A Morphable Model For The Synthesis Of 3D Faces
1.摘要
本文介绍了一种新的三维纹理人脸建模技术。3D人脸可以从一张或多张照片中自动生成。

通过3D人脸模型数据库生成人脸可形变模型,输入的2D图片经过人脸分析匹配到相应的3D人脸形变模型,再通过一定的调整生成3D输出。
2.3D人脸形变模型
人脸的几何信息通过形状向量S= 来表示,X,Y,Z都市n个点的坐标信息。
人脸的纹理信息通过纹理向量T=
,R,G,B表示所在定点的RGB值
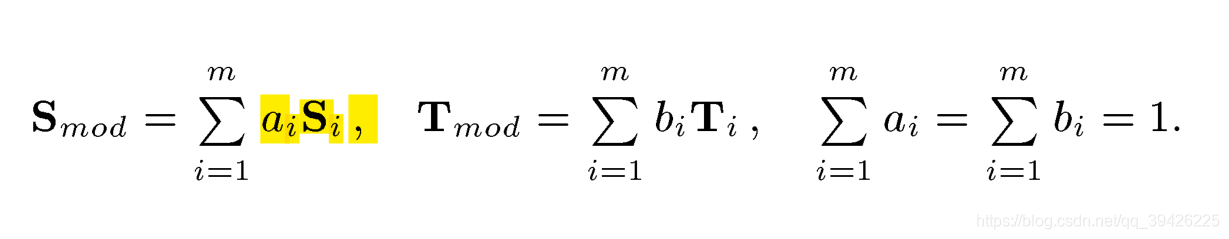
第i个人脸的的形状由形状基
和共轭复数
控制,第i个人脸的的纹理由纹理基
和共轭复数
控制,通过共轭参数
,
可以控制人脸生成不同的形状和纹理。
对于一个有用的人脸合成系统来说,能够根据人脸的可信性来量化结果是很重要的。因此,我们从我们的人脸的数据集中估计了系数
和
的概率分布。这种分布使我们能够控制系数
和
的可能性,并同时控制生成的人脸出现的可能性。
对于上述的200张人脸,求出他们的平均形状
,
,通过PCA得到si,ti为协方差矩阵Cs,Ct的特征向量
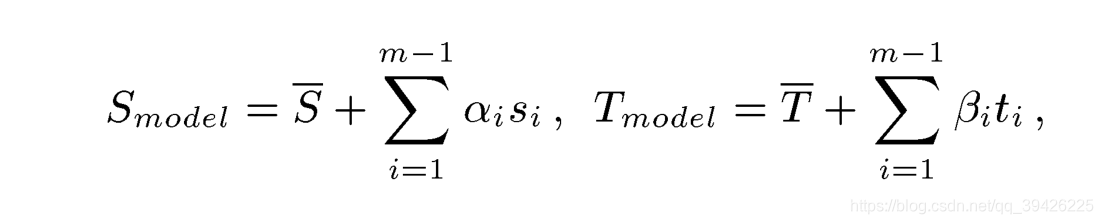
1.通过PCA技术找到相互正交的形状基和纹理基使得可以控制人脸一条条的进行形变而不是原来的整张人脸。
2.为什么是m-1求和而不是m求和:
由于抽取了平均人脸形状和纹理,所以他的维度最多是m-1
PS:PCA流程(这里简单的说一下,详细请点击下面的链接 PCA数学原理解析)
设有m条n维数据。
1)将原始数据按列组成n行m列矩阵X
2)将X的每一行(代表一个属性字段)进行零均值化,即减去这一行的均值
3)求出协方差矩阵C=1/m )求出协方差矩阵的特征值及对应的特征向量
5)将特征向量按对应特征值大小从上到下按行排列成矩阵,取前k行组成矩阵P
6)Y=PX即为降维到k维后的数据

通过调节 ɑ和ɞ来控制shape和texture基来调节人脸。
3.脸部属性
1.面部表情由于面部表情在不同人脸上的表示是大致相同的,比如笑,哭,生气等,因此可以使用同一个参数应用到不同人脸上,即可达到想要的效果。

不同于上面的面部表情具有统一性,面部特征在不同的个体的差异会变得很明显,例如脸颊、嘴巴、眉毛的宽度以及鼻子的形状。因此在具体实现的时候,我们需要手动标定出这些特征点,来找到输入图像与模型的对应关系。
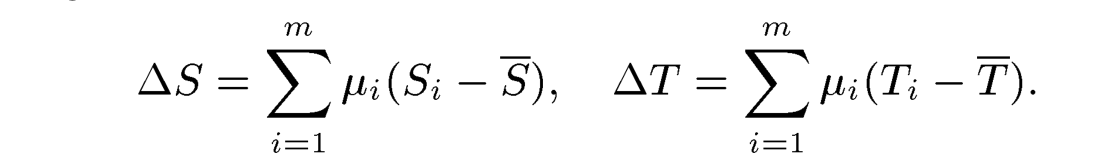
用u标注好权重的面部特征的delta S和delta T 可以直接在原有形变模型上进行加减使得可以作用于任何一个三维模型,来使它拥有或去掉对应的脸部特征。但是对应的特征很多,如果所有特征都用手工标定基本上不太现实,因此,做出假设u(S,T)是一个线性函数,这样寻找 是一个线性函数,这样寻找是一个线性函数,这样寻找delta u可以转化为存在确定值的最优解问题, 达到最优解条件为以下值最小
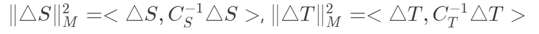
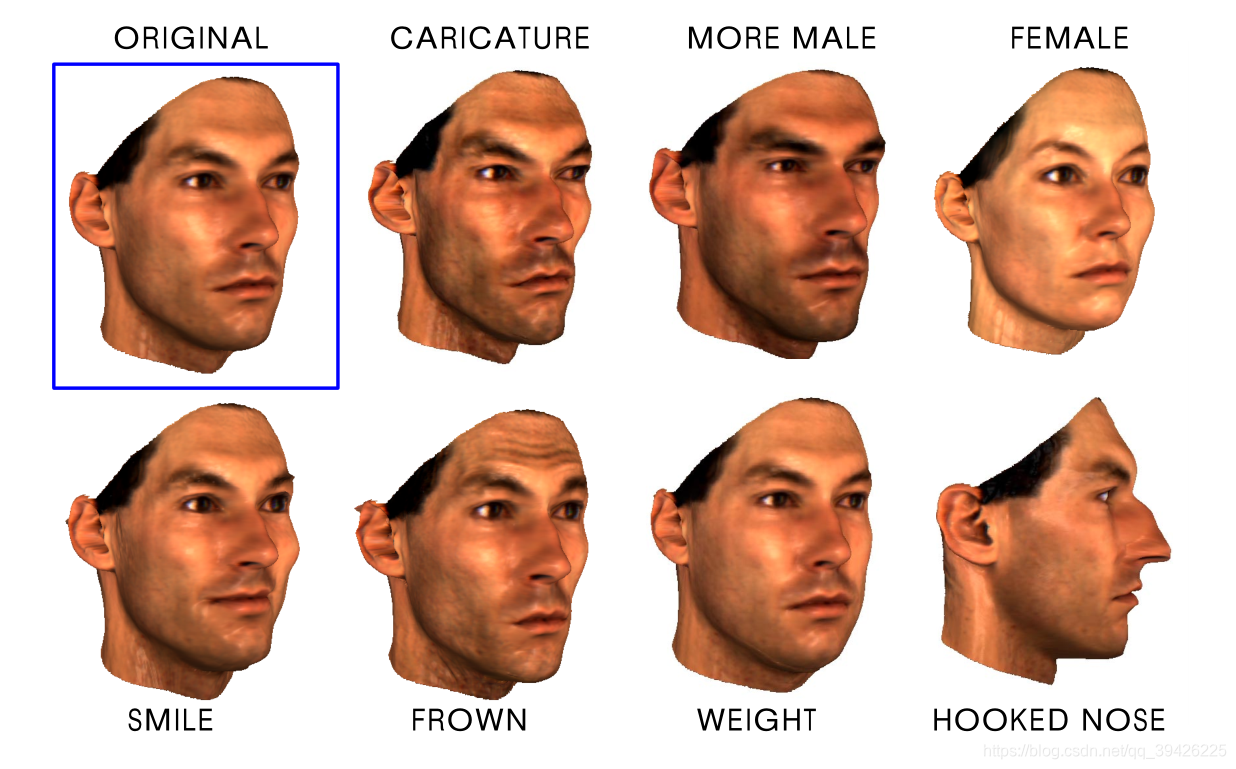
通过表情delta S和某些脸部特征delta S来控制人脸的特征。
4.图像匹配
1.我们的框架的一个关键元素是一个算法,自动匹配的形变人脸模型到一个或多个图像
2.优化了三维模型的系数系数ɑ,ɞ和一组渲染参数p,使其生成的图像尽可能接近输入图像。在综合分析的循环中,该算法根据当前模型参数创建纹理映射的三维人脸,渲染图像,并根据残差更新参数。

4.公式中的x,y值是基于3D曲面上随机选择点,估计
的值是从一个三角区域k的中心位置的纹理T
,3D位置S(
)的平均值,再通过中心化投影生成图片点P
。
5.要使输入的图片与重建后3D模型经过中心化投影和冯氏光照后的图片进行欧式距离最小化来使得原图和生成图误差最小,能量方程 的理解,范数的理解
6.上述的方法用于对比有一定的不适定问题,许多非表面类似的表面导致相同的图像,因此在我们的形态模型中,形状和纹理向量被限制在由数据库张成的向量空间
由 、 系数决定好的的脸部模型,在渲染的时候我们还需要的参数 ,因此我们可以继续将脸部模型扩充表示为,它包括了相机参数,对象尺寸,图像的旋转和平移,环境的光照强度等等,因此我们可以继续将脸部模型扩充表示为
**
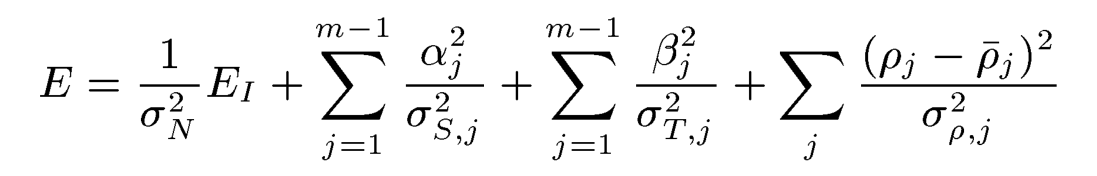
7.在贝叶斯决策理论中,为了解决上述不适定问题,我们可以对变化参数
)来控制使得P
最大也就是通过最小化代价函数来获得最大后验概率 ,代价函数如上图
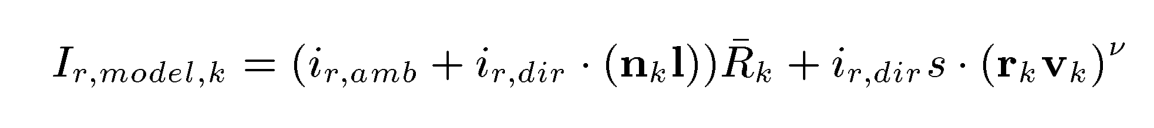
8.根据冯氏光照
,
,
模型也是采用这种形式上图方式:I是光照方向,
是摄像机位置与三角形中心位置的归一化差,
是反射光线的方向,s表示表面光泽,v控制镜面反射角度的分布,
,
,
代表环境光线,
,
,
代表定向光线。
**9.如果中心化投影到三角形的中心,则使用下面描述的方法进行测试:
.
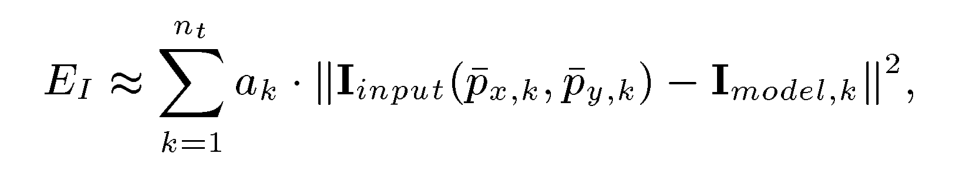
10.在梯度下降中,网格中不同三角形的贡献是多余的。因此,在每个迭代中,我们选择一个随机子集K∈{1,2,…,
}中的40个三角形区域,这种随机梯度下降方法不仅计算效率高,而且通过在梯度估计中加入噪声来避免局部极小值
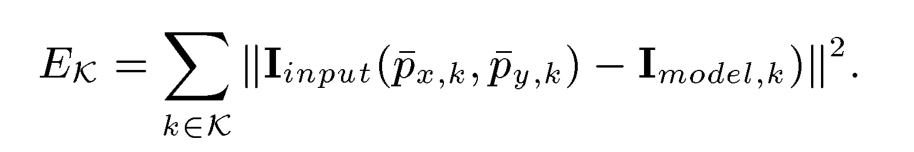
(1)从粗到细的图像匹配
由粗粒度到细粒度优化:为了避免局部极小,该算法在多个方面从粗到精的策略:
1、在低分辨率的形变模型中,对输入的图片这种进行下采样处理。
2、一开始要优化ɑ,ɞ来控制第一个主成分,随后优化p来优化其他成分,在随后的迭代中,添加了越来越多的主组件。
3、先试用大的高斯噪音的标准差,然后在慢慢减少。
4、在最后的迭代过程中,脸部模型的分解为小的Segment, 这个时候固定好ρ , 然后对于每一个Segment, 分别对α和β 参数进行优化,这样可以使得脸部的细节特征达到一个较好的优化。
(2)多图片处理
将此技术扩展到一个人的多个图像可用的情况是很简单的,形状和表情接收同一个共同
,
基控制,分割出不同的
来控制不同的图片输入角度,
替换为每对输入图像和模型图像的图像欧式距离之和,并同时优化所有参数,如下图
(3)光线校正和纹理提取
1.有特定的纹理不能被捕捉,例如表面瑕疵。
2.从图像中提取纹理是一种广泛应用于图像三维建模的技术。
3.在我们的程序中,这是可以实现的,因为我们的匹配程序提供了一个三维形状,姿态和光照的估计。

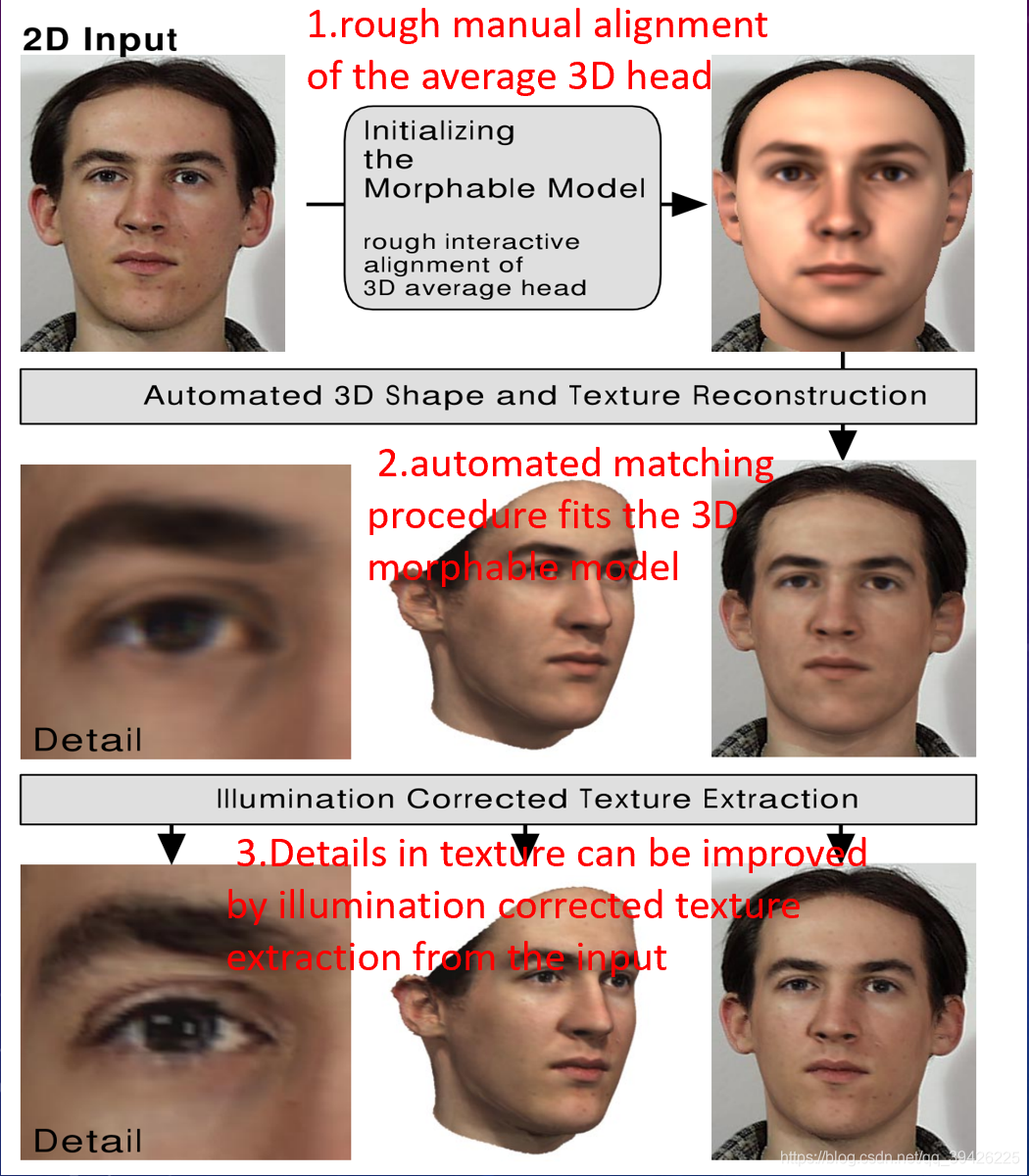
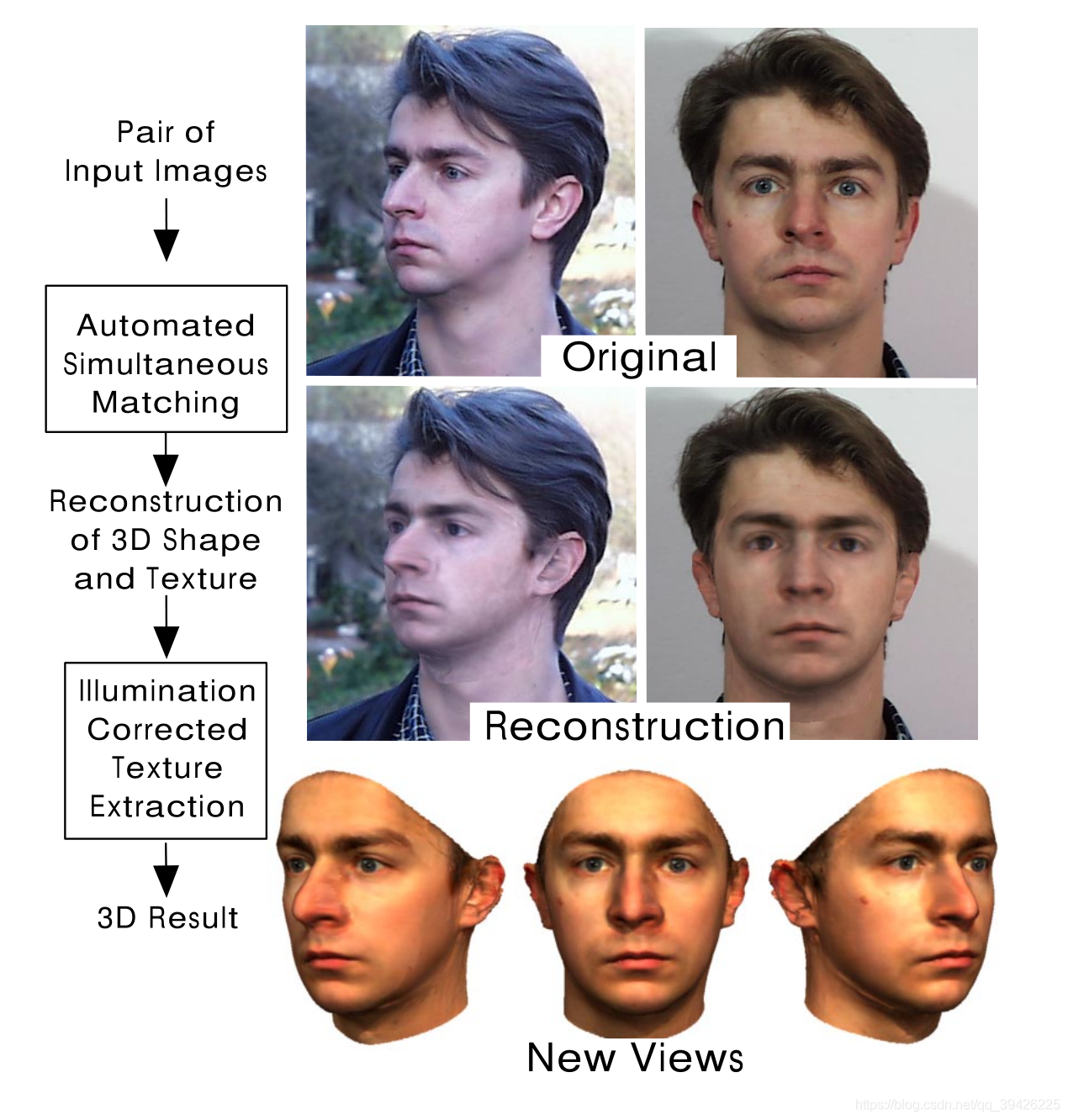
Last.结果

如上图,在手动初始化后,算法自动将彩色的morphable模型(颜色对比度设置为零)匹配到图像。在图像上绘制三维人脸的内部部分,可以生成新的阴影、面部表情和姿态

这是一些细节上的重建,表示=-=
