Python实现 logistic 回归算法
1、算法介绍
模型描述:
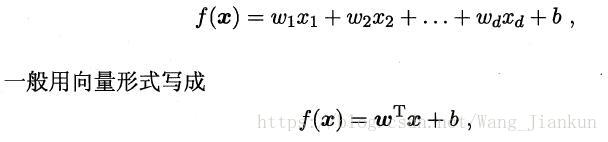
sigmoid函数:
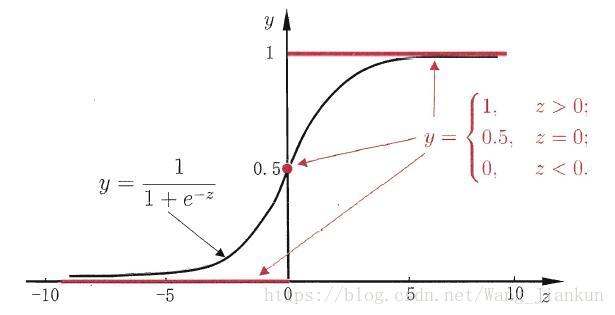
原理: 优化目标:最小化 sigmoid(f(x)) 和真实标签的差别(有不同的 cost function)。运用算法(梯度上升等)更新参数w、b。
2、Python代码实现及注释
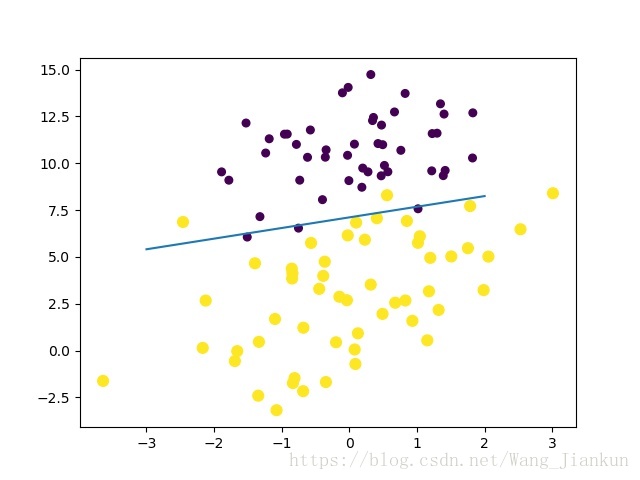
决策边界:
代码:
import numpy as np
from matplotlib import pyplot as plt
# 加载数据集
def loadDataset(filename):
# 数据集
dataList = []
# 数据样本
labelsList = []
fr = open(filename)
for line in fr.readlines():
lineArr = line.strip().split()
# 添加一个值为1的特征,对应于参数b
dataList.append([1.0, float(lineArr[0]), float(lineArr[1])])
labelsList.append(int(lineArr[-1]))
return dataList, labelsList
# sigmoid函数计算
def sigmoid(z):
return 1.0/(1+np.exp(-z))
# 运用标准的梯度上升法更新参数
def gradAscent(dataList, labelsList):
dataMat = np.mat(dataList)
labelsMat = np.mat(labelsList).T
m, n = np.shape(dataMat)
learningRate = 0.1
maxCycles = 1000
weights = np.ones((n, 1))
for i in range(maxCycles):
a = sigmoid(dataMat*weights)
# 梯度计算的公式
error = labelsMat - a
# 更新参数
weights = weights + learningRate*dataMat.T*error/m
return weights
# 运用随机梯度上升更新参数
def stocGradAscent(dataList, labelsList):
m, n = np.shape(dataList)
maxCycles = 200
weights = np.ones(n)
for j in range(maxCycles):
for i in range(m):
# 学习率递减
learningRate = 4/(1.0+j+i)+0.01
# randIndex = int(np.random.uniform(0, m))
# 计算 sigmoid 一次只计算一个样本
a = sigmoid(np.sum(dataList[i]*weights))
error = labelsList[i] - a
weights = weights + learningRate*error*np.array(dataList[i])
return weights
# 绘制数据集及决策边界
def plotLine(dataSet, labels, weights):
# 绘制数据集,不同类别颜色不同
plt.scatter(np.array(dataSet)[:, 1], np.array(dataSet)[:, 2], 30 * (np.array(labels)+1), 15*np.array(labels))
# 令表达式=0绘制决策边界
x = np.expand_dims(range(-3, 3, 1), 1)
y = (-weights[0]-x*weights[1])/weights[2]
plt.plot(x, y)
plt.show()
# 测试 logistic 回归分类器
def predict(sample, weights):
# 重构样本特征向量
sample = np.array([1.0, sample[0], sample[1]])
prob = sigmoid(np.sum(sample*weights))
if prob > 0.5:
print("this is a positive")
else:
print('this is a negative')
if __name__ == '__main__':
# 加载数据集
dataList, labelsList = loadDataset('testSet.txt')
# 得到模型参数
# weights = gradAscent(dataList, labelsList)
weights = stocGradAscent(dataList, labelsList)
print(weights)
# 绘制决策边界
plotLine(dataList, labelsList, weights)
# 测试分类器
sample = np.array([1, 9])
predict(sample, weights)