首先注意力模型可以宏观上理解为一个查询(query)到一系列(键key-值value)对的映射。
将Source(源)中的构成元素想象成是由一系列的<Key,Value>数据对构成,此时给定Target(目标)中的某个元素Query(查询),通过计算Query和各个Key的相似性或者相关性,得到每个Key对应Value的权重系数,通过softmax归一化后,对权重和相应Value进行加权求和,即得到了最终的Attention数值。所以本质上Attention机制是对Source中元素的Value值进行加权求和,而Query和Key用来计算对应Value的权重系数。目前在NLP研究中,key和value常常都是同一个,即key=value。


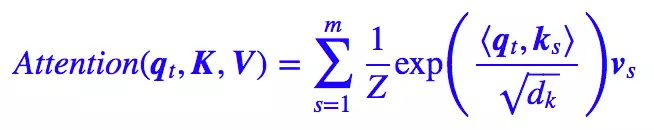
其中 K 、 V K、V K、V 是归一化因子。 是一一对应的,它们就像是 key-value 的关系,那么上式的意思就是通过 q t q_t qt 这个 query,通过与各个 k s k_s ks 内积的并 s o f t m a x softmax softmax 的方式,来得到 q t q_t qt 与各个 v s v_s vs 的相似度,然后加权求和,得到一个 d v d_v dv 维的向量。此处在进行 q t q_t qt 、相似度计算时,使用点积,除此之外还有拼接,感知机等方式。
其中因子 d k \sqrt{d_k} dk 起到调节作用,使得上方内积不至于太大(太大的话 s o f t m a x softmax softmax 后就非 0 即 1 了,不够“soft”了),其中 d k \sqrt{d_k} dk 指的是键向量维度的平方根。
多头注意力(Multi-head Attention)

多头attention(Multi-head attention)结构如上图,Query,Key,Value首先进过一个线性变换,然后输入到放缩点积attention,注意这里要做h次,也就是所谓的多头,每一次算一个头,头之间参数不共享,每次Q,K,V进行线性变换的参数 W W W 是不一样的。然后将h次的放缩点积attention结果进行拼接,再进行一次线性变换得到的值作为多头attention的结果。
可以看到,google提出来的多头attention的不同之处在于进行了h次计算而不仅仅算一次,论文中说到这样的好处是可以允许模型在不同的表示子空间里学习到相关的信息。
自注意力(Self Attention)
所谓 Self Attention,其实就是 Attention(X,X,X),X 就是前面说的输入序列。Self-attention即K=V=Q,例如输入一个句子,那么里面的每个词都要和该句子中的所有词进行attention计算。目的是学习句子内部的词依赖关系,捕获句子的内部结构。更准确来说,Google 所用的是 Self Multi-Head Attention。
自注意力可以提取句子自身词间依赖,比如常用短语、代词指代的事物等。或者说, 这层帮助编码器在对每个单词编码时关注输入句子的其他单词。
对于使用自注意力机制的原因,论文中提到主要从三个方面考虑(每一层的复杂度,是否可以并行,长距离依赖学习),并给出了和RNN,CNN计算复杂度的比较。
1、可以看到,如果输入序列n小于表示维度d的话,每一层的时间复杂度self-attention是比较有优势的。当n比较大时,作者也给出了一种解决方案self-attention(restricted)即每个词不是和所有词计算attention,而是只与限制的r个词去计算attention。
2、在并行方面,多头attention和CNN一样不依赖于前一时刻的计算,可以很好的并行,优于RNN。
3、在长距离依赖上,由于self-attention是每个词和所有词都要计算attention,所以不管他们中间有多长距离,最大的路径长度也都只是1。能够无视词之间的距离直接计算依赖关系,能够学习一个句子的内部结构。

先来看一个翻译的例子“I arrived at the bank after crossing the river” 这里面的bank指的是银行还是河岸呢,这就需要我们联系上下文,当我们看到river之后就应该知道这里bank很大概率指的是河岸。在RNN中我们就需要一步步的顺序处理从bank到river的所有词语,而当它们相距较远时RNN的效果常常较差,且由于其顺序性处理效率也较低。
Self-Attention则利用了Attention机制,计算每个单词与其他所有单词之间的关联,在这句话里,当翻译bank一词时,river一词就有较高的Attention score。利用这些Attention score就可以得到一个加权的表示,然后再放到一个前馈神经网络中得到新的表示,这一表示很好的考虑到上下文的信息。总之Self-Attention机制对每一个词得到新的考虑了上下文信息的表征。
位置嵌入(Position Embedding)
上述模型并不能学习序列的顺序。换句话说,如果将 K,V 按行打乱顺序(相当于句子中的词序打乱),那么 Attention 的结果还是一样的。学习不到顺序信息,那么效果将会大打折扣(比如机器翻译中,有可能只把每个词都翻译出来了,但是不能组织成合理的句子)。这就引出了位置向量(Position Embedding)。
将每个位置编号,然后每个编号对应一个向量,通过结合位置向量和词向量,就给每个词都引入了一定的位置信息,这样 Attention 就可以分辨出不同位置的词了,进而学习位置信息了。
在Attention Is All You Need一文中,Google直接给出了位置向量构造公式:
这里的意思是将 id 为 p p p 的位置映射为一个 d p o s d_{pos} dpos 维的位置向量,这个向量的第i个元素的数值就是 P E i ( p ) PE_i(p) PEi(p) 。
位置向量是绝对位置信息,相对位置信息也很重要。Google 选择前述的位置向量公式的一个重要原因如下:由于我们有 sin(α+β)=sinα·cosβ+cosα·sinβ 以及 cos(α+β)=cosα·cosβ−sinα·sinβ,这表明位置 p+k 的向量可以表示成位置 p、k 的向量的线性变换,这提供了表达相对位置信息的可能性。
结合位置向量和词向量有几个可选方案,可以把它们拼接起来作为一个新向量,也可以把位置向量定义为跟词向量一样大小,然后两者加起来,Attention Is All You Need使用的是后者。

Layer Normalization

我们指出BN并不适用于RNN等动态网络和batchsize较小的时候效果不好。Layer Normalization(LN)的提出有效的解决BN的这两个问题。LN和BN不同点是归一化的维度是互相垂直的,如图1所示。在图1中表示样本轴,表示通道轴,是每个通道的特征数量。BN如右侧所示,它是取不同样本的同一个通道的特征做归一化;LN则是如左侧所示,它取的是同一个样本的不同通道做归一化。
LN是和BN非常近似的一种归一化方法,不同的是BN取的是不同样本的同一个特征,而LN取的是同一个样本的不同特征。在BN和LN都能使用的场景中,BN的效果一般优于LN,原因是基于不同数据,同一特征得到的归一化特征更不容易损失信息。但是有些场景是不能使用BN的,例如batchsize较小或者在RNN中,这时候可以选择使用LN,LN得到的模型更稳定且起到正则化的作用。RNN能应用到小批量和RNN中是因为LN的归一化统计量的计算是和batchsize没有关系的。
Transformer
综合上述部分组成整体结构 T r a n s f o r m e r Transformer Transformer

Transformer模型分为编码器和解码器两个部分。
编码器由6个相同的层堆叠在一起,每一层又有两个支层。第一个支层是一个多头的自注意机制,第二个支层是一个简单的全连接前馈网络。在两个支层外面都添加了一个残差连接(residual),然后进行了layer nomalization的操作。模型所有的支层以及embedding层的输出维度都是。
解码器也是堆叠了6个相同的层。不过每层除了编码器中那两个支层,解码器还加入了第三个支层,如图中所示同样也用了残差连接以及layer normalization。