编者按:随着对大语言模型(LLM)评估领域的深入研究,我们更加清楚地认识到全面理解评估过程中的问题对于有效评估LLM至关重要。
本文探讨了机器学习模型评估中出现的常见问题,并深入研究了LLM对模型评估领域带来的重大挑战。在评估方法方面,我们将其划分为直接评估指标、基于辅助模型的评估和基于模型的评估。本文还强调了审慎观察复杂评估指标和注意细节的重要性。
以下是译文,Enjoy!
作者 | NLPurr
编译 | 岳扬
目录
01 Introduction
02 机器学习模型评估流程中的常见问题
-
2.1 数据泄漏(Leakage)
-
2.2 测试样本的覆盖率(Coverage)
-
2.3 测试评估样本与任务无关(Spurious Correlations)
-
2.4 数据集划分和表述改写(Partitioning and phrasing)
-
2.5 随机数种子(Random seed)
-
2.6 准确率与召回率的权衡
-
2.7 未解释的一些决策
03 大模型评估的组成内容
-
3.1 评估数据集(Evaluation Datasets)
-
3.2 模型的输出内容(Model Output)
-
3.3 对样本数据或模型输出进行某种形式的转换 Sample/Output Transformation
-
3.3.1 Looped Transformations 循环转换
-
3.3.2 Chained Transformations 链式转换
-
3.3.3 Atomic Outputs 原子输出
-
3.3.4 Constrained Output 受约束的输出
-
3.4 Ground Truth
-
3.5 评估媒介 Evaluation Medium
-
3.5.1 直接评估指标
-
3.5.2 Indirect or Decomposed Model-Based Evaluation 间接或分解的基于模型的评估
-
3.5.3 基于模型的评估
-
3.6 性能报告 Performance Report
04 tl;dr
目前,模型构建(modeling)、扩展(scaling)和泛化(generalization) 等方面的技术发展得比对其进行评估测试的方法更快,这就导致了对模型评估不足和对模型能力存在过高估计或夸大。AI模型的各种能力都是让我们惊叹的,但如果我们没有一种工具来确定这种能力到底具体是什么,或者AI模型在这种能力上究竟表现如何,那么我们可能会一直相信AI模型在任何场景下都能胜出。

01 引言
每当有关于模型评估的热门论文发布时,我们总会困扰于同一个问题:如何确定这是一种优秀的评估方法呢?
而不幸的是,获得答案并不容易,我甚至可以说,及时我们得出了答案,很可能也是不可靠的。即使对于简单的分类模型,评估(evaluation)和基准测试(benchmarking,(译者注:对模型性能进行评估和比较的过程))也已变得相当复杂。老实说,我们还没有找到解决小型生成式模型和长文本生成(long form generations)相关评估问题的方法;然后突然间,我们面临着大量庞大的、多用途的语言模型,即所谓的基础(语言)模型(foundation models)。
现在每个人手上都有这些经过精心处理的学术数据集,这些人根据这些数据集进行统计和展示相关数据、结果或其他内容,但很可能当整个互联网的数据都被爬取时,这些数据集的信息已经泄漏到训练集中了;而且,作为从事机器学习的专业人士,我们可能没有接受过基本统计知识的学习,这可能导致在技术方法上存在一些不完善之处。
02 机器学习模型评估流程中的常见问题
大模型评估流程中始终伴随着一些常见的问题。我在撰写本文时假设每个人都默认存在下面这些问题,因为之前很多机器学习模型中也存在这些问题。
2.1 数据泄漏(Leakage)
测试数据集中的信息泄漏到训练集中。这在大语言模型(LLM)中尤为常见,因为数据集的具体细节通常不详细,有时甚至是保密的。
2.2 测试样本的覆盖率(Coverage)
测试样本的覆盖率也是一个需要考虑的问题。评估数据集往往无法全面覆盖特定任务的各种评估方式。可能导致准确性问题、变异性问题、样本大小问题或鲁棒性问题。
译者注:
准确性问题(Accuracy problems) :指评估过程中得到的模型准确度不足或与期望结果存在差异的情况。
变异性问题(Variability problems) :指在多次评估中,同一模型在不同数据集或评估条件下产生不一致的结果。
样本大小问题(Efficient sample size problems) :指评估所使用的样本大小可能不足以充分代表模型运行的各种情况。
鲁棒性问题(Robustness problems) :指模型在面对不同数据分布、噪声或输入变化时的性能表现的不稳定性。
2.3 测试评估样本与任务无关(Spurious Correlations)
存在一些实质上并不相关的或重复的测试样本。许多任务的评估集被发现存在“走捷径”的解决方案。因此,虽然我们可能认为这些测试样本能很好地评估特定任务,但实际情况往往并非如此。
2.4 数据集划分和表述改写(Partitioning and phrasing)
处理评估数据集的划分问题是十分困难的。许多评估数据集都有同一问题的不同回答方式,它们也可能导致无意的数据泄露。例如,在以人为中心的任务中,评估数据集通常没有用户隔离,而只是基于样本进行划分。
2.5 随机数种子(Random seed)
神经网络的输出通常都略微依赖于随机数种子(Random seed)。如果仅基于一次单独的推理操作(singular inference run)来进行报告,可能会导致不准确的结果,并且无法完整地呈现问题的具体情况。
2.6 准确率与召回率的权衡
很多人都比较认可准确率,但是我们都知道,在不同任务中,误报和漏报的影响是不同的。例如,使用机器学习模型进行信息检索,出现误报或者漏报一个结果可能还可以容忍。但是,如果在passive health monitoring(译者注:一种通过收集和分析个体的生物信息、生理数据或行为模式等来进行健康状态监测的方法)中使用同样的模型,出现漏报情况就让人不可接受了。
2.7 未解释的一些决策
在机器学习领域中,关于保留数据还是丢弃数据的决策有很多。比如,在音频领域,为了在文献或其他材料中展示结果,通常会丢弃长度不足某个阈值的数据样本,因为这些样本可能不能被视为有效的语音。了解并解释这些阈值不仅对于论文评审和讨论很重要,也对于其他人是否能够重现实验结果至关重要。
03 大模型评估的组成内容
现在我们已经了解了机器学习模型评估流程中的常见问题,让我们来谈谈LLM评估内容的组成部分。可以将大语言模型(LLM)评估内容分解为以下6个部分,即评估数据集(Evaluation Datasets)、模型的输出内容(Model Output)、对样本数据或模型输出进行某种形式的变换 Sample/Output Transformation、Ground Truth、评估媒介 Evaluation Medium、性能报告 Performance Report。
3.1 评估数据集(Evaluation Datasets)
Evaluation Datasets(或被称为Evaluation Sets、Eval Sets)是用于对模型进行评估的测试样本。构建和使用评估数据集有多种方式,每种方式都存在一些问题。
如果使用相似的数据集进行评估,又会带来另一些问题:
-
prompts的模糊性: 既然流程中涉及 prompts,我们需要考虑prompt本身可能存在的模糊性。虽然评估数据集(Evaluation Datasets)是在没有任何“instruction language”和“prompted addition”的情况下使用的,但测试数据样本至少保持一致。(译者注:Instruction language:在使用生成模型时,我们可以通过输入一些指令性的语言来引导模型生成特定类型的回答或完成特定的任务。这些指令可以是问题的具体要求、对话的背景信息、预期的回答格式等。Prompted addition:指在输入给模型的文本中添加额外的提示信息,以引导模型生成特定的回答或执行特定的任务。可以是在输入中直接附加一些特定的关键词、短语或问题,以激发模型的特定注意力和创造力)
-
不可追踪性: 回到数据泄露(data leakage)这一问题,尽管过去一直存在这个问题,但现在由于没有人知道具体哪些数据会进入模型,即使进行了最真诚的、拥有多重检查的评估,也无法确保评估样本数据是否在训练数据集中。
评估数据集可以是以下这几种形式:
1. 预整理的数据集: 这些预整理的(Pre-curated)评估数据集来源于各种标准化测试,这些测试大多是为人类而不是为模型设计的。此外,这些数据集可能具有基于记忆的问题(memorization based questions),有可能会误以为是对大语言模型(LLM)理解能力的评估。(关于基于记忆的问题(memorization based questions),译者有如下注释:对于语言模型来说,如果它能够准确地记住并提供正确的答案,可能会被误认为是对问题理解的展示,尽管实际上它可能没有深入理解问题的背景和含义。因此,在评估大语言模型(LLM)时,需要注意这种偏向记忆的问题可能会导致错误的评估结果。)

What Disease does this Patient Have? A Large-scale Open Domain Question Answering Dataset fromMedical Exam[1]
2. 互联网上爬取的评估集: 这种评估数据集是通过从互联网上搜索特定标签,并将这些标签作为样本的标签来创建,也可由标注工作人员进行人工标注。这些评估集中的样本很可能已经存在于基础模型的训练集中,因此仅依靠这些数据集进行评估通常不可取。

TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension[2]
3. 人工整理的评估集 : 这些测试集通常被用来防止数据泄漏。毕竟,人类可以创建许多独特的评估数据进行评估。然而,这种数据集也存在一些缺点,如规模较小,难以创建和更新。

《Evaluating Large Language Models Trained on Code》提出的HumanEval数据集[3]
4. 模糊化的(Fuzzed)评价集: 这些是现有评估数据集的变种或扩展版本,其目的是测试模型在面对各种变化时(variability)的行为。前面说的variability可以是有意的对抗性变化,也可以是为了引入超出其训练数据范围的标签,以测试其鲁棒性,或者仅用于创建意义上等效的样本。

例如,像PromptBench中提出的那样,一组对抗性的prompt和输入,作为原始评估样本的补充或替换。[4]
5. 根据评估人员的直觉、经验和知识随机选择评估用例: 以对话形式对模型进行评估,尽管这些样本很可能是准确的,但也可能受到一定偏见的影响。通常情况下,评估者需要知道问题的解决方法才能进行评估,这可能导致所谓的“human imagination collapse”,即评估者被设定在固定的测试轨迹上,而不具备多样化。

通过《OpenAssistant Conversations - Democratizing Large Language Model Alignment》的单轮或多轮对话评估模型[5]
3.2 模型的输出内容(Model Output)
几乎我们提出的所有解决方案都存在一个严重问题:即使用判别型输出(discriminative outputs)来评估生成式模型。
模型的输出在很大程度上取决于(a)得到正确回答所要求的prompt 和(b)所要求的回答。例如,要求模型给出0或1的标签,与要求模型给出文字标签(例如:spam或non-spam)相比,可能会得到不同的结果。再举一个例子:要求模型直接输出并提取答案,可能会得到与具有多种选择的情况下不同的答案。
基于回归的模型输出可能缺乏可伸缩性(译者注:此处的意思应当是回归模型的输出结果在不同语境或评估尺度下可能无法简单调整或直接比较,需要在将模型应用于不同背景时进行仔细比对和考虑),因此可以改变回归模型输出的标准差和均值。例如,假设你有一个模型可以对某个产品进行评分,并且该评分的范围是从0到10,其中10表示最高评分。现在,你可能希望将这个评分转化为0到1的范围,以便更好地进行比较或分析。但是,简单地将评分除以10并不足以确保评分在不同尺度下的一致性。
3.3 对样本数据或模型输出进行某种形式的转换 Sample/Output Transformation
对模型的输入或输出进行转换,可以大致分为四类:
3.3.1 Looped Transformations 循环转换
Looped Transformations通常遵循以下理念:我们可以将模型的输出与当前回答的某种形式的评估(可以是同一模型、另一个模型或人工评估)相结合,并将其再次输入模型,直到达到理想的结果。这种方法的例子一种被称为自评模型(Self-Critique models)(通过反复迭代模型的输出和评估,从而不断优化结果)

《Reflexion: Language Agents with Verbal Reinforcement Learning》为Reflexion开发了一种模块化的框架,利用了三个不同的模型:一个Actor模型生成文本和动作;一个Evaluator模型对Actor产生的输出进行评分;以及一个Self-Reflection模型,生成口述的增强提示,帮助Actor自我改进。[6]
3.3.2 Chained Transformations 链式转换
链式转换这种方法通常在一系列的model input → output → model input之间没有可供衡量的评估标准。这些链 (...->model input → output → model input->... 链条) 通常是预先定义的,并且有一定数量的路径可供遵循。
3.3.3 Atomic Outputs 原子输出
这种方法涉及将模型的输出分解为原子组件,可以通过人工方式、基于规则的系统(a rule based system) 或者通过人工智能进行评估,将模型的输出分解成可以单独评估的原子组件,然后加权组合得到评估结果。
3.3.4 Constrained Output 受约束的输出
这种方法通过使用对数概率(在GPT3.5/GPT4 API中不可使用)或其他内部约束来确保模型的响应仅包含事先决定或允许的tokens内容。这样可以限制模型生成的输出内容的范围,使其符合特定的约束条件。
3.4 Ground Truth
其实这方面并不需要过多的解释,但有一些方面需要我们注意,特别是当你需要考虑评估场景中的Ground Truth时。(译者注:Ground Truth通常用于指代被认为是正确答案或参考标准的数据集、注释或标签。它是算法训练和评估的基准,用于验证模型的准确性和性能。然而,需要注意的是,Ground Truth可能具有主观性、不确定性或争议性,因此在评估和应用中需要谨慎处理。)
首先,Ground Truth可能存在偏见、不确定性或高度分歧的情况。 在涉及到人类的任务(如对散文的喜好程度)时,通常会将分歧平均处理(the disagreement is often averaged out),而不是作为注释曲线(annotation curve)来考虑。(译者注:annotation curve是在对某项任务进行人工标注时,不同标注者之间在给定样本上所得出的不同标注结果的一种可视化表示。它用于表示在同一个任务中,不同标注者对于给定输入的标注结果之间的差异程度。)因此,需要多次比较模型的输出才能得出真实的分布对比结果(true distribution comparison)(译者注:此处指将模型的输出与任务的真实或期望分布进行比较,以评估模型的性能和准确度。)。
在进行大模型评估的过程中,要知道在某些评估中可能有ground truth,也可能没有ground truth。
请记住ground truth可能存在的三个陷阱:
● Ground truth已被包含在循环转换或链式转换中。
● Ground truth已被包含在上下文或少样本学习示例中对prompt进行引导或调整的部分。
● Ground truth可能被用于构建评估指标间的相关性,但在实际评估模型性能时,没有直接使用ground truth进行比较。
3.5 评估媒介 Evaluation Medium
在我看来,评估媒介可以分为三个不同的类别。
3.5.1 直接评估指标

《Textbooks are all you need》用HumanEval和MBPP进行评估[7]
首先是“直接评估指标”这一类别。这些是在人工智能领域长期以来广泛使用的传统指标。像准确率(accuracy)和F1得分(F1 score)等指标属于这个类别。通常情况下,这种方法涉及从模型中获取单一的输出,并将其与参考值进行比较,可以通过约束条件或提取所需信息的方式来实现评估。 (译者注:在这种方法中,模型会生成一个输出结果,例如对话回复、分类标签或其他内容。然后,会将这个输出结果与参考值进行比较,以评估模型的性能或准确率。比较的方式可以通过约束条件来进行。例如,对于多项选择题的答案评估,约束条件可以是选择字母的匹配或完整选项的匹配。通过将模型的输出与参考答案进行匹配,我们可以判断模型是否产生了正确的结果。另一种比较方式是通过提取所需信息来进行。例如,在对话生成任务中,我们可能会提取模型生成的句子或回复中的特定信息,并将其与参考信息进行比较。通过比较提取的信息,我们可以判断模型的输出是否符合预期。)
“直接评估指标”的评估可以通过临时的基于人工对话的评估、预整理的专门数据集或直接的注解来完成。例如,有一种直接评估指标是将模型的准确率直接与ground truth进行比较。在评估多项选择题的回答时,可以通过匹配选项字母、完整选项或选项分布进行比较。如果想更深入地了解这些评估方法是如何影响结果的,请阅读这篇文章:What‘s going on with the Open LLM Leaderboard?[8]
3.5.2 Indirect or Decomposed Model-Based Evaluation 间接或分解的基于模型的评估

基于同一模型的评分标准。《TinyStories: How Small Can Language Models Be and Still Speak Coherent English?》[9]

《Self-critiquing models for assisting human evaluators》[10]

《G-EVAL: NLG Evaluation using GPT-4 with Better Human Alignment》使用form-filling进行评估,然后计算出与人类偏好的相关性。[11]

《LLM-EVAL: Unified Multi-Dimensional Automatic Evaluation for Open-Domain Conversations with Large Language Models》中的组件式模型驱动的评估分数[12]
接下来是第二类方法,称为“间接或分解的启发式方法(indirect or decomposed heuristics)”。在这种方法中,我们利用较小的模型(smaller models)来评估主模型(the main model)生成的答案,这些较小的模型可以是微调过的模型或原始的分解模型(raw decompositions)。其核心思想是选取在这些大模型擅长的任务上表现更好的小模型来进行评估。这些较小模型的输出被看作是弱得分(weak scores),然后将它们结合起来为生成的输出提供一个最终的标签或评价。这种间接评估方法能够更加细致地评估模型的性能,尤其在判断对散文的喜爱程度等这些任务。虽然这些模型引入了一定的变异性(variability),但需要注意的是,它们通常是为回归任务而训练的,并为特定的目的进行微调。(关于变异性(variability),译者有以下注释:在评估模型或数据时,变异性指的是不同样本或实例之间的差异程度。较高的变异性意味着样本之间存在很大的差异,而较低的变异性表示样本之间相对一致或相似。)
实际上,这种评估方法与下一种方法之间的界限有些模糊,尤其是在其对结果的影响程度以及可能存在的错误性或不确定性。因此,欢迎大家提出更好的评估标准!
3.5.3 基于模型的评估
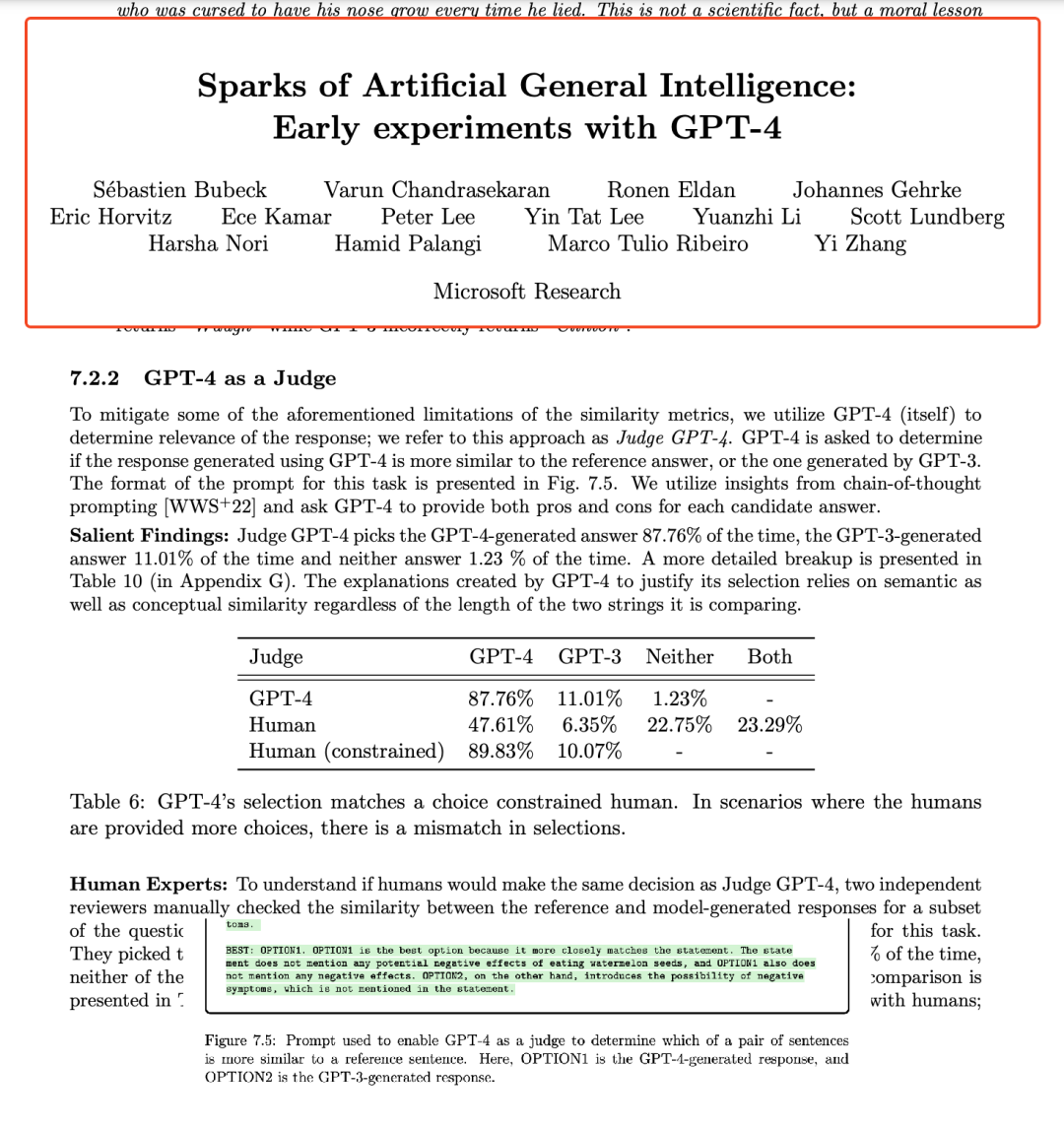
在《Sparks of AGI》中,通过将回复与参考的ground truth进行比较来进行评估。请记住,这包括了ground truth,并且可能是问题最少的模型驱动的评估形式之一。[13]

《Bring Your Own Data! Self-Supervised Evaluation forLarge Language Models》基于模糊输入样本的模型输出不变性进行了自监督评估。[14]

《Textbooks are all you need》使用GPT4进行评估[15]

从《Language Models (Mostly) Know What They Know》中询问AI部分的情况。[16]
第三类评估方法被称为”基于模型的评估”。在这种方法中,模型本身提供最终的评估分数或评估结果。然而,这也引入了额外的可变因素。即使模型可以获取到ground truth信息,评估指标本身也可能在评分过程中产生随机因素或不确定因素。举一个常见的评估问题:“生成的输出(O)与ground truth answer(G)相似吗?” 这个问题的答案不仅取决于模型输出的随机性,还取决于评估指标本身的可变性。
需要知道的是,现在的大模型评估实践,可能会在评估过程中包含或排除ground truth。
这导致出现了两种基于模型的评估方式:
[包含ground truth数据] 要求模型将输出与ground truth数据进行比较,并给出肯定或否定的答案。这也可以看作是向模型提供两段陈述,并要求它给它们贴上 “entailment”(蕴涵)和 “paraphrasing”(改写)或两者都是的标签。(译者注:蕴涵是指判断一个语句是否可以从另一个语句中推导出来。在这个任务中,给定两个语句,模型需要确定第一个语句是否是由第二个语句推导出来的真实信息。例如,对于语句 A:“狗在公园里追赶球” 和语句 B:“有一只狗正在户外运动”,蕴涵判断会认为语句 A 蕴含于语句 B,因为语句 A 中提到了狗在公园里活动,而语句 B 中提到了一个狗正在户外活动,两者之间有相似之处。改写是指将一个语句重新表达为与原始语句具有相同或相似含义的不同形式。在这个任务中,模型需要生成与给定语句意思相近的改写语句。例如,对于语句 “我喜欢吃冰淇淋”,可能改写语句是这样“我爱吃冰激凌”,虽然表达方式有所不同,但意思是相似的。有时候基于模型的评估任务既包括蕴涵判断,也包括改写生成。模型需要同时判断两个语句之间的蕴涵关系,并生成与给定语句意思相似的改写语句。这种任务结合了蕴涵和改写的要素,旨在对模型的语义理解和语言生成能力进行综合评估。)
[排除ground truth数据] 要求模型直接对模型输出进行“判断”。在这种情况下,通常会将较小的模型的输出提供给更大的模型,并要求其评估答案的正确性。评估可以是简短的反馈、李克特量表(Likert scale)的答案或介于两者之间的任何形式。需要注意的是,并非所有的论文都支持用较大模型评估较小模型,这种方式比前者更加可疑。
对于这种情况,通常给出的解释是:“这也是人类进行此类工作的通用方式”。因此,我们希望GPT-4在评估时更接近人类,避免使用最初二元标签评估方式。例如,《Textbooks are all you need》[7]的作者们认为这是一种正确的评估方法。(译者注:例如“正确”或“错误”、“是”或“否”等。然而,这种二元标签可能限制了评估的全面性和准确性,因为它们无法提供更细致的信息或对复杂情况进行区分。可以使用更灵活的评估方式,比如打分、等级、程度或文本评论等)。
3.6 性能评估报告 Performance Report
在大模型评估领域中呈现性能评估指标时,我们需要慎重考虑。这些数字可能受到许多因素的影响,如数据集拆分和其他细微差异。使用不同的prompt和样本,并在每个样本上进行多次测试是最理想的做法。然而,这种方法相当消耗资源且需要对当下的评估框架进行重大修改。因此,在展示评估数据时,我们必须保持一定的怀疑态度并谨慎对待。
在大语言模型(如GPT)崛起之前,机器学习领域常常会对每个测试样本使用不同的随机模型运行多次测试。然而,由于在GPT模型的推理过程中无法控制随机数种子,因此建议至少进行三次测试。性能评估指标的平均值和标准差对于正确解释评估结果现在变得至关重要。尽管p-values可能有些复杂,但仅凭少数几个点的差异和单个推理结果来宣称这个模型有明显的改进就更有问题了。
另一个需要考虑的方面是性能****评估报告的详细程度。许多学术数据集本身存在各种问题,而在这些大型多任务数据集上取平均值,而不考虑每个测试样本的具体评估目标,进一步加剧了这个问题。目前,大部分评估报告甚至在基于任务的评估中都缺乏足够多的细节,更别提基于样本级别的细致分析了。
Mosaic 30B(发布于2023年6月22日)提出了将基准(benchmarks)合并成主题组(thematic groups)的概念,以进一步探索这个问题。(关于将基准(benchmarks)合并成主题组(thematic groups),译者有以下注释:这种方法有助于更好地了解模型在特定主题或领域中的表现,并提供更具针对性的反馈和改进建议。例如,对于语言模型,可以将针对文本生成、问答和阅读理解等任务的基准组合为一个主题组,从而对模型在这些相关任务上的综合表现进行评估。)
最后,我们必须讨论“prompt fine-tuning”这个概念。很多研究论文通过使用特定任务的最佳prompt来展示测试集的结果。虽然这种方法在理论上似乎合理,但在解决普通用户遇到的real-world问题时,这种方法并不能可靠地衡量模型的性能。 如果是想要将prompt作为pipeline中的辅助组件使用,那么使用适合该任务和模型的最佳prompt是可以接受的。然而,对于直接面向用户的端到端(end-to-end)模型而言,必须认识到每次都能使用最佳的prompt可能对所有用户来说并不现实或可行,尤其是对于通用模型来说,这一点至关重要。
04 tl;dr
在语言模型(LLM)评估领域中,我们一直在努力解决与模型评估可靠性相关的复杂问题。事实上,模型评估和基准测试(benchmarking)一直都具有挑战性,而大型多用途模型的出现则更进一步加剧了其复杂性。数据泄漏(data leakage)、样本覆盖率限制(coverage limitations)、测试评估样本与任务无关的情况和数据划分难题等困扰着我们进行模型评估。 此外,精确率和召回率之间的权衡以及ground truth的缺乏也使情况变得更加复杂。本文探讨了机器学习模型评估中的常见问题,并深入研究了LLM对模型评估领域所带来的重大挑战。我们将评估方法分为直接评估指标、基于辅助模型的评估和基于模型的评估,旨在揭示每种方法之间的微小差别。我们需要以审慎的眼光来观察复杂的性能评估指标,并需要注意细节的重要性。同时,我们还了解了Prompt-fine tuning的相关问题,这提醒我们要考虑用户交互的现实场景。随着我们对大模型评估领域的深入研究,我们清楚地认识到全面理解这些复杂问题对于有效评估LLM至关重要。
END
参考资料
1.https://arxiv.org/pdf/2009.13081v1.pdf
2.https://arxiv.org/pdf/1705.03551.pdf
3.https://arxiv.org/abs/2107.03374
4.https://arxiv.org/pdf/2306.04528.pdf
5.https://arxiv.org/pdf/2304.07327.pdf
6.https://arxiv.org/pdf/2303.11366.pdf
7.https://arxiv.org/pdf/2306.11644.pdf
8.https://huggingface.co/blog/evaluating-mmlu-leaderboard
9.https://arxiv.org/pdf/2305.07759.pdf
10.https://arxiv.org/pdf/2206.05802.pdf
11.https://arxiv.org/pdf/2303.16634.pdf
12.https://arxiv.org/pdf/2305.13711.pdf
13.https://arxiv.org/pdf/2303.12712.pdf
14.https://arxiv.org/pdf/2306.13651.pdf
15.https://arxiv.org/pdf/2306.11644.pdf
16.https://arxiv.org/pdf/2207.05221.pdf
本文经原作者授权,由Baihai IDP编译。如需转载译文,请联系获取授权。
原文链接:
https://nlpurr.github.io/posts/case-of-llm-evals.html