测试误差作为泛化误差的近似
先使用某种评估方法得到训练集和测试机
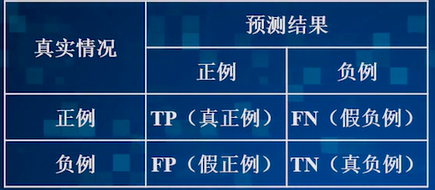
再使用分类器分的样本中的正例和负例
然后计算评估指标,判断分类器好坏
1、评估方法之训练集和测试集的确定
留出法:
直接将数据集划分为两个互斥集合
训练集和测试集的划分要尽可能保持数据分布的一致性
一般若干次随即划分、重复实验取平均值
训练样本和测试样本的比例:2-1\3-1\4-1
只一次,随机性太大,说服力不强
k折交叉验证:
将数据集分为k个大小相同或者相似的互斥的子集
每次使用k-1个子集为训练集,1个为测试集
k通常取10
为了减少因样本划分不同而引入的误差
通常随机使用不同的划分重复p次
最终的结果是p次k折交叉验证的均值
通常p = k = 10
留一法:
k折的特例:即将所有数据集作为训练集,仅用1个数据(而不是1个子集)作为测试集
优点: 没有随机因素,具有确定性
缺点:
-
时间开销太大
-
遇到有类别划分的数据集,仅一个数据不能体现所有特征
因此,当数据集比较小的时候,用留一法比较好。
一般使用k折法
自助法:
以自主采样法为基础,对数据集D有放回采样m次得到训练集D‘
剩下的为测试集
约有3/1的样本没有出现在训练集中(有一些数据被重复选择进入了训练集)
可以产生多个不同的训练集
在数据集较小、难以有效划分训练、测试集时很有用
但由于改变了数据集分布可能引入估计误差,所有数据集很大的时候,留出和k折更常用
2、评估指标
如何确定正例和负例?-——分类器
根据分类器的概率预测结果,对样本进行排序,然后选择截断点,确定正例负例
具体分类器:补充
判断分类器性能的各种指标:
准确率和错误率:
将每个类看得同等重要,不适合类不平衡的数据集
精确率P和召回率R:
P = TP/(TP+FP)(预测为正例中实际是正例的比例)
R = TP/(TP+FN)(所有实际正例中,预测对的比例)
两者往往互斥
为了综合考虑,提出F1度量
F1 = 2PR/(P+R) = 2*TP/(总数+TP-TN)
或者调整参数得到Fβ: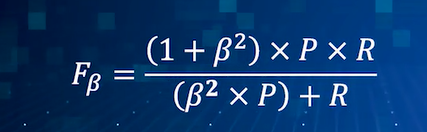
越高越好
ROC曲线:
真正率TPR = TP/(TP+FN)(被判断为正例的正样本比例) = 召回率 (纵轴)
假正率FPR = FP/(FP+TN)(被误判为正例的负样本比例) (横轴)
比较曲线与横轴形成的面积大小(AUC,Area Under Curve),越大越好
AUC
 AUC越大越好
AUC越大越好
显然:因为n0、n1不变,当所有反例排在最后时,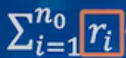 最大,AUC最大。
最大,AUC最大。
条件似然CLL

3、比较检验
因为:
- 测试性能不等于泛化性能
- 测试性能会随着测试集的变化而变化
- 很多机器学习算法本身有一定的随机性
所以,比较相应评估方法、相应分类器下的相应指标并不可取
成对双边t检验:
假设评估方法采用的是:k折交叉验证法

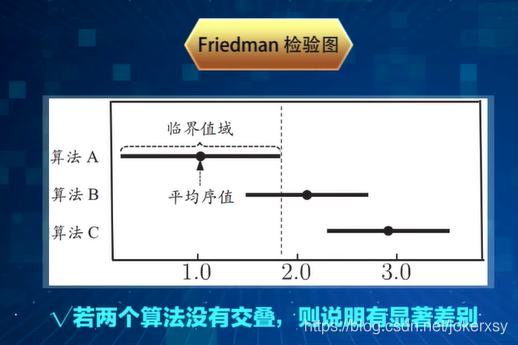
Frienman检验
在一组数据集上比较k个分类器
采用留出法或k折交叉检验,得出一组数据上各个分类器的平均值,利用概率统计的只是判断性能。
如果多个分类器性能不一致,要进一步使用Nemenyi检验。
Nemenyi后续检验
Turkey分布???
重新学一下置信度
F检验的统计量、F分布的临界值查表、临界值、大于则拒绝、两者平均序值之差<CD则两者性能差不多、若差不多则平均序值小的性能高、