**本文更完整的内容请参考极客教程的深度学习专栏:http://geek-docs.com/deep-learning/rnn/keras-lstm-tutorial.html,欢迎提出您的宝贵意见。感谢。
文章目录
1 循环神经网络
2 LSTM网络
3 LSTM字嵌入和隐藏层大小
4 Keras LSTM架构
5 构建Keras LSTM模型
6 创建Keras LSTM数据生成器
7 创建Keras LSTM结构
8 编译并运行Keras LSTM模型
9 Keras LSTM结果
Keras LSTM教程,在本教程中,我将集中精力在Keras中创建LSTM网络,简要介绍LSTM的工作原理。在这个Keras LSTM教程中,我们将利用一个称为PTB语料库的大型文本数据集来实现序列到序列的文本预测模型。本教程中的所有代码都可以在此站点的Github存储库中找到。
循环神经网络
LSTM网络是一种循环神经网络。循环神经网络是一种神经网络,它试图对依赖于时间或顺序的行为(如语言、股价、电力需求等)进行建模。这是通过将神经网络层在t时刻的输出反馈给同一网络层在t + 1时刻的输入来实现的。它是这样的:
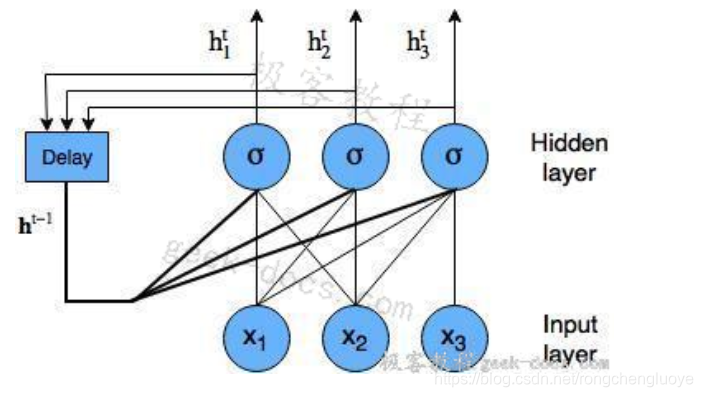
带节点的循环神经网络图
在训练和预测过程中,循环神经网络以编程方式“展开”,得到如下结果:
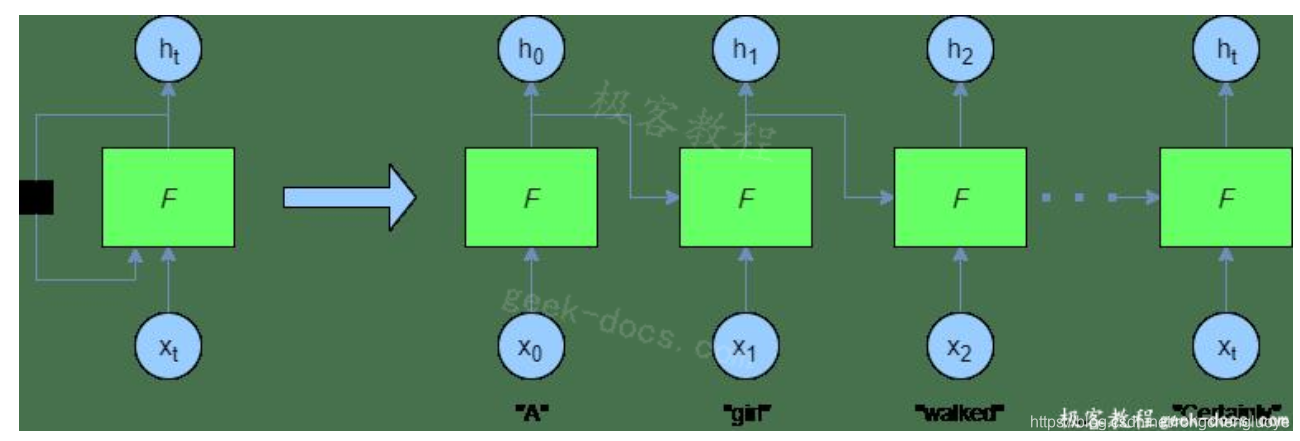
在这里,您可以看到,在每个时间步骤中,都提供了一个新单词——前一个F(即 )的输出也在每个时间步骤中提供给网络。
vanilla 循环神经网络(由常规神经网络节点构造)的问题在于,当我们尝试对由大量其他单词分隔的单词或序列值之间的依赖关系建模时,我们体验到了梯度消失问题(有时也是梯度爆炸问题)。这是因为小梯度或权重(小于 1 的值)在多个时间步长中乘以多次,并且梯度以不相通方式收缩为零。这意味着这些早期图层的权重不会显著更改,因此网络不会学习长期依赖关系。
LSTM网络是解决这一问题的一种方法。
LSTM网络
如前所述,在这个Keras LSTM教程中,我们将构建一个用于文本预测的LSTM网络。LSTM网络是一个循环神经网络,它用LSTM细胞块来代替我们的标准神经网络层。这些单元格有不同的组成部分,称为输入门、遗忘门和输出门——这些将在稍后详细解释。以下是LSTM单元格的图形表示:
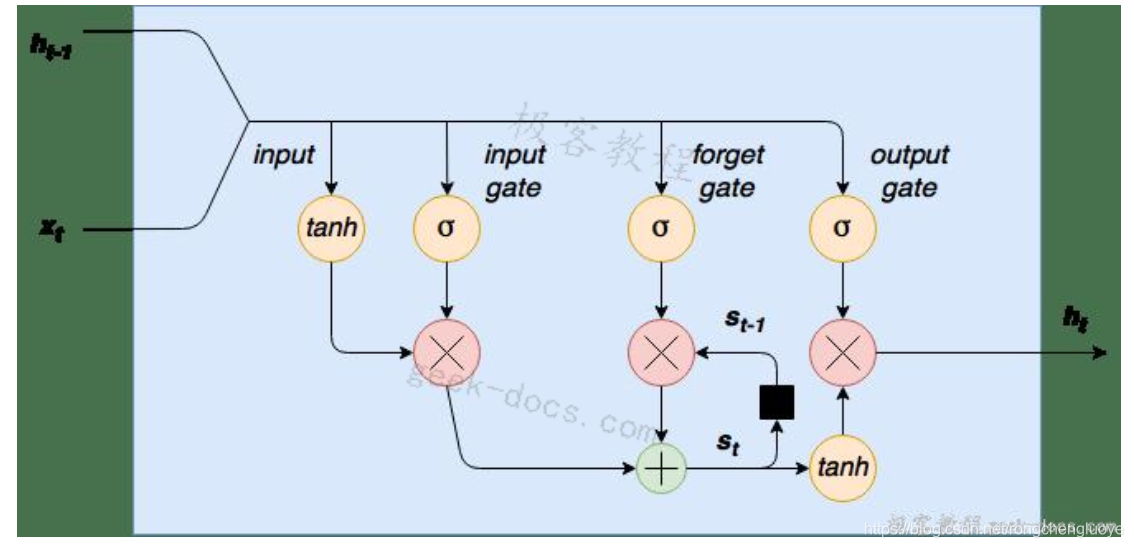
LSTM细胞图
首先请注意,在左侧,我们将新单词/序列值 连接到单元格 的前一个输出。这个组合输入的第一步是通过tanh层进行压缩。第二步是这个输入通过一个输入门。输入门是一层sigmoid激活节点,其输出乘以压扁的输入。这些输入门sigmoid可以“杀死”输入向量中不需要的任何元素。一个sigmoid函数输出0到1之间的值,因此可以将连接到这些节点的输入的权重训练为接近于零的输出值来“关闭”某些输入值(或者相反,接近于1的输出值来“传递”其他值)。
通过此单元格的数据流的下一步是内部状态/遗忘门循环。LSTM细胞有一个内部状态变量 。这个变量,滞后一个时间步长,即 被添加到输入数据中,创建一个有效的递归层。这个加法运算,而不是乘法运算,有助于降低梯度消失的风险。然而,这个递归循环是由遗忘门控制的——它的工作原理与输入门相同,但是它帮助网络学习哪些状态变量应该“记住”或“忘记”。
最后,我们有一个输出层tanh压扁函数,它的输出由一个输出门控制。这个门决定哪些值实际上可以作为单元格 的输出。
LSTM细胞的数学是这样的:
输入
首先,使用tanh激活函数将输入压缩到-1和1之间。这可以表示为:

其中
和
分别为输入和以前的单元输出的权重,
为输入偏差。注意,指数g不是提高的幂,而是表示这些是输入权重和偏置值(与输入门、遗忘门、输出门等相反)。
然后将这个压缩后的输入按元素乘上输入门的输出,如上所述,输入门是一系列sigmoid激活节点:

LSTM单元输入部分的输出由:
忘记门和状态循环
遗忘门输出表示为:
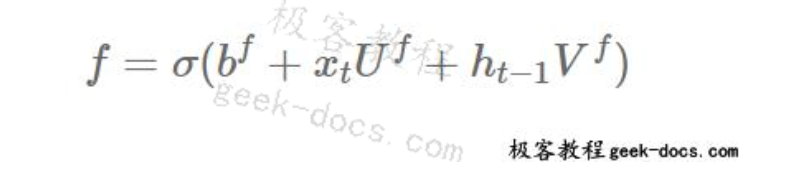
前一状态和遗忘门的元素乘积的输出表示为
∘ f。忘记门/状态循环阶段的输出为:
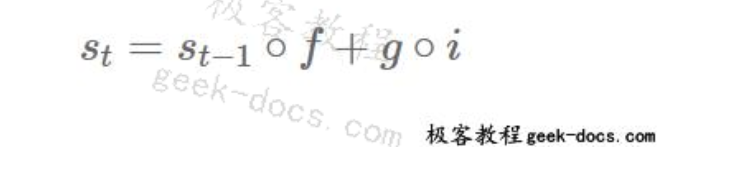
输出门
输出门表示为:
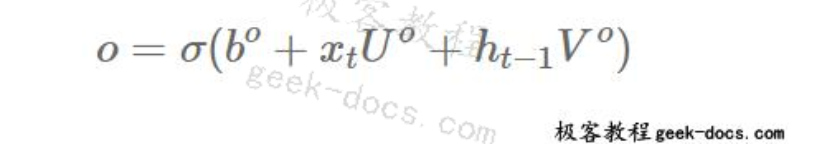
因此,经过tanh压扁后,单元格的最终输出为:
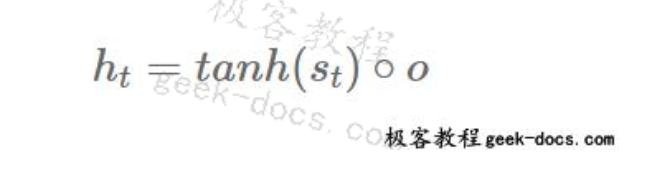
LSTM字嵌入和隐藏层大小
应该记住,在上面的所有数学中,我们处理的都是向量,即输入 和 不是单值标量,而是一定长度的向量。同样,所有的权值和偏置值分别是矩阵和向量。现在,你可能想知道,我们如何表示输入到神经网络的单词?答案是单词嵌入。在其他的教程中,我已经详细介绍了这一点,特别是在Python和TensorFlow中的Word2Vec word嵌入教程和Word2Vec Keras教程中。基本上,它涉及到取一个单词,并找到该单词的向量表示,它捕捉了该单词的一些含义。在Word2Vec中,这个意思通常是由上下文来量化的,也就是说,在向量空间中靠得很近的单词向量就是那些出现在句子中离同一个单词很近的单词。
向量这个词可以单独学习,就像在本教程中一样,也可以在您的Keras LSTM网络训练期间学习。在接下来的示例中,我们将设置所谓的嵌入层,将每个单词转换为有意义的单词向量。我们必须指定嵌入层的大小——这是每个单词所表示的向量的长度——通常在100-500之间。换句话说,如果嵌入层的大小为250,那么每个单词将由一个250长度的向量表示,i.e.[ , ,…, ]
LSTM隐藏层大小
我们通常将嵌入层输出的大小与LSTM单元中隐藏层的数量匹配起来。您可能想知道LSTM单元格中的隐藏层来自何处。在我的LSTM概览图中,我简单地显示了输入数据流经的“data rails”。然而,单元格中的每个sigmoid、tanh或隐藏状态层实际上是一组节点,其数量等于隐藏层的大小。因此,LSTM细胞中的每个“节点”实际上是一组正常的神经网络节点,就像密集连接的神经网络中的每一层一样。
Keras LSTM架构
本节将演示完整的LSTM体系结构,并展示我们在Keras中构建的网络体系结构。这将进一步阐明上面表达的一些思想,包括嵌入层和在网络中流动的张量大小。建议的架构如下:
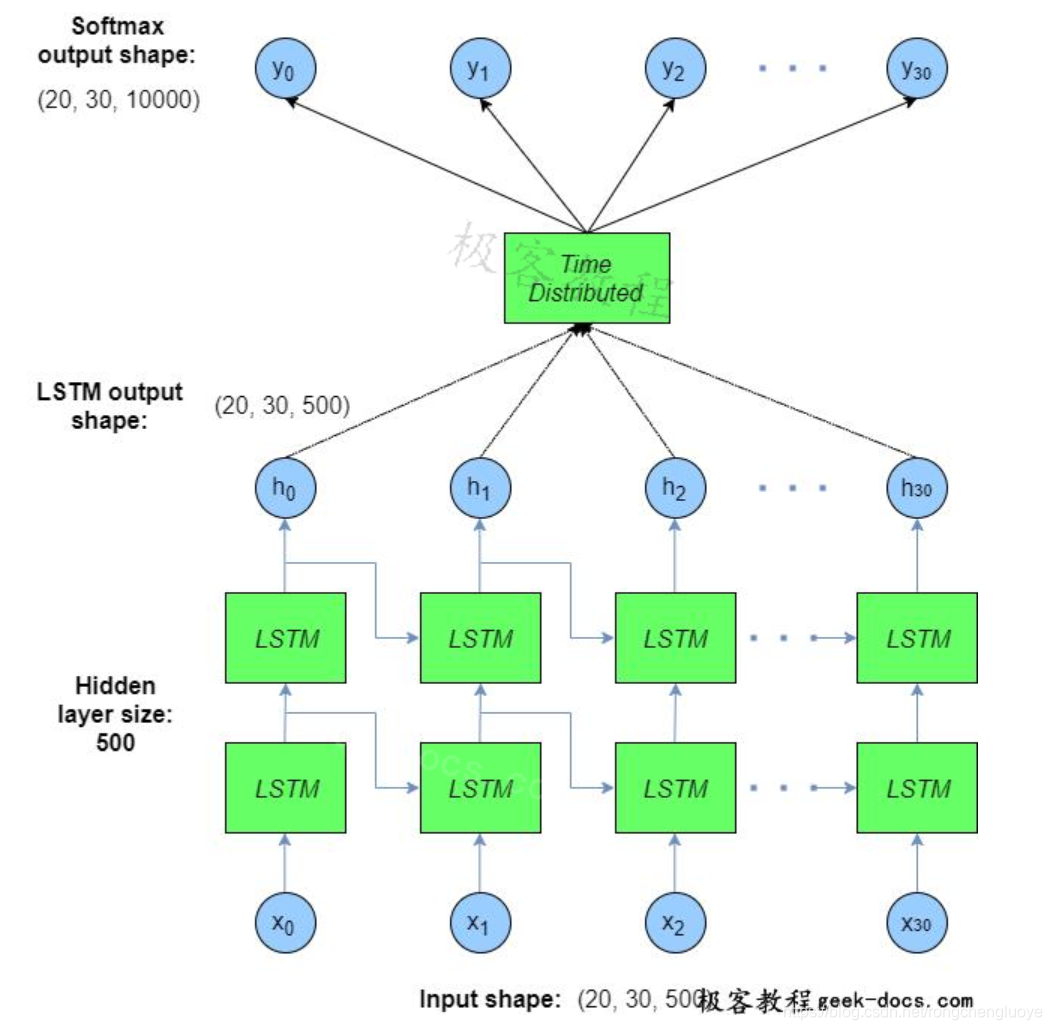
文本数据的输入形状按如下顺序排列:(批量大小、时间步长、隐藏大小)。换句话说,对于每个批次样本和每个单词的时间步长,都有一个500长度的嵌入单词向量来表示输入单词。这些嵌入向量将作为整体模型学习的一部分来学习。然后将输入数据输入到两个LSTM单元的“stacked”层(长度为500隐藏大小)中——在上面的图中,LSTM网络显示为在所有时间步骤上展开。这些展开单元格的输出仍然是(批大小、时间步长、隐藏大小)。
然后将这个输出数据传递到一个名为TimeDistributed的Keras层,下面将对此进行更全面的解释。最后,输出层应用了一个softmax激活。将该输出与每个批次的训练y数据进行比较,然后在Keras中从那里执行误差和梯度反向传播。在本例中,训练y数据是输入x个提前一个时间步长的单词——换句话说,在每个时间步中,模型都试图预测序列中的下一个单词。然而,它在每个时间步长都这样做——因此输出层的时间步长与输入层的时间步长相同。这一点稍后将更加清楚。
构建Keras LSTM模型
在本节中,将逐步介绍并讨论用于创建上面所示Keras LSTM体系结构的每一行代码。但是,我只简要讨论文本预处理代码,它主要使用TensorFlow站点上的代码。Keras LSTM教程的完整代码可以在这个站点的Github存储库中找到,名为keras_lstm.py。注意,您首先必须下载Penn Tree Bank (PTB)数据集,该数据集将用作培训和验证语料库。您需要更改Github代码中的data_path变量,以匹配下载数据的位置。
文本预处理代码
为了使文本数据具有正确的形状,以便输入Keras LSTM模型,必须为语料库中的每个惟一单词分配一个惟一的整数索引。然后需要按顺序重新构建文本语料库,但不是按照文本单词的顺序使用整数标识符。代码中执行此操作的三个函数是read_words、build_vocab和file_to_word_ids。我不会详细讨论这些函数,但基本上,它们首先将给定的文本文件分割为单独的单词和基于句子的字符(即句子末尾)。然后,每个惟一的单词被标识并分配一个惟一的整数。最后,将原始文本文件转换为这些惟一整数的列表,其中每个单词都用其新的整数标识符替换。这允许文本数据在神经网络中使用。
我创建的运行这些函数的load_data函数如下所示:
def load_data():
# get the data paths
train_path = os.path.join(data_path, "ptb.train.txt")
valid_path = os.path.join(data_path, "ptb.valid.txt")
test_path = os.path.join(data_path, "ptb.test.txt")
# build the complete vocabulary, then convert text data to list of integers
word_to_id = build_vocab(train_path)
train_data = file_to_word_ids(train_path, word_to_id)
valid_data = file_to_word_ids(valid_path, word_to_id)
test_data = file_to_word_ids(test_path, word_to_id)
vocabulary = len(word_to_id)
reversed_dictionary = dict(zip(word_to_id.values(), word_to_id.keys()))
print(train_data[:5])
print(word_to_id)
print(vocabulary)
print(" ".join([reversed_dictionary[x] for x in train_data[:10]]))
return train_data, valid_data, test_data, vocabulary, reversed_dictionary
要调用这个函数,我们可以运行:
train_data, valid_data, test_data, vocabulary, reversed_dictionary = load_data()
这个函数的三个输出分别是来自数据集的训练数据、验证数据和测试数据,但是每个单词在列表中都表示为整数。一些信息在load_data()运行期间打印出来,其中之一是print(train_data[:5])——这将生成以下输出:
[9970, 9971, 9972, 9974, 9975]
正如您所看到的,训练数据按照预期由一组整数组成。
接下来,输出词汇表只是文本语料库的大小。当单词被合并到训练数据中时,并没有考虑每一个单独的单词——相反,在自然语言处理中,文本数据通常被限制在最常见的N个单词中。在本例中,N =词汇量= 10,000。
最后,reversed_dictionary是一个Python字典,其中键是单词的惟一整数标识符,关联值是文本中的单词。这允许我们从模型将生成的预测整数词向后工作,并将它们翻译回实际文本。例如,下面的代码将train_data中的整数转换回随后打印的文本:print(” “.join([reversed_dictionary[x] for x in train_data[100:110]]))。这段代码产生:
workers exposed to it more than N years ago researchers
这就是关于文本预处理所需要的所有解释,所以让我们继续设置输入数据生成器,它将把样本输入到Keras LSTM模型中。
创建Keras LSTM数据生成器
在训练神经网络时,我们通常以小批量的方式将数据输入它们,称为mini-batches or just “batches”。Keras有一些方便的函数,可以从预先提供的Python迭代器/生成器对象中自动提取训练数据并将其输入模型。其中一个Keras函数称为fit_generator。fit_generator的第一个参数是我们将要创建的Python迭代器函数,它将用于在培训过程中提取成批的数据。Keras中的这个函数将处理所有的数据提取、模型的输入、执行梯度步骤、记录指标(如精度)和执行回调(这些将在稍后讨论)。Python迭代器函数需要有如下形式:
while True:
#do some things to create a batch of data (x, y)
yield x, y
在本例中,我创建了一个生成器类,其中包含实现这种结构的方法。这个类的初始化是这样的:
class KerasBatchGenerator(object):
def __init__(self, data, num_steps, batch_size, vocabulary, skip_step=5):
self.data = data
self.num_steps = num_steps
self.batch_size = batch_size
self.vocabulary = vocabulary
# this will track the progress of the batches sequentially through the
# data set - once the data reaches the end of the data set it will reset
# back to zero
self.current_idx = 0
# skip_step is the number of words which will be skipped before the next
# batch is skimmed from the data set
self.skip_step = skip_step
这里,KerasBatchGenerator对象将我们的数据作为第一个参数。注意,这些数据可以是训练、验证或测试数据——可以在机器学习开发周期的不同阶段(训练、验证调优、测试)创建和使用同一个类的多个实例。提供的下一个参数称为num_steps——这是我们将输入到网络的时间分布式输入层的单词数量。换句话说,这是模型将从中学习的一组单词,用于预测后面的单词。参数batch_size非常容易理解,我们已经讨论了词汇表(在本例中它等于10,000)。最后,skip_steps是每批训练样本之间要跳过的单词数量。为了更清楚地说明这一点,考虑下面这句话:
“The cat sat on the mat, and ate his hat. Then he jumped up and spat”
如果将num_steps设置为5,那么作为给定示例的输入数据使用的数据将是“The cat sat on the”。在本例中,由于我们通过模型预测序列中的下一个单词,对于每个时间步长,匹配的输出y或目标数据将是“cat sat on the mat”。最后,skip_steps是在下一个数据批处理之前要跳过的单词数量。在本例中,如果是skip_steps=num_steps,那么下一批的下5个输入单词将是“mat and ate his hat”。希望这能说得通。
需要讨论类初始化中的最后一项。这是变量current_idx,初始值为零。这个变量需要通过完整的数据集跟踪数据的提取——一旦在训练中使用了完整的数据集,我们需要将current_idx重置为零,以便再次从数据集的开始使用数据。换句话说,它基本上是一个数据集位置指针。
好的,现在我们需要讨论将在fit_generator期间调用的生成器方法.
def generate(self):
x = np.zeros((self.batch_size, self.num_steps))
y = np.zeros((self.batch_size, self.num_steps, self.vocabulary))
while True:
for i in range(self.batch_size):
if self.current_idx + self.num_steps >= len(self.data):
# reset the index back to the start of the data set
self.current_idx = 0
x[i, :] = self.data[self.current_idx:self.current_idx + self.num_steps]
temp_y = self.data[self.current_idx + 1:self.current_idx + self.num_steps + 1]
# convert all of temp_y into a one hot representation
y[i, :, :] = to_categorical(temp_y, num_classes=self.vocabulary)
self.current_idx += self.skip_step
yield x, y
在前几行中创建了x和y输出数组。变量x的大小很容易理解——它的第一个维度是我们在批处理中指定的样本数量。第二个维度是我们预测的单词数量。变量y的大小有点复杂。首先将批大小作为第一个维度,然后将时间步长作为第二个维度,如上所述。然而,y还有一个额外的三维空间,与我们的词汇表大小相同,在本例中为10,000。
原因是Keras LSTM网络的输出层将是一个标准的softmax层,它将为10,000个可能的单词分配一个概率。具有最高概率的单词将是预测单词——换句话说,Keras LSTM网络将从10,000个可能的类别中预测一个单词。因此,为了训练这个网络,我们需要为每个单词创建一个训练样本,每个单词的真单词位置都是1,其他9999个位置都是0。它将看起来像这样:(0,0,0,…,1,0,…,0,0)-这被称为一个热(one-hot)表示,或者,一个分类表示。因此,对于每个目标单词,需要有一个10000长度的向量,该向量中只有一个元素被设置为1。
好了,现在讲while True: yield x, y范型,这是前面讨论过的生成器。在第一行中,我们输入一个大小为batch_size的for循环,以填充批处理中的所有数据。接下来,需要测试一个条件,即是否需要重置current_idx指针。记住,对于每个训练样本,我们使用num_steps单词。因此,如果当前索引点加上num_steps大于数据集的长度,则需要将current_idx指针重置为零以重新开始数据集。
执行此检查后,输入数据将被使用到x数组中。所使用的数据索引非常容易理解——它是当前索引到current-index-plus-num_steps单词数量的当前索引。接下来,一个临时变量y填充的工作方式差不多,唯一的区别在于,起始点和结束点的数据消费提前1(例如+ 1)。如果这是困惑,请参阅“cat sat on the mat etc.”上面所讨论的例子。
最后一步是将每个示例中的每个目标单词转换为前面讨论过的一个 one-hot或分类表示。为此,可以使用Keras to_categorical函数。这个函数以一系列整数作为它的第一个参数,并向整数向量添加一个额外的维度——这个维度是每个整数的一个 one-hot表示。它的大小由传递给函数的第二个参数指定。假设我们有一系列形状(100,1)的整数,我们将它传递给to_categorical函数,并指定大小为10,000—返回的形状将是(100,10000)。例如,假设整数的序列/向量看起来像(0,1,2,3,…),to_categorical输出看起来像:
(1, 0, 0, 0, 0, ….)
(0, 1, 0, 0, 0, ….)
(0, 0, 1, 0, 0, ….)
and so on…
这里的“…”表示一大堆零,确保与每个整数关联的元素总数为10,000。希望这能说得通。
生成器函数的最后两行代码非常简单——首先,current_idx指针由前面讨论过的skip_step递增。最后一行生成一批x和y数据。
现在已经创建了生成器类,我们需要创建它的实例。如前所述,我们可以设置相同类的实例来对应于训练和验证数据。在代码中,如下所示:
train_data_generator = KerasBatchGenerator(train_data, num_steps, batch_size, vocabulary,
skip_step=num_steps)
valid_data_generator = KerasBatchGenerator(valid_data, num_steps, batch_size, vocabulary,
skip_step=num_steps)
现在Keras LSTM代码的输入数据已经设置好,可以运行了,现在是创建LSTM网络本身的时候了。
创建Keras LSTM结构
在本例中,将使用构建深度学习网络的顺序方法。这种构建网络的方法是在我的Keras教程中介绍的——用11行代码构建卷积神经网络。在Keras中构建网络的另一种方法是函数API,我在Word2Vec Keras教程中使用了它。基本上,顺序方法允许您轻松地将层堆叠到您的网络中,而不必过多担心流经模型的所有张量(及其形状)。然而,对于一些更复杂的层,您仍然需要保持头脑清醒,下面将对此进行讨论。在这个例子中,它看起来像这样:
model = Sequential()
model.add(Embedding(vocabulary, hidden_size, input_length=num_steps))
model.add(LSTM(hidden_size, return_sequences=True))
model.add(LSTM(hidden_size, return_sequences=True))
if use_dropout:
model.add(Dropout(0.5))
model.add(TimeDistributed(Dense(vocabulary)))
model.add(Activation('softmax'))
第一步是使用sequence()构造函数创建Keras模型。网络中的第一层,正如前面显示的架构图所示,是一个单词嵌入层。这将把我们的单词(由数据中的整数引用)转换成有意义的嵌入向量。这个Embedding() 层将词汇表的大小作为它的第一个参数,然后将生成的嵌入向量的大小作为下一个参数。最后,由于这一层是网络的第一层,我们必须指定输入的“长度”,即每个样本中的步骤/单词的数量。
跟踪网络中的张量形状是值得的——在本例中,嵌入层的输入是(batch_size, num_steps),输出是(batch_size, num_steps, hidden_size)。注意,在顺序模型中,Keras始终将批处理大小保持为第一个维度。它从Keras拟合函数(即本例中的fit_generator)接收批处理大小,因此它很少(从不?)包含在序列模型层的定义中。
下一层是我们两个LSTM层中的第一个。要指定LSTM层,首先必须提供LSTM单元中隐藏层中的节点数,例如忘记门层中的单元数、tanh压缩输入层中的单元数等等。上面代码中指定的下一个参数是return_sequences=True参数。这样做的目的是确保LSTM单元始终返回展开的LSTM单元的所有输出。如果省略了这个参数,LSTM单元将只提供来自最后一个时间步骤的LSTM单元的输出。下图显示了我的意思:
未完待续,请参考极客教程的深度学习专栏的《Keras LSTM教程》http://geek-docs.com/deep-learning/rnn/keras-lstm-tutorial.html 继续查看后文。请多提宝贵意见,感谢。