前言
目前的目标检测器会出现以下问题:
- NMS操作未能移除重复的检测结果。如下图所示,左:两个关于领带的检测结果,置信度很高,但IoU很低;右:对于图中的目标,检测结果是马和斑马,发生了重叠。

- 一些局部的判断未能充分利用上下文信息,也就是说,一些目标看起来与某个类别很相似,但如果代入目标所处的上下文环境中,会发现该目标完全不可能属于这个类别。如下图所示,左:在钟表里检测出香蕉和雨伞;右:在树的背景中检测出一个球体。

本文提出了一个模型,它可以使用图像中所有检测结果的上下文信息,来对先前检测器的检测结果进行重打分。每个检测结果由一个特征向量表示,包括原始置信度,预测的类别和bbox坐标。baseline检测器只使用视觉信息,本文的模型利用的是非视觉的高级上下文信息,比如类之间的关联性,目标的位置和大小。为了生成上下文表示以对检测结果进行重打分,本文使用了RNN和self-attention机制。作者认为本文的方法可以被广泛使用,因为它没有使用视觉或其他特定于检测器的特征。
通过该模型可以降低不符合上下文的检测结果,和重复的检测结果的置信度,同时保持其它符合要求的目标的高置信度,以实现准确的检测。如下图所示,false positive(sports ball, potted plant和umbrella)的置信度都被降低了,而true positive(suitcase和umbrella)的高置信度保持不变。

本文的贡献有:
- 给定固定匹配模式的预测bbox和gt bbox,使用重打分算法(rescoring algorithm)来使AP最大化;
- 通过考虑原始置信度,预测类别和bbox坐标,通过上下文重打分(contextual rescoring)方法为每个检测结果生成一个新的置信度。使用RNN和self-attention为每个检测结果生成一个上下文表示(contextual representation),并通过训练来回归使AP最大化的值。
实现方法
在保持预测的bbox的类别和位置不变的情况下,只改变置信度的值,也就是上下文重打分。如果重打分之后置信度为0,那么该检测结果是可以被抹去的。在给定一系列gt标注和检测结果的情况下,对检测结果重打分以使AP得到显著提升。
1. AP的计算
在各种IoU阈值(0.5,0.55,……,0.95)下分别为每个类计算AP,IoU阈值越高,与gt更接近的检测结果就能被视为true positive,从而获得更好的定位结果。为了计算AP,首先要通过为每个检测结果匹配一个gt,来确定true positive和false positive。下面以COCO数据集为例,COCO的匹配策略将检测结果按置信度降序排列,只有当满足以下条件时,才能将检测结果与IoU最高的gt匹配起来:
- 检测结果与gt的类别是相同的;
- 检测结果与gt之间的IoU大于或等于IoU阈值;
- 该gt还未和其它检测结果匹配。
如果没有一个可以匹配的gt,那么该检测结果就是false positive
然后计算精度-召回率的内插曲线,从最高置信度的检测结果开始,通过一组检测结果的当前召回率
对应于精度
的点,得到曲线
,然后通过将每次召回率对应的的精度重新分配为更高召回率处的最大精度,使该曲线单调递减:
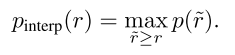
AP通过求101个等距召回率级别上内插精度的平均值,来近似精度-召回率曲线下的面积。给定类别
和IoU阈值
,AP可以计算为:
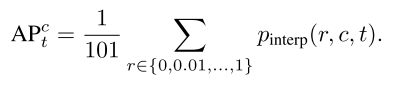
最终的AP是通过计算80个类别在10个不同IoU阈值上的AP的平均值得到的:
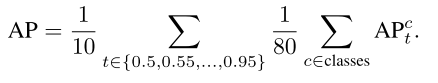
2. 如何使AP最大化
AP是由置信度得到的排序函数,为了通过重打分使AP得到提升,必须对检测结果重新排序,通过将更高的置信度分配给true positive而不是false positive来对检测结果重新排序。本文将AP的最大化分为两个步骤:
- 将检测结果与gt进行匹配;
- 为每个检测结果选择最优的置信度。
将检测结果与gt进行匹配
在本文的重打分方法中,要找到检测结果与gt之间的单一匹配。当一个匹配策略优先考虑检测结果的置信度时,如果最高置信度的检测结果不是局部最优,那么AP会受到影响。这是因为对于一个较低的IoU阈值来说,一个高置信度的检测结果可能是true positive,但如果Iou阈值变高,那么该检测结果有可能变成false positive。因此本文提出的启发式算法优先考虑检测结果与gt之间的IoU:

设已经被匹配的检测结果集为:
,已经被匹配的gt集为:
,
是检测结果,
是gt,该算法总结如下:
- 给定 和 ,最终要得到的是 和 之间的匹配 , ;
- 设IoU阈值为 ,从最大的IoU阈值开始,然后逐渐减小,即 ;
- 如果一个gt还没有被匹配,并且该gt与一组未被匹配的检测结果属于同一类别,且IoU大于等于阈值,那么将该gt与其中IoU最高的检测结果进行匹配。
选择最优的置信度
在将gt与最合适的检测结果进行匹配之后,接下来就是为检测结果选择最优的置信度,从而使有较高IoU的检测结果也能有较高的置信度。目标置信度
是true positive与匹配的gt之间的IoU,false positive的
为0:
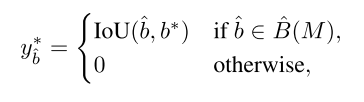
模型设计

上图是模型的整体结构:
- 1-2:一个目标检测器输出的一系列检测结果;
- 3:检测结果被映射到一个特征序列 中,也就是从每个检测结果中提取出一个特征向量,包括置信度,预测的类别和bbox坐标;
- 4:将特征向量送入RNN和self-attention中进行处理;
- 5:得到新的置信度。
1. 特征提取
图像中每个检测结果的特征向量包括原始置信度,预测的类别和bbox坐标,所有的特征向量一起形成了检测结果集的上下文表示。第
个检测结果的特征向量为:
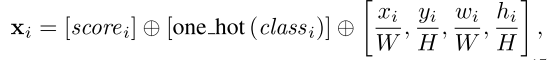
其中
表示向量的连结,
,
是检测结果的bbox的左上角的坐标,
和
分别表示bbox的宽和高。
和
表示检测结果的置信度和类别。其中one-hot方程将类别编码为一个one-hot向量。检测结果根据图像进行分组,然后被映射到特征序列中,根据置信度进行降序排序。序列还要被填充至长度为100。
2. RNN
该模型使用双向堆叠GRU(bidirectional stacked GRU)来计算两个大小为 的隐藏状态 和 ,分别对应于前向和后向序列,然后这些隐藏状态被连结起来以生成大小为 的状态向量 。将 个GRU层堆叠起来以产生更深的模型。双向模型允许每个检测结果的表示,是序列中过去和未来目标的函数。
3. self-attention
使用self-attention来处理检测结果之间的长距离依赖关系,这些依赖关系仅使用RNN是很难捕获的。对于每个元素
,在给定序列中所有隐藏向量的平均值的情况下,由一个alignment score进行加权,self-attention将整个序列概括为一个上下文向量
:
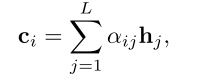
其中
是序列在填充之前的长度,
是元素
的隐藏向量,
衡量的是
和
之间的alignment,是一个权重,是通过在alignment score上进行softmax操作得到的:
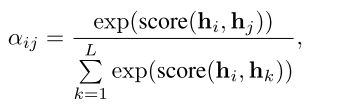
其中
是一个打分函数,衡量的是
和
之间的alignment,使用缩放的点积函数来衡量alignment:
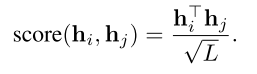
3. 回归器
使用一个多层感知器(MLP)来为每个检测结果重打分后的置信度预测一个值。回归器的输入是GRU的隐藏向量 的连结,和self-attention的上下文向量 ,回归器的输出是0到1之间的一个分数。回归器的结构包括一个大小为 并且带有ReLU激活函数的线性层,后跟一个大小为 并且带有sigmoid函数的线性层。
4. 损失函数
本文针对AP最大化的目标,将重打分公式化为回归,使用平方误差:
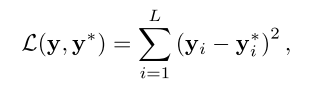
其中
是重打分过的置信度,
是目标序列。
结论
本文将上下文信息融入目标检测中,这里的上下文我感觉是从检测结果中提取出的特征向量,包括置信度,类别和bbox坐标。在匹配gt时是根据IoU的,即哪个检测结果与gt的IoU最大,它俩之间就来一个匹配。同时还要对检测结果的置信度进行重打分,可以匹配gt的检测结果,就让它的置信度大一点;不能匹配gt的检测结果,就让它的置信度小一点,从而使AP能够最大化。算是对two-stage目标检测器的一个加强吧。
