Summary
question
作者提出了一个新的领域:Open World Object Detection,该任务定义为:
- 测试集中可能出现未知类别的物体,网络需将其识别为unknown类别 ;
- 如果之后给出某个未知的标签,需要网络能够增量学习新的类别。
目前已有类似领域为:
Open Set Classification:该领域所有工作虽然可以识别unknown类别,但是它们不能在多个训练episode中以增量方式动态更新
Open World Classification:该领域的模型可以识别物体,并且当某个unknown标签给定时其可以更新自己,但是这些工作并没有在图像分类的benchmark上测试
Open Set Detection:该领域的研究发现传统物体检测模型经常将未知类别的物体识别成已知的某一类别,因此其处理方式通常为:1. 新增一个background类别 2. 去除未知类别的物体。但是上述两个方法都不能在真实动态环境中使用
significance
虽然目标检测技术目前已经发展得较为成熟,但如果要真正能实现让计算机像人眼一样进行识别,有项功能一直尚未达成——那就是像人一样能识别现实世界中的所有物体,并且能够逐渐学习认知新的未知物体。开放集和开放世界图像分类的进展不能简单地适用于开放集和开放世界的目标检测,开放集和开放世界的目标检测的不同之处在于:在目标检测器的训练过程中,将那些未知的目标当做背景。许多未知类的实例已经和已知目标一起引入到目标检测器中。由于它们没有被标注,训练检测模型时,这些未知的实例将被学习为背景。
文中提出了一种新的基于对比聚类和基于能量的未知识别的开放世界目标检测模型(ORE)。开放世界目标检测模型是一个新问题,即一个模型应该能够以一种通用的方式识别未知目标的实例作为“未知”,然后在训练数据逐步取得时,学习识别它们。
Strengths
网络结构
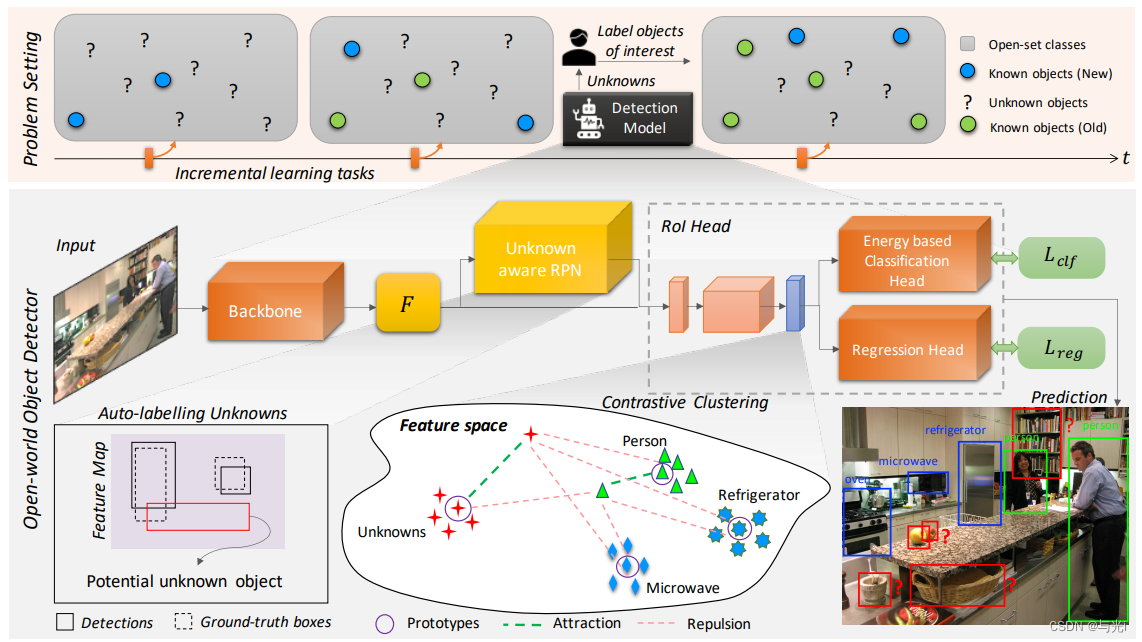
总体思想
定义t时刻已知类别为 K t = 1 , 2 , . . . , C ⊂ N + K^t={1,2,...,C}\subset\mathbb{N}^+ Kt=1,2,...,C⊂N+其中 N + \mathbb{N}^+ N+ 表示positive物体集合,为了适应动态真实世界,定义额外的未知类别 U = C + 1 , . . . U={C+1,...} U=C+1,... ,则已知数据集为 D t = X t , Y t D^t={X^t,Y^t} Dt=Xt,Yt,其中image集合包含 M M M个图片 I M I_M IM ,与之对应的label为 Y M Y_M YM,每个label Y i = y 1 , . . . , y k Y_i={y_1,...,y_k} Yi=y1,...,yk 包含了图片 I M I_M IM所包含的 K K K个物体的groud truth y i y_i yi ,其中 y i = l k , x k , y k , w k , h k y_i={l_k,x_k,y_k,w_k,h_k} yi=lk,xk,yk,wk,hk, l k ∈ K + l_k\in K^+ lk∈K+。
该任务主要功能逻辑为:模型 M c M_c Mc能够识别 C C C个物体和未知物体(unknown,label 0),之后再从 U t U_t Ut中标注 n n n个类别,并提供相应的训练样本,则网络可以无需重新在整个训练集(包括之前的)上训练即可新增识别 n n n个物体,即得到 M C + n M_{C+n} MC+n,则 K t + 1 = K t + C + 1 , . . . , C + n K_{t+1}=K_t+{C+1,...,C+n} Kt+1=Kt+C+1,...,C+n。
创新点
本文主体是基于Faster-RCNN进行改进的。
对比聚类
思想:针对隐空间中的特征表示,相同的类别应该距离相近,不同的类别距离应该较远;基于这一期望,为骨干网络抽取的特征添加一个聚类约束。
具体实现:对每个类别的隐空间特征,统计一段时间内迭代样本的特征均值,作为聚类中心,并约束期望该类样本特征都靠近该中心,其他类的样本特征远离该中心;聚类中心在训练过程中不断更新。
优势:1. 可以帮助网络辨别unknown类别的物体与已知类别的表示有何不同 2. 促进网络在不覆盖潜在空间中原有类别表示情况下学习未知类别的潜在表示
利用RPN自动标注未知类别
思想:实际使用中,我们不可能提前在训练集中标注未知类别的目标。考虑到RPN产生的候选框只区分前景和背景,背景框实际上是没有被标注的区域,作者认为这些背景框中分数较高的很可能就是没有标注的目标,因此,作者直接从RPN产生的背景框中直接按分值排序的top_k个框视为未知类别目标。
优势:利用RPN网络能够完成自动标注图片中未知类别物体的工作
基于能量模式的未知类别辨识修正
思想:该部分基于Energy based models (EBMs),给定潜在空间 F F F的特征 f ∈ F f\in F f∈F和其对应的label l ∈ L l\in L l∈L,作者的目标是寻找一个能量函数 E ( ⋅ ) E(\cdot) E(⋅),其输出为一个标量,该标量估计观测变量 F F F和可能的输出变量集合 L L L之间的兼容性(compatibility),即 E ( f ) : R d → R E(f):\mathbb{R}^d\rightarrow\mathbb{R} E(f):Rd→R。
EBMs给分布内的数据(in-distribution data)分配低能量值,反之则分配高能量值,因此可以用能量值的高低表示样本是否属于未知类别。
优势:能够将标准Faster R-CNN中的分类头转换成一个能量函数,推理时,可以计算出推理样本的能量值,并基于分别对样本类别进行矫正。
Weaknesses and Improvements
anchor-based
模型严重依赖设置密集的目标候选框,比如对特征图(HW)每个像素设置k个anchor boxes,这样就会有成千上万个acnhors(HW*k),这样过于低效。
改进:
使用稀疏R-CNN网络作为骨干网络。
输入包括一个图像、一组建议框和建议功能,其中后两个是可学习的参数。主干提取特征图,将每个建议框和建议特征输入到其唯一的动态头部,生成目标特征,最后输出分类和定位。
网络公式:
image + proposal boxes – (融合) --> ROIs
RoIs + proposal features – (融合) --(全连接层)–> predictions
可学习的建议框 learnable proposal box:
使用一种固定的可学习的建议框( N × 4 ) (N\times4)(N×4) 提供区域建议,替代RPN网络。
由0到1的四维参数表示,表示标准化的中心坐标( x , y ) (x,y)(x,y)、高度和宽度,使用反向传播算法进行更新。
是训练集中潜在对象位置的统计信息,可以看作是,除开输入的内容的影响,对图像中最可能包含对象的区域的初始猜测。
可学习的建议特征learnable proposal feature:
建议框只提供了对对象的粗略定位,并丢失了许多细节的信息,如对象姿势和形状。因此引入建议特征( N × d ) (N\times d)(N×d) ,是一个高维向量(如256),对实例特征进行编码。
数量和建议框相同。
动态实例交互头Dynamic instance interactive head:
给定N个提议框,稀疏R-CNN首先利用RoI Align操作为每个框提取特征。然后,每个框特征将用于使用预测头,生成最终预测。
生成未知类别
自动生成未知类别的方法,实际上隐含的应用场景是:未知类别的目标已经出现在了训练集中,只是还没有进行标注,只有这样,抽取到的未知类别的proposal才有意义。但在很多场景中,往往未知类别不会提前出现在训练集中(如果出现了就会被标注),而是在未来才可能产生,这可能导致这一方法的实际应用存在风险。
改进:
训练一个泛化能力强的检测网络,最好使之能够泛化到训练集中没有出现过的,但模式与训练集中的目标模式类似的目标上;
训练一个具有异常检测能力的分类网络,能够自动发现某些目标与任何已知的目标模式都不一致。
对比聚类
本文中实现对比聚类时,将未知类别也进行了聚类,但是未知类别可能是多种多样的,实际上并不是同一个类别,这个聚类理论上可能是有副作用的,值得进一步实验验证。
改进:
进一步的,把未知类别进行初步的分类,或者用更好的方法替代掉当前的聚类方法。