Thompson Sampling for Contextual Bandits with Linear Payoffs(线性收益)
参考论文:
Agrawal S , Goyal N . Thompson Sampling for Contextual Bandits with Linear Payoffs[J]. 2012.
摘要
有关Thompson Sampling理论性能的许多问题仍未解决
本文设计和分析
- Thompson Sampling algorithm
- 随机 contextual multi-armed bandit 问题(上下文信息由自适应的adversary提供)
- 线性收益函数
Introduction
MAB问题主要用于为许多顺序决策问题中固有的勘探/开发权衡建模。
1. contextual MAB
在这个问题中,在每轮T轮中,一个learner会从N个action中选择一个最好的,N个action称为N个arms。
在选择要哪个arms之前,learner会看到与每个arm i相 关联的d维特征向量bi,称为“上下文”。
learner将这些特征向量与她过去使用过的arm的特征向量和reward一起使用,以选择在当前回合中要选择的arm。
随着时间的流逝,learner的目标是收集有关特征向量和reward如何相互关联的足够信息,以便她可以确定地通过观察特征向量来预测哪条arm可能会提供最佳reward。
learner与一类预测变量竞争,其中每个预测变量都接受特征向量并预测哪条arm会获得最佳回报。如果learner可以保证在事后预测中所做的工作与最佳预测者的预测几乎一样(即,regret很低——用于评判该learner(算法)的有效性),那么该learner可以成功地与该类竞争。
pridictor由d为参数
μˉ来定义,然后根据
biTμˉ来将arms排序
即:假设有个未知参数
μ,则每个arm对应的reward为
biTμˉ,学习者的目标就是学习该未知参数
μ
2. Thompson sampling(TS)
基本思想是:假设每个arm的reward分布的基础参数具有简单的先验分布,并且在每个时间步长,根据该先验分布成为最佳arm的后验概率来选择arm
主要包含以下参数:
- 一组参数
μ
- 关于这些参数的先验分布
p(μˉ)
- 过去的观察结果D,由t-1时刻的上下文b,奖励r组成
- 似然函数
P(r∣b,μ~)
,即给定上下文b和参数
μ的情况下得到奖励的概率
- 后验分布
P(μ~∣D)∝P(D∣μ~)P(μ~),其中
P(D∣μ~)是似然函数
在每一轮中,TS根据具有最好参数的后验概率来选择arm。
一种简单的方法是使用后验分布为每个arm生成参数样本,然后选择生成最佳样本的arm。
使用高斯先验和高斯似然函数
在本文中,我们使用基于鞅的分析技术(novel martingale-based analysis techniques)来证明TS对具有线性收益函数的随机contextual bandits实现了高概率,接近最优的regret界限。
3.问题设置和算法描述
3.1 问题设置
- N个arms,每个arm i
- 时间t
- 上下文向量
biT(t)
- 要学习的参数
μ
- 时间t内选择的动作
a(t)
- 历史信息
Ht−1={a(τ),ra(τ)(τ),bi(τ),i=1,…,N,τ=1,…,t−1},包括t-1时刻之前已经选择的arm及其对应的rewards,和t-1时刻观察到的上下文向量
bi(τ)
给定
bi(t),时间t内arm i 的奖励是通过平均量
biT(t)的(未知)分布生成的,其中
μˉ∈Rd是一个固定但未知的参数:
E[ri(t)∣{bi(t)}i=1N,Ht−1]=E[ri(t)∣bi(t)]=bi(t)Tμ
- 时间t内最优的arm
a∗(t),
a∗(t)=argmaxibi(t)Tμ
-
Δi(t) 为时间t时最优arm和arm i的平均reward之间的差值:
Δi(t)=ba∗(t)(t)Tμ−bi(t)Tμ
则时间t内的regret定义为:
regret(t)=Δa(t)(t)
regret(t)=ra∗(t)(t)−ra(t)(t)
算法的目标是最小化时间T内总的regret
且假设(对所有t和i):
∥bi(t)∥≤1,∥μ∥≤1, and Δi(t)≤1
使得regret界限无标度。
3.2 Thompson Sampling 算法
使用高斯似然函数和高斯先验设计汤普森采样算法。
更精确地,假设在给定上下文
bi(t)和参数
μ的情况下,在时间t处:
-
ri(t)的似然由高斯分布
N(bi(t)Tμ,v2)的概率密度函数给出。(v是给定的值)
令:
B(t)μ^(t)=Id+τ=1∑t−1ba(τ)(τ)ba(τ)(τ)T=B(t)−1(τ=1∑t−1ba(τ)(τ)ra(τ)(τ))
-
μ 的先验分布服从~
N(μ^(t),v2B(t)−1),则TS算法需要从
N(μ^(t),v2B(t)−1)分布中采样,得到采样值
μ~(t);
μ^(t)是要学习的参数
μ在时间t内的均值。
- 则t+1时刻的后验分布可根据
Pr(μ~∣ri(t))∝Pr(ri(t)∣μ~)P(μ~)计算得出。
1)算法一
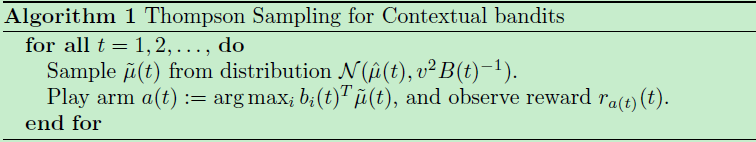
是对每个时间t内的所有arm,从所给分布采样整体的参数miu
然后再对每个arm i 求reward:
bi(t)Tμ~(t)
2)算法二

是在每个时隙t内,针对每个arm t 直接根据奖励的分布采样得到每个arm的奖励采样值。
3)算法三

首先所有上下文向量以及要学习的参数都是独立于每个arm i的,有新的定义:
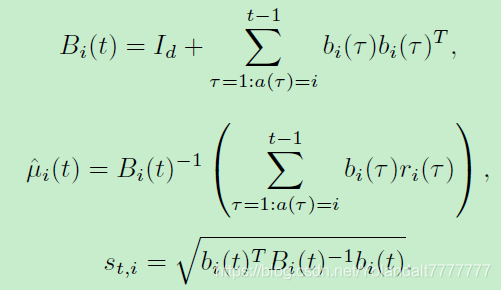
即不同的arm会有不同的参数
μ,该算法会为每个arm i 的均值
μi(t)和
Bi(t)维持单独的估计。
