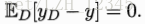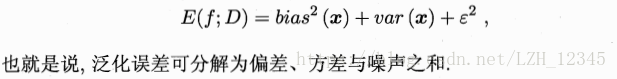一、评估方法
1.1 留出法
“留出法”(hold-out)直接将数据集D划分为两个互斥的集合,其中一个集合作为训练集S,另一个作为测试集T,即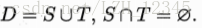
注意:
- 训练/测试集的划分尽可能保持数据分布的一致性,避免因数据划分过程中引入额外的偏差而对最终结果产生影响,例如:在分类任务中至少要保持样本的类别比例相似,一般可以采用分层采样方法进行采用。
- 即便在给定训练/测试集的样本比例后,仍存在多种划分的方式对初始数据集D进行分割,因此,单次使用留出法得到的估计结果往往不够稳定,在使用留出法时,一般要采用若干次随机划分、重复进行实验评估后取平均值作为留出法的评估结果。
1.2 交叉验证法
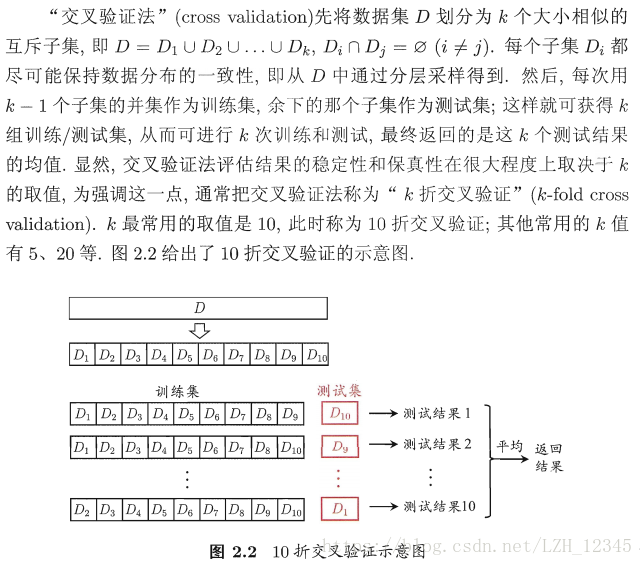
1.3 自助法
在留出法和交叉验证法中,由于保留了一部分样本用于测试,因此实际评估的模型所使用的训练集比D小,这必然会引入一些因训练样本规模不同而导致的估计偏差。留出法受训练样本规格变化的影响较小,但计算复杂度又太高了。

因此,在初始化数据量足够的情况下,留出法的交叉验证法更为常用。
二、度量性能


2.1 错误率与精度

2.2 准确率、召回率和F1
错误率和精度虽然常用,但不能满足所有任务需求。实际上,错误率这个度量掩盖了样例如何被分错的事实。在机器学习中,有一个普遍适用的称为混淆姐阵(confusion matrix )的工具,它可以帮助人们更好地了解分 类中的错误。

准确率和召回率是一对矛盾的度量,一般来说,准确率高时,召回率往往偏低;而召回率高时,准确率往往偏低。通常只有在一些简单的任务中,才能使得召回率和准确率都很高。
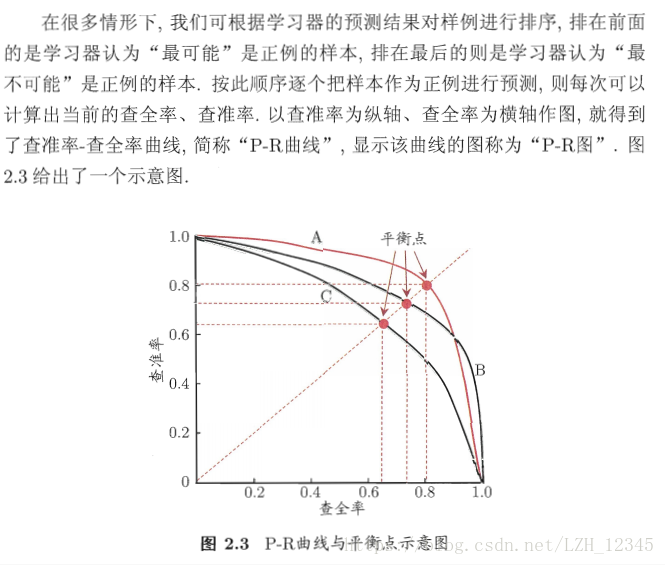
从上图可以看出:
- 若一个学习器的P-R曲线被另一个学习器的曲线完全“包住”,则可断言后者的性能优于前者,例如:A的性能优于C;
- 若若两个学习器的P-R曲线发生交叉,则难以一般性的断言两者孰优孰劣,只能在具体的准确率和召回率条件下进行比较;
- “平衡点“(Break-Event Point,简称BEP)即”准确率=召回率”时的取值,例如:基于BEP的比较,A优于B;
- BEP过于简单,F1度量更为常用。
F1度量:

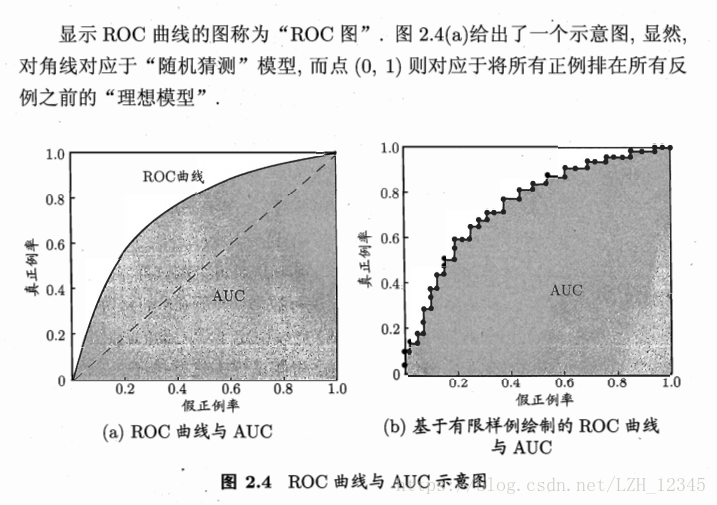
2.3 ROC和AUC
很多学习器是为测试样本产生一个实值或概率预测,然后将这个预测值与一个分类阈值(threshold)进行比较,若大于阈值则分为正类,否则为反类。
在不同的应用任务中,我们可根据任务需求来采用不同的截断点,如:当我们更重视“准确率”时,则可以将排序中靠前的位置进行截断;若更重视“召回率”时,则可选择靠后的位置进行截断。因此,排序本身的质量好坏,体现了综合考虑学习器在不同任务下的“期望泛化性能”的好坏。而ROC曲线则是从这个角度出发来研究学习器泛化性能的有力工具。


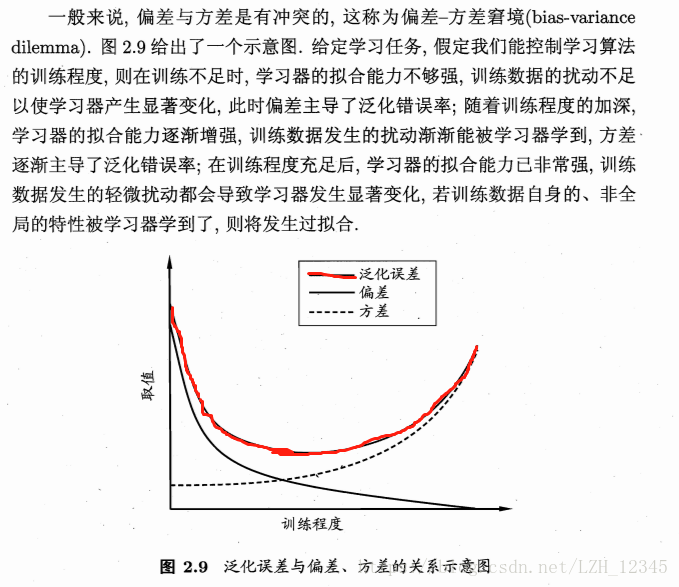
三、偏差和方差
“偏差-方差分解”是解释学习算法泛化性能的一种重要工具。


为了便于讨论,假定噪声期望为零,