Lago de datos tal como lo vemos
Como equipo del centro de datos de iQiyi, nuestra tarea principal es gestionar y dar servicio a la gran cantidad de activos de datos dentro de la empresa. En el proceso de implementación de la gobernanza de datos, continuamos absorbiendo nuevos conceptos e introduciendo herramientas de vanguardia para perfeccionar la gestión de nuestro sistema de datos.
El "lago de datos" es un concepto que se ha debatido ampliamente en el campo de los datos en los últimos años, y sus aspectos técnicos también han recibido una amplia atención por parte de la industria. Nuestro equipo ha realizado una investigación en profundidad sobre la teoría y la práctica de los lagos de datos. Creemos que los lagos de datos no son solo una nueva perspectiva para la gestión de datos, sino también una tecnología prometedora para la integración y el procesamiento de datos.
El lago de datos es una idea de gobernanza de datos
El propósito de implementar un lago de datos es proporcionar una solución de gestión y almacenamiento eficiente para llevar la facilidad de uso y la disponibilidad de los datos a un nuevo nivel.
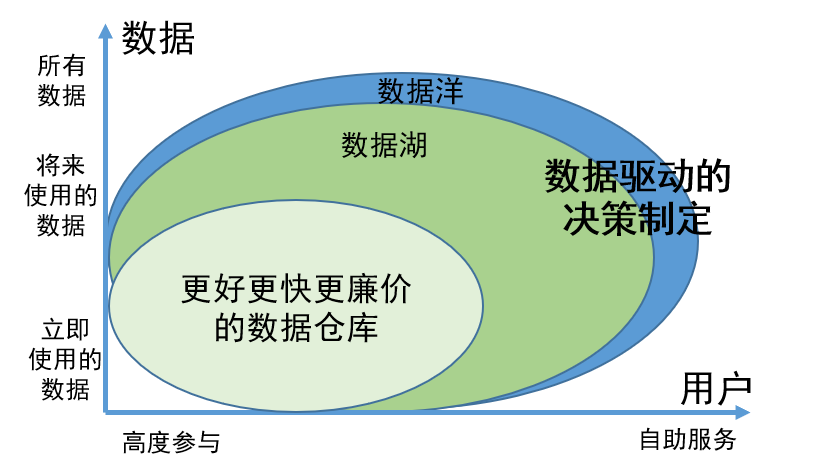
Como concepto innovador de gobernanza de datos, el valor del lago de datos se refleja principalmente en los dos aspectos siguientes:
1. La capacidad de almacenar de forma integral todos los datos, independientemente de si se están utilizando o no están disponibles temporalmente, garantiza que la información requerida se pueda encontrar fácilmente cuando sea necesario y mejora la eficiencia del trabajo;
2. Los datos del lago de datos se han gestionado y organizado científicamente, lo que facilita a los usuarios encontrar y utilizar datos por sí mismos. Este modelo de gestión reduce en gran medida la participación de los ingenieros de datos. Los usuarios pueden completar las tareas de búsqueda y uso de datos por sí mismos, ahorrando así una gran cantidad de recursos humanos.
Para gestionar todo tipo de datos de forma más eficaz, el lago de datos divide los datos en cuatro áreas principales en función de diferentes características y necesidades: área original, área de producto, área de trabajo y área sensible:
Área sin procesar
: esta área está enfocada a satisfacer las necesidades de los ingenieros de datos y científicos de datos profesionales, y su objetivo principal es almacenar datos sin procesar y sin procesar. Cuando sea necesario, también se puede abrir parcialmente para admitir requisitos de acceso específicos.
Área de productos
: la mayoría de los datos en el área de productos son procesados y procesados por ingenieros de datos, científicos de datos y analistas de negocios para garantizar la estandarización y un alto grado de gestión de datos. Este tipo de datos suele utilizarse ampliamente en informes comerciales, análisis de datos, aprendizaje automático y otros campos.
Área de trabajo
: El área de trabajo se utiliza principalmente para almacenar datos intermedios generados por varios trabajadores de datos. Aquí, los usuarios son responsables de administrar sus datos para respaldar la exploración y experimentación de datos flexibles para satisfacer las necesidades de diferentes grupos de usuarios.
Área sensible
: El área sensible se centra en la seguridad y se utiliza principalmente para almacenar datos sensibles, como información de identificación personal, datos financieros y datos de cumplimiento legal. Esta área está protegida por el más alto nivel de control de acceso y seguridad.
A través de esta división, el lago de datos puede gestionar mejor diferentes tipos de datos y al mismo tiempo proporcionar un acceso y utilización convenientes a los datos para satisfacer diversas necesidades.
Aplicación de ideas de gobernanza de datos de Data Lake en centros de datos
El objetivo del centro de datos es resolver problemas como calibres estadísticos inconsistentes, desarrollo repetido, respuesta lenta a las necesidades de desarrollo de indicadores, baja calidad de los datos y altos costos de datos causados por el aumento de datos y la expansión comercial.
Los objetivos del centro de datos y del lago de datos son coherentes. Al combinar el concepto de lago de datos, se han optimizado y actualizado el sistema de datos y la arquitectura general del centro de datos.
En la etapa inicial de la construcción del centro de datos, integramos el sistema de almacén de datos de la empresa, realizamos una investigación en profundidad sobre el negocio, clasificamos la información de campo y dimensiones existente, resumimos las dimensiones de coherencia, establecimos un sistema de indicadores unificados y formulamos la construcción del almacén de datos. especificaciones. De acuerdo con esta especificación, construimos la capa de datos original (ODS), la capa de datos detallados (DWD) y la capa de datos agregados (MID) del almacén de datos unificado, y establecimos una biblioteca de dispositivos, que incluye una biblioteca de dispositivos acumulada y un nuevo dispositivo. biblioteca. Sobre la base del almacén de datos unificado, el equipo de datos construyó un almacén de datos temático y un mercado comercial basado en diferentes análisis, direcciones estadísticas y necesidades comerciales. El almacén de datos en cuestión y el mercado empresarial incluyen datos detallados procesados adicionalmente, datos agregados y tablas de datos de la capa de aplicación. La capa de aplicación de datos utiliza estos datos para proporcionar diferentes servicios a los usuarios.
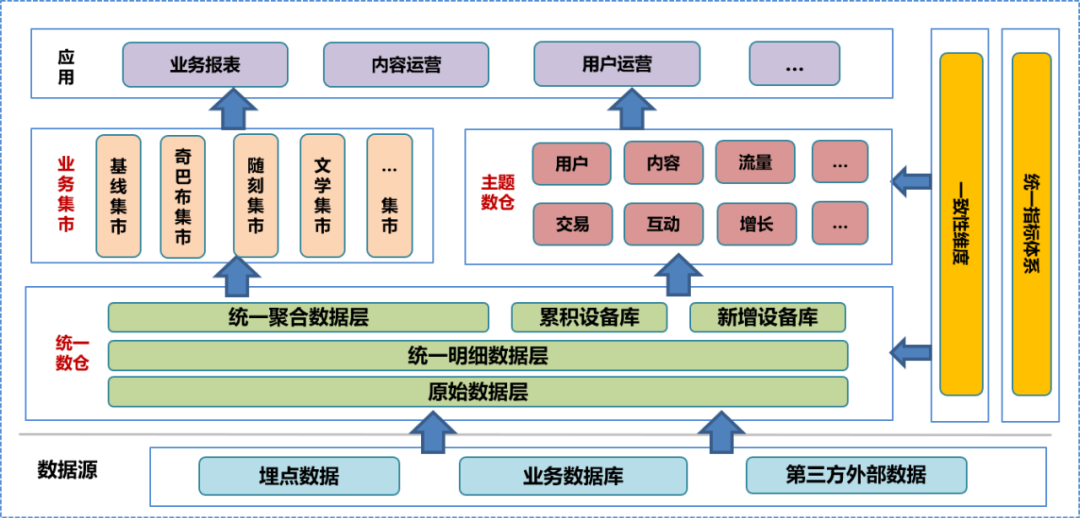
En un sistema de almacenamiento de datos unificado, la capa de datos original y
las inferiores
no están abiertas al público. Los usuarios solo pueden utilizar ingenieros de datos para procesar los datos procesados, por lo que es inevitable que se pierdan algunos detalles de los datos.
En el trabajo diario, los usuarios con capacidades de análisis de datos a menudo desean acceder a los datos sin procesar subyacentes para realizar análisis personalizados o solucionar problemas.
El concepto de gestión de datos del lago de datos puede resolver este problema de forma eficaz. Después de presentar la idea de gobernanza de datos del lago de datos, clasificamos e integramos los recursos de datos existentes, enriquecimos y ampliamos los metadatos de datos y construimos un centro de metadatos de datos específicamente para administrar el centro de metadatos.
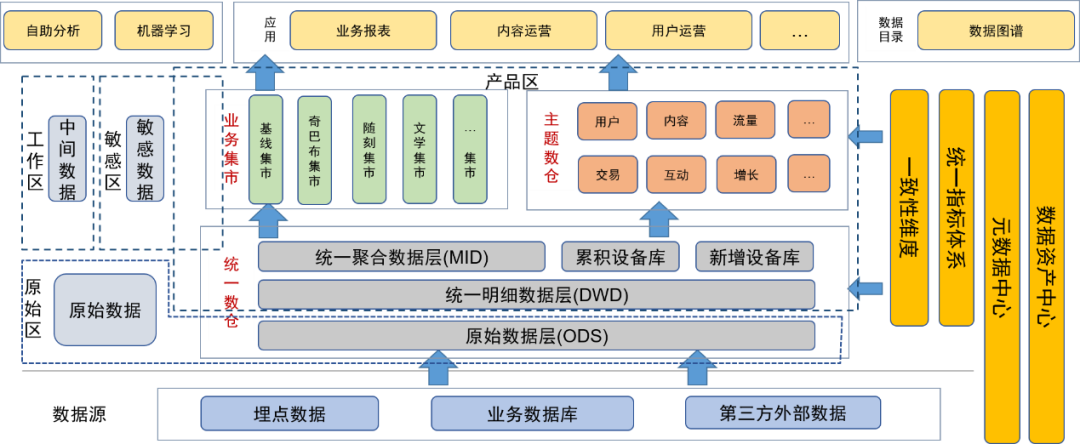
Después de introducir el concepto de lago de datos para la gobernanza de datos, colocamos la capa de datos originales y otros datos originales (como los archivos de registro originales) en el área de datos originales. Los usuarios con capacidades de procesamiento de datos pueden solicitar permiso para usar los datos en esta área.
La capa detallada, la capa de agregación, el almacén de datos temático y el centro comercial del almacén de datos unificado se colocan en el área de productos. Estos datos han sido procesados por los ingenieros de datos del equipo de datos y proporcionados a los usuarios como productos de datos finales. en esta área ha sido procesado por gestión de datos, por lo que la calidad de los datos está garantizada.
También hemos definido áreas sensibles para datos confidenciales y nos hemos centrado en controlar los derechos de acceso.
Las tablas temporales o tablas personales generadas diariamente por los usuarios y desarrolladores de datos se colocan en el área temporal. Estas tablas de datos son responsabilidad de los propios usuarios y pueden abrirse a otros usuarios de forma condicional.
Los metadatos de cada dato se mantienen a través del centro de metadatos, incluida la información de la tabla, la información de campo y las dimensiones e indicadores correspondientes a los campos. Al mismo tiempo, también mantenemos el linaje de datos, incluidas las relaciones de linaje a nivel de tabla y de campo.
Mantenga las características de los activos de los datos a través del centro de activos de datos, incluida la gestión del nivel, la sensibilidad y los permisos de los datos.
Para facilitar que los usuarios utilicen mejor los datos por sí mismos, proporcionamos un mapa de datos como un directorio de datos en la capa de aplicación para que los usuarios consulten datos, incluidos metadatos como el uso de datos, dimensiones, indicadores y linaje. Al mismo tiempo, la plataforma también se puede utilizar como portal para la solicitud de permisos.
Además, también proporcionamos una plataforma de análisis de autoservicio para brindar a los usuarios de datos capacidades de análisis de autoservicio.
Mientras optimizamos el sistema de datos, también actualizamos la arquitectura de la plataforma intermedia de datos basada en el concepto de lago de datos.
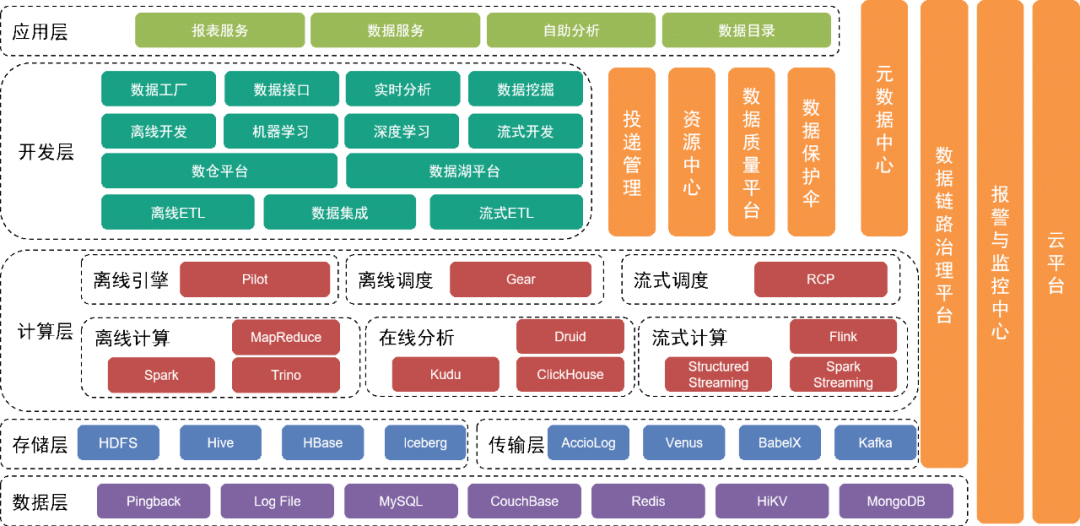
La capa inferior es la capa de datos , que incluye varias fuentes de datos, como los datos de Pingback, que se utilizan principalmente para recopilar datos sobre el comportamiento del usuario y se almacenan en varias bases de datos relacionales y bases de datos NoSQL.
Estos datos se almacenan en la capa de almacenamiento a través de diferentes herramientas de recopilación en la capa de transporte.
Por encima de la capa de datos está la capa de almacenamiento
, que se basa principalmente en HDFS, un sistema de archivos distribuido, para almacenar archivos originales. Otros datos estructurados o no estructurados se almacenan en Hive, Iceberg o HBase.
Más arriba está la capa informática
, que utiliza principalmente el motor fuera de línea Pilot para impulsar Spark o Trino para cálculos fuera de línea, y utiliza el motor de programación Gear fuera de línea para la programación del flujo de trabajo programado. La plataforma informática en tiempo real RCP es responsable de programar la informática en tiempo real. Después de varias rondas de iteraciones, la computación de flujo actualmente utiliza principalmente Flink como motor informático.
La capa de desarrollo sobre la capa informática
encapsula aún más cada módulo de servicio de la capa informática y la capa de transmisión para proporcionar funciones para desarrollar flujos de trabajo de procesamiento de datos fuera de línea, integrar datos, desarrollar flujos de trabajo de procesamiento en tiempo real y desarrollar implementaciones de ingeniería de aprendizaje automático e implementaciones de ingeniería de aprendizaje automático. servicios para completar el trabajo de desarrollo. La plataforma del lago de datos administra la información de cada archivo de datos y tabla de datos en el lago de datos, mientras que la plataforma del almacén de datos administra el modelo de datos del almacén de datos, el modelo físico, las dimensiones, los indicadores y otra información.
Al mismo tiempo, proporcionamos una variedad de herramientas y servicios de administración verticalmente. Por ejemplo, la herramienta de administración de entrega administra metainformación, como especificaciones ocultas de Pingback, campos, diccionarios y tiempos de entrega, el centro de metadatos, el centro de recursos y otros módulos. se utilizan para mantener tablas de datos o archivos de datos y garantizar la seguridad de los datos y la plataforma de gestión de enlaces monitorean la calidad de los datos y el estado de producción del enlace de datos, notifican rápidamente a los equipos relevantes sobre las medidas de seguridad y responden rápidamente a los problemas y fallas en línea. en base a los planes existentes.
Los servicios subyacentes los proporciona el equipo de servicios en la nube para brindar soporte para la nube pública y la nube privada.
La capa superior de la arquitectura proporciona un mapa de datos como directorio de datos para que los usuarios encuentren los datos que necesitan. Además, proporcionamos aplicaciones de autoservicio como Magic Mirror y Beidou para satisfacer las necesidades de los usuarios en diferentes niveles para el trabajo de datos de autoservicio.
Después de la transformación de todo el sistema arquitectónico, la integración y gestión de datos son más flexibles y completas. Reducimos el umbral de usuarios optimizando las herramientas de autoservicio, satisfacemos las necesidades de los usuarios en diferentes niveles, mejoramos la eficiencia del uso de datos y mejoramos el valor de los datos.
Aplicación de la tecnología de lago de datos en el centro de datos.
En un sentido amplio, el lago de datos es un concepto de gobernanza de datos. En un sentido estricto, el lago de datos también se refiere a una tecnología de procesamiento de datos.
La tecnología de lago de datos cubre el formato de almacenamiento de tablas de datos y la tecnología de procesamiento de datos después de ingresar al lago.
Hay tres soluciones de almacenamiento principales en lagos de datos en la industria: Delta Lake, Hudi e Iceberg. Una comparación de las tres es la siguiente:
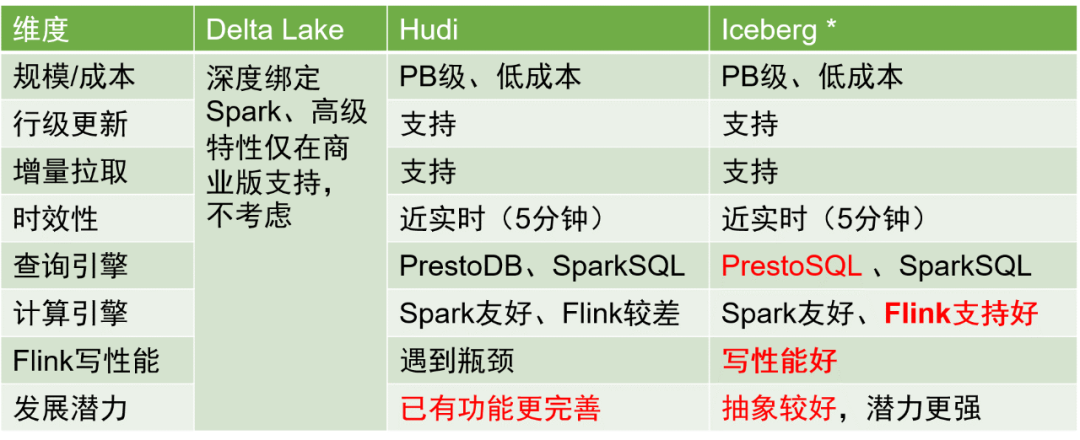
Después de una consideración exhaustiva, elegimos Iceberg como formato de almacenamiento de la tabla de datos.
Iceberg es un formato de almacenamiento de tablas que organiza archivos de datos en el sistema de archivos o almacén de objetos subyacente.
Aquí están las principales comparaciones entre Iceberg y Hive:
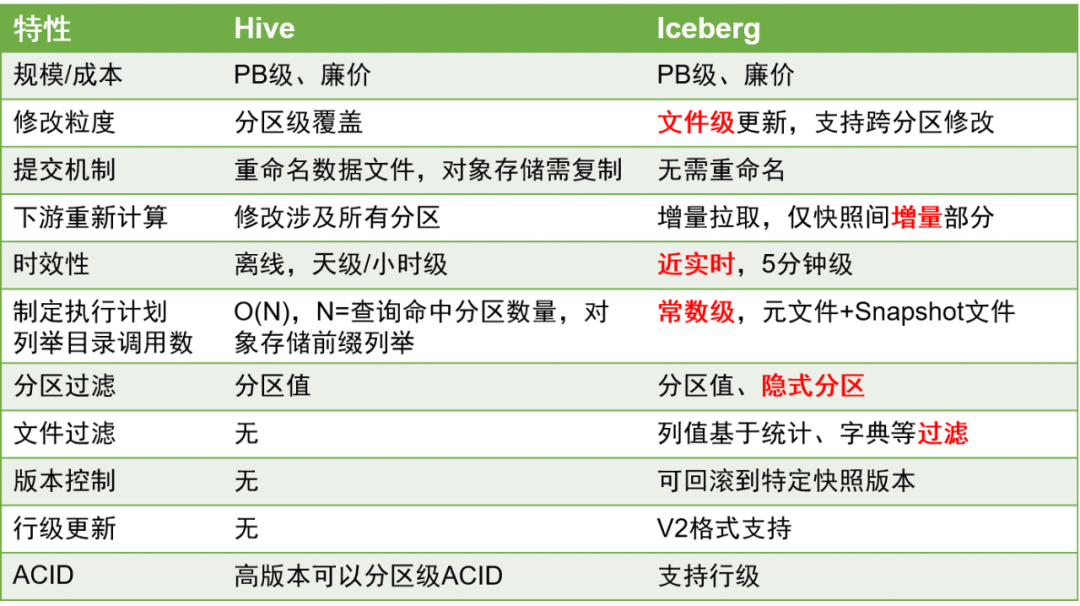
En comparación con las tablas de Hive, las tablas Iceberg tienen ventajas significativas porque pueden admitir mejor las actualizaciones a nivel de fila y la puntualidad de los datos se puede mejorar al nivel de minutos.
Esto es de gran importancia en el procesamiento de datos, porque mejorar la puntualidad de los datos puede mejorar en gran medida la eficiencia del procesamiento de datos ETL.
Por lo tanto, podemos transformar fácilmente la arquitectura Lambda existente para lograr una arquitectura integrada de transmisión por lotes:
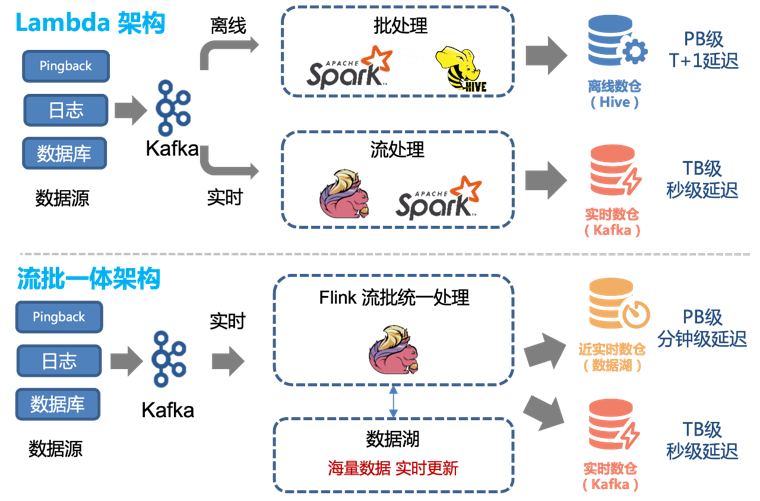
Antes de la introducción de la tecnología de lago de datos, utilizábamos una combinación de procesamiento fuera de línea y procesamiento en tiempo real para proporcionar un almacén de datos fuera de línea y un almacén de datos en tiempo real.
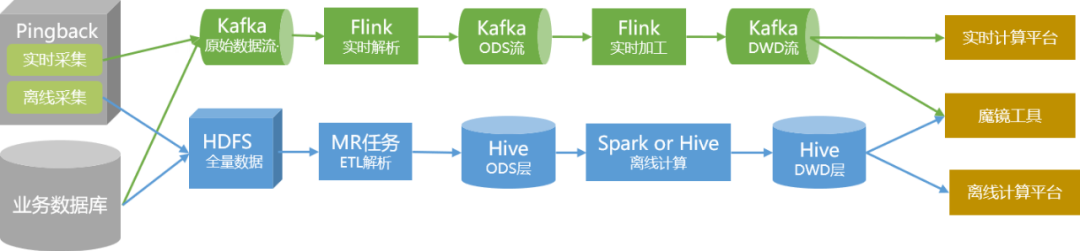
La cantidad total de datos se incorpora a los datos del almacén de datos mediante métodos tradicionales de procesamiento y análisis fuera de línea,
y se almacena en el clúster en forma de tablas de Hive.
Para datos con altos requisitos en tiempo real, los producimos por separado a través de enlaces en tiempo real y se los proporcionamos a los usuarios en forma de temas en Kafka.
Sin embargo, esta arquitectura tiene los siguientes problemas:
-
Los dos canales, en tiempo real y fuera de línea, deben mantener dos conjuntos diferentes de lógica de código. Cuando cambia la lógica de procesamiento, los canales en tiempo real y fuera de línea deben actualizarse al mismo tiempo; de lo contrario, se producirán inconsistencias en los datos.
-
Las actualizaciones cada hora de los enlaces fuera de línea y un retraso de aproximadamente 1 hora significan que los datos a las 00:01 no se pueden consultar hasta las 02:00. Para algunos servicios descendentes con altos requisitos de tiempo real, esto es inaceptable, por lo que es necesario admitir enlaces en tiempo real.
-
Aunque el rendimiento en tiempo real del enlace en tiempo real puede alcanzar el segundo nivel, su costo es alto. Para la mayoría de los usuarios, una actualización de cinco minutos es suficiente. Al mismo tiempo, consumir flujos de Kafka no es tan conveniente como operar tablas de datos directamente.
Estos problemas se pueden resolver mejor utilizando el método de procesamiento de datos integrado de tablas Iceberg y lotes de transmisión.

Durante el proceso de optimización, realizamos principalmente la transformación Iceberg en las tablas de la capa ODS y la capa DWD, y reconstruimos el análisis y el procesamiento de datos en tareas de Flink.
Para garantizar que la estabilidad y precisión de la producción de datos no se vea afectada durante el proceso de transformación, hemos tomado las siguientes medidas:
1. Comience a cambiar con datos complementarios. Según las condiciones comerciales reales, utilizamos la entrega QOS y la entrega personalizada como proyectos piloto.
2. Al abstraer la lógica de análisis fuera de línea, se forma un SDK de almacenamiento de análisis Pingback unificado, que realiza una implementación unificada en tiempo real y fuera de línea y hace que el código esté más estandarizado.
3. Después de implementar la mesa Iceberg y el nuevo proceso de producción, ejecutamos operaciones paralelas de doble enlace durante dos meses y realizamos un seguimiento comparativo regular de los datos.
4. Después de confirmar que no hay problemas con los datos y la producción, realizamos un cambio imperceptible a la capa superior.
5. Para los datos de inicio y reproducción relacionados con los datos centrales, llevaremos a cabo la transmisión integrada y la transformación por lotes después de que la verificación general sea estable.
Después de la transformación, los beneficios son los siguientes:
1. Los qos y los enlaces de datos de entrega personalizados se han implementado casi en tiempo real en su conjunto. Los datos con un retraso de una hora se pueden actualizar a nivel de cinco minutos.
2. Excepto en circunstancias especiales, el enlace integrado de transmisión por lotes y transmisión puede satisfacer las necesidades en tiempo real. Por lo tanto, podemos desconectar los enlaces existentes en tiempo real y los enlaces de análisis fuera de línea relacionados con QOS y personalización, ahorrando así recursos.
A través de la transformación del procesamiento de datos, nuestro enlace de datos será como se muestra en la siguiente figura en el futuro:
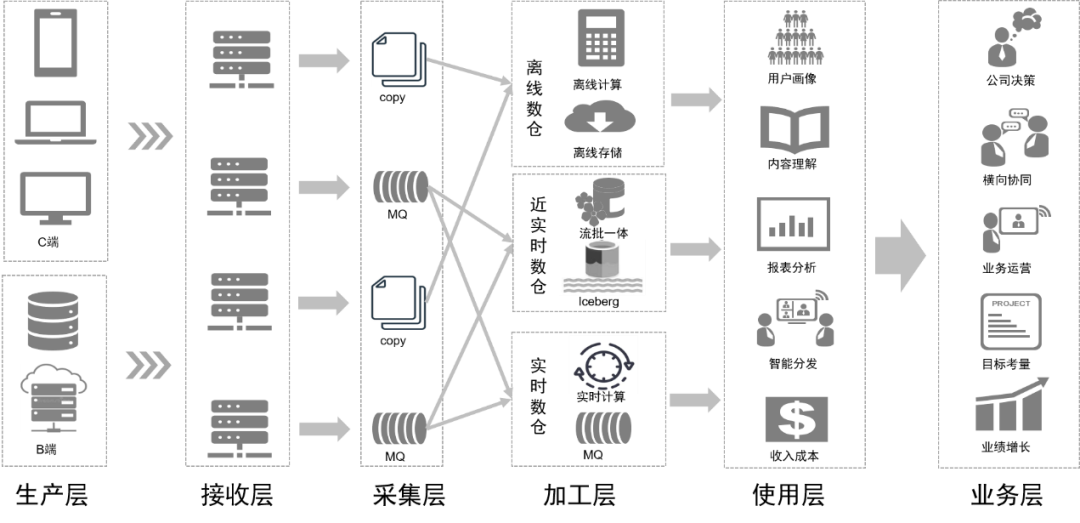
Planificación de seguimiento
Para la posterior planificación de la aplicación del data lake en el centro de datos existen dos aspectos principales:
Desde el nivel arquitectónico, continuaremos perfeccionando el desarrollo de cada módulo para hacer que los datos y servicios proporcionados por el centro de datos sean más completos y más fáciles de usar, de modo que diferentes usuarios puedan usarlos cómodamente;
A nivel técnico, continuaremos transformando el enlace de datos en una integración de flujo por lotes y, al mismo tiempo, continuaremos introduciendo activamente tecnologías de datos apropiadas para mejorar la producción y la eficiencia del uso de datos y reducir los costos de producción.
6. Alex Gorelik. El lago de big data empresarial.
Quizás tú también quieras ver
Este artículo se comparte desde la cuenta pública de WeChat: Equipo de productos de tecnología iQIYI (iQIYI-TP).
Si hay alguna infracción, comuníquese con [email protected] para eliminarla.
Este artículo participa en el " Plan de creación de fuentes OSC ". Los que están leyendo pueden unirse y compartir juntos.
