
01
Antecedentes y puntos débiles
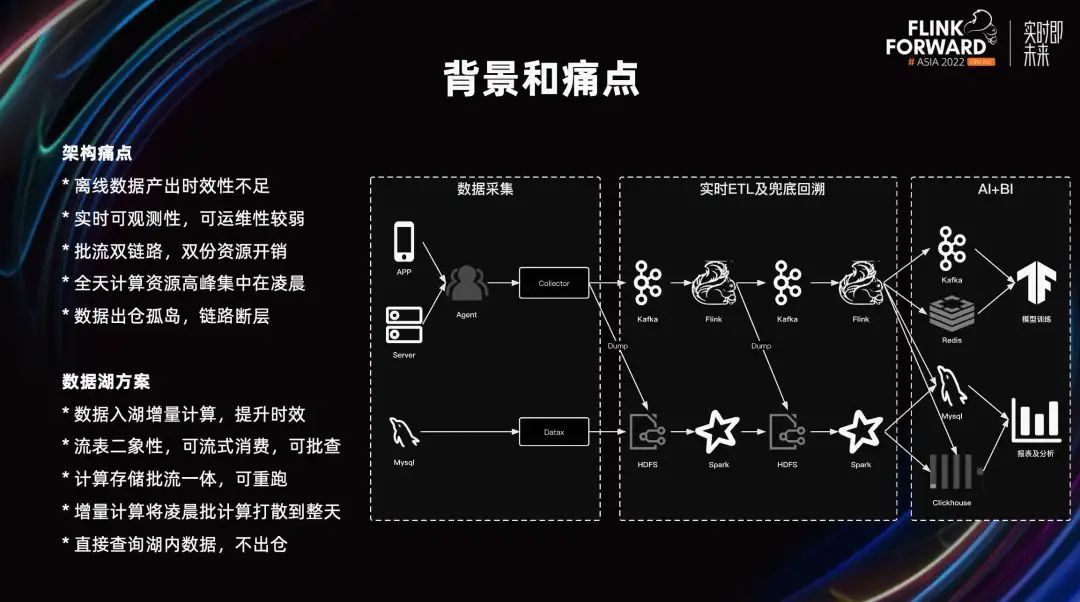
En la aplicación de escenarios de big data, las empresas no solo deben calcular los resultados de los datos, sino también garantizar la puntualidad. En la actualidad, nuestra empresa ha desarrollado dos enlaces. Los datos con alta puntualidad pasan a través de enlaces en tiempo real de Kafka y Flink; los datos con bajos requisitos de puntualidad pasan a través de enlaces fuera de línea de Spark. La figura anterior describe brevemente el enlace para el informe, procesamiento y uso de datos de la estación B. La recopilación de datos se realiza principalmente a través de los datos de eventos de comportamiento informados por la aplicación. Los datos de registro informados por el servidor se distribuirán en flujo al sistema de almacenamiento de big data a través de la puerta de enlace y la capa de distribución.
Los datos comerciales almacenados en MySQL se sincronizan periódicamente por lotes con el almacén de datos a través de Datax. Los datos urgentes se calcularán en flujo a través de Flink + Kafka. Los datos con baja puntualidad se calculan por lotes a través de Spark+HDFS y finalmente se entregan al medio MySQL Redis Kafka para su uso en escenarios de análisis de informes y entrenamiento de modelos de IA y BI.
En el proceso de uso, también se encontraron muchos problemas.
1. La puntualidad de los datos fuera de línea no es suficiente y el cálculo del lote fuera de línea se basa en horas/días. Cada vez más partes comerciales esperan que la puntualidad pueda alcanzar el nivel de minutos, y los cálculos diarios o horarios fuera de línea no pueden satisfacer las necesidades de las partes comerciales. Para lograr una mayor puntualidad, la empresa desarrollará otro enlace en tiempo real.
2. Pero la observabilidad del vínculo en tiempo real es débil. Debido a que no es conveniente ver datos en Kafka, los datos en Kafka deben moverse a otros almacenamientos antes de verlos. Los enlaces de datos en tiempo real generalmente no son fáciles de alinear con el tiempo comercial y es difícil ubicar con precisión el punto de partida que debe volver a ejecutarse. Si los datos son anormales, la empresa generalmente no elige volver a ejecutar la transmisión en tiempo real, sino realizar la reparación T-1 en el enlace fuera de línea.
3. El enlace dual fuera de línea en tiempo real tendrá el doble de costos generales de recursos, desarrollo y operación y mantenimiento. Además, un calibre inconsistente generará costos de interpretación adicionales.
4. El pico de recursos informáticos a lo largo del día se concentra temprano en la mañana y el uso máximo de todo el clúster de big data es entre las 2:00 y las 8:00 de la mañana. Principalmente ejecutando tareas a nivel del cielo, también existe el fenómeno de la cola de tareas. Los recursos en otros períodos están relativamente inactivos y hay picos y valles obvios cuando se utilizan. Hay margen para la optimización en la utilización general de los recursos.
5. En términos de islas de almacenamiento de datos, los usuarios también necesitan clonar una copia de los datos en HDFS, por lo que habrá problemas de coherencia de los datos. Cuando los datos están fuera del almacén, los permisos y las consultas de federación de datos serán insuficientes.
Esperamos resolver los puntos débiles anteriores a través de la solución del lago de datos en tiempo real.
1. Usamos Flink+Hudi para almacenar incrementos de datos y los resultados de cálculos incrementales en Hudi, lo que admite cálculos de datos a nivel de minutos y mejora aún más la puntualidad de los datos.
2. Además, Hudi tiene la dualidad de la tabla de flujo, que no solo puede realizar un consumo incremental de transmisión en tiempo real, sino que también puede usarse como una tabla para consultas directas. En comparación con el vínculo de Kafka, la observabilidad aumenta aún más.
3. El lago de datos en tiempo real cumple con los requisitos tanto en tiempo real como fuera de línea, logrando el efecto de reducir costos y aumentar la eficiencia. Además, también respalda la demanda de volver a ejecutar datos del almacén de datos fuera de línea.
4. Mediante cálculo incremental, los recursos de datos originalmente asignados después de las 0 en punto se subdividen y asignan a cada minuto de todo el día, y los recursos se utilizan en picos escalonados.
5. Mediante clasificación, indexación, materialización, etc., podemos consultar directamente los datos en la tabla Hudi, para lograr el efecto de que los datos salgan del almacén.
02
exploración de escena
2.1 Escenario de almacenamiento de base de datos
Cuando los datos del sistema empresarial se almacenan en MySQL, estos datos deben importarse al almacén de datos de big data para informes, análisis, cálculos y otros escenarios. En la actualidad, el almacenamiento de datos empresariales no solo se utiliza para ETL fuera de línea, sino que también se espera que sea urgente. Por ejemplo, en el escenario de revisión del contenido del manuscrito, el personal quiere saber si el aumento de manuscritos en los últimos diez minutos coincide con la mano de obra de revisión del manuscrito, y existen demandas de alarma y monitoreo en tiempo real. Los datos del manuscrito provienen de la base de datos comercial, que no está satisfecha con la puntualidad de la sincronización de datos actual a nivel de día y hora, y espera lograr la puntualidad del nivel de minutos.
En el contexto de reducir costos y aumentar la eficiencia, no solo debemos satisfacer las demandas comerciales, sino también considerar la eficiencia. El enlace en tiempo real se utiliza en escenarios en tiempo real y el enlace fuera de línea es un desperdicio en escenarios ETL por lotes. Por lo tanto, esperamos construir una solución unificada de flujo por lotes a través del lago de datos en tiempo real, al tiempo que satisfacemos las demandas de escenarios en tiempo real y fuera de línea. A través de la investigación, se encuentra que los esquemas existentes se clasifican en las siguientes categorías:
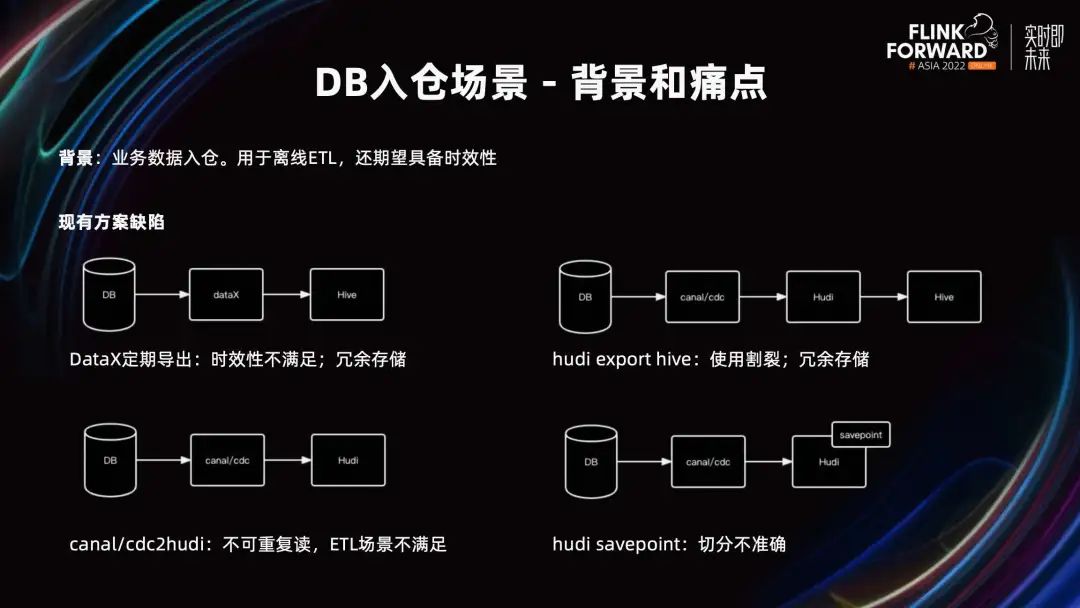
Primero, DataX exporta datos por lotes periódicamente a Hive.
Hive en sí no tiene la capacidad de actualizarse y, por lo general, exporta la cantidad total a diario, lo que no cumple con los requisitos de puntualidad. Además, esta solución también presenta el problema de la redundancia de datos. Las particiones diarias de la tabla de Hive son instantáneas de la tabla MySQL de ese día. Por ejemplo, la información en una tabla de información del usuario rara vez cambia y es necesario almacenar una instantánea completa todos los días. Es decir, cada dato del usuario se almacenará una vez al día. Si el ciclo de vida de la tabla de Hive es de 365 días, entonces este dato se almacenará repetidamente 365 veces.
En segundo lugar, la solución de Canal/CDC a Hudi.
Los datos de DB se escriben en Hudi a través de Canal o Flink CDC, para cumplir con los requisitos de puntualidad. Dado que los datos de Hudi se actualizan en tiempo real, no tiene la capacidad de lectura repetible. Por tanto, esta solución no cumple con el escenario ETL. Incluso con las capacidades de "lectura de instantáneas" de Hudi. Aunque es posible leer el historial de confirmación de Hudi, obtener una instantánea de los datos en un momento determinado. Sin embargo, si los datos de confirmación se mantienen durante mucho tiempo, se generarán demasiados archivos, lo que afectará el rendimiento del acceso a la línea de tiempo y luego afectará el rendimiento de lectura y escritura de Hudi.
En tercer lugar, la solución Hudi export Hive.
Este esquema es una combinación de los dos esquemas anteriores: después de que los datos de la base de datos se escriben en Hudi a través de Canal/CDC, se exportan periódicamente a la tabla de Hive. Las tablas Hudi se utilizan en escenarios en tiempo real y las tablas Hive se utilizan en escenarios ETL sin conexión. Para satisfacer las demandas de la escena de dos aspectos al mismo tiempo. La desventaja es que el usuario utiliza dos tablas durante el proceso de uso y existe un cierto costo de comprensión y redundancia de datos.
Cuarto, la solución Hudi Savepoint.
Resuelve principalmente el problema de la redundancia de datos. A través de Savepoint periódico, se pueden almacenar los metadatos de la línea de tiempo de Hudi en ese momento. Al acceder a Savepoint, se asignará para acceder al archivo real de Hudi para evitar archivos de datos de almacenamiento redundantes. Un Savepoint por día equivale a almacenar una instantánea de MySQL todos los días, cumpliendo así con los requisitos de relectura de escenas ETL. Al mismo tiempo, también puede acceder directamente a los datos más recientes de Hudi para satisfacer las demandas de los usuarios en tiempo real.
Pero este esquema todavía tiene algunos defectos: no puede dividir con precisión los datos de varios días. Al escribir de forma incremental en Hudi a través de Flink, el compromiso se generará periódicamente y el tiempo comercial y la alineación del compromiso no se pueden controlar. Si los datos de ayer y hoy caen en el mismo compromiso, Savepoint utilizará el compromiso como fuerza mínima. Al acceder al Savepoint de ayer, este contiene los datos de hoy, que no son los que esperaba el usuario.
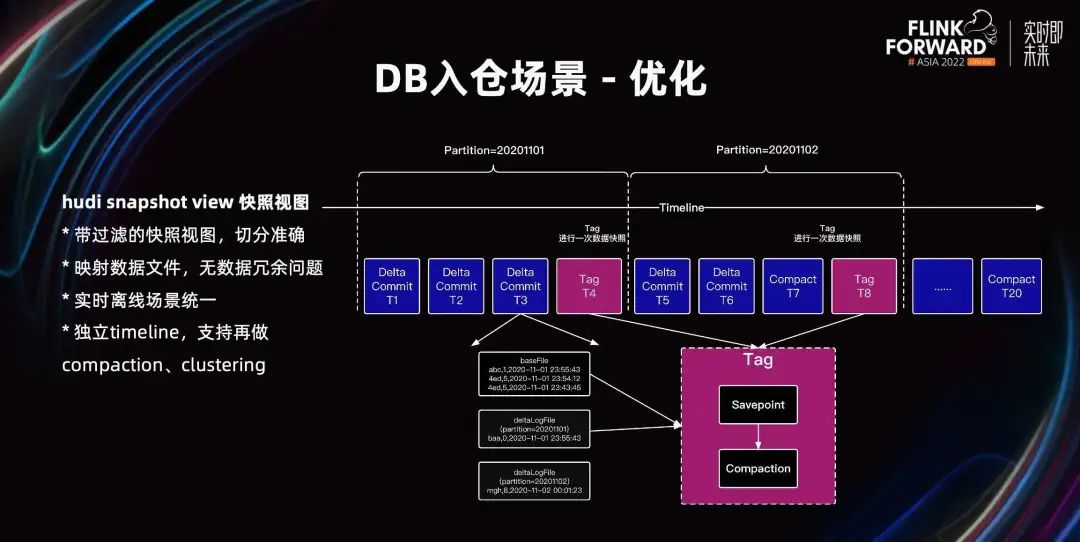
Para resolver los problemas anteriores, la solución que proponemos es la vista de instantáneas Hudi Snapshot View. Se ha realizado una mejora en el esquema Hudi Savepoint, que es simplemente un Hudi Savepoint con filtrado.
En el esquema de exportación de Hive, se pueden agregar condiciones de filtro para filtrar los datos del día siguiente. Incorporamos lógica de filtrado en la vista de instantáneas de Hudi. En la vista de instantánea, la lógica de filtrado se implementa en la parte inferior de Hudi y se almacena en Hudi Meta. Al acceder a la vista de instantáneas, mostraremos los datos filtrados para resolver el problema de los datos de varios días en la instantánea.
Como se muestra en la figura anterior, Delta Commit T3 contiene los datos del 1 y 2 de noviembre. Cuando se almacenan los datos de origen de la vista de instantánea, se almacenan todos los datos de origen históricos de T1, T2 y T3. Además, también se almacena la condición del filtro de Delta<=1 de noviembre. Filtre los datos al leer e incluya solo los datos a partir del 1 de noviembre hasta el final de la consulta, sin incluir los datos del 2 de noviembre.
La vista instantánea también almacena metadatos y accede a los archivos de datos reales mediante mapeo, por lo que no hay problema de almacenamiento de datos redundante. También satisface escenarios en tiempo real y fuera de línea al mismo tiempo, logrando la unificación de transmisión por secuencias y procesamiento por lotes. Además, la vista de instantánea recorta de forma independiente una línea de tiempo, que admite operaciones como la compactación y la agrupación en clústeres para acelerar las consultas.
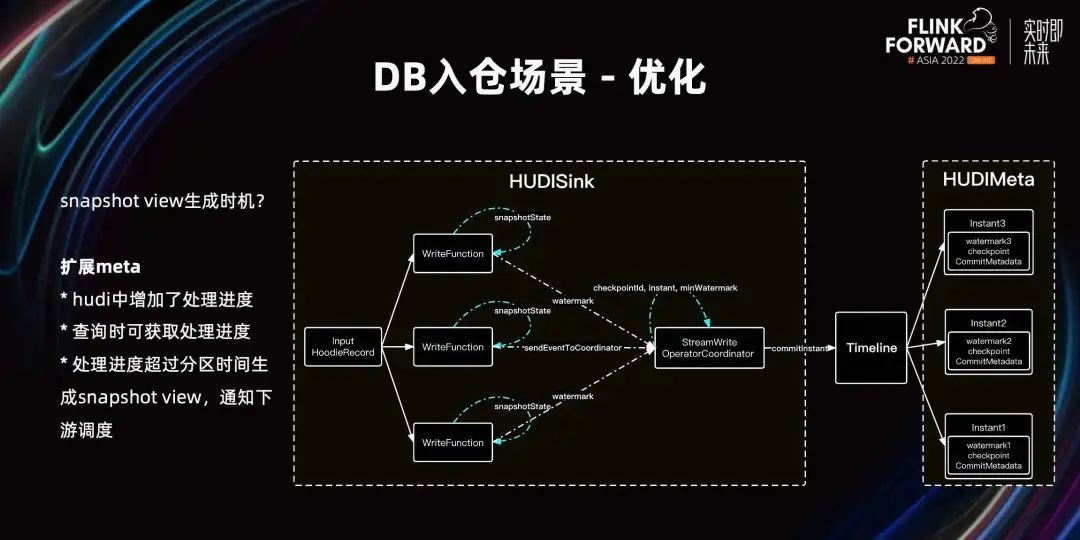
A continuación, hablemos del momento en que se genera la vista instantánea. ¿Después de qué confirmación debería el usuario realizar esta vista instantánea? Hay dos conceptos que deben entenderse aquí: uno es el tiempo del evento y el otro es el tiempo de procesamiento.
Cuando los datos se retrasan, aunque la hora real llega a las 0 en punto, es posible que todavía esté procesando los datos a las 22 en punto. En este momento, si se realiza la vista de instantánea, los datos de la vista de instantánea leídos por el usuario serán relativamente pequeños. Porque el compromiso es tiempo de procesamiento, no tiempo de evento comercial. Esta vista instantánea debe realizarse después de que la hora del evento avance hasta las 0 en punto para garantizar la integridad de los datos. Para ello, agregamos el progreso del procesamiento en Hudi. Este concepto es similar al uso de Watermark en Flink para identificar el progreso del procesamiento. Ampliamos Hudi Meta para almacenar el progreso del procesamiento en Commit. Cuando la hora del evento avanza hasta las 0 en punto, la operación de vista instantánea comienza a notificar a las tareas posteriores que se pueden llamar. Con el progreso del procesamiento del evento en Meta, el progreso del procesamiento también se puede obtener al consultar Hudi, para hacer algunos juicios.
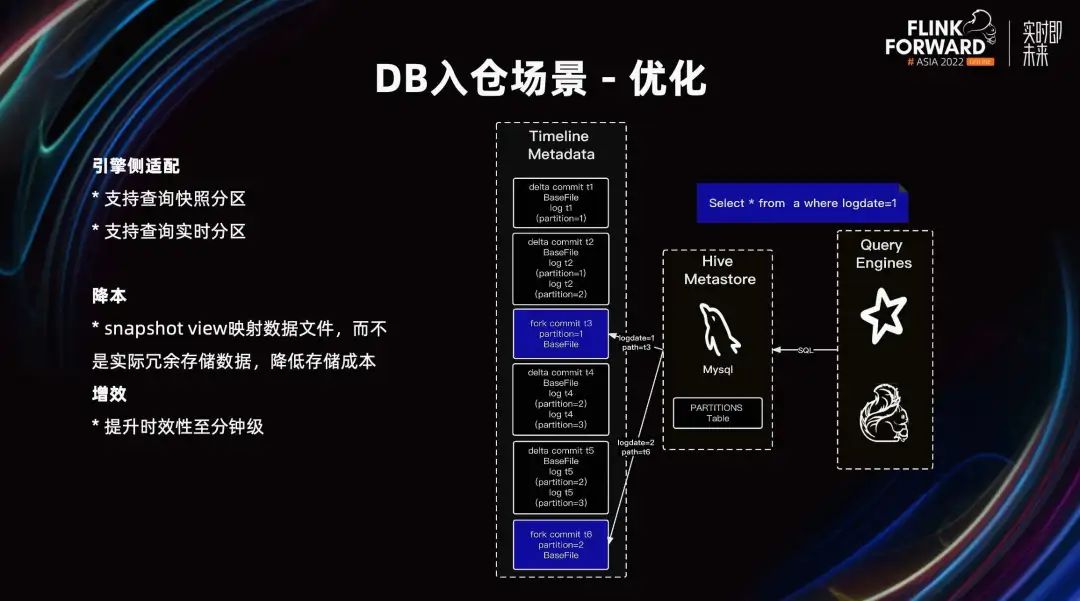
Además, también hemos hecho la adaptación de la capa del motor. En términos de uso, el SQL escrito por el usuario es básicamente el mismo que el original: mediante el parámetro sugerencia o conjunto se especifica si se consulta la partición instantánea o la partición en tiempo real. En el escenario del almacenamiento de bases de datos, no solo cumple con la puntualidad de los escenarios en tiempo real, sino que también satisface las demandas fuera de línea de ETL, logra con éxito la unificación de tiempo real y fuera de línea y logra el propósito de reducir costos y aumentar la eficiencia.
2.2 Escena de almacenamiento del punto enterrado
A continuación, hablemos de la escena del enterramiento de puntos en los almacenes. Como empresa de Internet, nuestra empresa también define eventos de comportamiento del usuario, recopila datos, los informa al almacén y luego los analiza y utiliza. Utilice datos para impulsar el desarrollo empresarial.
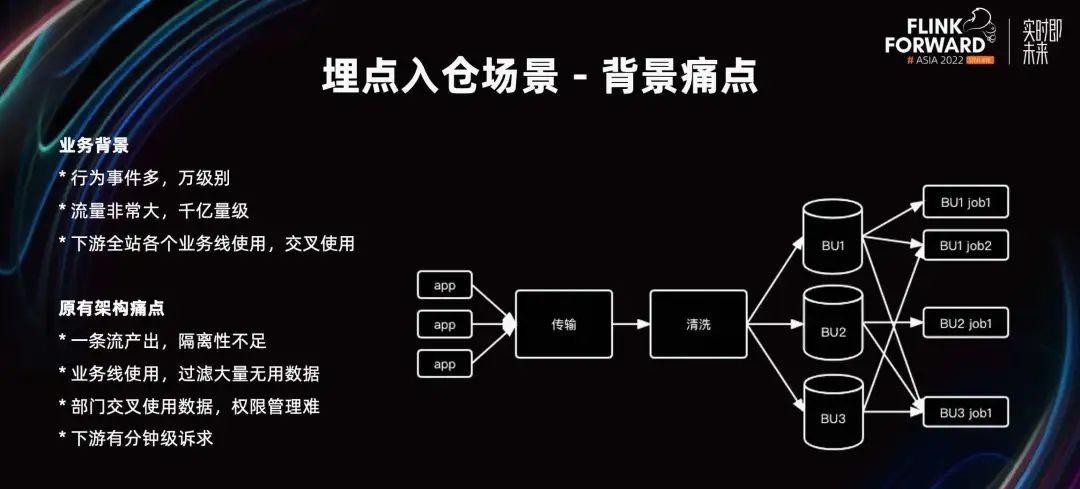
Los informes de nuestra empresa sobre eventos de comportamiento de los usuarios han alcanzado una escala considerable y hay muchos eventos de comportamiento. Ahora se han definido decenas de miles de ID de eventos de comportamiento y cada día se agregan cientos de miles de millones de datos y el tráfico es muy grande. El almacenamiento de puntos enterrados es un proyecto a nivel de empresa y todas las partes comerciales en el sitio informan sobre puntos enterrados. Al utilizar puntos enterrados, nuestra empresa tiene una gran cantidad de uso cruzado de líneas de negocio departamentales. Por ejemplo, la IA publicitaria necesita utilizar datos proporcionados por otras líneas de negocio para la recopilación de muestras y la capacitación.
En la arquitectura original, los datos reportados por el extremo de la aplicación se transmiten y limpian, y caen en las particiones de tablas predivididas del almacén de datos, que se proporcionan al lado comercial para su desarrollo y uso. Esta división comercial es una división general basada en información comercial como unidades de negocio y tipos de eventos. Las tareas posteriores pueden utilizar las tablas de su propio departamento y las tablas de otros departamentos, y solo necesitan solicitar permiso.
Pero la arquitectura también tiene algunos puntos débiles. El aislamiento de un flujo de datos no es suficiente, decenas de miles de puntos enterrados se transmiten a través del mismo canal y el aislamiento es insuficiente para la limpieza. Es fácil que un determinado evento de comportamiento aumente drásticamente durante la actividad, lo que afecta el progreso general del procesamiento de la tarea. Además, el uso de la línea comercial necesita filtrar una gran cantidad de datos inútiles. En tareas comerciales posteriores, solo se puede utilizar para el análisis uno de sus propios eventos de comportamiento. Pero en este momento el incidente de conducta se mezcla con otros incidentes de conducta en el mismo departamento. En el filtrado condicional, la capa del motor solo puede realizar filtrado a nivel de partición. Al cargar los archivos de toda la partición y luego filtrar, se desperdicia IO para leer archivos más grandes. Al mismo tiempo, cuando los departamentos utilizan datos cruzados, la gestión de la autoridad es difícil. Si se utiliza un evento de comportamiento de otra BU, es necesario solicitar la autoridad de toda la tabla de BU. Tamaño de partícula grueso, existe riesgo. Downstream tiene demandas de nivel mínimo. Actualmente, los datos de transmisión se eliminan cada hora. La puntualidad aguas abajo es a nivel de horas, lo que no satisface las demandas de puntualidad de los usuarios.
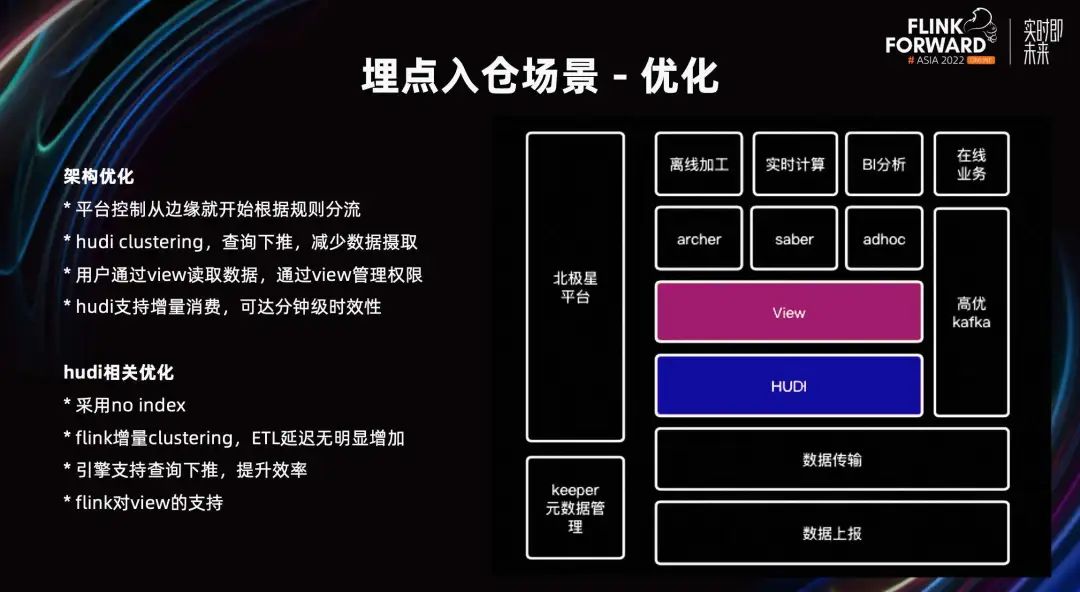
Para resolver los problemas anteriores, hemos realizado algunas optimizaciones arquitectónicas. Como se muestra en la figura anterior, después de informar y transmitir los datos, los datos se colocan en la tabla Hudi del hogar. Los usuarios acceden o utilizan estos datos a través de View, que se puede utilizar en escenarios como ETL fuera de línea, cálculos en tiempo real y análisis de informes de BI.
Para los datos que requieren puntualidad de segundo nivel, se utilizarán enlaces Kafka de alta calidad para proporcionar servicios en línea, y esta proporción es relativamente pequeña. La plataforma de gestión de eventos Polaris y la gestión de metadatos son responsables de gestionar el ciclo de vida de todo el punto de enterramiento de eventos de comportamiento, las reglas de distribución, etc.
El control de la plataforma comienza desde los informes perimetrales, la distribución de reglas, el aislamiento empresarial y el aislamiento mejorado. Una vez que los datos caen en la tabla empresarial de Hudi, se realiza una agrupación en clústeres para ordenar e indexar los datos empresariales. A través de la capa del motor, se realiza el salto de datos a nivel de archivo/bloque de datos para reducir la sobrecarga de E/S de leer la cantidad de datos. Los usuarios leen datos a través de Hive View y la plataforma logra la gestión de permisos a nivel de eventos de comportamiento agregando eventos de comportamiento autorizados a la Vista del usuario. Por ejemplo, cuando los estudiantes del departamento a usan los eventos de comportamiento del departamento b, simplemente agregue una ID del evento de comportamiento del departamento b a la Vista del departamento a. Al enviar SQL para inspección, se realizará la verificación de permisos a nivel de evento de comportamiento. Cuando la transmisión incremental limpia la tabla Hudi, la tabla Hudi admite el consumo incremental, lo que puede lograr una puntualidad a nivel de minutos. Detrás de esta Vista se pueden utilizar tareas posteriores en tiempo real para lograr la unificación del flujo por lotes.
En términos de optimización en el lado de Hudi, debido a que los datos de tráfico no se actualizan cuando ingresan al lago, adoptamos el modo sin índice y eliminamos la asignación de depósitos y otros procesos para mejorar la velocidad de escritura. Al mismo tiempo, el retraso de ETL en sentido descendente del clustering incremental de Flink no aumentó significativamente. Después de la agrupación, los datos se vuelven ordenados. El índice registra la distribución de eventos de comportamiento y se puede filtrar a nivel de archivo y a nivel de bloque de datos mediante consultas condicionales. Además, motores como Flink y Spark también admiten la inserción de predicados de tablas Hudi, lo que mejora aún más la eficiencia. En términos del soporte de Flink para View, la parte posterior de View puede definir Watermark o definir el atributo with en View, etc.
Mediante la combinación del ajuste de la arquitectura y las capacidades de Hudi, hemos mejorado el aislamiento y la puntualidad de la gestión de puntos enterrados y hemos ahorrado recursos.
2.3 Escenario de informe de BI en tiempo real
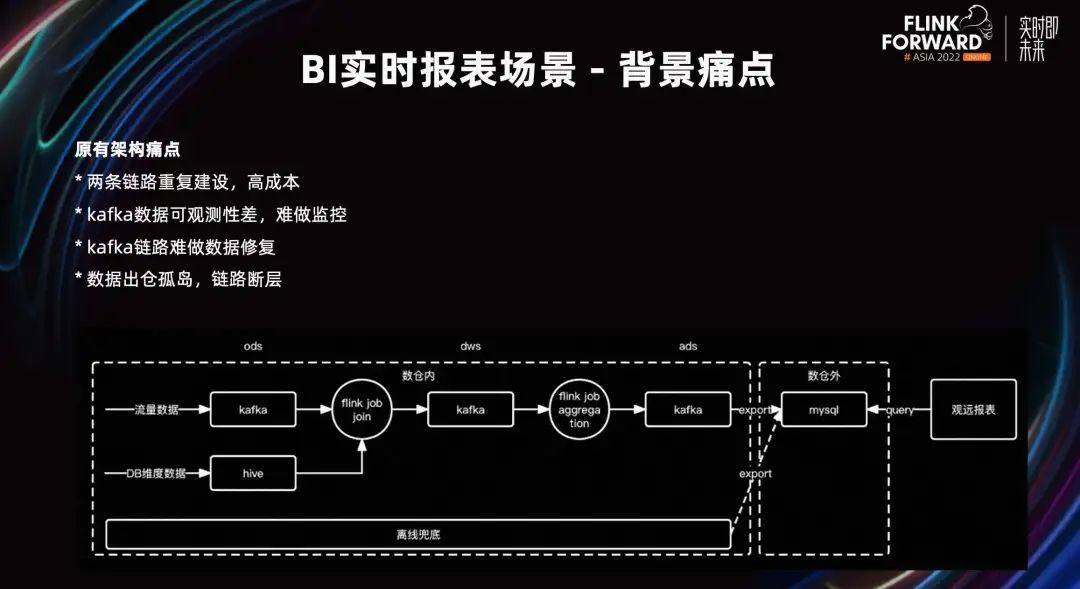
A continuación, hablemos del escenario del informe de BI en tiempo real. Bajo la arquitectura original, después de importar los datos de tráfico y los datos de la base de datos al almacén de datos, se unirán y ampliarán, y los resultados del cálculo original se enviarán a un almacenamiento como MySQL después de la agregación. Los informes de BI se conectarán directamente a MySQL para mostrar los datos. Otro enlace fuera de línea realizará la reparación de datos T-1.
El punto débil de la arquitectura original radica en la construcción repetida de enlaces en tiempo real y fuera de línea, los altos costos de computación y almacenamiento, los altos costos de desarrollo y operación y los costos de interpretación de alto calibre. Los datos de Kafka deben copiarse a otro almacenamiento para poder consultarlos y la observabilidad es relativamente débil. Además, es difícil realizar la reparación de datos en los enlaces de Kafka. Es difícil determinar el punto de partida para reparar el enlace Kafka, y el método T-1 generalmente se usa para la reparación. Existen problemas como las islas de almacenamiento de datos.
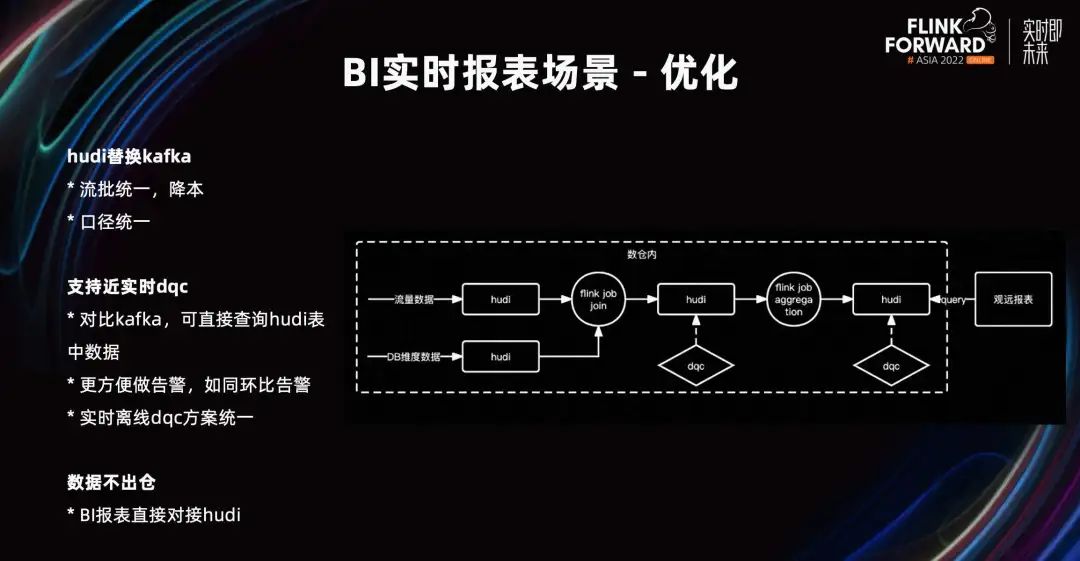
Los escenarios de informes de BI en tiempo real generalmente no requieren una puntualidad de segundo nivel, y la puntualidad de un minuto puede cumplir con los requisitos. Reemplazamos Kafka con Hudi, que cumplió con los requisitos en tiempo real y fuera de línea al mismo tiempo, logró la unificación de flujos por lotes, logró una reducción de costos y un calibre de datos unificado.
En comparación con Kafka, Hudi puede consultar directamente los datos en Hudi, y es más fácil y conveniente generar alarmas que Kafka.
Por ejemplo, compare los datos de hace siete días en Kafka y genere una alarma de umbral. Es necesario consumir los datos de hace siete días y los datos actuales, realizar cálculos y luego emitir una alarma. Todo el proceso es más complicado. La consulta SQL de Hudi es coherente con la consulta SQL fuera de línea. Para el sistema DQC, el esquema de DQC en tiempo real y DQC fuera de línea está unificado y el costo de desarrollo es bajo. Para tareas con requisitos de puntualidad de segundo nivel, también se requiere el enlace Kafka.
Además, los datos se pueden mantener fuera del almacén. Los informes de BI se pueden consultar directamente y conectarse a la tabla Hudi consultada para mostrar los datos.
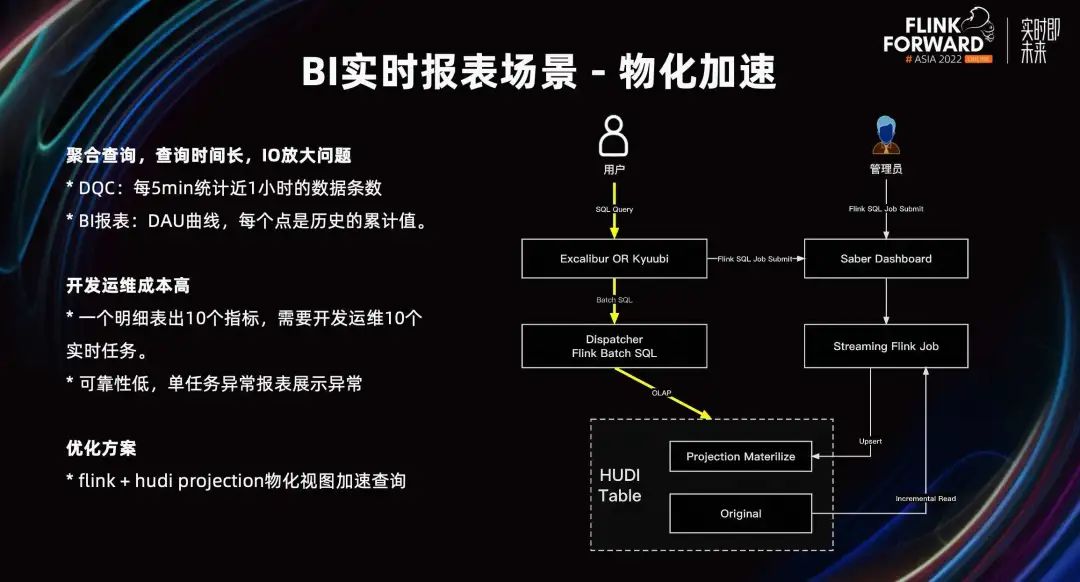
En el uso real, también existen algunos problemas. Cuando la consulta agregada se realiza directamente en la tabla de detalles de Hudi, el tiempo de consulta es demasiado largo y existe un problema de amplificación de lectura.
Supongamos que DQC en tiempo real cuenta los datos durante casi una hora cada cinco minutos para monitorear la cantidad de elementos de datos. Los datos de casi una hora se calcularán en cinco minutos y los datos de casi una hora se calcularán en los próximos cinco minutos. En el proceso de deslizar la ventana, los datos intermedios se calcularán muchas veces y se producirá una importante amplificación de IO.
Además, tome el escenario del informe de BI como ejemplo. Suponiendo que se muestra una curva DAU, cada punto es el valor acumulado de los datos históricos. Los datos de 1 punto son el valor acumulativo de los datos de 0 puntos ~ 1 punto. Los datos en el punto 2 son el valor acumulativo de los datos desde el punto 0 hasta el punto 2. Al mostrar en la interfaz, es necesario calcular n puntos, y cada punto se calculará repetidamente, lo que resultará en un tiempo de consulta prolongado y problemas de amplificación de lectura.
Además, el costo de desarrollo, operación y mantenimiento es relativamente alto. Los usuarios mostrarán múltiples indicadores en la interfaz de un panel de BI. Pueden ser datos de diferentes dimensiones del mismo horario de Hudi. Si se producen diez indicadores, es necesario desarrollar y mantener diez tareas en tiempo real, lo que genera altos costos de desarrollo y mantenimiento y baja confiabilidad. Cuando ocurre una excepción en una tarea en tiempo real, algunos indicadores faltarán en este panel.
La solución de optimización que proponemos es construir la vista materializada de Proyección a través de Flink + Hudi. A través del estado Flink State, solo es necesario ingerir cálculos de datos incrementales, lo que evita el problema de la amplificación de lectura. Los resultados de la consulta se calculan de antemano y los datos del resultado se consultan directamente para lograr el efecto de acelerar la consulta.
El proceso específico es que el usuario envía una consulta SQL a Excalibur Server para su análisis SQL. Durante el proceso de análisis, se envía la creación de la Proyección, se envía una tarea de Stream y luego los datos de la tabla original se leen de forma incremental y, después del cálculo de materialización, se almacenan en la tabla de materialización de la Proyección. Cuando la consulta SQL alcanza la regla de materialización, la consulta se reescribirá para consultar directamente la tabla de resultados para lograr el efecto de aceleración.
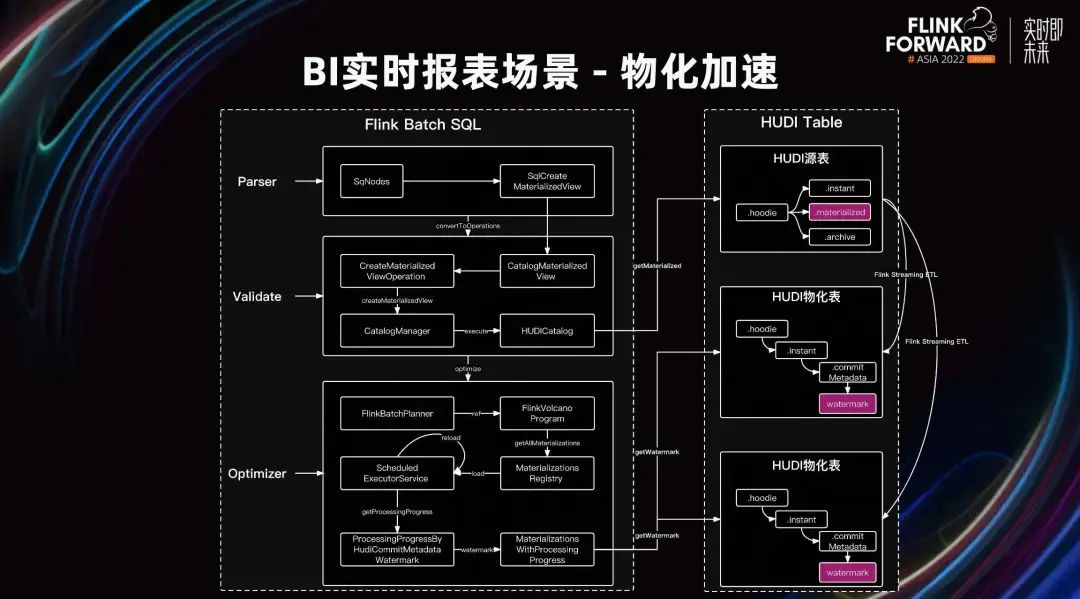
Al ampliar el proceso de análisis de Flink Batch SQL, las reglas de materialización y los metadatos de proyección se cargarán durante la consulta. Y juzgue el progreso actual de materialización de la marca de agua de la tabla materializada. Si se cumplen los requisitos, reescriba la consulta en la tabla materializada de Proyección.

Nos referimos a las reglas de materialización de Calcite y agregamos el soporte de sintaxis de TVF.
Admite la creación de proyección. Cuando los usuarios envían consultas por lotes, pueden agregar una sugerencia a la declaración de selección para activar el motor de consultas y la consulta se reutilizará. El motor creará una proyección para la consulta.
Admite la sintaxis y las reglas de Projection DDL de Flink SQL para la reescritura de consultas SQL. Cuando el usuario envía una consulta por lotes, si hay una Proyección correspondiente, se puede reescribir. Después de reescribir, los resultados de Projection se pueden usar directamente, lo que acelera enormemente la consulta y puede lograr una respuesta de segundo nivel o incluso de milisegundos.
La reescritura y degradación de Projection se basa en indicadores como Watermark, que protege problemas como retrasos y fallas en las tareas de Projection en tiempo real y garantiza la confiabilidad de los resultados de las consultas. Agregamos información sobre el progreso del procesamiento de datos de Watermark en Hudi Meta. Durante el proceso de escritura de datos, registraremos el progreso de materialización en Commit Meta. Al realizar la coincidencia de reglas de materialización, si está demasiado atrasado con respecto a la hora actual, se rechazará la reescritura de la Proyección actual y la tabla se degradará directamente a la tabla original para la consulta de datos.
Agregue la creación de sugerencias en la declaración de selección y logre el efecto de acelerar la consulta mediante la capacidad de materialización. No solo resuelve el problema de la amplificación de lectura, sino que también reduce los costos de desarrollo, operación y mantenimiento del usuario mediante la degradación automática.
En el futuro, optimizaremos la eficiencia de la proyección. Recicle las proyecciones que no se pueden alcanzar durante mucho tiempo. Fusione varias proyecciones con las mismas dimensiones para reducir el costo de cálculo de las proyecciones. Además, nos conectaremos con el sistema de indicadores y aceleraremos la consulta a través del caché del sistema de indicadores para cumplir con el cálculo de flujo de algunos escenarios de alto QPS.
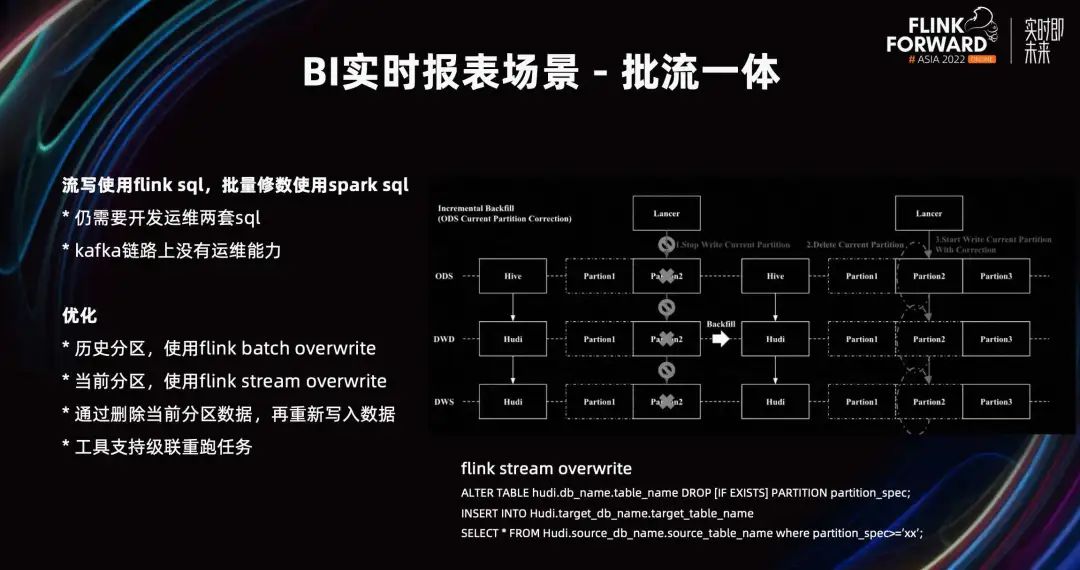
En el pasado, Flink SQL se usaba para la escritura de transmisión y Spark SQL para la reparación por lotes. Todavía se necesitan dos conjuntos de SQL para el desarrollo, la operación y el mantenimiento. Bajo la solución de base de datos en tiempo real de Hudi, nos referimos a la solución de corrección fuera de línea.
La repetición de la partición histórica utiliza Flink Batch Overwrite, que es coherente con el método de reparación fuera de línea.
Para volver a ejecutar la partición actual, utilizamos el método Flink Stream Overwrite. Por ejemplo, los datos de la partición actual deben borrarse, eliminarse y luego escribirse. Debido a que está escrito sin índice, no hay forma de sobrescribir los datos escritos previamente en forma de actualización. Ampliamos el catálogo de Hudi para admitir Flink SQL, y la operación de modificación de partición y eliminación de tabla elimina particiones y datos. Luego, Flink Stream Overwrite se implementa mediante la retransmisión de escritura.
Cuando la herramienta admite tareas de repetición en cascada, podemos reparar desde el nivel de ODS más fuente hasta el final y ya no necesitamos desarrollar y mantener tareas de reparación de Spark T-1. Realmente logró el efecto de la integración de flujo por lotes.
03
Optimización de infraestructura
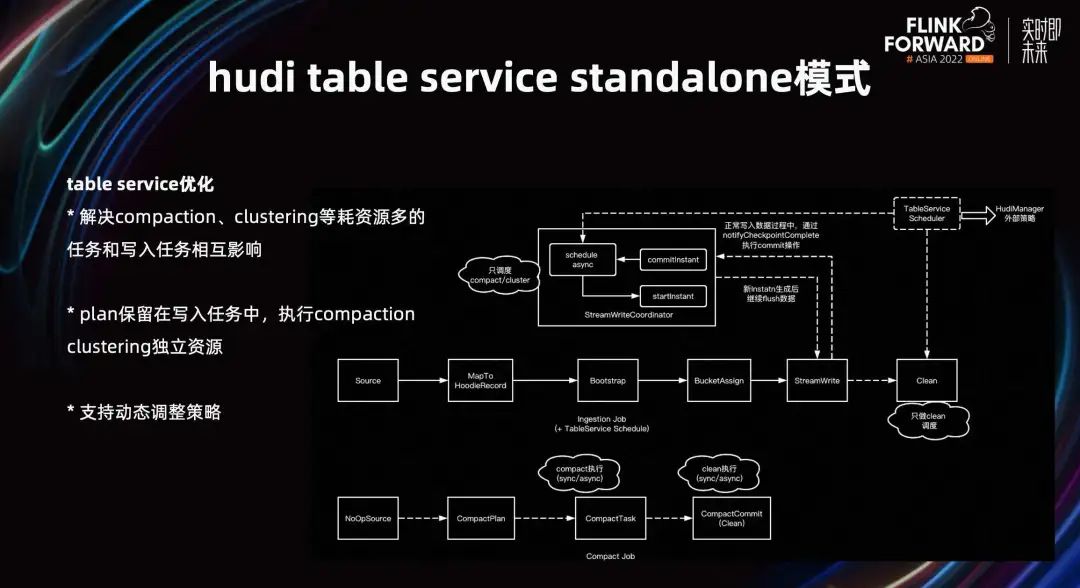
En términos de optimización de infraestructura, optimizamos Table Service. Debido a que tareas como la compactación y la agrupación en clústeres consumen más recursos e interactúan con las tareas de escritura, el rendimiento de la escritura se degrada. Resolvemos este problema dividiendo Table Service y ejecutándolo a través de recursos independientes.
Ponemos el proceso de generación del plan de compactación y el plan de ejecución del plan de agrupación en la tarea de escritura y, de hecho, ejecutaremos el proceso independiente de la tarea de compactación y agrupación. Evita la interacción entre escritura y Table Service y mejora el rendimiento de la escritura. Al mismo tiempo, respalda la estrategia de ajustar dinámicamente el plan de compactación y reduce las IO innecesarias ajustando la frecuencia.
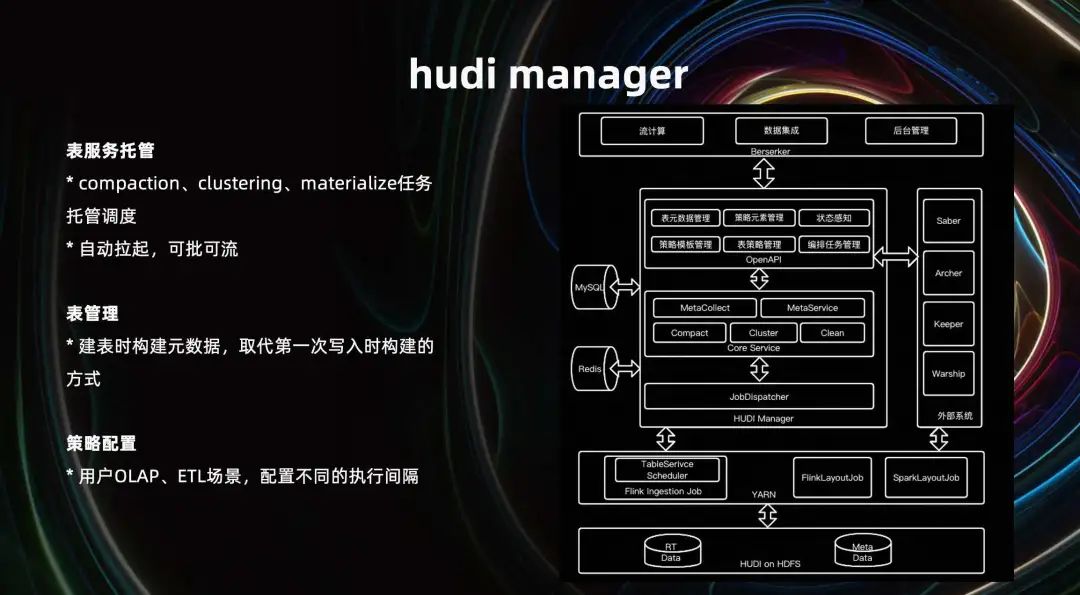
Hudi Manager se utiliza para la administración y el alojamiento a gran escala, incluido el alojamiento de servicios de tabla, como el alojamiento de tareas de compactación, agrupación en clústeres y proyección, operación independiente, aislamiento de recursos y estabilidad de escritura mejorada. Admite extracción automática, puede funcionar por lotes o fluir.
En términos de gestión de tablas, los datos de origen de Hudi se crean cuando se crea la tabla, reemplazando los datos de origen creados cuando se realiza la primera escritura, para evitar la omisión de parámetros importantes. Por ejemplo, al importar datos a Hudi en lotes, no le importa el campo de comparación previo a Combinar y los metadatos de la tabla se inicializan. Cuando la transmisión escribe, los metadatos de la tabla no se modifican. La ausencia de este campo coincidente resultará en la imposibilidad de obtener el resultado combinado correcto.
En términos de configuración de políticas, cuando el usuario selecciona escenarios OLAP y ETL, el intervalo de ejecución de diferentes servicios de tabla se puede configurar automáticamente. Por ejemplo, el escenario ETL descendente es la programación a nivel diario. En comparación con los escenarios OLAP, podemos utilizar una frecuencia de compactación más baja.
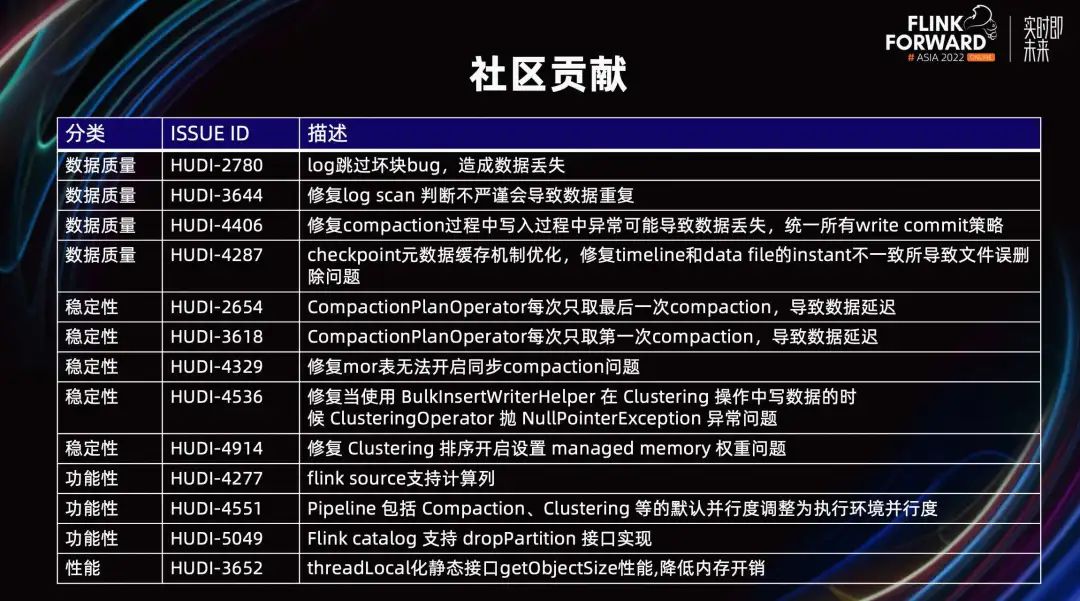
Como se muestra en la figura anterior, en el proceso de uso real, descubrimos y resolvimos muchos problemas en la calidad, la estabilidad y el rendimiento de los datos, y realizamos mejoras funcionales para contribuir a la comunidad. Cubre varios aspectos como sumidero, compactación, agrupación, paquete común, fuente, catálogo, etc. Algunas de las capacidades mencionadas en los escenarios anteriores se enviarán a la comunidad en forma de PR o RFC una tras otra.
04
Resumen y perspectivas

Hemos realizado una serie de prácticas en el flujo de datos hacia el lago, datos de base de datos en la escena del lago, escena de informes e integración de flujo por lotes.
A continuación, profundizaremos en el campo de los almacenes de datos, exploraremos la reducción de las capas del almacén de datos a través de tareas materializadas y realizaremos capas inteligentes a través del análisis, diagnóstico y optimización de tareas en capas. Hacer que los estudiantes de negocios se centren más en el uso de datos, reducir la carga de trabajo de las capas del almacén de datos y evolucionar hacia la integración del lago y el almacén. Mejore la computación incremental, admita Join ETL en Hudi y optimice la lógica de Join en la capa de almacenamiento. Explore el uso de Hudi en el campo de la IA.
En términos del kernel, mejoraremos Hudi Meta Store en el futuro para unificar la gestión de metadatos; mejoraremos Table Service; mejoraremos la capacidad de empalme de columnas de Hudi Join.
Si este artículo te resulta útil, ¡no olvides darle "Me gusta", "Me gusta" y "Favorito" tres veces!


La peor era de Internet puede estar aquí
Estoy estudiando en la universidad de Bilibili, especializándome en big data.
¿Qué estamos aprendiendo cuando aprendemos Flink?
193 artículos golpearon violentamente a Flink, debes prestar atención a esta colección
¿Qué estamos aprendiendo cuando aprendemos Spark?
¡Entre todos los módulos de Spark, me gustaría llamar a SparkSQL el más fuerte!
Hard Gang Hive | Resumen de la entrevista de ajuste básico de 40.000 palabras
Una pequeña enciclopedia de metodologías y prácticas de gobernanza de datos
Una pequeña guía para la construcción de retratos de usuarios bajo el sistema de etiquetas.
Artículos que he escrito sobre crecimiento/entrevista/avance profesional
¿Qué estamos aprendiendo cuando aprendemos Hive? "Secuela de Hardcore Hive"