算法特性:在监督学习中进行二元分类的常用算法
算法详解:
我们希望输入一个自变量x,通过算法输出二元分类的结果。那么应该如何来构造这样一个数学模型呢?
事实上我们更希望这个数学模型可以实现这样一个过程:输入一个待分类的自变量(可以是一张图片、一段音频或其他),如何输出的是一个概率,表示数学模型对输入的概率预测。这样的话我们就可以通过神经网络模型来搭建我们的logistic数学模型了。
我们可以将x统一处理为一个维的矩阵,即
,同时设定一个参数矩阵
,这样模型就可以定义为:
,但是稍加思索,我们发现此时的模型在训练中容易产生系统偏差,故此考虑加上偏差矫正参数
,即:
,但是此时的输出
并不总是在区间
中,不满足统计要求。故此我们需要利用一个限幅函数:sigmoid(),来使得
,图形如下:
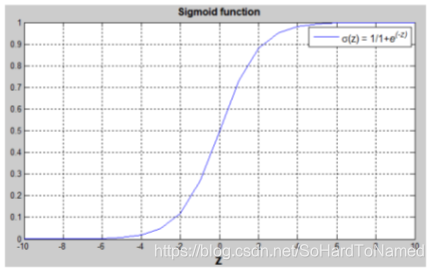
故最后logistic模型为:
其中
