前言
目标检测算法可以分为两大类,一类是Faster R-CNN这种的,先生成候选区域,然后对这些候选区域进行分类与回归,这是将目标检测视为一种分类问题。一般这类算法的检测精度较高,但是检测速度有待提升,对于实时监测系统并不适用。另一类是YOLO这种整个检测过程由一个单一神经网络实现的,它将目标检测视为一种回归问题,检测速度虽然有所提升,但是检测精度不如第一类算法。尤其YOLO对于较小目标的检测并不友好。可以说是牺牲检测精度来提升检测速度。
本篇论文提出一种SSD的目标检测算法,在检测速度和精度上都有所提升。在提升检测速度上,去掉了生成候选框和特征提取阶段。在提升检测精度上,一是用一个卷积滤波器预测目标类别和边界框的偏移值,二是用一些分离的预测器(滤波器)来应对不同长宽比的检测器,即将这些滤波器应用到网络不同层得到的特征图上,以在不同尺度上进行目标检测。通过这些改变,当输入像素相对较低的图像时,也能得到很高的检测精度,进一步提升了检测速度。
本文做出的贡献
- 提出了一种新的目标检测算法SSD,它比同为single-shot的YOLO的检测速度和检测精度要高,事实上检测精度和需要生成候选框的目标检测算法差不多(比如Faster R-CNN)。
- SSD的核心部分是预测类别分数,和offset(边界框的真实预测值,由边界框相对于预设框的转换得到),这是通过在特征图上使用较小的卷积滤波器来实现的。
- 从不同尺度的特征图中生成不同尺度的预测值,并将这些预测值以不同的长宽比分离开来。这是提高检测精度最重要的一步。
- 通过2和3的设计,即使输入较低像素的图像,也能实现端到端的训练和较高的检测精度,实现了速度和精度之间的权衡。
- 实验在PASCAL VOC,COCO和ILSVRC上进行,对检测时间和检测精度与另外一些目标检测算法进行对比。
SSD的实现过程

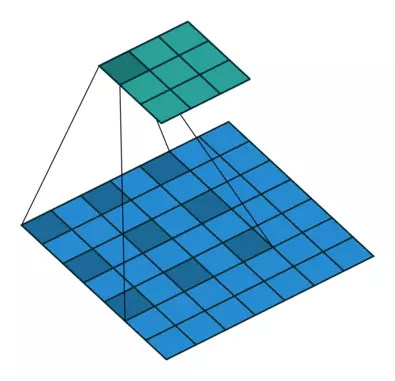
首先根据上图来说明几个概念:
- 特征图单元(feature map cell)。如上图(b)是一个8 × 8的特征图,那么每个小格就是一个特征图单元。接下来的部分把特征图单元称为cell。
- 真实框(ground truth box)。可以理解为目标所对应的唯一正确的那个框。
- 预设框(default box)。如上图(b)和(c),在每个cell中的虚线框就是预设框,可以看到在每个cell上都会有一组数目相同的预设框,它们的长宽比是不同的。预设框其实和Faster R-CNN中的anchor差不多。
- 边界框(bounding box)。每个预设框对应一个边界框,需要经过一个边界框相对于预设框的转换,得到边界框的真实预测值,也就是下面的内容里提到的offset。最终的检测结果来自于对边界框的处理。
SSD在训练时只需要一个输入图像和每个目标的真实框(ground truth box),如上图(a)中分别框住喵和汪的蓝色框和红色框。对于每个预设框,要预测offset,和每个目标的类别置信度((c1, c2, · · · , cp))。在训练时,首先将这些预设框与真实框匹配,比如上图(a)中,两个预设框分别与喵和汪的两个真实框匹配,这两个预设框就是正样本(positive),其他的预设框就是负样本(negative)。SSD的损失函数是位置损失函数(比如Fast R-CNN中的Smooth L1)和置信度损失函数(比如Softmax)的权重和。
SSD的具体设计
SSD基于前馈神经网络,该网络会生成一组大小固定的边界框,然后给边界框中的目标类实例打分,然后进行NMS(non-maximum suppression)操作来产生最终检测结果。下面介绍一下具体设计理念。
1.多尺度特征图
在基础网络后添加卷积层,这些卷积层的大小是逐层递减的,由此可以对不同尺度的特征图进行预测。每个层的卷积模型都是不同的。
2.用卷积层进行检测
在YOLO中是用全连接层来进行检测,但在SSD中,是用卷积层处理特征图来产生预测结果。对于一个m × n × p的特征图,用一个3 × 3 × p这样较小的卷积核来得到检测值。
3.预设框
在每个cell中设置了一组尺度或者长宽比不同的预设框,每个预设框相对于与其对应的cell的位置是固定的。对于每个cell的每个预设框,要预测各个类别的分数,和一个offset。
接下来说一下怎么计算offet。参考的是Faster R-CNN中根据anchor计算预测的边界框坐标的方法。在Faster R-CNN中,设
表示边界框的4个坐标经过转换后的预测值,(
,
,
,
)表示边界框,(
,
,
,
)表示anchor,计算如下:
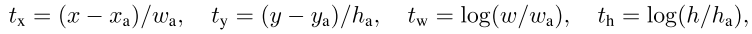
在SSD中,预设框其实和anchor差不多,那么我们可以根据预设框和边界框得到边界框的预测值,也就是offset。设预设框用
=(
,
,
,
)表示,边界框用
=(
,
,
,
)表示,那么参照Faster R-CNN中的式子,边界框的预测值
就为:
(
)
(
)
(
)
(
)
对于一个大小为m × n的特征图,每个cell设置k个预设框,每个预设框要预测c个类别分数,和有4个值的offset,那么整个特征图需要(c + 4)kmn个预测值,所以需要(c + 4)k个卷积核来完成这个特征图的检测过程。预设框其实和Faster R-CNN中的anchor类似,但不同的是预设框被应用在不同尺度的特征图上,而在Faster R-CNN中,anchor只被应用在一个特征图上。
SSD的网络结构

上图是SSD和YOLO的对比,可以看到SSD在不同尺度的特征图上进行检测,输入图像大小为300 × 300。SSD使用VGG16作为基础网络,将fc6和fc7两个全连接层转换为卷积层,移除了所有的dropout层和fc8层,将池化层pool5由原来的2 × 2 − s2变成3 × 3 − s1,这样做会增大池化后的特征图,减少损失信息,但却减小了感受野。为了配合这种变换,采用atrous algorithm,其实就是使用空洞卷积(dilated convolution),这样做不必减小特征图大小,也能使感受野增大。dilated conv的原始论文是
《MULTI-SCALE CONTEXT AGGREGATION BY DILATED CONVOLUTIONS》
接下来看一下论文中的一张图:

(a)图是3x3的1-dilated conv,和普通的卷积操作一样,每个小红点的感受野为3x3。(b)图是3x3的2-dilated conv,实际的卷积kernel size还是3x3,但是dilation rate为2,可以理解为在卷积时每隔1个(rate-1)像素“卷”一下,感受野变为7x7,在卷积时只有9个红色的点的权重不为0,其余都为0。 ©图是4-dilated conv操作,感受野为15x15。下面通过两个动图感受一下普通卷积和空洞卷积(动图来源https://github.com/vdumoulin/conv_arithmetic):
 普通卷积
普通卷积
 空洞卷积
空洞卷积
训练过程
在训练时最重要的是将真实框与预设框进行匹配,当匹配好之后,使用损失函数和向后传播进行端到端的训练。训练过程也包括如何选择预设框的尺度,hard negative mining和数据扩增。接下来对这几个问题以及损失函数进行说明。
1.如何匹配?
首先,对于每个真实框,哪个预设框和它的IoU最高,就用哪个预设框去匹配。这里对每个真实框只选出与它匹配的一个预设框。然后对于每个真实框,如果哪些预设框和它的IoU超过一个阈值(0.5),那么这些预设框依然可以和真实框匹配。也就是说,一个真实框可以有多个预设框与其进行匹配,这些可以匹配的为正样本,其余的为负样本。
2.正负样本的数量平衡
在上一步匹配之后,大多数的预设框都是负样本,这会导致正负样本间显著的不平衡。SSD使用hard negative mining方法,将负样本按照置信度误差进行降序排序,然后只选择误差较大的前几个作为负样本,这样可以使正负样本的比例接近1:3。这可以使优化更快,训练过程更稳定。
3.预设框的尺度和长宽比
不同层的特征图有不同大小的感受野。在SSD中,预设框不必和每层的实际感受野相对应。通过设计一系列预设框,特定的特征图负责特定尺度目标的检测。假设有m个特征图,那么每个特征图的预设框的尺度为:
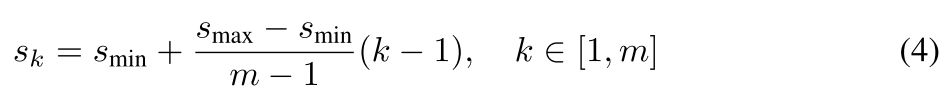
随着特征图大小降低,先验框尺度线性增加。其中
和
分别表示最底层和最高层的尺度,分别为0.2和0.9。
预设框还有不同的长宽比,表示为:
∈{1,2,3,1/2,1/3} 。
以此来计算预设框的宽度为:
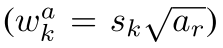
高度为:
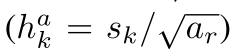
长宽比为1时,除了有一个尺度为
的预设框外,还有一个尺度为:
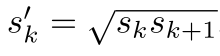
的预设框,因此每个cell中有6个预设框。
每个预设框的中心点为:
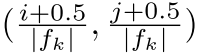
其中|
|是第k个特征图的大小,i,j∈[0,|
|)
通过将不同特征图的每个cell上的不同尺度和长宽比的预设框的预测值结合起来,基本上可以包含具有不同大小和形状的目标。还看汪和喵的那张图:

可以看到,汪与4 × 4特征图中的预设框相匹配,也就是(c)中的红色虚线框,而并没有和(b)中8 × 8特征图中的任一预设框相匹配。这是因为(b)中的预设框的尺度并不能和汪相匹配,因此在训练时相对于汪来说被视为负样本。
4.损失函数
SSD的损失函数是定位误差(loc)与置信度误差(conf)的加权和,通过交叉验证将权重项
设为1:
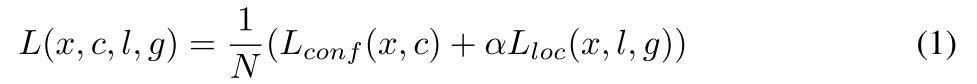
N是匹配的预设框的数目,即正样本的数目,如果N=0,就设损失函数为0。定义
{1,0},当
1时,表示第
个预设框与第
个真实框匹配,并且真实框中目标类别为
。通过之前的匹配策略,可以得到
的总数大于等于1。
是置信度的预测值,
是预设框对应的边界框的预测值(
的计算过程在上面),
是真实框的位置参数。
位置误差是Smooth L1损失函数,定义在
和
上:

置信度误差是softmax损失函数,计算多个类(
)的置信度误差:
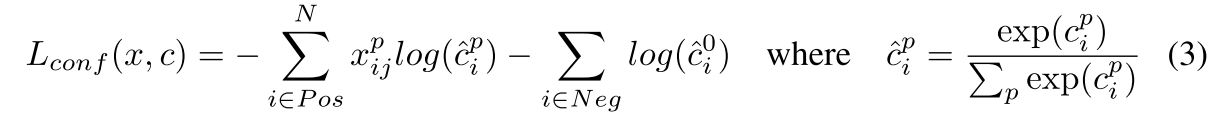
5.数据扩增
为了让模型可以更好的应对不同大小和形状的目标,每个训练图像通过以下几种操作来随机采样:
- 使用完整的原始输入图像;
- 采样一个patch,与目标的最小IoU为:0.1,0.3,0.5,0.7或0.9;
- 随机采样一个patch。
每个被采样的patch是原始图像大小的[0.1,1],长宽比在0.5和2之间。如果真实框的中心在patch中,保留patch与真实框重叠的部分。在采样步骤之后,每个patch的大小将固定,并以0.5的概率水平翻转。
