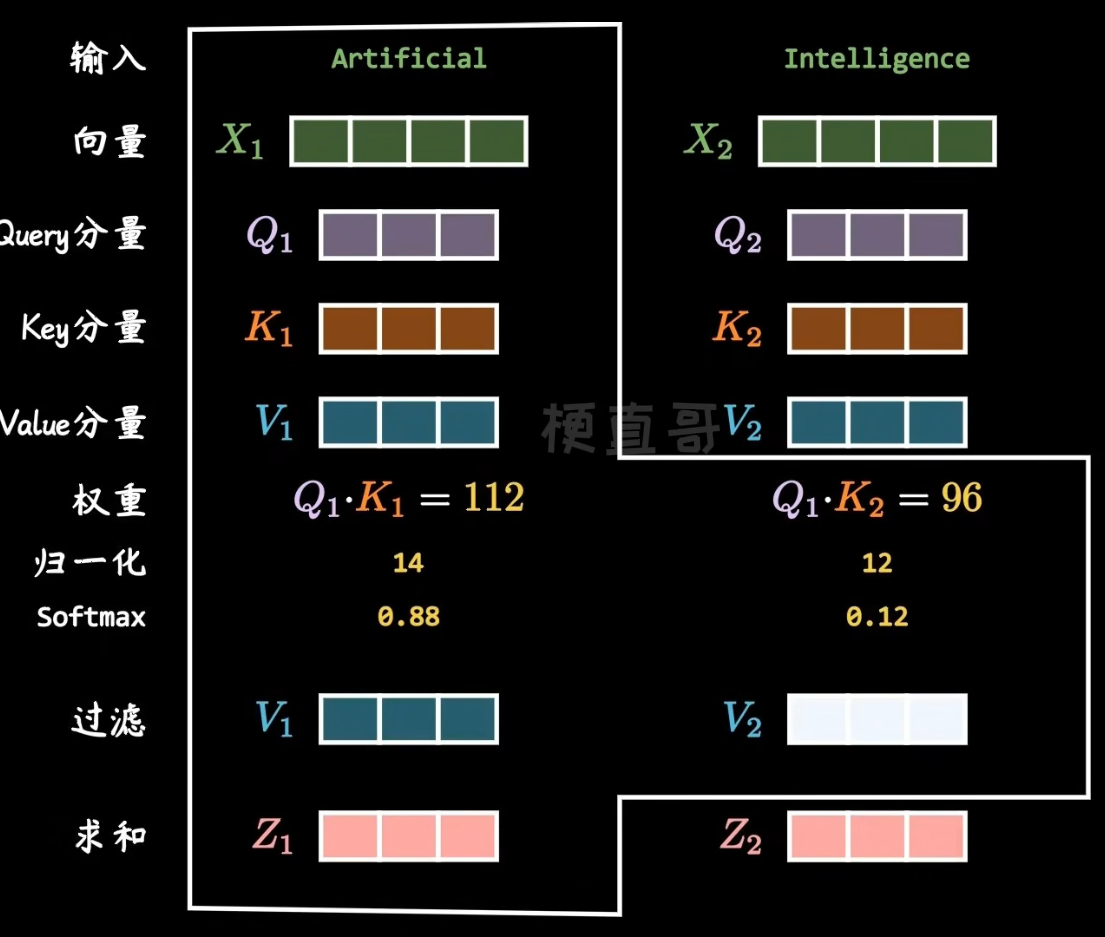
计算attention score的过程:
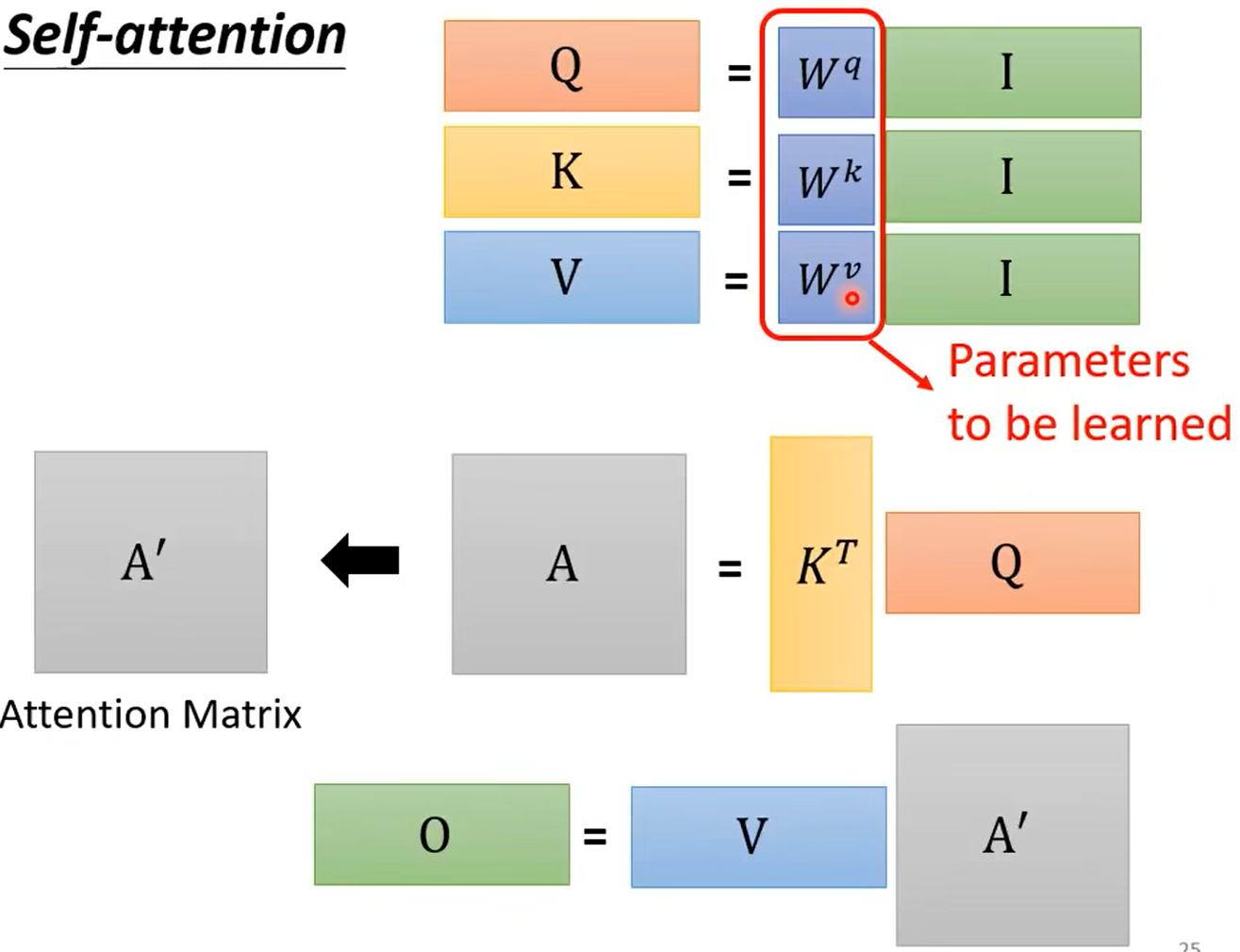
总结:只有矩阵qkv需要从学习训练得到
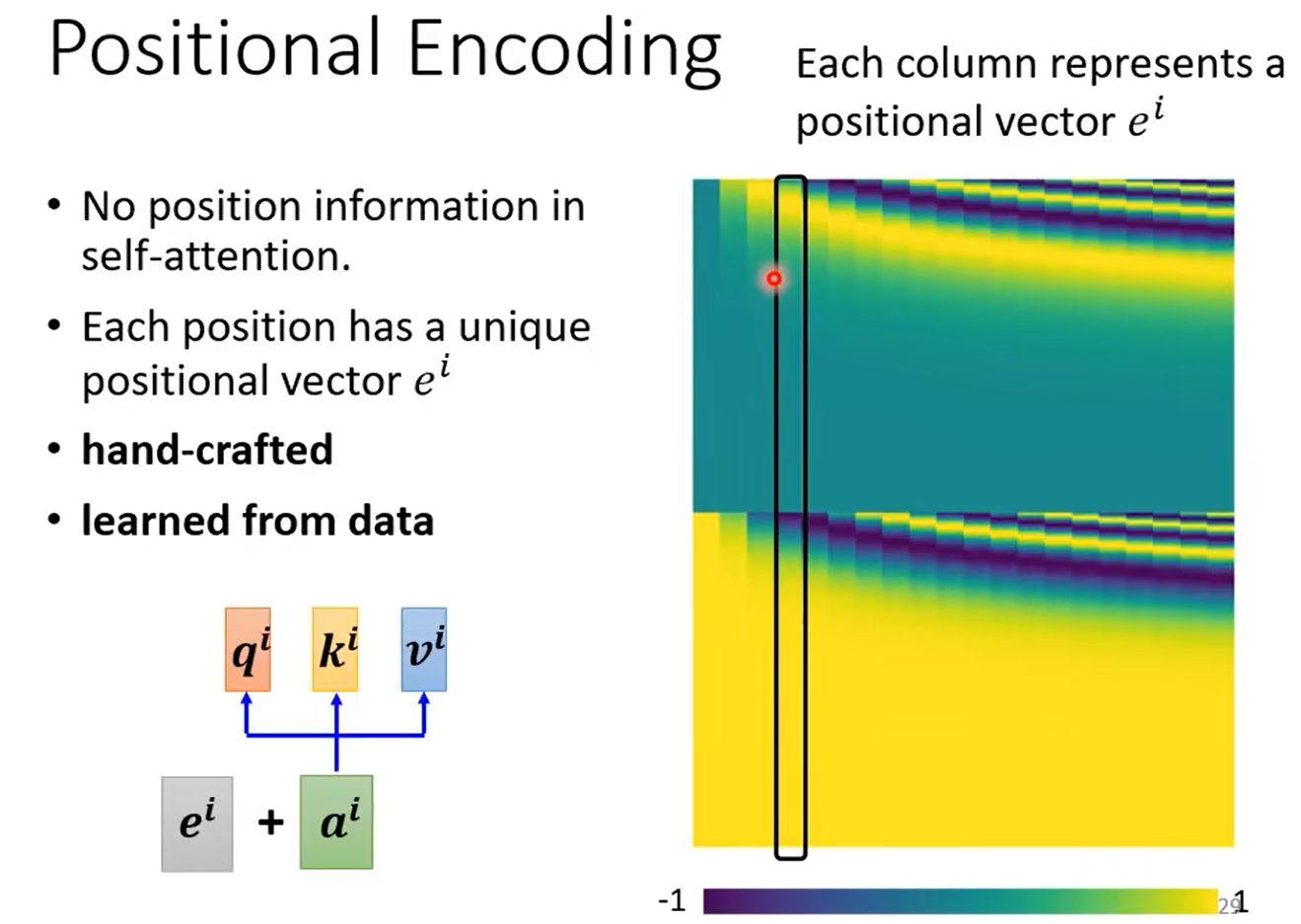
2、Positional Encoding
上面得到的向量并没有考虑到单词位置的信息(比如动词一般在中间)。因此引入一个新的向量 e i e^i ei
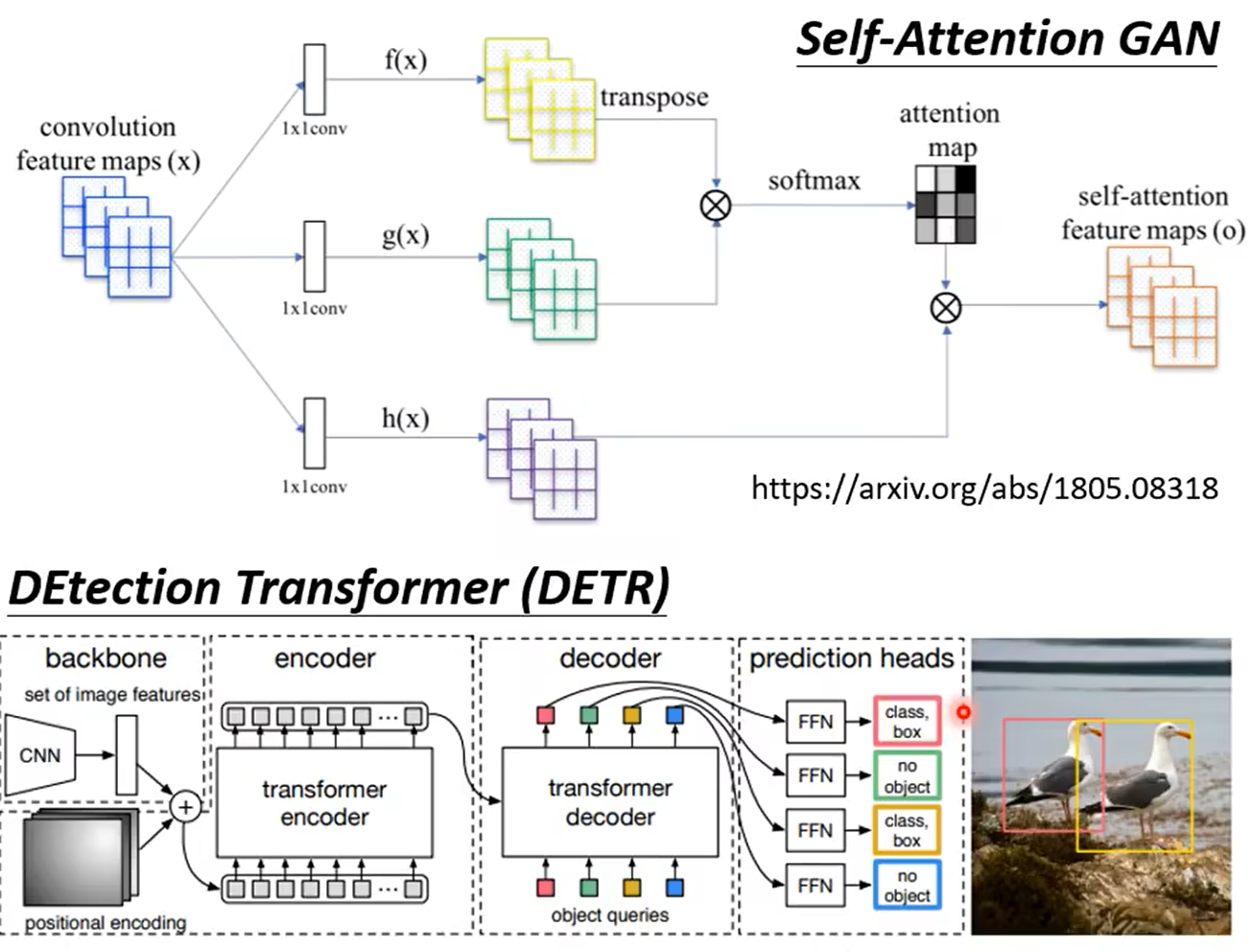
3、self attention和CNN
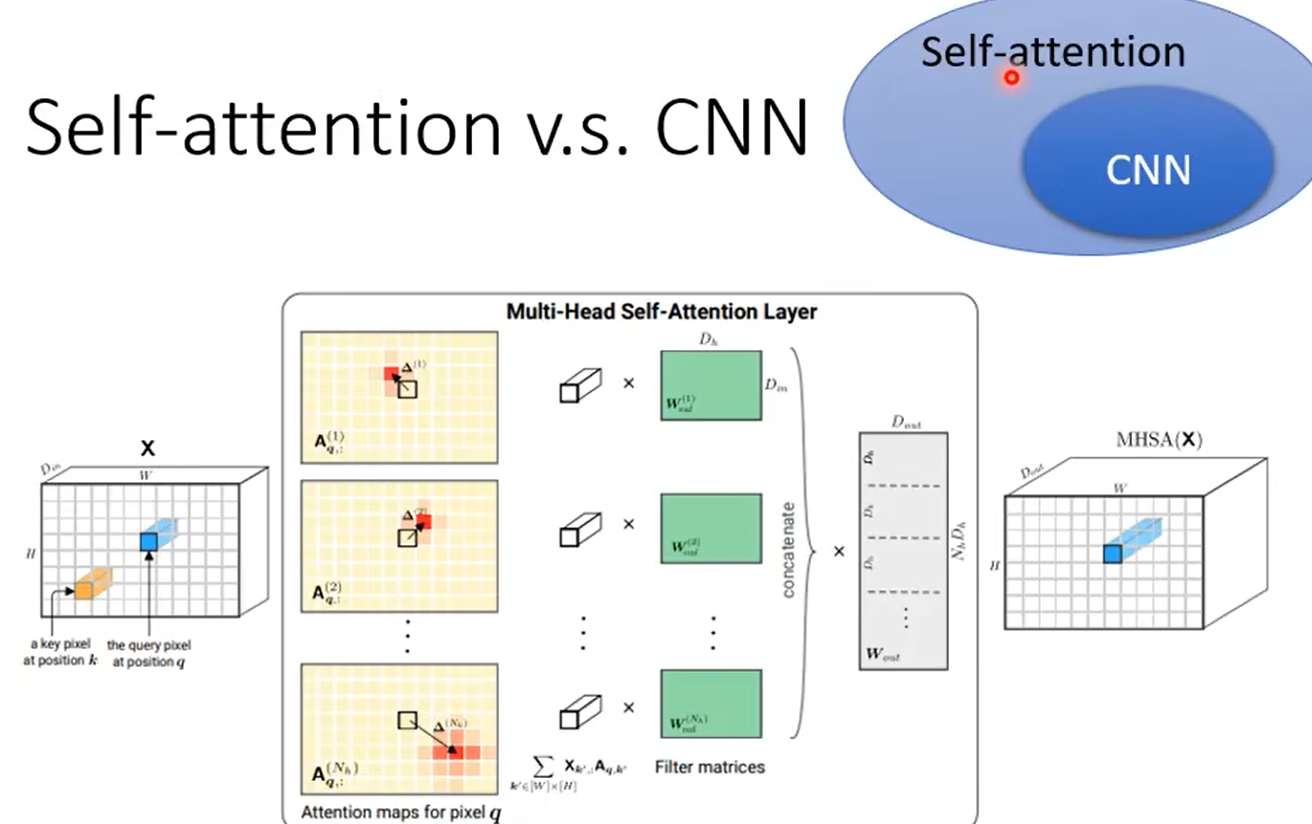
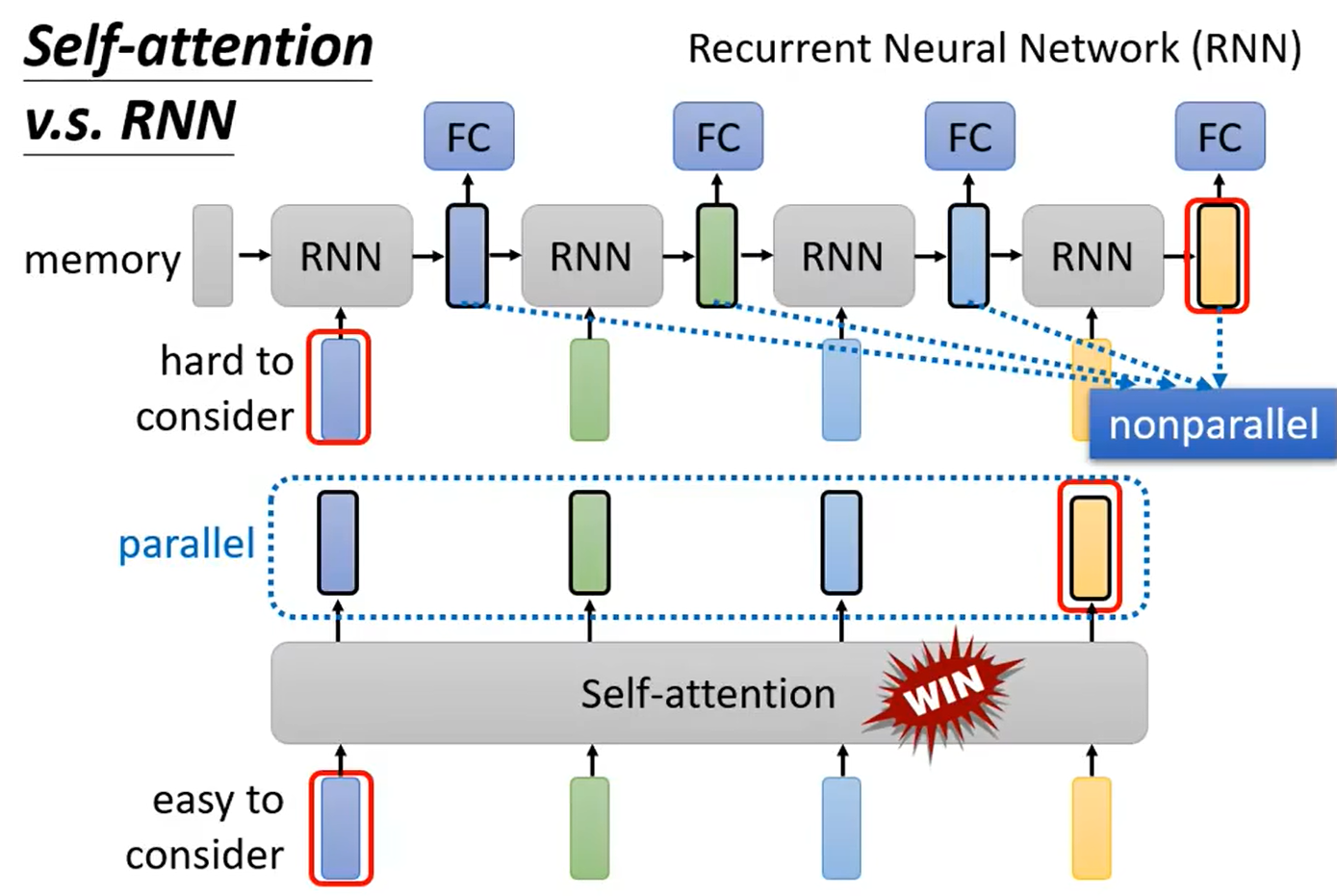
4、self attention和RNN
RNN消耗内存,更复杂;self attention可以平行计算
异同点:
- 序列建模能力:RNN 是一种经典的序列模型,能够处理可变长度的输入序列,适用于自然语言处理(NLP)等序列任务。Transformer 也适用于序列任务,但其在处理长序列时的效果更好,这归功于自注意力机制的并行性和长程依赖的处理能力。
- 结构:RNN 是一个逐步迭代的网络结构,它在每个时间步都接受当前输入和前一个时间步的隐状态,并根据当前输入和前一个状态计算当前状态。Transformer 是一个基于注意力机制的网络,它不依赖于时间步的顺序,可以并行处理整个序列。Transformer 使用自注意力机制来捕获序列中不同位置之间的依赖关系。
- 参数共享:在 RNN 中,参数共享是通过在不同时间步上使用相同的参数来实现的,以捕获序列中的模式和长期依赖。Transformer 中的自注意力机制也允许信息在不同位置之间共享,并且 Transformer 通过多头注意力进一步增强了参数共享的能力。
- 处理长程依赖:RNN 在处理长期依赖关系时可能会遇到梯度消失或爆炸问题,这会导致较长序列的建模效果较差。Transformer 引入了自注意力机制,使其能够更好地处理长程依赖关系,而不受梯度问题的影响。
- 并行性:由于 RNN 的顺序计算特性,其难以并行处理。相比之下,Transformer 中的自注意力机制可以并行地计算不同位置之间的注意力权重,从而提高了训练和推理的效率。
- 预训练模型:Transformer 的注意力机制在 NLP 中取得了显著的成功,并衍生出各种预训练模型,如BERT、GPT等。这些预训练模型在各种 NLP 任务中表现出色,并成为了当今 NLP 领域的主流模型。
总的来说,RNN 和 Transformer 是两种不同的序列建模方法。RNN 是经典的序列模型,适用于较短的序列任务,但在处理长序列和长程依赖时可能受限。Transformer 引入了自注意力机制,能够更好地处理长序列和长程依赖,且具有更高的并行性。Transformer 的成功在于其在 NLP 中取得的显著成果,并衍生出各种强大的预训练模型。

5、GNN
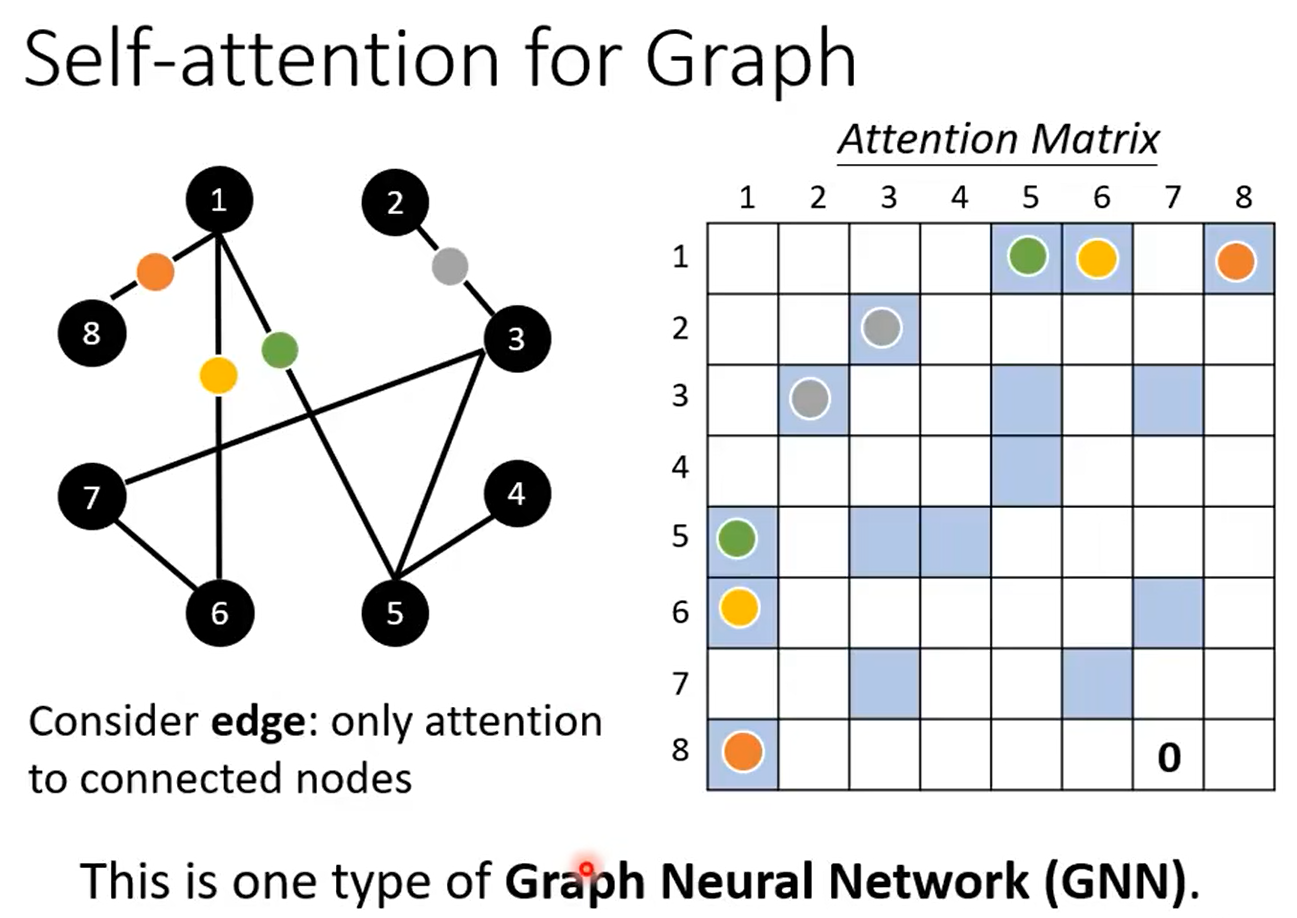
二、transformer
1、万物皆可适用的Seq2seq
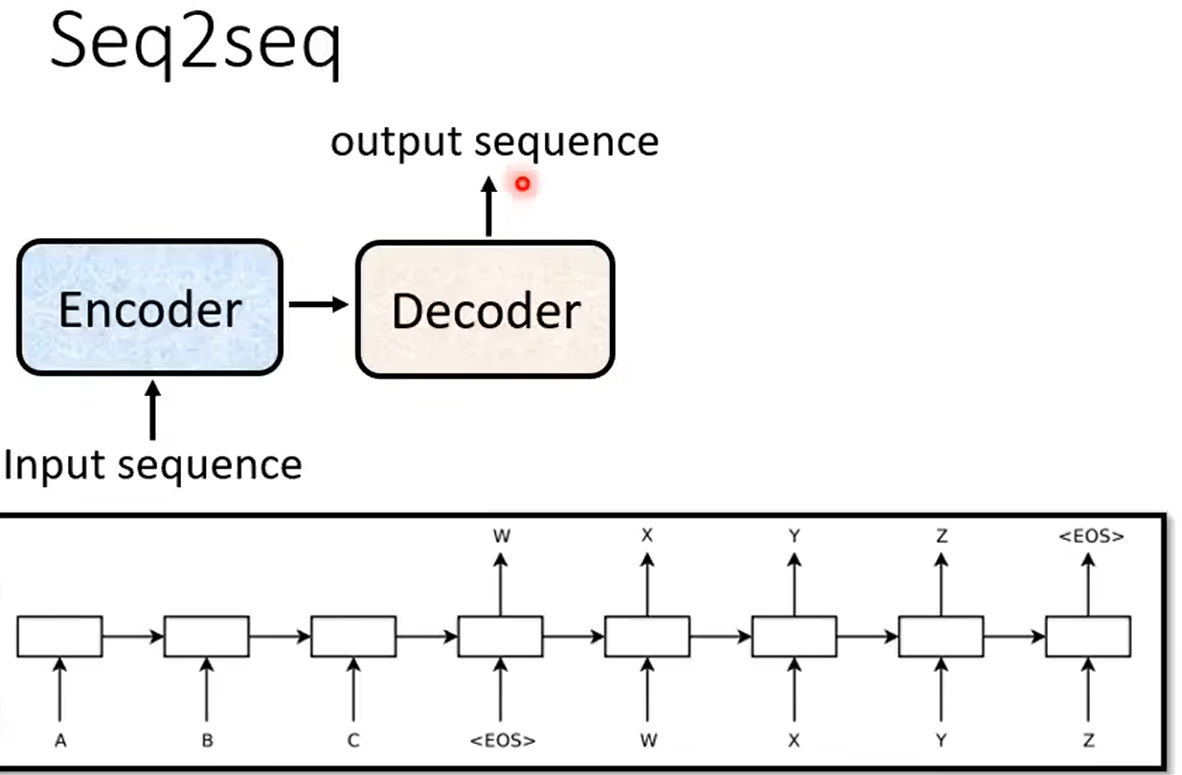
1)Encoder
(1)attention机制
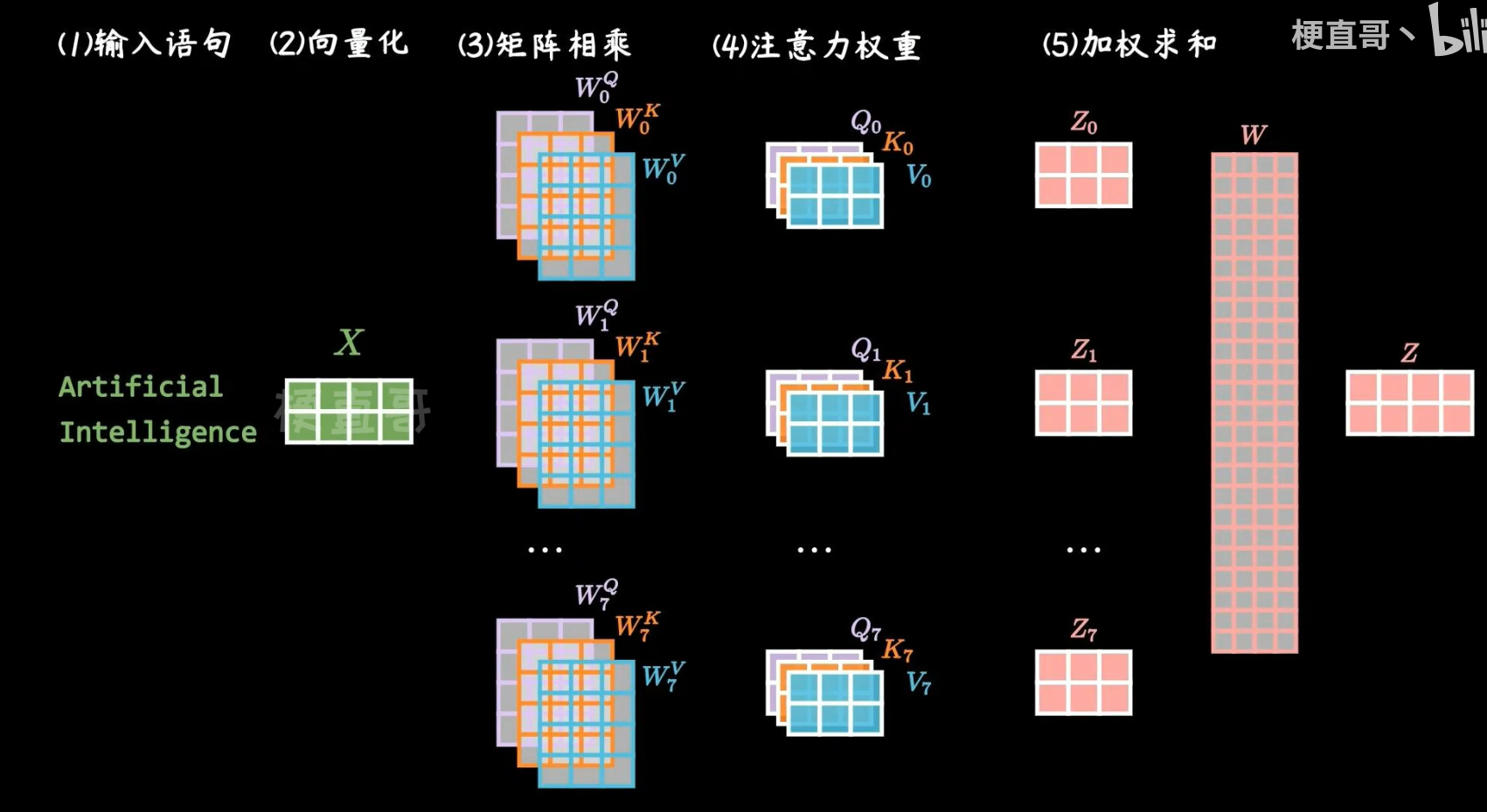
再加入多头注意力机制,也就是多个QKV矩阵,主要是为了消除QKV初始值的影响,然后求得的多个Z取加权平均得到最终的Z,
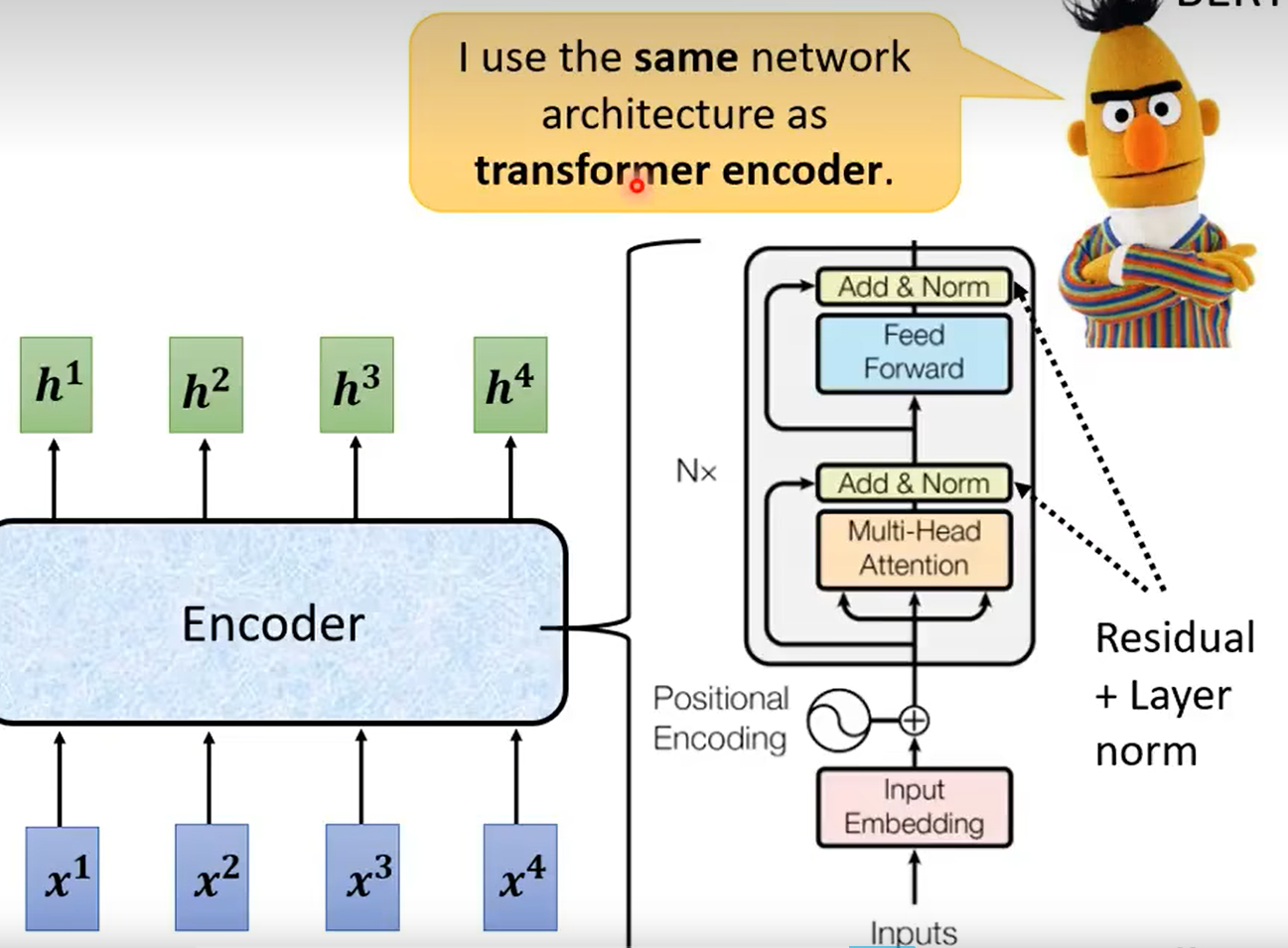
下图中Encoder就是使用的self-attention结构
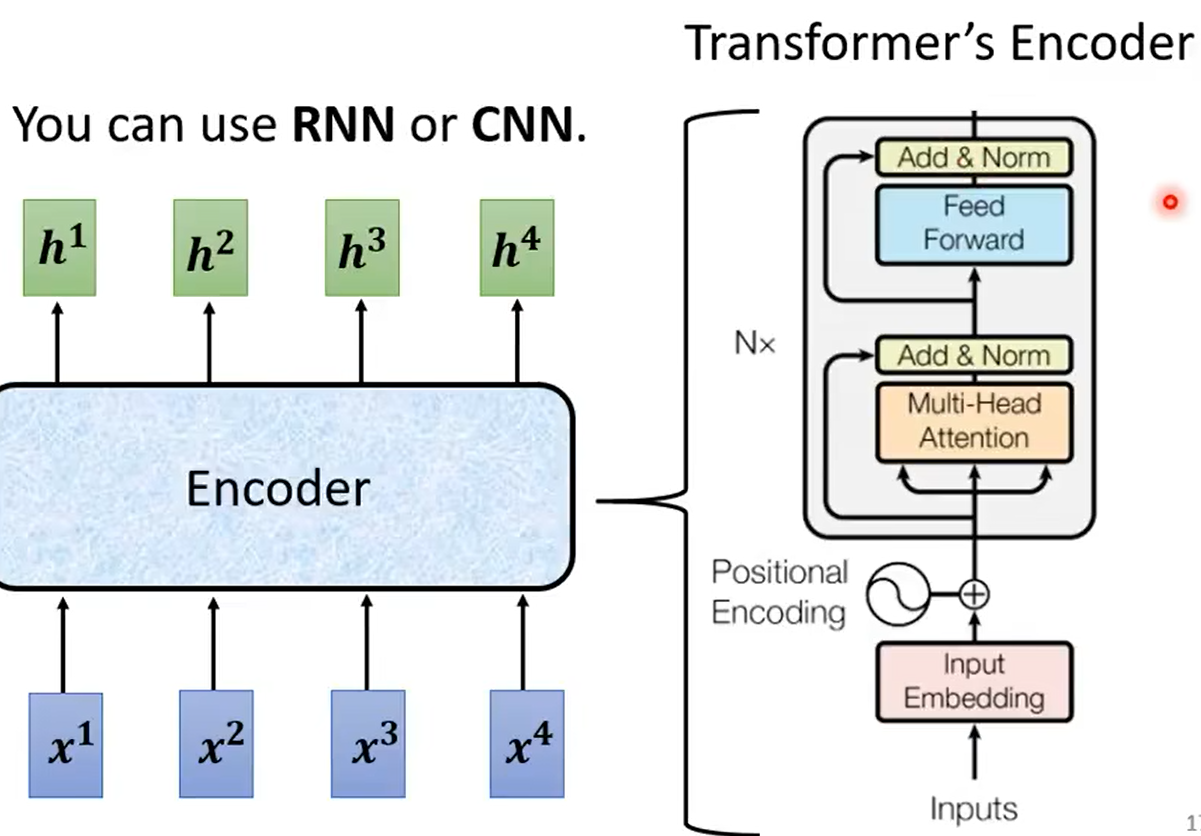
总体结构:
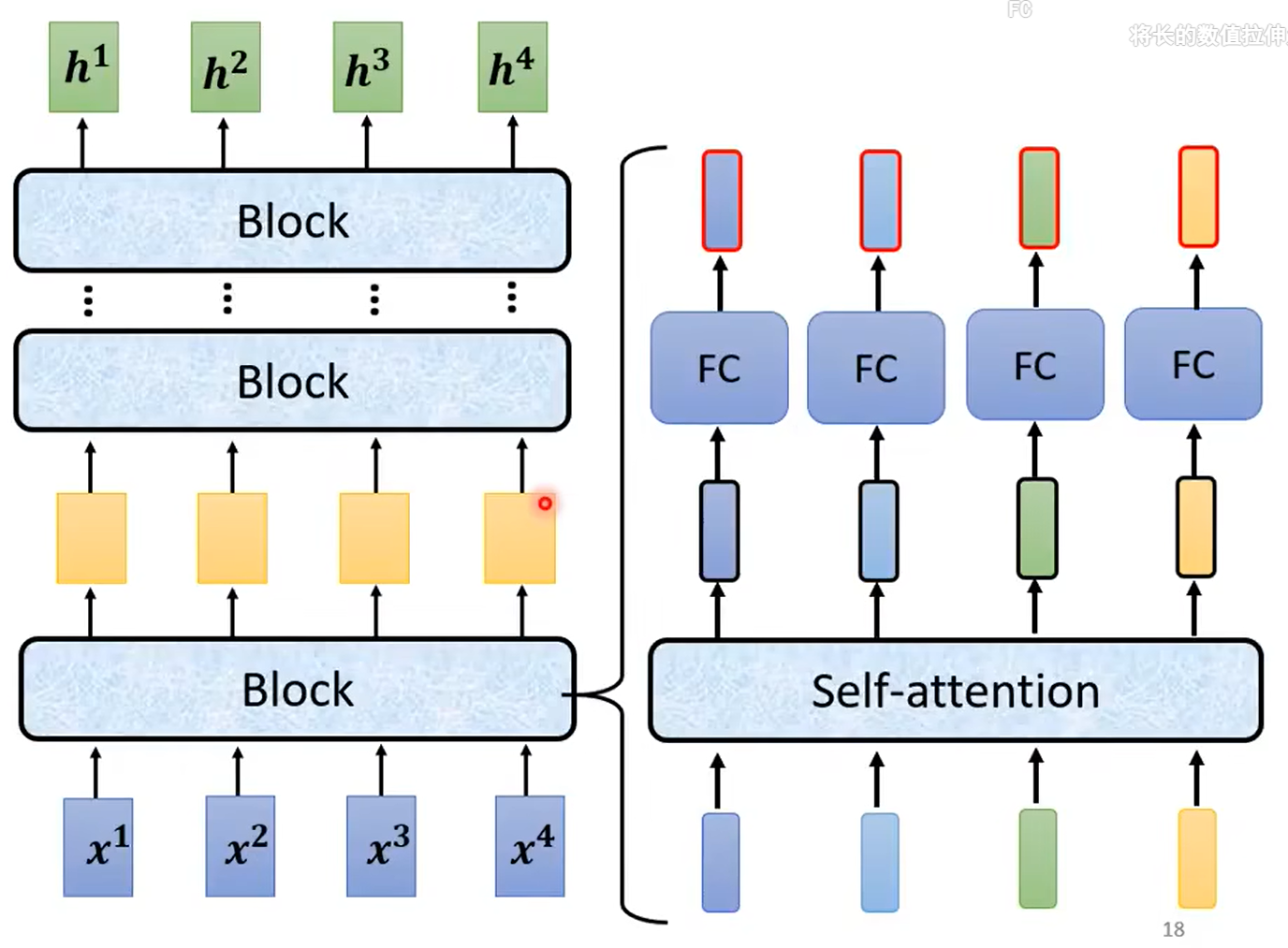
详解每一个block:
下面norm使用的是layer normalization,比batch normalization的效果好
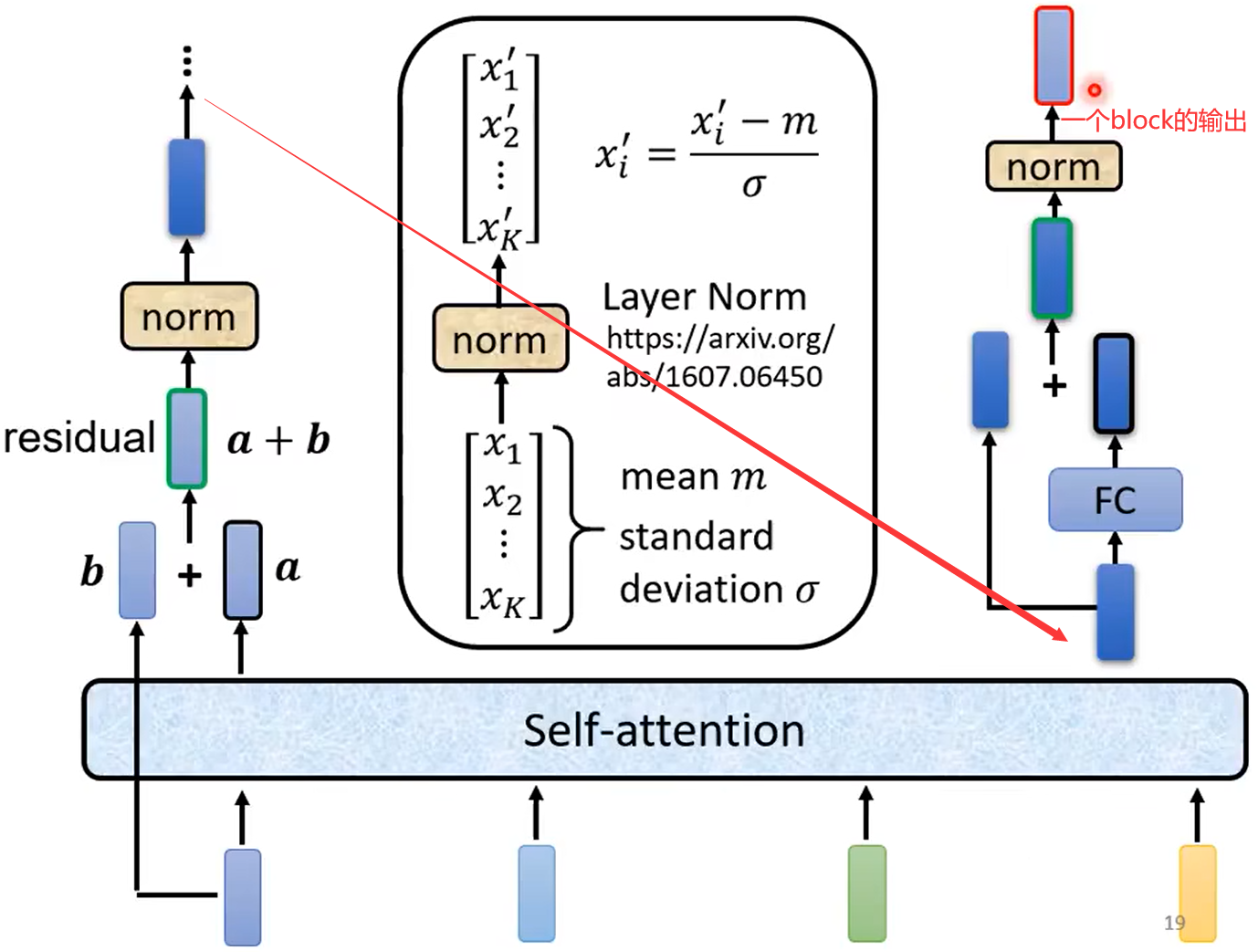
-------------------------------------------------------
(2)位置编码
Transformer 的位置编码(Positional Encoding)是一种特殊的编码方式,用于将输入序列中的位置信息加入到嵌入向量中。在没有位置编码的情况下,Transformer 模型无法区分输入序列中不同位置的单词,因为嵌入向量只包含了单词的语义信息,而没有包含顺序信息。位置编码的作用是为输入序列中的每个位置提供一个独特的编码,从而使得 Transformer 能够区分不同位置的单词,捕捉序列的顺序信息。
2)Decoder
(1)Autoregressive
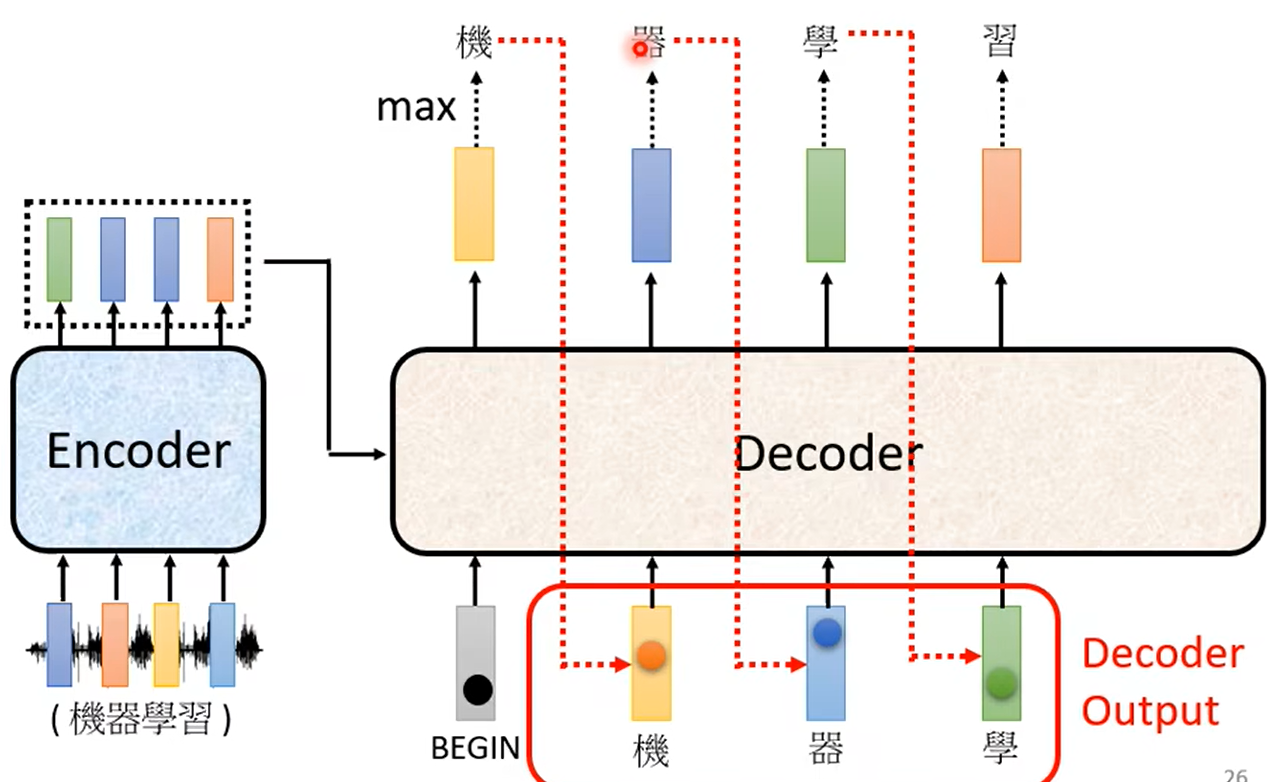
具体的网络结构:
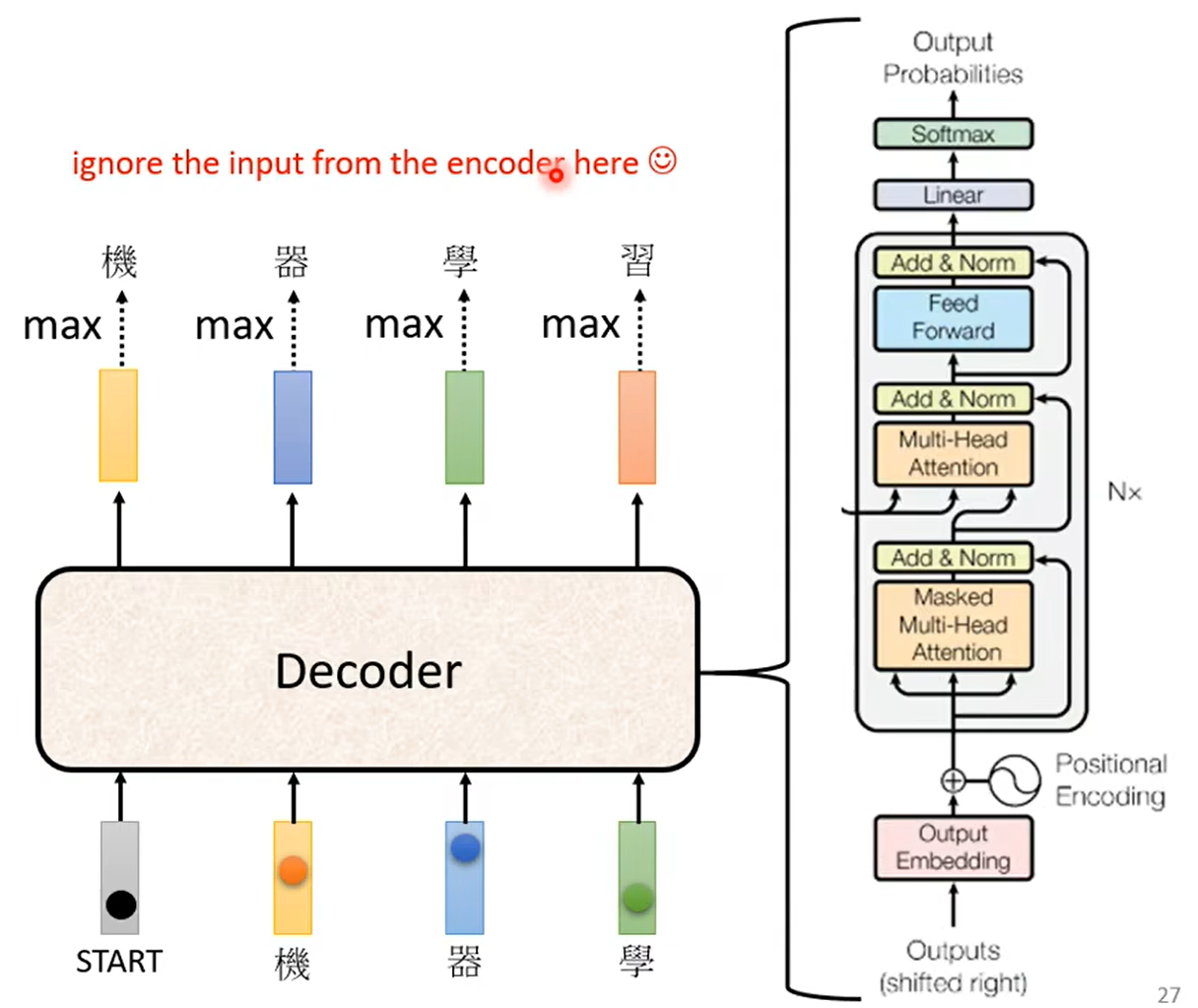
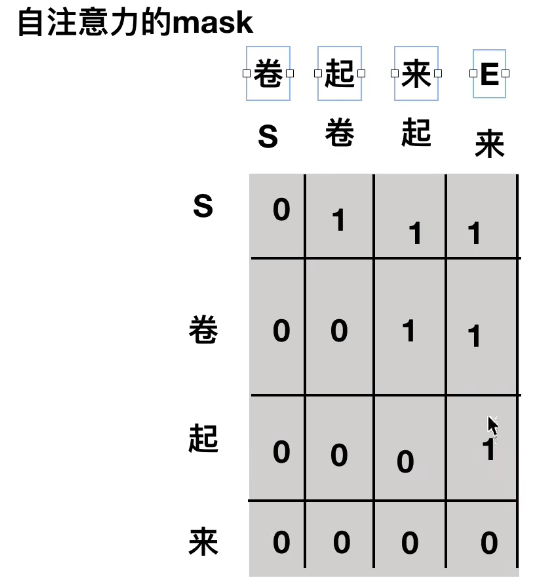
注意到:decoder中的结构里不是self-attention而是masked self-attention,因为解码过程中是一个一个得到翻译后的下一个向量
(2)Non-autoregressive (NAT)
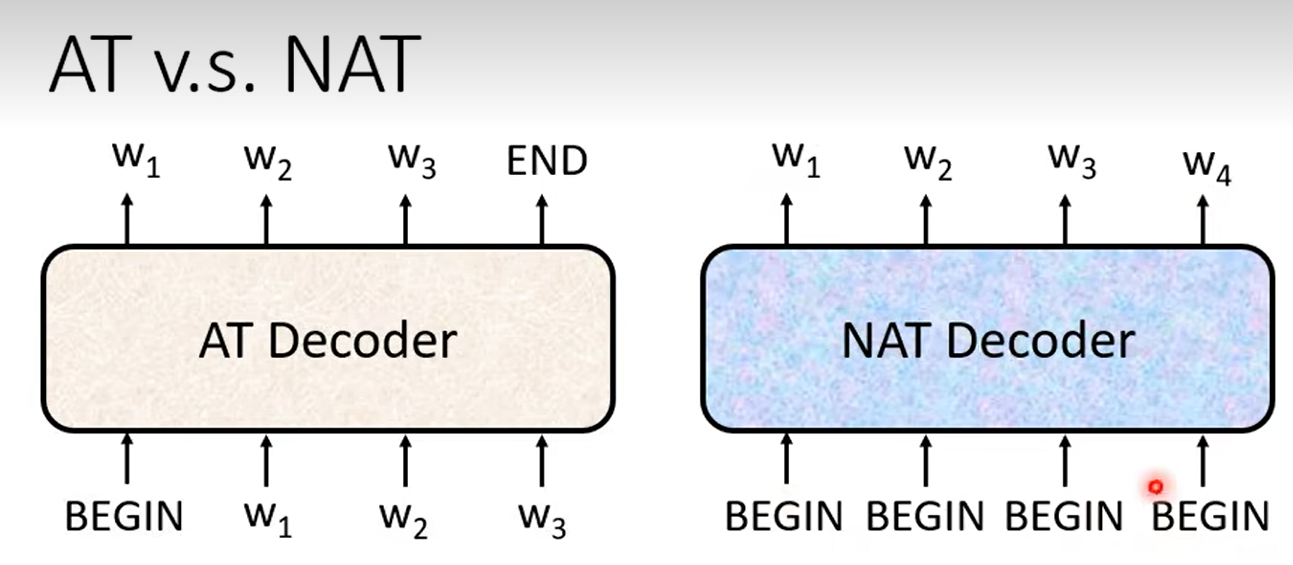
NAT具有一次性同时decode结果的优点
3)Encoder和Decoder之间的连接
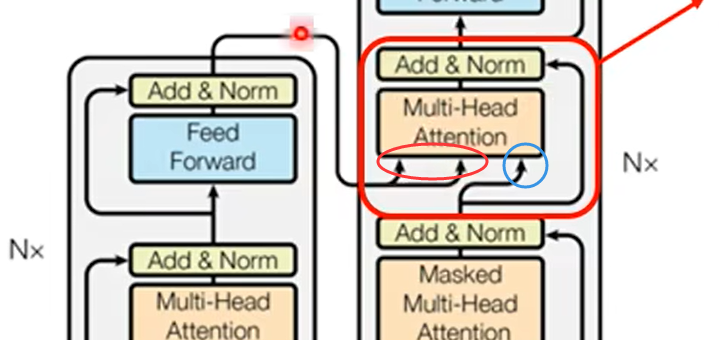
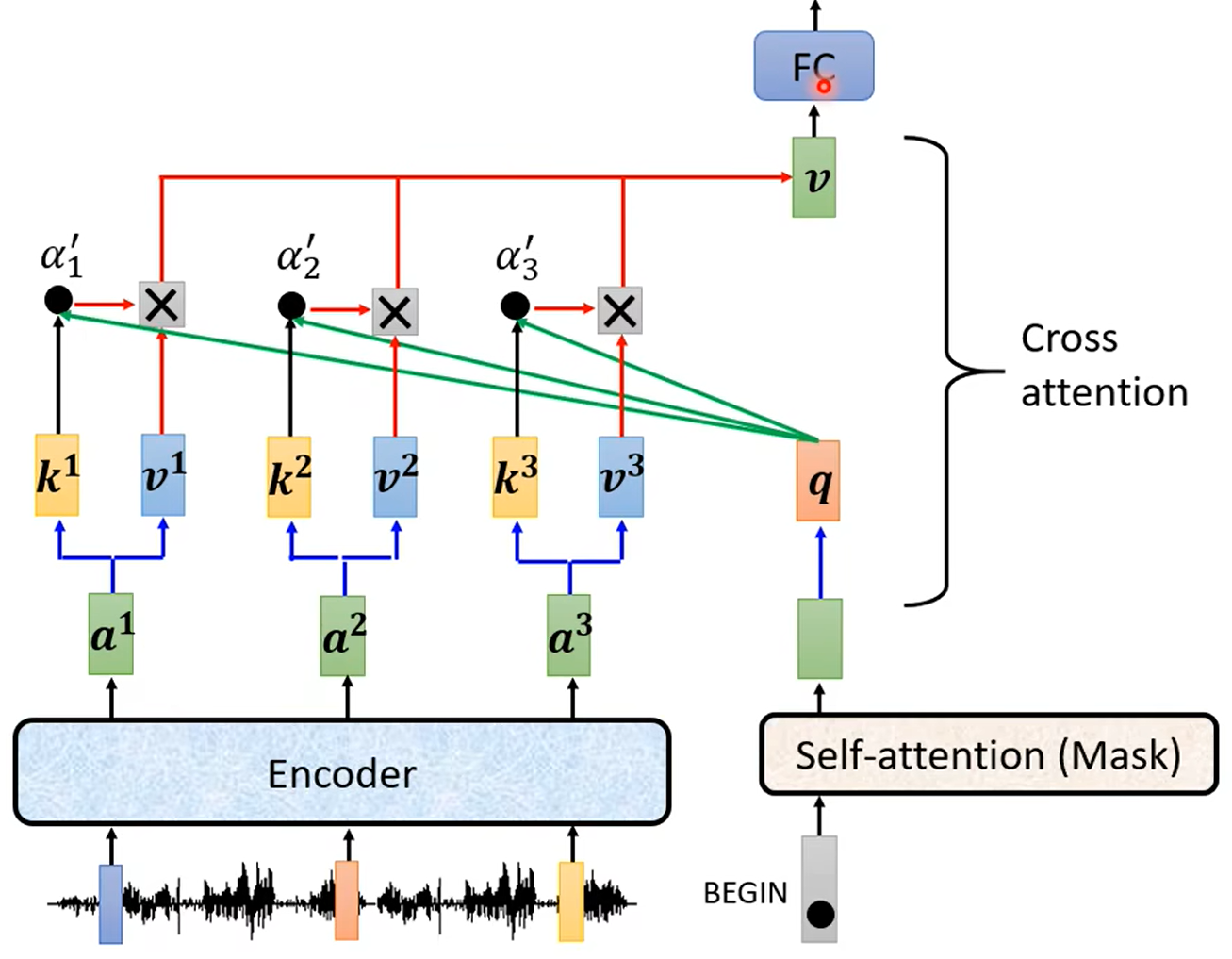
展开:即Cross attention中的q来自Decoder,k V来自Encoder
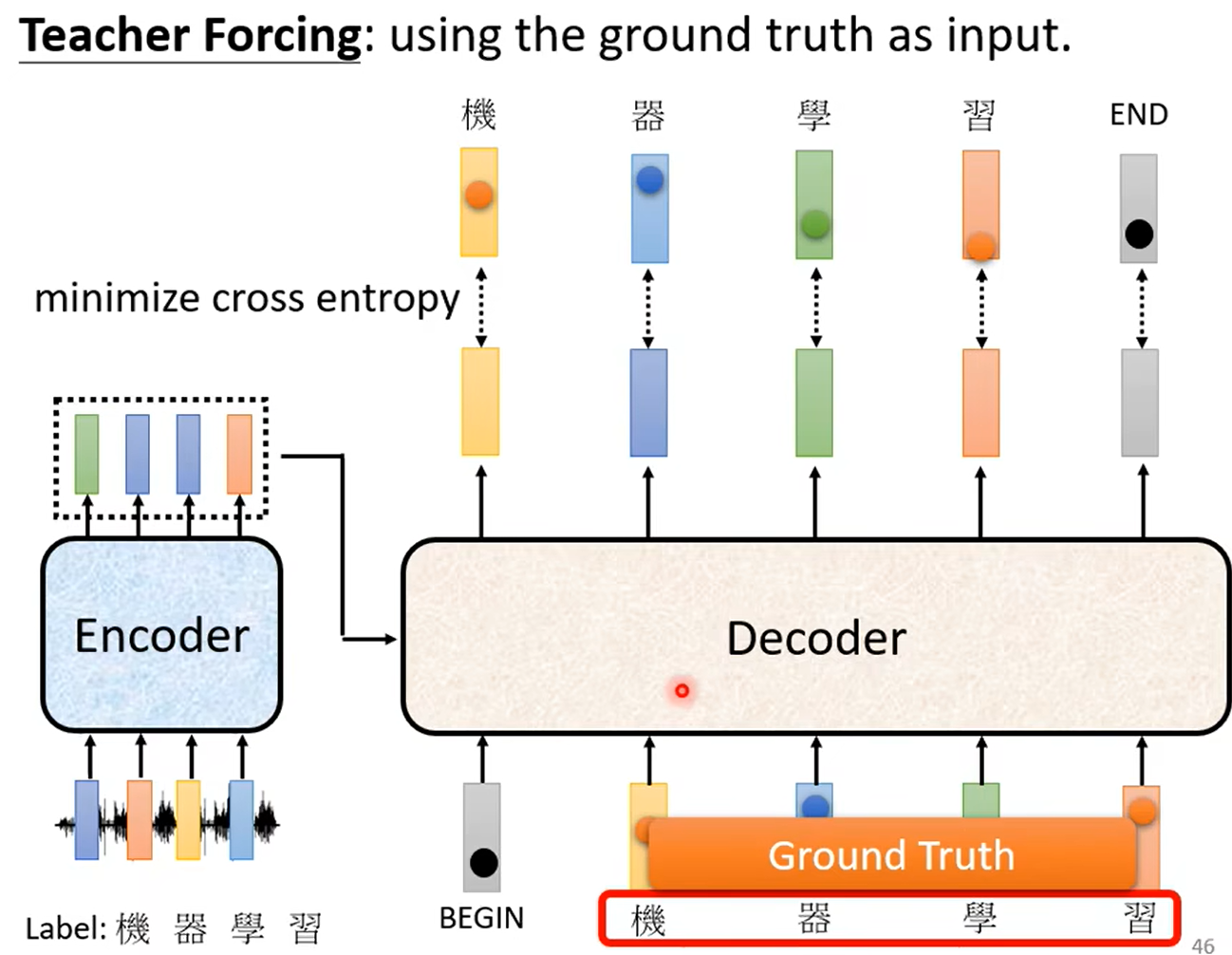
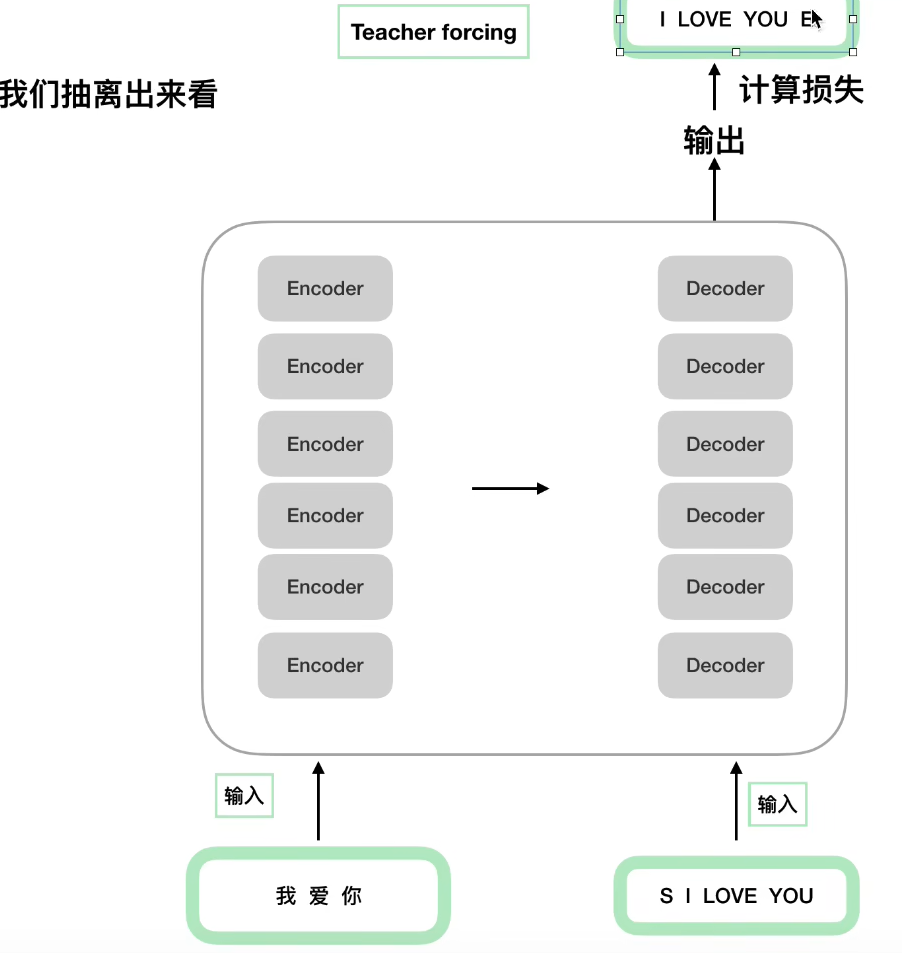
训练:为了解决decoder只能一个一个处理词向量,加快训练速度,把正确答案作为decoder的输入。这种方法叫做“Teacher Foring”
3、训练的tips
(1)Copy Mechanism:复制一些特定的名词
(2)Summarization
(3)Guided Attention
(4)Beam Search
三、代码细节
1. 输入和输出
注意,I LOVE YOU E表示的是整个输出的标签,而S I LOVE YOU是Decoder的输入,且需要后面的MASK,遮盖着每次的单词!!
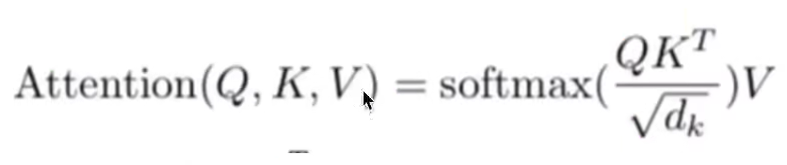
mask:
四、总结
Transformer有如下突出优点:
-
自注意力机制:Transformer 引入了自注意力机制,允许模型在处理序列数据时对不同位置的信息进行动态关注。这使得模型能够更好地处理长序列,捕捉全局依赖关系,避免了传统循环神经网络(RNN)中存在的梯度消失和梯度爆炸问题。
-
并行计算:Transformer 中的注意力计算可以进行并行处理,因为每个位置的输出只依赖于其它位置的信息。这使得 Transformer 能够更好地利用硬件设备的并行性,加速训练和推理过程。
-
多头注意力:Transformer 使用多头注意力机制,允许模型同时从不同的注意力头中学习多种表示。每个注意力头可以关注输入序列中不同的部分,增强了模型的表达能力和泛化能力。
-
位置编码:为了处理序列数据的顺序信息,Transformer 使用位置编码将输入序列中的每个位置进行编码。这使得模型能够在处理序列时,不仅关注单词的语义信息,还能理解单词在序列中的位置和顺序。
-
缩放的点积注意力:Transformer 使用缩放的点积注意力,使得注意力计算的时间复杂度与输入序列的长度无关。这使得模型能够处理较长的序列,而不会因为序列长度的增加而导致计算开销的显著增加。
-
Transfer Learning:由于 Transformer 在 NLP 中表现出色,预训练的 Transformer 模型(如BERT、GPT等)成为强大的语言表示学习工具。这些预训练模型可以通过微调(fine-tuning)适应各种不同的 NLP 任务,使得在少量标注数据上也能获得很好的性能。