提出背景擦除(Background Erasing)方法来减轻模型对背景的依赖,从而使模型更关注动作变化。
CVPR2021
论文地址:https://arxiv.org/abs/2009.05769
1. 总述
自监督学习通过对数据本身的监督,在提高深层神经网络的视频表现能力方面显示出巨大的潜力。然而,目前的一些方法往往会存在着背景欺骗,即预测结果高度依赖于视频背景而不是运动,使得模型容易受到背景变化的影响。

背景欺骗的图示:在真实的世界中,一个动作可以在不同的地点发生,而不是某个场景下只是某种动作。目前在主流数据集上训练的模型往往只看到一些背景线索来给出预测,而忽略了运动模式才是实际上在定义“动作”。
为了减轻模型对背景的依赖,作者通过添加背景来消除背景影响,具体来说:
- 给定一个视频,随机选择一个静态帧,并将其添加到其他帧中,以构建一个分散注意力的视频样本
- 然后通过一致性正则化,强制模型提取背景混合的视频的特征和原始视频的特征。这样,对视频背景进行了扰动,要求其特征与原始视频一致,达到了使模型不过度依赖背景的目的,从而缓解了背景欺骗问题,更加关注运动变化。
即本文提出的方法——背景擦除(Background Erasing-BE)。而且这个方法实现比较简单和简洁,可以不费吹灰之力地添加到大多数SOTA方法中。
2. 背景擦除(BE)的架构

-
首先在空间上对视频进行随机裁剪
-
然后随机选择一个静态帧作为空间背景噪声来添加到每一帧中来生成分散注意力的视频,公式化为:
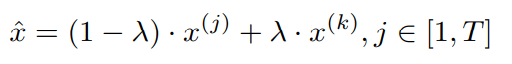 ,其中 x ( j ) x^{(j)} x(j)代表每一帧, x ( k ) x^{(k)} x(k)代表随机选择的那一帧。
,其中 x ( j ) x^{(j)} x(j)代表每一帧, x ( k ) x^{(k)} x(k)代表随机选择的那一帧。 -
接着分别使用3维卷积块来提取特征
-
最后这两者由一个已有的自监督任务和一致性约束共同训练,目的是拉近原始视频和干扰视频的特征,使模型不过度依赖背景
由于原视频和干扰视频在运动模式上彼此相似,但在空间上彼此不同,当它俩的特征更接近时,模型将被提升以抑制背景噪声,产生对运动变化更敏感的视频表示。
这样做背景发生了变化,但是运动模型并没有变:

随机选择一个视频内静态帧作为噪声添加到其他帧中。产生的干扰视频的背景发生了变化,但光流梯度基本没有变化,表明运动模式得到了保留。
如何拉近原始视频和干扰视频特征?
对于不同的自监督方法(Handcrafted Pretext和Contrastive Learning):
- handcrafted pretext:使用一致性正则化来拉近原始视频和干扰视频特征,使
它们在时间维度上保持一致。具体为两者先经过空间全局最大池化,再最小化池化后两者的L2正则化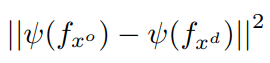
- Contrastive Learning:对比学习通过最大化相似对的相似性来实现。将原视频和干扰视频作为正例对(相似对),两者经过一个时空最大池化和一个全连接层得到特征 Z ( . ) Z(.) Z(.),然后采样函数S构造负例集合 N 1 i N_{1i} N1i
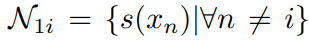 ,最后最小化式子
,最后最小化式子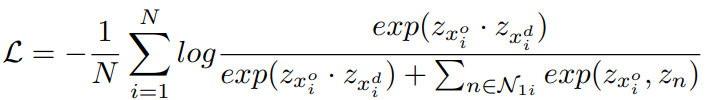
3. 实验
(1)在UCF101和HMDB51数据集上,将BE作为正则化项与四种现有方法进行结合的Top-1精度(%)

(2)在 UCF101和HMDB51数据集上的不同干扰策略的Top-1 accuracy (%)
