Title:Seeing Through Fog Without Seeing Fog:Deep Multimodal Sensor Fusion in Unseen Adverse Weather
看透雾而不见雾:在看不见的不利天气下进行深度多模态传感器融合
Abstract:
The fusion of multimodal sensor streams,such as cam-era,lidar,and radar measurements,plays a critical role inobject detection for autonomous vehicles,which base theirdecision making on these inputs.While existing methodsexploit redundant information in good environmentalconditions,they fail in adverse weather where the sensorystreams can be asymmetrically distorted.These rare“edge-case”scenarios are not represented in available datasets,and existing fusion architectures are not designed tohandle them.To address this challenge we present a novelmultimodal dataset acquired in over 10,000 km of drivingin northern Europe.Although this dataset is the first largemultimodal dataset in adverse weather,with 100k labels forlidar,camera,radar,and gated NIR sensors,it does not fa-cilitate training as extreme weather is rare.To this end,wepresent a deep fusion network for robust fusion without alarge corpus of labeled training data covering all asymmet-ric distortions.Departing from proposal-level fusion,wepropose a single-shot model that adaptively fuses features,driven by measurement entropy.We validate the proposedmethod,trained on clean data,on our extensive validationdataset.Code and data are available here https://github.com/princeton-computational-imaging/SeeingThroughFog.
摘要:多模态传感器流的融合,如摄像机、激光雷达和雷达测量,在自动驾驶车辆的目标检测中起着至关重要的作用,它们的决策基于这些输入。现有的方法在良好的环境条件下利用冗余信息,但在恶劣天气下感知流会发生不对称失真。这些罕见的"边缘案例"场景并没有在可用的数据集中表现出来,现有的融合架构也没有对其进行处理。为了应对这一挑战,我们提出了一个在北欧超过10,000公里的驾驶中获得的新的多模态数据集。尽管该数据集是第一个在恶劣天气下的大型多模态数据集,具有100k个标签( forlidar、摄像头、雷达和门控NIR传感器),但由于极端天气很少,不便于训练。为此,我们提出了一种深度融合网络,用于鲁棒融合,而不需要覆盖所有非对称失真的大量有标签训练数据。从建议级融合出发,我们提出了一种由测量熵驱动的自适应融合特征的单样本模型。我们在我们广泛的验证数据集上对提出的方法进行验证,在干净的数据上进行训练。代码和数据见https://github.com/princeton-computational-imaging/SeeingThroughFog.
1.Introduction
Object detection is a fundamental computer vision prob-lem in autonomous robots,including self-driving vehiclesand autonomous drones.Such applications require 2D or3D bounding boxes of scene objects in challenging real-world scenarios,including complex cluttered scenes,highlyvarying illumination,and adverse weather conditions.Themost promising autonomous vehicle systems rely on redun-dant inputs from multiple sensor modalities[58,6,73],in-cluding camera,lidar,radar,and emerging sensor such asFIR[29].A growing body of work on object detection us-ing convolutional neural networks has enabled accurate 2Dand 3D box estimation from such multimodal data,typicallyrelying on camera and lidar data[64,11,56,71,66,42,35].While these existing methods,and the autonomous sys-tem that performs decision making on their outputs,per-form well under normal imaging conditions,they fail inadverse weather and imaging conditions.This is becauseexisting training datasets are biased towards clear weatherconditions,and detector architectures are designed to relyonly on the redundant information in the undistorted sen-sory streams.However,they are not designed for harsh sce-narios that distort the sensor streams asymmetrically,seeFigure.1.Extreme weather conditions are statistically rare.For example,thick fog is observable only during 0.01% of typical driving in North America,and even in foggy re-gions,dense fog with visibility below 50 m occurs only upto 15 times a year[61].Figure 2 shows the distributionof real driving data acquired over four weeks in Swedencovering 10,000 km driven in winter conditions.The nat-urally biased distribution validates that harsh weather sce-narios are only rarely or even not at all represented in avail-able datasets[65,19,58].Unfortunately,domain adaptationmethods[44,28,41]also do not offer an ad-hoc solution asthey require target samples,and adverse weather-distorteddata are underrepresented in general.Moreover,existingmethods are limited to image data but not to multisensordata,e.g.including lidar point-cloud data.
1. 介绍
目标检测是自主机器人中的一个基本计算机视觉问题,包括自动驾驶车辆和自主无人机。这类应用在具有挑战性的现实场景中需要场景对象的2D或3D边界框,包括复杂的杂乱场景、高度变化的光照和恶劣的天气条件。最有前途的自动驾驶系统依赖于多个传感器模态[ 58、6、73]的冗余输入,包括相机、激光雷达、雷达和红外等新兴传感器[ 29 ]。越来越多的使用卷积神经网络进行目标检测的工作已经能够从这些多模态数据中准确地估计2D和3D框,通常依赖于相机和激光雷达数据[ 64、11、56、71、66、42、35]。虽然这些现有的方法,以及对其输出执行决策的自治系统,在正常成像条件下表现良好,但在恶劣天气和成像条件下失败。这是因为现有的训练数据集偏向于晴朗的天气状况,而检测器架构的设计仅依赖于未失真感知流中的冗余信息。然而,它们并不是针对不对称地扭曲传感器流的恶劣场景而设计的,见图1。极端天气条件在统计上是罕见的。例如,只有在0.01 % 在北美地区,甚至在雾区,能见度低于50 m的浓雾每年仅发生15次期间才能观测到浓雾。图2显示了瑞典在冬季驾驶10000公里的情况下,四周内获得的实际驾驶数据的分布情况。自然偏态分布验证了恶劣天气场景在可用数据集[ 65、19、58]中只有很少甚至根本没有表现。不幸的是,域适应方法[ 44、28、41]也没有提供一个临时的解决方案,因为它需要目标样本,而不利的天气失真数据通常是代表性不足的。此外,现有方法仅限于图像数据,而不适用于多传感器数据,如激光雷达点云数据。
Existing fusion methods have been proposed mostly forlidar-camera setups[64,11,42,35,12],as a result of thelimited sensor inputs in existing training datasets[65,19,58].These methods do not only struggle with sensor distor-tions in adverse weather due to the bias of the training data.Either they perform late fusion through filtering after inde-pendently processing the individual sensor streams[12],orthey fuse proposals[35]or high-level feature vectors[64].The network architecture of these approaches is designedwith the assumption that the data streams are consistent andredundant,i.e.an object appearing in one sensory streamalso appears in the other.However,in harsh weather condi-tions,such as fog,rain,snow,or extreme lighting condition,including low-light or low-reflectance objects,multimodalsensor configurations can fail asymmetrically.For exam-ple,conventional RGB cameras provide unreliable noisymeasurements in low-light scene areas,while scanning li-dar sensors provide reliable depth using active illumina-tion.In rain and snow,small particles affect the color im-age and lidar depth estimates equally through backscatter.Adversely,in foggy or snowy conditions,state-of-the-artpulsed lidar systems are restricted to less than 20 m rangedue to backscatter,see Figure 3.While relying on lidarmeasurements might be a solution for night driving,it isnot for adverse weather conditions.
由于现有的训练数据集[ 65、19、58]中传感器的输入有限,现有的融合方法大多是针对相机-相机设置提出的。这些方法不仅在恶劣天气下由于训练数据的偏差而与传感器故障作斗争。它们要么在独立处理各个传感器流后通过滤波进行后期融合[ 12 ],要么融合提案[ 35 ]或高层特征向量[ 64 ]。这些方法的网络结构是在数据流是一致且冗余的假设下设计的,即出现在一个感知流中的对象也出现在另一个感知流中。然而,在恶劣的天气条件下,如雾、雨、雪或极端光照条件下,包括低光照或低反射物体,多模态传感器配置可能会不对称地失效。例如,传统的RGB相机在低光照场景区域提供不可靠的噪声测量,而扫描激光雷达传感器通过主动照明提供可靠的深度。在雨和雪中,小粒子通过后向散射对彩色图像和激光雷达深度估计产生同等影响。相反,在雾天或雪天条件下,由于后向散射的影响,先进的脉冲激光雷达系统被限制在20 m以内,见图3。虽然依靠激光雷达测量可能是夜间驾驶的一种解决方案,但它不适用于恶劣的天气条件。
In this work,we propose a multimodal fusion method forobject detection in adverse weather,including fog,snow,and harsh rain,without having large annotated trainingdatasets available for these scenarios.Specifically,we han-dle asymmetric measurement corruptions in camera,lidar,radar,and gated NIR sensor streams by departing from ex-isting proposal-level fusion methods:we propose an adap-tive single-shot deep fusion architecture which exchangesfeatures in intertwined feature extractor blocks.This deepearly fusion is steered by measured entropy.The proposedadaptive fusion allows us to learn models that generalizeacross scenarios.To validate our approach,we address thebias in existing datasets by introducing a novel multimodaldataset acquired on three months of acquisition in northernEurope.This dataset is the first large multimodal driving dataset in adverse weather,with 100k labels for lidar,cam-era,radar,gated NIR sensor,and FIR sensor.Although theweather-bias still prohibits training,this data allows us tovalidate that the proposed method generalizes robustly tounseen weather conditions with asymmetric sensor corrup-tions,while being trained on clean data.Specifically,we make the following contributions:
在本文中,我们提出了一种多模态融合方法,用于在雾、雪和恶劣降雨等恶劣天气下进行目标检测,而无需为这些场景提供大量有标注的训练数据集。具体来说,我们通过与现有的建议级融合方法不同,处理相机、激光雷达、雷达和门控NIR传感器流中的不对称测量损坏:我们提出了一种自适应的单样本深度融合架构,在相互交织的特征提取器块中交换特征。这种深度早期融合是由测量的熵引导的。提出的自适应融合允许我们学习跨场景泛化的模型。为了验证我们的方法,我们通过介绍一个新的多模态数据集在欧洲北部的三个月的采集来解决现有数据集的偏见。该数据集是第一个恶劣天气下的大型多模态驾驶数据集,具有100k个标签,用于激光雷达、摄像机、雷达、门控NIR传感器和FIR传感器。虽然天气偏差仍然禁止训练,但这一数据使我们能够验证所提出的方法在干净数据上训练的同时,对具有不对称传感器故障的未知天气条件具有鲁棒性。
具体而言,我们做出以下贡献:
•We introduce a multimodal adverse weather datasetcovering camera,lidar,radar,gated NIR,and FIR sen-sor data.The dataset contains rare scenarios,such asheavy fog,heavy snow,and severe rain,during morethan 10,000 km of driving in northern Europe.
•我们介绍了一个涵盖相机、激光雷达、雷达、门控NIR和FIR传感器数据的多模态不良天气数据集。该数据集包含了在北欧超过10,000公里的驾驶过程中罕见的场景,如大雾、大雪和暴雨。
•We propose a deep multimodal fusion network whichdeparts from proposal-level fusion,and instead adap-tively fuses driven by measurement entropy.
•我们提出了一个深度多模态融合网络,它脱离了提案级融合,而是由测量熵驱动的自适应融合。
•We assess the model on the proposed dataset,validat-ing that it generalizes to unseen asymmetric distor-tions.The approach outperforms state-of-the-art fu-sion methods more than 8%AP in hard scenarios in-dependent of weather,including light fog,dense fog,snow,and clear conditions,and it runs in real-time.
•我们在提出的数据集上评估了该模型,验证了其泛化为看不见的非对称扭曲。该方法在与天气无关的硬场景中,包括轻雾、浓雾、雪和晴朗条件下,优于现有的融合方法8 %以上的AP,并且实时运行。

2.Related
WorkDetection in Adverse Weather Conditions Over the lastdecade,seminal work on automotive datasets[5,14,19,16,65,9]has provided a fertile ground for automotiveobject detection[11,8,64,35,40,20],depth estima-tion[18,39,21],lane-detection[26],traffic-light detec-tion[32],road scene segmentation[5,2],and end-to-enddriving models[4,65].Although existing datasets fuel thisresearch area,they are biased towards good weather con-ditions due to geographic location[65]and captured sea-son[19],and thus lack severe distortions introduced by rarefog,severe snow,and rain.A number of recent worksexplore camera-only approaches in such adverse condi-tions[51,7,1].However,these datasets are very small withless than 100 captured images[51]and limited to camera-only vision tasks.In contrast,existing autonomous driv-ing applications rely on multimodal sensor stacks,includ-ing camera,radar,lidar,and emerging sensor,such as gatedNIR imaging[22,23],and have to be evaluated on thou-sands of hours of driving.In this work,we fill this gap andintroduce a large scale evaluation set in order to develop afusion model for such multimodal inputs that is robust tounseen distortions.
近十年来,在汽车数据集[ 5、14、19、16、65、9]上的开创性工作为汽车目标检测[ 11、8、64、35、40、20]、深度估计[ 18、39、21]、车道线检测[ 26 ]、交通灯检测[ 32 ]、道路场景分割[ 5、2]和端到端驾驶模型[ 4、65]提供了肥沃的土壤。尽管现有的数据集为本研究区域提供了燃料,但由于地理位置[ 65 ]和捕获的季节[ 19 ],它们偏向于良好的天气状况,因此缺乏由罕见的雾、严重的雪和雨引入的严重失真。最近的一些工作探讨了在这种不利条件下仅使用相机的方法。然而,这些数据集非常小,只有不到100张拍摄图像[ 51 ],并且仅限于相机视觉任务。相比之下,现有的自动驾驶应用依赖于多模态传感器栈,包括相机、雷达、激光雷达和新兴传感器,如门控近红外成像[ 22、23],并且需要在数千小时的驾驶时间内进行评估。在本工作中,我们填补了这一空白,并引入了一个大规模的评价集,以便为这些多模态输入开发一个对不可观测的失真具有鲁棒性的融合模型。
Data Preprocessing in Adverse Weather A large body ofwork explores methods for the removal of sensor distor-tions before processing.Especially fog and haze removalfrom conventional intensity image data have been exploredextensively[67,70,33,53,36,7,37,46].Fog results ina distance-dependent loss in contrast and color.Fog re-moval methods have not only been suggested for display application[25],it has also been proposed as preprocess-ing to improve the performance of downstream semantictasks[51].Existing fog and haze removal methods rely onscene priors on the latent clear image and depth to solve theill-posed recovery.These priors are either hand-crafted[25]and used for depth and transmission estimation separately,or they are learned jointly as part of trainable end-to-endmodels[37,31,72].Existing methods for fog and visibilityestimation[57,59]have been proposed for camera driver-assistance systems.Image restoration approaches have alsobeen applied to deraining[10]or deblurring[36].
数据恶劣天气下的预处理大量工作探索了在处理前去除传感器故障的方法。特别是对传统强度图像数据中的雾和霾去除进行了广泛的探索。雾导致对比度和颜色的距离依赖性损失。去雾方法不仅被提出用于显示应用[ 25 ],也被提出作为预处理来提高下游语义任务的性能[ 51 ]。现有的去雾和去雾方法依赖于潜在清晰图像和深度的场景先验来解决不适定恢复问题。这些先验要么是手工设计的[ 25 ],分别用于深度和传输估计,要么作为可训练端到端模型[ 37、31、72]的一部分共同学习。现有的雾和能见度估计方法[ 57、59]已经被提出用于相机辅助驾驶系统。图像复原方法也被应用于去雨[ 10 ]或去模糊[ 36 ]。
Domain Adaptation Another line of research tackles theshift of unlabeled data distributions by domain adaptation[60,28,50,27,69,62].Such methods could be appliedto adapt clear labeled scenes to demanding adverse weatherscenes[28]or through the adaptation of feature representa-tions[60].Unfortunately,both of these approaches struggleto generalize,because,in contrast to existing domain trans-fer methods,weather-distorted data in general,not only la-beled data,is underrepresented.Moreover,existing meth-ods do not handle multimodal data.
领域自适应 另一类研究通过领域自适应[ 60、28、50、27、69、62]解决无标签数据分布的偏移问题。这类方法可以应用于将清晰的标注场景适应苛刻的恶劣天气场景[ 28 ]或通过特征表示的自适应[ 60 ]。不幸的是,这两种方法都很难推广,因为与现有的域转移方法相比,通常情况下,天气失真数据,而不仅仅是标记数据,是代表性不足的。此外,现有方法没有处理多模态数据。
Multisensor Fusion Multisensor feeds in autonomous ve-hicles are typically fused to exploit varying cues in the mea-surements[43],simplify path-planning[15],to allow forredundancy in the presence of distortions[47],or solvefor joint vision tasks,such as 3D object detection[64].Existing sensing systems for fully-autonomous driving in-clude lidar,camera,and radar sensors.As large automotivedatasets[65,19,58]cover limited sensory inputs,existingfusion methods have been proposed mostly for lidar-camerasetups[64,55,11,35,42].Methods such as AVOD[35]andMV3D[11]incorporate multiple views from camera and li-dar to detect objects.They rely on the fusion of pooledregions of interest and hence perform late feature fusionfollowing popular region proposal architectures[49].In adifferent line of research,Qi et al.[48]and Xu et al.[64]propose a pipeline model that requires a valid detection out-put for the camera image and a 3D feature vector extractedfrom the lidar point-cloud.Kim et al.[34]propose a gatingmechanism for camera-lidar fusion.In all existing meth-ods,the sensor streams are processed separately in the fea-ture extraction stage,and we show that this prohibits learn-ing redundancies,and,in fact,performs worse than a singlesensor stream in the presence of asymmetric measurementdistortions.
多传感器融合在无人驾驶车辆中的多传感器馈源通常是融合的,以利用测量中的不同线索[ 43 ],简化路径规划[ 15 ],在存在失真时允许冗余[ 47 ],或解决联合视觉任务,如3D目标检测[ 64 ]。现有的用于全自主驾驶的传感系统包括激光雷达、摄像头和雷达传感器。由于大型汽车数据集[ 65、19、58]涵盖的感官输入有限,现有的融合方法大多针对激光雷达-相机系统[ 64、55、11、35、42]提出。AVOD [ 35 ]和MV3D [ 11 ]等方法融合了相机和激光雷达的多个视角来检测物体。它们依赖于感兴趣区域的融合,因此按照流行的区域建议架构进行后期的特征融合[ 49 ]。在不同的研究路线中,Qi等[ 48 ]和Xu等[ 64 ]提出了一种管道模型,该模型需要相机图像的有效检测输出和从激光雷达点云中提取的三维特征向量。Kim等人[ 34 ]提出了一种相机-眼睑融合的选通机制。在所有现有的方法中,传感器流在特征提取阶段是分开处理的,我们表明这禁止了学习冗余,并且,事实上,在存在不对称测量失真的情况下,表现比单个传感器流差。
3.Multimodal Adverse Weather Dataset
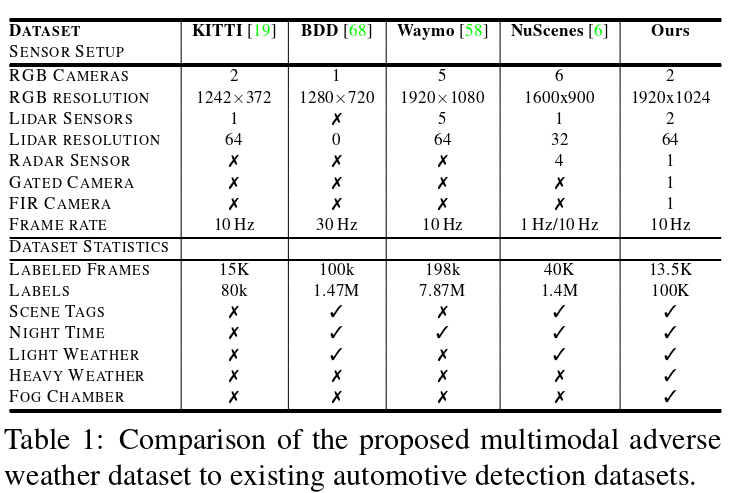
To assess object detection in adverse weather,we haveacquired a large-scale automotive dataset providing 2D and3D detection bounding boxes for multimodal data with afine classification of weather,illumination,and scene typein rare adverse weather situations.Table 1 compares our dataset to recent large-scale automotive datasets,such as theWaymo[58],NuScenes[6],KITTI[19]and the BDD[68]dataset.In contrast to[6]and[68],our dataset containsexperimental data not only in light weather conditions butalso in heavy snow,rain,and fog.A detailed description ofthe annotation procedures and label specifications is givenin the supplemental material.With this cross-weather an-notation of multimodal sensor data and broad geographi-cal sampling,it is the only existing dataset that allows forthe assessment of our multimodal fusion approach.In thefuture,we envision researchers developing and evaluatingmultimodal fusion methods in weather conditions not cov-ered in existing datasets.
3 .多模态不利天气数据集
为了评估恶劣天气下的目标检测,我们获得了一个大规模的汽车数据集,为多模态数据提供2D和3D检测边界框,在罕见的恶劣天气情况下对天气、光照和场景类型进行精细分类。表1比较了我们的 数据集与最近的大规模汽车数据集,如Waymo [ 58 ],NuScenes [ 6 ],KITTI [ 19 ]和BDD [ 68 ]数据集。与[ 6 ]和[ 68 ]不同的是,我们的数据集不仅包含了小天气条件下的实验数据,而且包含了大雪、大雨和大雾的实验数据。补充材料中给出了注释步骤和标签规范的详细描述。通过这种多模态传感器数据的跨天气标注和广泛的地理采样,它是唯一允许评估我们的多模态融合方法的现有数据集。在未来,我们展望了研究人员在现有数据集未覆盖的天气条件下开发和评估多模态融合方法。
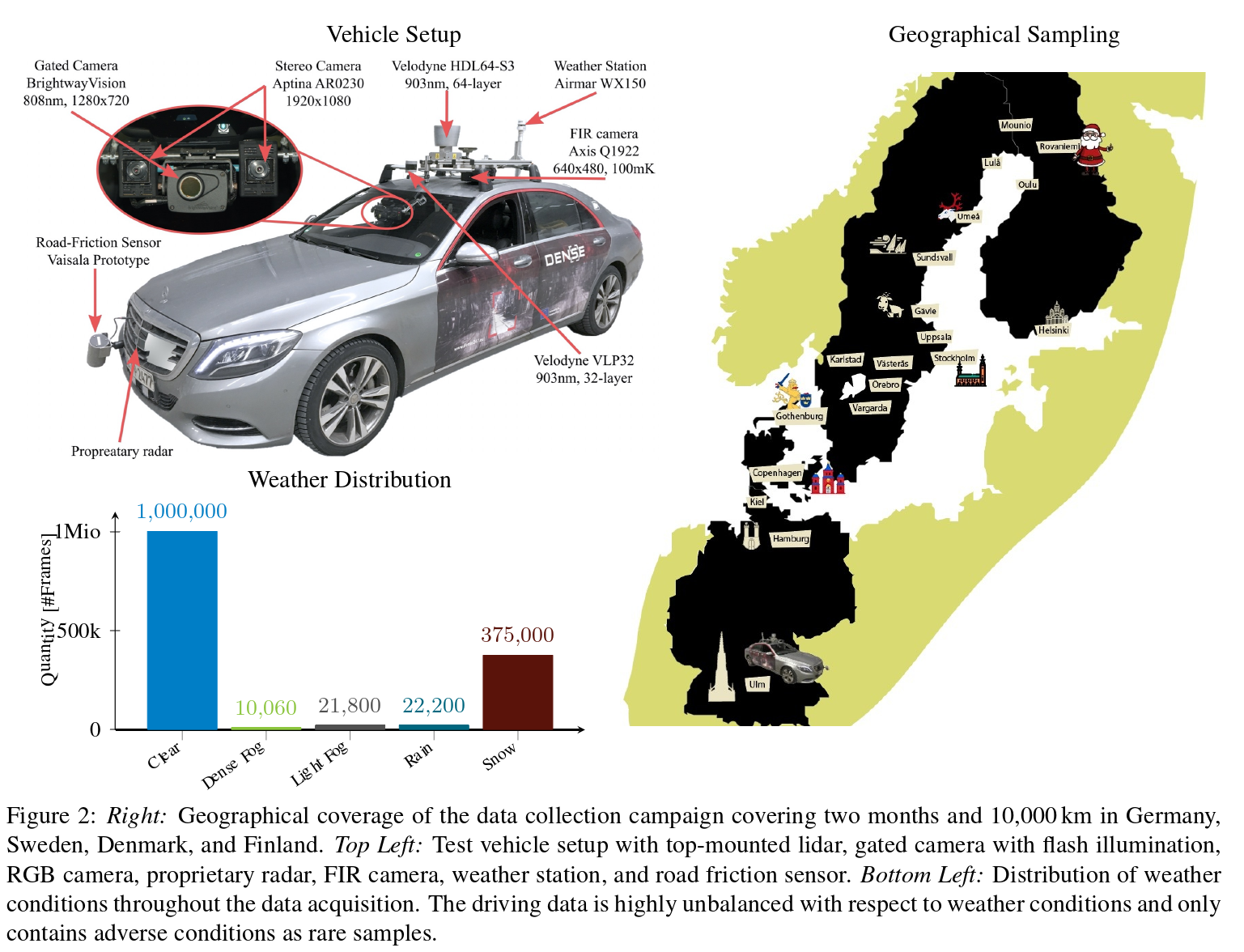
In Figure 2,we plot the weather distribution of the pro-posed dataset.The statistics were obtained by manually an-notating all synchronized frames at a frame rate of 0.1 Hz.We guided human annotators to distinguish light from densefog when the visibility fell below 1 km[45]and 100 m,re-spectively.If fog occurred together with precipitation,thescenes were either labeled as snowy or rainy depending onthe environment road conditions.For our experiments,wecombined snow and rainy conditions.Note that the statisticsvalidate the rarity of scenes in heavy adverse weather,whichis in agreement to[61]and demonstrates the difficulty andcritical nature of obtaining such data in the assessment oftruly self-driving vehicles,i.e.without the interaction of re-mote operators outside of geo-fenced areas.We found thatextreme adverse weather conditions occur only locally andchange very quickly.
在图2中,我们绘制了所提数据集的天气分布。统计通过手动作标记所有同步帧以0.1 Hz的帧率获得。当能见度分别低于1 km [ 45 ]和100 m时,我们指导人类注释者区分轻雾和浓雾。如果雾和降水同时发生,则根据环境道路情况将场景标记为雪天或雨天。对于我们的实验,我们结合了雪和雨的条件。值得注意的是,该统计数据证实了恶劣天气下的场景是罕见的,这与文献[ 61 ]一致,并表明在评估真正的自动驾驶车辆时,获得这些数据的难度和关键性质,即没有地理禁区以外的远程运营商的互动。我们发现极端不利气象条件只在局地发生,且变化非常快。
The individual weather conditions result in asymmetri-cal perturbations of various sensor technologies,leading toasymmetric degradation,i.e.instead of all sensor outputsbeing affected uniformly by a deteriorating environmentalcondition,some sensors degrade more than others,see Fig-ure 3.For example,conventional passive cameras performwell in daytime conditions,but their performance degradesin night-time conditions or challenging illumination settingssuch as low sun illumination.Meanwhile,active scanningsensors as lidar and radar are less affected by ambient lightchanges due to active illumination and a narrow bandpass on the detector side.On the other hand,active lidar sensorsare highly degraded by scattering media as fog,snow orrain,limiting the maximal perceivable distance at fog den-sities below 50 m to 25 m,see Figure 3.Millimeter-waveradar waves do not strongly scatter in fog[24],but currentlyprovide only low azimuthal resolution.Recent gated im-ages have shown robust perception in adverse weather[23],provide high spatial resolution,but are lacking color infor-mation compared to standard imagers.With these sensor-specific weaknesses and strengths of each sensor,multi-modal data can be crucial in robust detection methods.
不同的气象条件导致各种传感器技术的不对称扰动,导致不对称的退化,即所有传感器的输出不受恶化的环境条件的统一影响,一些传感器的退化程度高于其他传感器,见图3。例如,传统的被动相机在白天条件下表现良好,但在夜间条件下或太阳光照不足等具有挑战性的照明设置中,其性能会下降。同时,激光雷达和雷达等主动扫描传感器由于主动照明和窄带通,受环境光变化的影响较小在探测器侧。另一方面,主动激光雷达传感器受雾、雪或雨等散射介质的影响严重退化,将雾密度低于50 m时的最大可感知距离限制在25 m以内,见图3。毫米波雷达波在雾中没有强烈的散射[ 24 ],但目前只能提供较低的方位分辨率。最近的门控图像在恶劣天气下表现出稳健的感知[ 23 ],提供了高空间分辨率,但与标准成像仪相比缺乏颜色信息。利用这些传感器特有的弱点和每个传感器的优势,多模态数据可以在稳健的检测方法中至关重要。

3.1.Multimodal Sensor Setup
For acquisition we have equipped a test vehicle with sen-sors covering the visible,mm-wave,NIR,and FIR band,seeFigure 2.We measure intensity,depth,and weather condi-tion.
Stereo Camera As visible-wavelength RGB cameras,we use a stereo pair of two front-facing high-dynamic-range automotive RCCB cameras,consisting of two On-Semi AR0230 imagers with a resolution of 1920×1024,a baseline of 20.3 cm and 12 bit quantization.The camerasrun at 30 Hz and are synchronized for stereo imaging.UsingLensagon B5M8018C optics with a focal length of 8 mm,afield-of-view of 39.6°×21.7°is obtained.
3.1.多模态传感器设置
为了采集,我们配备了一个测试车辆,传感器覆盖可见光、毫米波、NIR和FIR波段,见图2。我们测量强度、深度和天气状况。
立体相机 作为可见光波长的RGB相机,我们使用两个前置的高动态范围汽车RCCB相机的立体对,由两个On - Semi AR0230成像仪组成,分辨率为1920 × 1024,基线为20.3 cm,12 bit量化。相机运行在30 Hz,并同步进行立体成像。使用焦距为8mm的Lensagon B5M8018C光学器件,获得了39.6 ° × 21.7 °的视场。
Gated camera We capture gated images in the NIR bandat 808 nm using a BrightwayVision BrightEye camera op-erating at 120 Hz with a resolution of 1280×720 and a bitdepth of 10 bit.The camera provides a similar field-of-viewas the stereo camera with 31.1°×17.8°.Gated imagersrely on time-synchronized camera and flood-lit flash lasersources[30].The laser pulse emits a variable narrow pulse,and the camera captures the laser echo after an adjustable delay.This enables to significantly reduce backscatter fromparticles in adverse weather[3].Furthermore,the high im-ager speed enables to capture multiple overlapping sliceswith different range-intensity profiles encoding extractabledepth information in between multiple slices[23].Follow-ing[23],we capture 3 broad slices for depth estimation andadditionally 3-4 narrow slices together with their passivecorrespondence at a system sampling rate of 10 Hz.
门控相机 采用Brightway Vision Bright Eye相机,分辨率为1280 × 720,位深为10 bit,工作频率为120 Hz,采集808 nm近红外波段的门控图像。该相机提供了与31.1 ° × 17.8 °立体相机相似的视场。门控成像仪依赖于时间同步相机和泛光灯闪光激光源[ 30 ]。激光脉冲发射可变窄脉冲,相机经过可调 延时后捕获激光回波。这使得在恶劣天气下能够显著减少来自粒子的后向散射[ 3 ]。此外,高成像速度能够捕获多个具有不同距离-强度剖面的重叠切片,在多个切片之间编码可提取的深度信息[ 23 ]。根据文献[ 23 ],在系统采样率为10 Hz的情况下,捕获3个用于深度估计的宽切片和3 ~ 4个窄切片及其被动对应。
Radar For radar sensing,we use a proprietary frequency-modulated continuous wave(FMCW)radar at 77 GHz with1°angular resolution and distances up to 200 m.The radarprovides position-velocity detections at 15 Hz.
雷达用于雷达探测,我们使用77 GHz的专用调频连续波( FMCW )雷达,其角分辨率为1 °,距离可达200 m。雷达提供15 Hz的位置-速度探测。
Lidar On the roof of the car,we mount two laser scannersfrom Velodyne,namely HDL64 S3D and VLP32C.Both areoperating at 903 nm and can provide dual returns(strongestand last)at 10 Hz.While the Velodyne HDL64 S3D pro-vides equally distributed 64 scanning lines with an angularresolution of 0.4°,the Velodyne VLP32C offers 32 non-linear distributed scanning lines.HDL64 S3D and VLP32Cscanners achieve a range of 100 m and 120 m,respectively.
激光雷达在车顶安装两台调速发电机激光扫描仪,分别是HDL64 S3D和VLP32C。两者都工作在903 nm,并能提供10 Hz的双回波(最强和最后)。调速发电机HDL64 S3D提供64条均匀分布的扫描线,角度分辨率为0.4 °,调速发电机VLP32C提供32条非线性分布的扫描线。HDL64 S3D和VLP32C扫描仪分别实现了100 m和120 m的扫描范围。
FIR camera Thermal images are captured with an AxisQ1922 FIR camera at 30 Hz.The camera offers a resolu-tion of 640×480 with a pixel pitch of 17µm and a noiseequivalent temperature difference(NETD)<100 mK.
FIR相机采用AxisQ1922型FIR相机在30 Hz下采集热图像。相机分辨率为640 × 480,像元间距为17 µ m,噪声等效温差( NETD ) < 100 mK。
Environmental Sensors We measured environmen-tal information with an Airmar WX150 weather stationthat provides temperature,wind speed and humidity,anda proprietary road friction sensor.All sensors are time-synchronized and ego-motion corrected using a proprietaryinertial measurement unit(IMU).The system provides asampling rate of 10 Hz.
环境传感器我们使用提供温度、风速和湿度的Airmar WX150气象站和专有的路面摩擦传感器测量环境信息。所有传感器都使用专有的惯性测量单元( IMU )进行时间同步和自运动校正。系统提供10 Hz的采样率。
3.2.Recordings
Real-world Recordings All experimental data has beencaptured during two test drives in February and December2019 in Germany,Sweden,Denmark,and Finland for twoweeks each,covering a distance of 10,000 km under dif-ferent weather and illumination conditions.A total of 1.4million frames at a frame rate of 10 Hz have been collected.Every 100th frame was manually labeled to balance scenetype coverage.The resulting annotations contain 5,5k clearweather frames,1k captures in dense fog,1k captures inlight fog,and 4k captures in snow/rain.Given the extensivecapture effort,this demonstrates that training data in harshconditions is rare.We tackle this approach by training onlyon clear data and testing on adverse data.The train andtest regions do not have any geographic overlap.Insteadof partitioning by frame,we partition our dataset based onindependent recordings(5-60 min in length)from differentlocations.These recordings originate from 18 different ma-jor cities illustrated in Figure 2 and several smaller citiesalong the route.
3.2 记录
所有实验数据均于2019年2月和12月在德国、瑞典、丹麦和芬兰进行了为期两周的两次测试,覆盖了不同天气和光照条件下的10000 km距离。在10Hz的帧率下,共采集了140万帧图像。每隔100帧进行人工标注以平衡场景类型覆盖。得到的标注包含5,5k个晴空天气帧,1k个在浓雾中捕获,1k个在轻雾中捕获,4k个在雪/雨中捕获。鉴于广泛的捕获努力,这表明在恶劣条件下的训练数据是罕见的。我们通过只对清晰数据进行训练和对不良数据进行测试来解决这个问题。列车和测试区域没有任何地理重叠。与按帧划分不同,我们基于不同位置的独立记录( 5 ~ 60 min)对数据集进行划分。这些记录来源于图2所示的18个不同的主要城市和沿途的几个较小的城市。
Controlled Condition Recordings To collect image andrange data under controlled conditions,we also providemeasurements acquired in a fog chamber.Details on the fogchamber setup can be found in[17,13].We have captured35k frames at a frame rate of 10 Hz and labeled a subsetof 1,5k frames under two different illumination conditions(day/night)and three fog densities with meteorological vis-ibilities V of 30 m,40 m and 50 m.Details are given in thesupplemental material,where we also do comparisons to asimulated dataset,using the forward model from[51].
受控条件记录为了收集受控条件下的图像和范围数据,我们还提供了在雾室中获得的测量。关于雾室设置的细节可以在[ 17、13]中找到。我们在两种不同光照条件(白天/夜晚)和三种雾天密度下,以10 Hz的帧率拍摄了35k帧图像,并标注了1,5k帧图像的子集,气象能见度V分别为30 m,40 m和50 m。详细信息在补充材料中给出,我们还使用文献[ 51 ]中的正演模型与模拟数据集进行了比较。
4.Adaptive Deep Fusion
In this section,we describe the proposed adaptive deepfusion architecture that allows for multimodal fusion in thepresence of unseen asymmetric sensor distortions.We de-vise our architecture under real-time processing constraintsrequired for self-driving vehicles and autonomous drones.Specifically,we propose an efficient single-shot fusion ar-chitecture.
4 .自适应深度融合
在本节中,我们描述了所提出的自适应深度融合架构,该架构允许在不可见的非对称传感器失真情况下进行多模态融合。我们在自动驾驶汽车和自主无人机所需的实时处理约束下设计了我们的架构。具体地,我们提出了一种高效的单炮融合结构。
4.1.Adaptive Multimodal Single-Shot Fusion
The proposed network architecture is shown in Figure 4.It consists of multiple single-shot detection branches,eachanalyzing one sensor modality.
4 . 1 .自适应多模态单镜头融合
本文提出的网络架构如图4所示。它由多个单发检测分支组成,每个分支分析一个传感器模态。
Data Representation The camera branch uses conven-tional three-plane RGB inputs,while for the lidar andradar branch,we depart from recent bird’s eye-view(BeV)projection[35]schemes or raw point-cloud representa-tions[64].BeV projection or point-cloud inputs do notallow for deep early fusion as the feature representationsin the early layers are inherently different from the camerafeatures.Hence,existing BeV fusion methods can only fusefeatures in a lifted space,after matching region proposals,but not earlier.Figure 4 visualizes the proposed input dataencoding,which aids deep multimodal fusion.Instead ofusing a naive depth-only input encoding,we provide depth,height,and pulse intensity as input to the lidar network.Forthe radar network,we assume that the radar is scanning in a2D-plane orthogonal to the image plane and parallel to thehorizontal image dimension.Hence,we consider radar in-variant along the vertical image axis and replicate the scanalong vertical axis.Gated images are transformed into theimage plane of the RGB camera using a homography map-ping,see supplemental material.The proposed input en-coding allows for a position and intensity-dependent fusionwith pixel-wise correspondences between different streams.We encode missing measurement samples with zero value.
数据相机分支使用传统的三平面RGB输入,而对于激光雷达和雷达分支,我们偏离了最近的鸟瞰( BeV )投影[ 35 ]方案或原始的点云表示[ 64 ]。BeV投影或点云输入不允许进行深度早期融合,因为早期层中的特征表示与相机特征本质上不同。因此,现有的BeV融合方法只能在匹配区域提议后的提升空间中进行特征融合,而不能更早地进行特征融合。图4可视化了所提出的输入数据编码,这有助于深度多模态融合。我们不使用简单的深度输入编码,而是提供深度、高度和脉冲强度作为激光雷达网络的输入。对于雷达网,我们假设雷达在与图像平面正交且平行于水平图像维度的二维平面内进行扫描。因此,我们考虑沿垂直图像轴的雷达不变量,并沿垂直轴复制扫描。门控图像通过单应映射变换到RGB相机的图像平面,见补充材料。所提出的输入编码允许不同流之间具有像素级对应的位置和强度依赖的融合。我们对缺失的测量样本进行零值编码。
Feature Extraction As feature extraction stack in eachstream,we use a modified VGG[54]backbone.Similar to[35,11],we reduce the number of channels by half and cutthe network at the conv4 layer.Inspired by[40,38],we usesix feature layers from conv4-10 as input to SSD detection layers.The feature maps decrease in size1,implementing afeature pyramid for detections at different scales.As shownin Figure 4,the activations of different feature extractionstacks are exchanged.To steer fusion towards the most reli-able information,we provide the sensor entropy to each fea-ture exchange block.We first convolve the entropy,apply asigmoid,multiply with the concatenated input features fromall sensors,and finally concatenate the input entropy.Thefolding of entropy and application of the sigmoid generatesa multiplication matrix in the interval[0,1].This scales theconcatenated features for each sensor individually based onthe available information.Regions with low entropy canbe attenuated,while entropy rich regions can be amplifiedin the feature extraction.Doing so allows us to adaptivelyfuse features in the feature extraction stack itself,which wemotivate in depth in the next section.
特征提取作为每个流中的特征提取堆栈,我们使用了一个修改的VGG [ 54 ]主干。与[ 35、11]类似,我们将通道数减少一半,并在conv4层进行网络裁剪。受[ 40、38]的启发,我们使用conv4 - 10的六个特征层作为SSD检测层的输入。特征图尺寸减小为1,实现不同尺度检测的特征金字塔。如图4所示,交换了不同特征提取栈的激活。为了引导融合朝向最可靠的信息,我们为每个特征交换块提供传感器熵。我们首先对熵值进行卷积,然后应用aigmoid,与所有传感器的级联输入特征相乘,最后将输入熵值进行级联。熵的折叠和sigmoid函数的应用产生了区间[ 0 , 1]上的乘法矩阵。该方法基于可用信息对每个传感器的关联特征进行单独的缩放。在特征提取时,低熵的区域可以被衰减,而熵丰富的区域可以被放大。这样做允许我们在特征提取堆栈本身中自适应地融合特征,这将在下一节中进行深入研究。
4.2.Entropy-steered Fusion
To steer the deep fusion towards redundant and reliableinformation,we introduce an entropy channel in each sen-sor stream,instead of directly inferring the adverse weathertype and strength as in[57,59].We estimate local measure-ment entropy,the entropy is calculated for each 8 bit binarized stream Iwith pixel values i [0,255]in the proposed image-space data representation.Each stream is split into patches ofsize M×N=16 px×16 px resulting in a w×h=1920 px×1024 px entropy map.The multimodal entropymaps for two different scenarios are shown in Figure 5:theleft scenario shows a scene containing a vehicle,cyclist,andpedestrians in a controlled fog chamber.The passive RGBcamera and lidar suffer from backscatter and attenuationwith decreasing fog visibilities,while the gated camera sup-presses backscatter through gating.Radar measurementsare also not substantially degraded in fog.The right sce-nario in Figure 5 shows a static outdoor scene under vary-ing ambient lighting.In this scenario,active lidar and radarare not affected by changes in ambient illumination.For thegated camera,the ambient illumination disappears,leavingonly the actively illuminated areas,while the passive RGBcamera degenerates with decreasing ambient light.
为了将深度融合引向冗余和可靠的信息,我们在每个传感器流中引入一个熵通道,而不是像在[ 57、59]中那样直接推断不利天气类型和强度。我们估计局部测量熵,在提出的图像空间数据表示中,对每个像素值为i[ 0,255]的8位二进制流I计算熵。每个流被分割成大小为M × N = 16 px × 16 px的小块,得到w × h = 1920 px × 1024 px的熵图。两种不同场景下的多模态熵图如图5所示:左侧场景为受控雾室内包含车辆、骑车人和行人的场景。被动RGB相机和激光雷达受到后向散射和衰减的影响,雾的能见度降低,而门控相机通过门控抑制后向散射。
The steering process is learned purely on clean weatherdata,which contains different illumination settings presentin day to night-time conditions.No real adverse weatherpatterns are presented during training.Further,we dropsensor streams randomly with probability 0.5 and set theentropy to a constant zero value.
转向过程纯粹是在干净的天气数据上学习的,其中包含了白天到夜间不同的光照设置。训练过程中没有出现真实的不利天气形势。进一步,我们以概率0.5随机丢弃传感器流,并将熵值设置为恒定的零值。
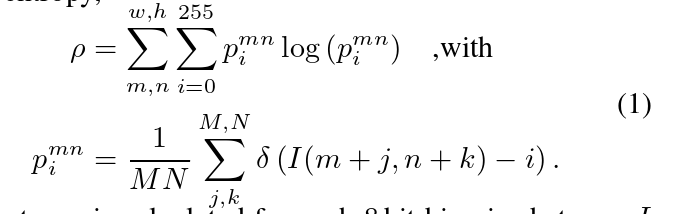
4.3.Loss Functions and Training Details
The number of anchor boxes in different feature layersand their sizes play an important role during training andare given in the supplemental material.In total,each anchorbox with class label yi and probability pi is trained using thecross entropy loss with softmax,
The loss is split up for positive and negative anchor boxeswith a matching threshold of 0.5.For each positive anchorbox,the bounding box coordinates x are regressed using aHuber loss H(x)given by,
The total number of negative anchors is restricted to 5×thenumber of positive examples using hard example mining[40,52].All networks are trained from scratch with a con-stant learning rate and L2 weight decay of 0.0005.
4.3.损失函数和训练细节
不同特征层中锚框的数量和大小在训练过程中起着重要作用,并在补充材料中给出。总的来说,每个带有类别标签yi和概率pi的锚框使用带softmax的交叉熵损失进行训练, 将损失拆分为正负锚框,匹配阈值为0.5。对于每个正锚框,使用由, 给出的Huber损失H ( x )回归包围框坐标x。使用难例挖掘[ 40 , 52]将负锚框总数限制为正例数量的5倍。所有网络从头开始训练,学习速率恒定,L2权重衰减0.0005。
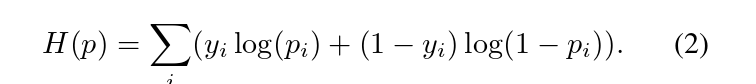
5.Assessment
In this section,we validate the proposed fusion modelon unseen experimental test data.We compare the methodagainst existing detectors for single sensory inputs and fu-sion methods,as well as domain adaptation methods.Dueto the weather-bias of training data acquisition,we only usethe clear weather portion of the proposed dataset for train-ing.We assess the detection performance using our novelmultimodal weather dataset as a test set,see supplementaldata for test and training split details.
在本节中,我们在未见到的实验测试数据上对提出的融合模型进行验证。我们将该方法与现有的单感官输入检测器和融合方法以及域适应方法进行比较。由于训练数据采集的天气偏向性,我们只使用所提数据集的晴朗天气部分进行训练。我们使用新的多模态天气数据集作为测试集来评估检测性能,测试和训练分割细节见补充数据。
We validate the proposed approach in Table 2,which we dub Deep Entropy Fusion,on real adverse weather data.We report Average Precision(AP)for three different dif-ficulty levels(easy,moderate,hard)and evaluate on carsfollowing the KITTI evaluation framework[19]at variousfog densities,snow disturbances,and clear weather condi-tions.We compare the proposed model against recent state-of-the-art lidar-camera fusion models,including AVOD-FPN[35],Frustum PointNets[48],and variants of the pro-posed method with alternative fusion or sensory inputs.Asbaseline variants,we implement two fusion and four sin-gle sensor detectors.In particular,we compare against latefusion with image,lidar,gated,and radar features concate-nated just before bounding-box regression(Fusion SSD),and early fusion by concatenating all sensory data at theearly beginning of one feature extraction stack(ConcatSSD).The Fusion SSD network shares the same structureas the proposed model,but without the feature exchangeand the adaptive fusion layer.Moreover,we compare theproposed model against an identical SSD branch with sin-gle sensory input(Image-only SSD,Gated-only SSD,Lidar-only SSD,Radar-only SSD).All models were trained withidentical hyper-parameters and anchors.
在本节中,我们在未知的实验测试数据上对提出的融合模型进行验证。我们将该方法与现有的单感官输入检测器和融合方法以及域适应方法进行了比较。由于训练数据采集的天气偏向性,我们只使用所提数据集的晴朗天气部分进行训练。我们使用新的多模态天气数据集作为测试集来评估检测性能,测试和训练分割细节见补充数据。我们在真实的恶劣天气数据上验证了表2中提出的方法,我们称之为深度熵融合。我们报告了3个不同难度等级的平均精度( Average Precision,AP ) (易、中、难),并按照KITTI评价框架[ 19 ]在不同雾密度、雪干扰和晴朗天气条件下对汽车进行评价。我们将提出的模型与最新的先进的激光雷达-相机融合模型进行了比较,包括AVOD - FPN [ 35 ]、截头锥体PointNets [ 48 ],以及采用交替融合或感官输入的改进方法。作为基线变体,我们实现了两个融合和四个单传感器检测器。特别地,我们比较了与图像、激光雷达、门控和雷达特征在边界框回归之前级联的后期融合( Fusion SSD )和在一个特征提取堆栈的早期连接所有感官数据的早期融合( Concat SSD )。Fusion SSD网络与本文模型结构相同,但没有特征交换和自适应融合层。此外,我们将所提出的模型与具有单一感官输入的SSD分支进行了比较。所有模型均使用相同的超参数和锚点进行训练。
Evaluated on adverse weather scenarios,the detection performance decrease for all methods.Note that assessmentmetrics can increase simultaneously as scene complexitychanges between the weather splits.For example,whenfewer vehicles participate in road traffic or the distance be-tween vehicles increases in icy conditions,fewer vehiclesare occluded.While the performance for image and gateddata is almost steady,it decreases substantially for lidar datawhile it increases for radar data.The decrease in lidar per-formance can be described by the strong backscatter,seeSupplemental Material.As a maximum of 100 measure-ment targets limits the performance of the radar input,thereported improvements are resulting from simpler scenes.
在恶劣天气场景下评估,所有方法的检测性能都有所下降。值得注意的是,评估度量可以随着天气片段之间场景复杂度的变化而同时增加。例如,在结冰条件下,当参与道路交通的车辆较少或者车辆间距离增加时,较少车辆被遮挡。虽然图像和门控数据的性能几乎是稳定的,但对于激光雷达数据,它的性能大幅下降,而对于雷达数据,它的性能增加。激光雷达性能的下降可以用强后向散射来描述,见补充材料。由于最多100个测量目标限制了雷达输入的性能,因此报告的改进来自于更简单的场景。
Overall,the large reduction in lidar performance forfoggy conditions affects the lidar only detection rate by adrop in 45.38%AP.Furthermore,it also has a strong impacton camera-lidar fusion models AVOD,Concat SSD and Fu-sion SSD.Learned redundancies no longer hold,and thesemethods even fall below image-only methods.
总体而言,雾天条件下激光雷达性能的大幅下降影响了仅激光雷达的探测率下降了45.38 % AP,同时也对相机-激光雷达融合模型AVOD、Concat SSD和Fusion SSD产生了强烈的影响。学习到的冗余不再成立,这些方法甚至低于图像方法。
Two-stage methods,such as Frustum PointNet[48],dropquickly.However,they asymptotically achieve higher re-sults compared to AVOD,because the statistical priorslearned for the first stage are based on Image-only SSD thatlimits its performance to image-domain priors.AVOD islimited by several assumptions that hold for clear weather,such as the importance sampling of boxes filled with li-dar data during training,achieving the lowest fusion per-formance overall.Moreover,as the fog density increases,the proposed adaptive fusion model outperforms all othermethods.Especially under severe distortions,the proposedadaptive fusion layer results in significant margins overthe model without it(Deep Fusion).Overall the proposedmethod outperforms all baseline approaches.In dense fog,it improves by a margin of 9.69%compared to the next-bestfeature-fusion variant.
两步法,如截头锥体点网络[ 48 ],Dropquickly .然而,与AVOD相比,它们渐进地获得了更高的结果,因为第一阶段学习的统计先验是基于图像域的SSD,这限制了它的性能。AVOD受限于几个适用于晴朗天气的假设条件,例如训练时对装满激光雷达数据的箱子进行重要性采样,总体上实现了最低的融合性能。此外,随着雾密度的增加,所提出的自适应融合模型优于所有其他方法。特别是在严重失真下,提出的自适应融合层比没有它的模型( Deep Fusion )产生了显著的边缘。总体而言,所提方法优于所有基线方法。在浓雾中,它比次优的特征融合算法提高了9.69 %。
For completeness,we also compare the proposed modelto recent domain adaptation methods.First,we adapt ourImage-Only SSD features from clear weather to adverseweather following[60].Second,we investigate the style transfer from clear weather to adverse weather utilizing[28]and generate adverse weather training samples from clearweather input.Note that these methods have an unfair ad-vantage over all other compared approaches as they haveseen adverse weather scenarios sampled from our validationset.Note that domain adaptation methods cannot be directlyapplied as they need target images from a specific domain.Therefore,they do also not offer a solution for rare edgecases with limited data.Furthermore[28]does not modeldistortions,including fog or snow,see experiments in theSupplemental Material.We note that synthetic data aug-mentation following[51]or image-to-image reconstructionmethods that remove adverse weather effects[63]do nei-ther affect the reported margins of the proposed multimodaldeep entropy fusion.
为了完整起见,我们还将提出的模型与最近的域适应方法进行了比较。首先,我们将我们的Image - Only SSD特征从晴朗天气适应到逆风天气[ 60 ]。其次,我们对风格进行了考察。为了完整起见,我们还将提出的模型与最近的领域适应方法进行了比较。首先,我们将我们的Image - Only SSD特征从晴朗天气适应到逆风天气[ 60 ]。其次,我们利用[ 28 ]研究晴朗天气到恶劣天气的风格迁移,并从晴朗天气输入生成恶劣天气训练样本。值得注意的是,这些方法与所有其他比较方法相比具有不公平的优势,因为它们从我们的验证集中采样了不利的天气场景。注意域适应方法不能直接应用,因为它们需要来自特定域的目标图像。因此,它们也没有为数据有限的稀有边缘情况提供解决方案。此外,文献[ 28 ]没有对雾或雪等失真进行建模,见补充材料中的实验。我们注意到,采用合成数据增强[ 51 ]或消除不利天气影响的图像到图像重建方法[ 63 ]并不影响所提出的多模态深度熵融合的报告边缘。
6.Conclusion and Future Work
In this paper we address a critical problem in au-tonomous driving:multi-sensor fusion in scenarios,whereannotated data is sparse and difficult to obtain due to nat-ural weather bias.To assess multimodal fusion in adverseweather,we introduce a novel adverse weather dataset cov-ering camera,lidar,radar,gated NIR,and FIR sensor data.The dataset contains rare scenarios,such as heavy fog,heavy snow,and severe rain,during more than 10,000 kmof driving in northern Europe.We propose a real-time deepmultimodal fusion network which departs from proposal-level fusion,and instead adaptively fuses driven by mea-surement entropy.Exciting directions for future researchinclude the development of end-to-end models enabling thefailure detection and an adaptive sensor control as noiselevel or power level control in lidar sensors.
6 .结论与未来工作
本文解决了自动驾驶中的一个关键问题:在自然天气偏差导致标注数据稀疏且难以获得的场景中进行多传感器融合。为了评估不利天气下的多模态融合,我们引入了一个新的不利天气数据集,包括相机、激光雷达、雷达、门控NIR和FIR传感器数据。该数据集包含了北欧地区超过10,000公里的驾驶过程中罕见的场景,如大雾、大雪和暴雨。我们提出了一个实时的深度多模态融合网络,它脱离了提案级融合,而是由测量熵驱动的自适应融合。未来令人兴奋的研究方向包括开发能够进行故障检测的端到端模型以及激光雷达传感器中的自适应传感器控制如声压级或功率级控制。