笔者曾经用python第三方库requests来爬取京东商城的商品页内容,经过解析之后发现只爬到了商品页一半的图片。(这篇文章我们以爬取智能手机图片为例)
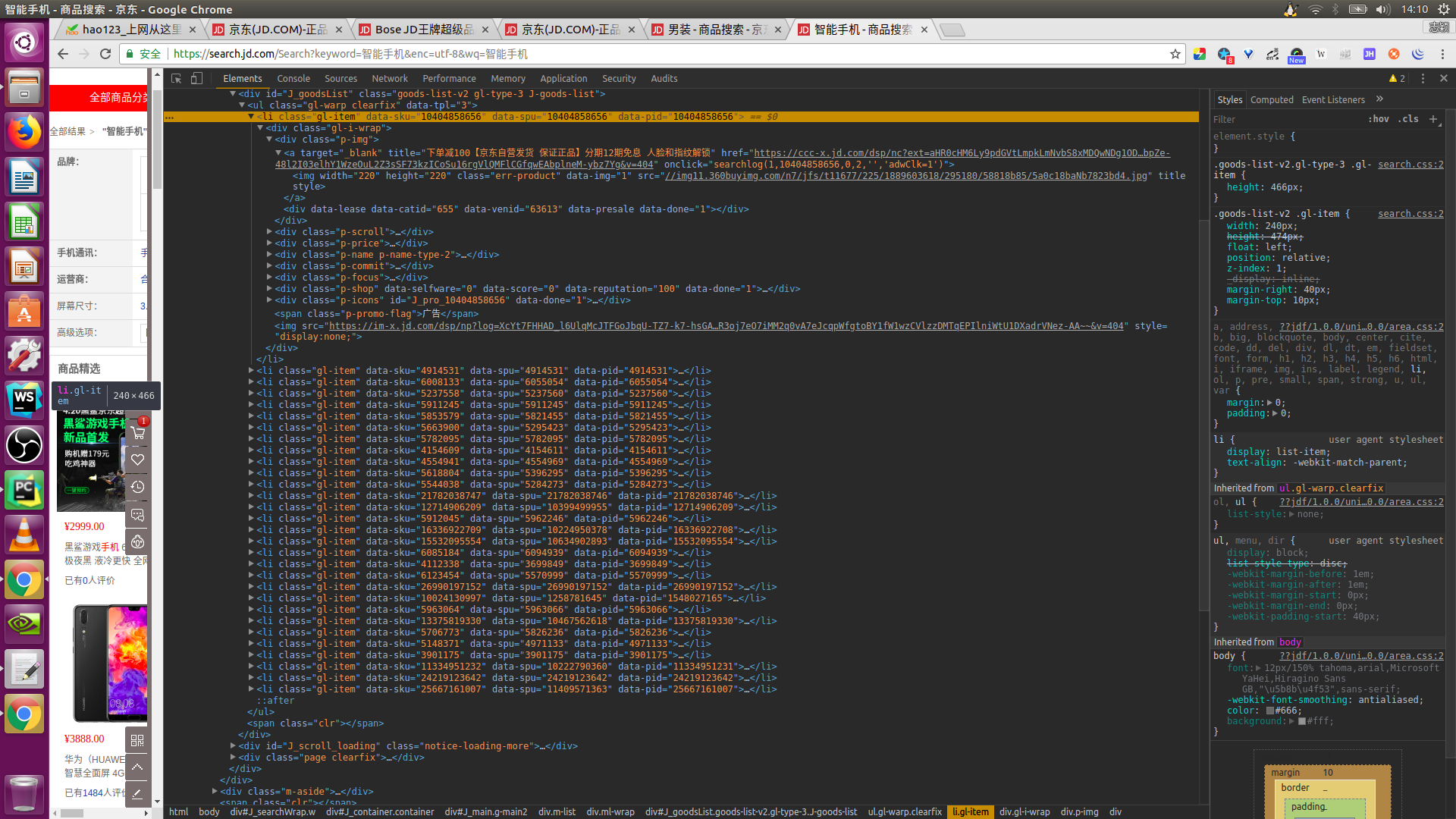
当鼠标没有向下滑时,此时查看源代码的话,就会看到上图的内容,只有三十个 li 标签(一个li标签中有一个图片地址)。
但是鼠标滑至底部后再查看源代码的话就会看到六十个 li 标签,这才是我们真正需要爬取的内容。下图是鼠标滑至底部时的源代码。
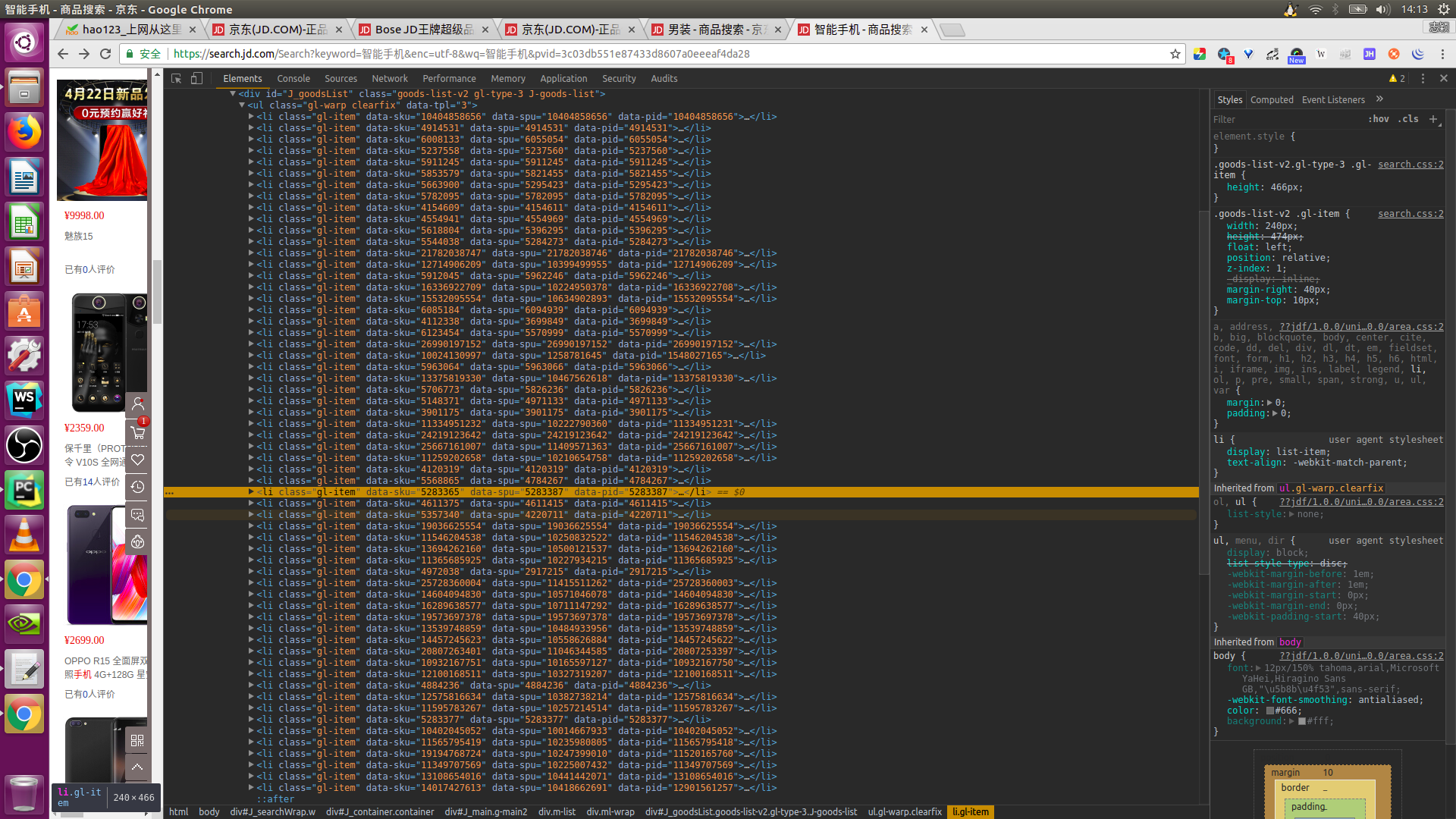
为什么会出现这种原因呢?这是因为京东商城的商品信息是通过动态加载的方式进行加载的,而这种页面又被称为动态页面。要想爬取这种页面就必须模拟浏览器的行为,和页面进行交互。python第三方库selenium恰好能做到这些,只需要将页面滑至底部就行。
首先我们通过pip工具来安装selenium库:
pip install selenium通过分析每个页面的url链接,我找到了京东商品页每个网页的url的规律:
# search_p 是要查询的商品名称,page后面的值是按照,1,3,5,7,9......的规律递增的,对应的网页是第1页,第2页,第3页......
url = "https://search.jd.com/Search?keyword=" + str(search_p) + "&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&wq=" + \
str(search_p) + "&page=" + str(index * 2 + 1)
接着来分析一下图片的地址,通过分析我找到了两种图片链接格式:
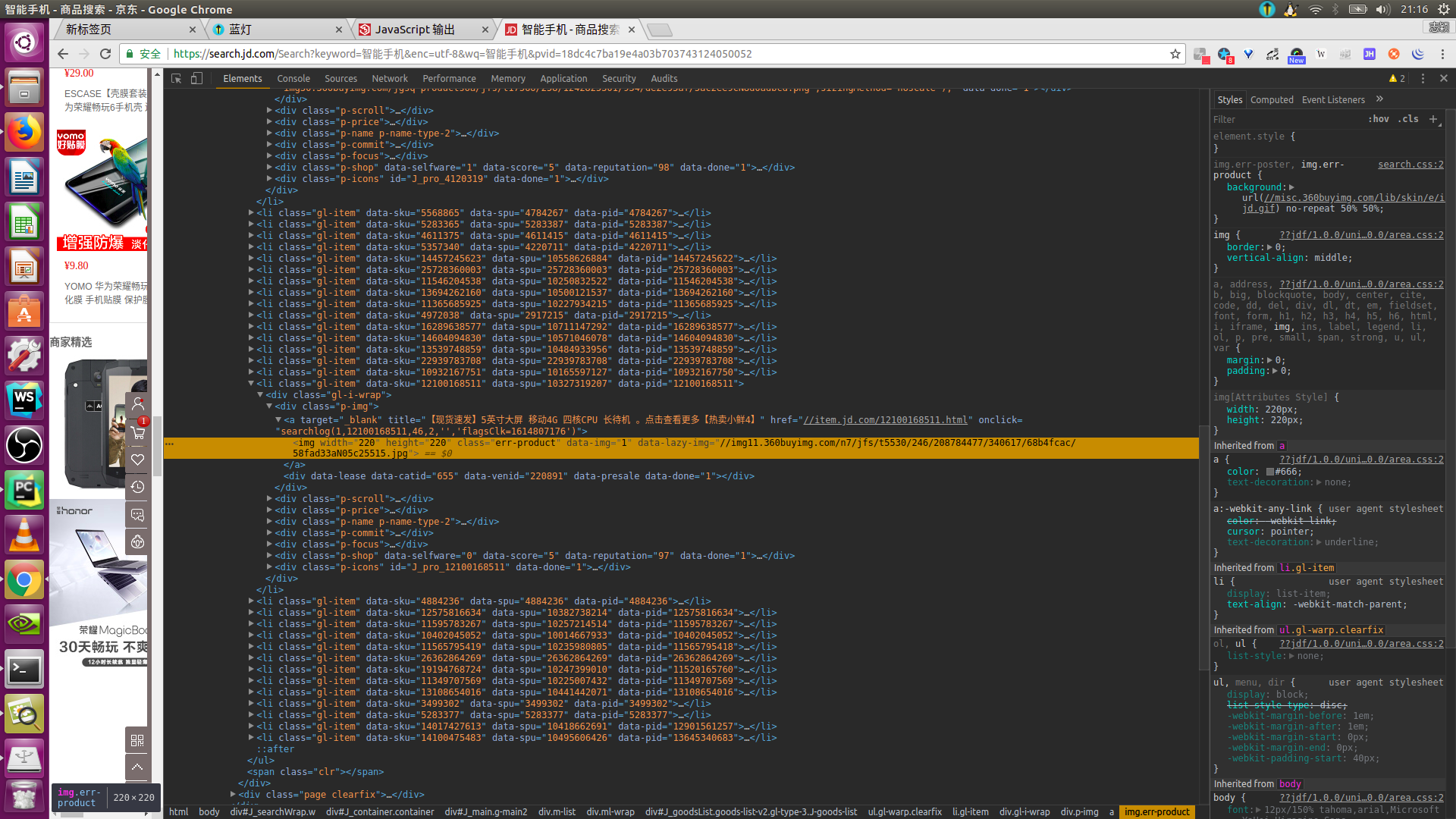
一种是上图所示的格式:
<img width="220" height="220" class="err-product" data-img="1" data-lazy-img="//img11.360buyimg.com/n7/jfs/t5530/246/208784477/340617/68b4fcac/58fad33aN05c25515.jpg">还有一种是这种格式的:
<img width="220" height="220" class="err-product" data-img="1" src="//img14.360buyimg.com/n7/jfs/t4549/6/4532220459/272946/d0b72af9/59119ddbNd25bdd22.jpg">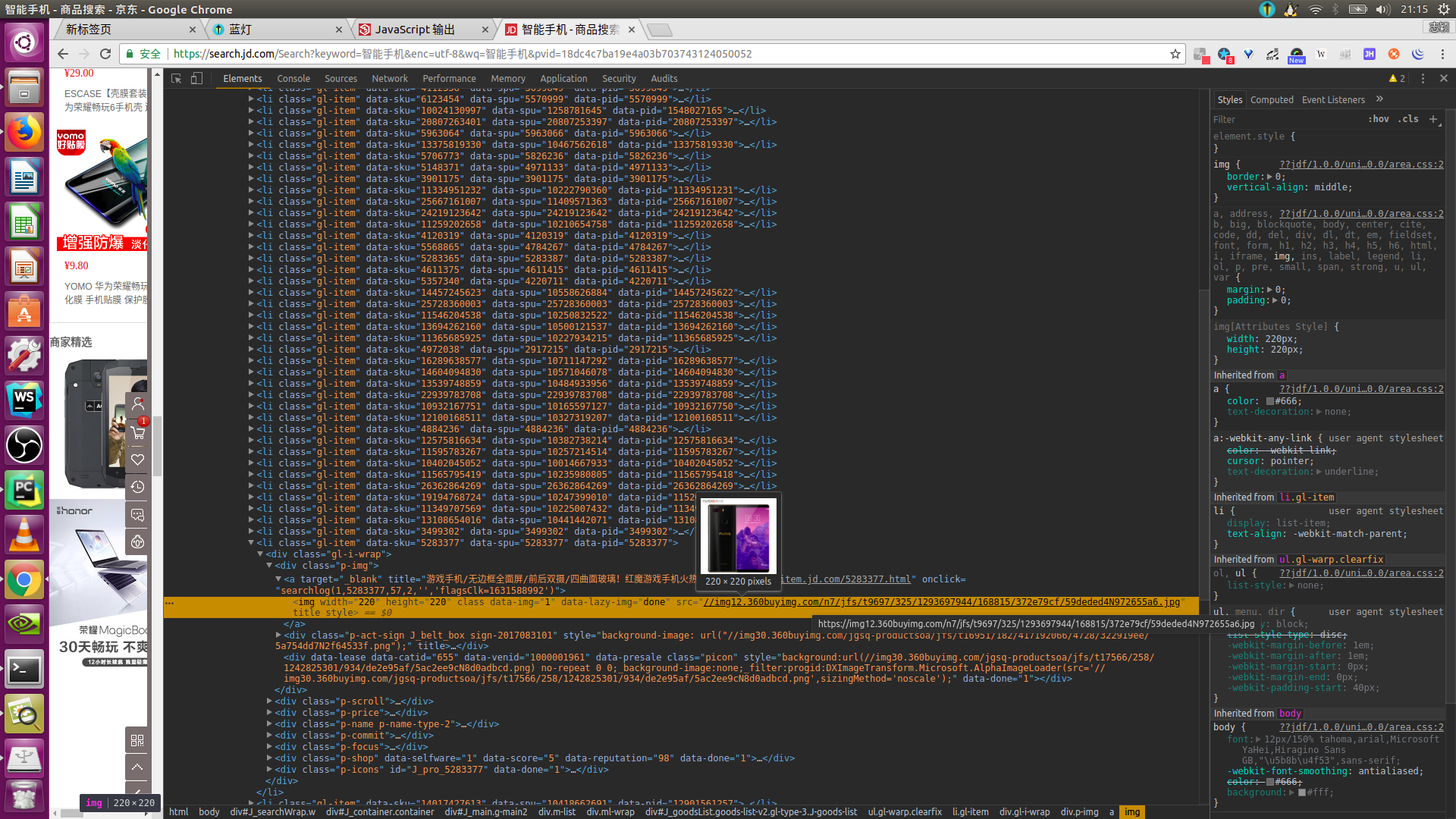
确定图片格式后,定义一个函数来解析网页中的图片地址,这里我用BeautifulSoup4库对其进行解析。
# 提取网页的图片的网址
def parse_html_page(html):
# 对有效图片网址进行提取
soup = BeautifulSoup(html, 'lxml')
# 定义一个列表来获取分析得到的图片的网址
url_items = []
li_tags = soup.find_all('li', 'gl-item')
for li_tag in li_tags:
try:
if len(li_tag.img["src"]) >= 10:
url_items.append(li_tag.img['src'])
else:
pass
except:
if len(li_tag.img["data-lazy-img"]) >= 10:
url_items.append(li_tag.img['data-lazy-img'])
else:
url_items.append(li_tag.img["src"])
return url_items然后我们开始获取网页源代码,前面已经提到,要想获取到完整的网页源代码,就需要浏览器和网页进行交互,即让浏览器自动执行一个向下滑至网页底部的动作,停顿几秒,等待网页加载完成(这一步必须有,否则获得的网页源代码仍会不完整),待网页加载完成之后就可以获取网页源代码了。
这里使用selenium来使浏览器自动执行向下滑动至网页底部的动作:
# 执行页面向下滑至底部的动作
driver.execute_script("window.scrollTo(0,document.body.scrollHeight);")
# 停顿5秒等待页面加载完毕!!!(必须留有页面加载的时间,否则获得的源代码会不完整。)
time.sleep(5)网页源代码获取成功之后,便可以用urlretrieve(url, filename=path)方法来定义下载函数。
最后总结一下这个爬虫,有几个方面需要注意:1,每个商品页面对应的url。2,如何利用selenium + 浏览器来解决获取动态页面的源代码的问题。3,如何完整提取每个商品页中的60张图片的url。