Introducción: Con la popularidad de la computación en la nube y la expansión de los requisitos de análisis de datos, la capacidad de análisis integrado del lago de datos + almacén de datos se ha convertido en la capacidad principal del sistema de análisis de datos de próxima generación. En comparación con los almacenes de datos, los lagos de datos tienen ventajas obvias en términos de costo, flexibilidad y análisis de datos de múltiples fuentes. Entre los diez pronósticos de las tendencias del mercado de la computación en la nube de China publicados por IDC en 2021, tres están relacionados con el análisis del lago de datos. Es previsible que las capacidades de integración entre sistemas, las capacidades de control de datos y las capacidades más completas basadas en datos serán áreas importantes de competencia para los futuros sistemas de análisis de datos.
1. Antecedentes
Con la popularidad de la computación en la nube y la expansión de los requisitos de análisis de datos, la capacidad de análisis integrado del lago de datos + almacén de datos se ha convertido en la capacidad principal del sistema de análisis de datos de próxima generación. En comparación con los almacenes de datos, los lagos de datos tienen ventajas obvias en términos de costo, flexibilidad y análisis de datos de múltiples fuentes. Entre los diez pronósticos de las tendencias del mercado de la computación en la nube de China publicados por IDC en 2021, tres están relacionados con el análisis del lago de datos. Es previsible que las capacidades de integración entre sistemas, las capacidades de control de datos y las capacidades más completas basadas en datos serán áreas importantes de competencia para los futuros sistemas de análisis de datos.
La versión de AnalyticDB PostgreSQL (denominada ADB PG) es un producto de almacenamiento de datos nativo de la nube creado por el equipo de base de datos de Alibaba Cloud basado en el kernel de PostgreSQL (denominado PG). En escenarios comerciales como el análisis interactivo en tiempo real de datos de nivel PB, HTAP, ETL y generación de informes BI, ADB PG tiene ventajas técnicas únicas. Como producto de almacenamiento de datos, ¿cómo ADB PG tiene las capacidades de análisis integradas del lago y el almacén? Este artículo presentará cómo ADB PG crea capacidades de análisis de lago de datos basadas en la apariencia de PG.
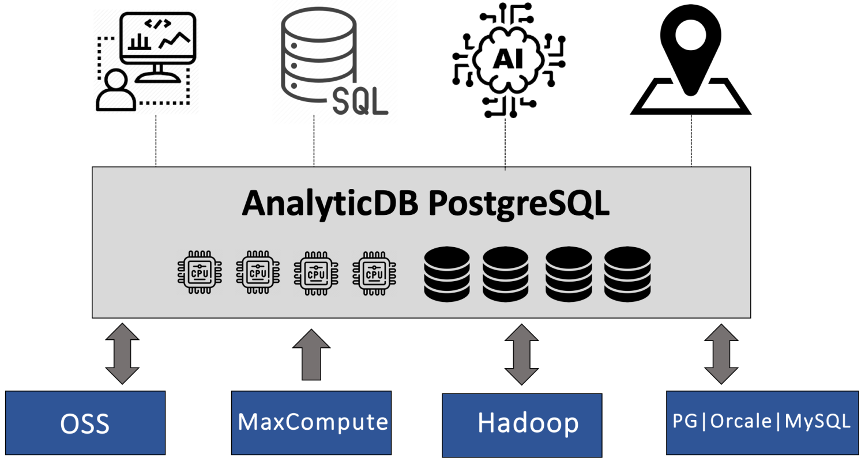
ADB PG hereda la función de tabla externa de PG. En la actualidad, las capacidades integradas de lago y almacén de ADB PG se basan principalmente en la apariencia. Basado en la apariencia de PG, ADB PG puede consultar y escribir datos de otros sistemas de análisis de datos. Si bien es compatible con múltiples fuentes de datos, reutiliza las ventajas del motor de ejecución y optimizador original de ADB PG. Las capacidades de análisis integradas de ADB PG del lago y el almacén actualmente admiten el análisis o la escritura de múltiples fuentes de datos como OSS, MaxCompute, Hadoop, RDS PG, Oracle y RDS MySQL. Los usuarios pueden aplicar ADB PG de manera flexible a diferentes campos, como almacenamiento de datos, análisis interactivo, ETL, etc., y pueden implementar múltiples funciones de análisis de datos en una sola instancia. ADB PG se puede utilizar para completar el proceso central del análisis de datos, y también se puede utilizar como uno de los muchos enlaces para construir un enlace de datos.
Sin embargo, el análisis de datos externos se basa en SDK externo y E / S de red para realizar la lectura y escritura de datos. Debido a que las características de la red en sí son muy diferentes del disco local, debe ser diferente del almacenamiento local a nivel técnico. y requiere diferentes soluciones de optimización del rendimiento. Este artículo toma como ejemplo la lectura y escritura de datos de tablas externas de OSS para presentar algunos problemas y soluciones importantes encontrados por ADB PG al construir las capacidades de análisis integradas del lago y el almacén.
2. Análisis de problemas
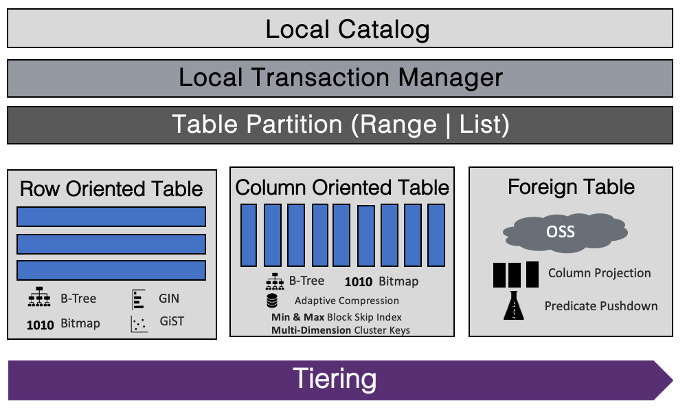
El kernel de ADB PG se puede dividir en optimizador, motor de ejecución y motor de almacenamiento. El análisis de datos de tablas externas puede reutilizar las partes centrales del optimizador original y el motor de ejecución de ADB PG, con solo una pequeña cantidad de modificación. La extensión principal es la transformación de la capa del motor de almacenamiento, que consiste en leer y escribir datos de tablas externas a través de la interfaz externa. Los datos de la tabla externa se almacenan en otro sistema distribuido y deben conectarse al ADB PG a través de la red. Esta es la principal diferencia con la lectura de archivos locales. Por un lado, diferentes datos externos proporcionarán diferentes interfaces de acceso remoto, que deben ser compatibles en ingeniería. Por ejemplo, las interfaces de lectura de datos de OSS y MaxCompute son diferentes. Por otro lado, acceder a datos en máquinas remotas a través de la red tiene ciertos puntos en común, como retrasos en la red, amplificación de la red, limitaciones de ancho de banda y problemas de estabilidad de la red.
Este artículo se centrará en los desafíos centrales anteriores e introducirá algunos puntos técnicos importantes del proyecto de análisis de apariencia ADB PG para respaldar el proceso de análisis de datos de OSS. OSS es un sistema de almacenamiento distribuido de bajo costo lanzado por Alibaba Cloud, que almacena una gran cantidad de datos fríos y calientes, y tiene mayores requisitos de análisis de datos. Para facilitar la expansión de los desarrolladores, OSS proporciona SDK basados en lenguajes de desarrollo convencionales como Java, Go, C / C ++ y Python. ADB PG adopta OSS C SDK para el desarrollo. En la actualidad, ADB PG ha soportado perfectamente varias funciones de análisis de tablas externas OSS Además de las diferentes sentencias de creación de tablas, los usuarios pueden acceder a las tablas externas OSS al igual que las tablas locales. Admite lectura y escritura simultáneas y admite formatos de datos comunes como CSV, ORC y Parquet.
3. Optimización de la tecnología de análisis de apariencia.
A continuación, presentamos algunos problemas técnicos centrales que ADB PG resolvió en el proceso de desarrollo del análisis de apariencia de OSS basado en OSS C SDK.
3.1 Problema de solicitud de fragmentación de red
En escenarios de bases de datos analíticas, la industria generalmente cree que el almacenamiento en columnas es mejor que el almacenamiento en filas en términos de rendimiento de E / S. Debido a que el almacenamiento en columnas solo necesita escanear columnas específicas al escanear datos, y el almacenamiento de filas escanea la cantidad total de datos después de todo, el almacenamiento en columnas puede ahorrar algunos recursos de E / S. Sin embargo, durante el proceso de desarrollo, el equipo descubrió que en algunos escenarios, como los escaneos de tablas de gran ancho con más campos, el formato de almacenamiento de columnas con mayor rendimiento de escaneo resultó ser peor que el formato de texto de almacenamiento de filas CSV de escaneo. Después del posicionamiento, se encontró que por un lado, al escanear el formato ORC / PARQUET, el cliente interactúa con el servidor OSS con demasiada frecuencia, por otro lado, la cantidad de datos que ADB PG solicita a OSS en un solo tiempo es relativamente pequeño. Estas dos razones han traído grandes problemas de rendimiento.
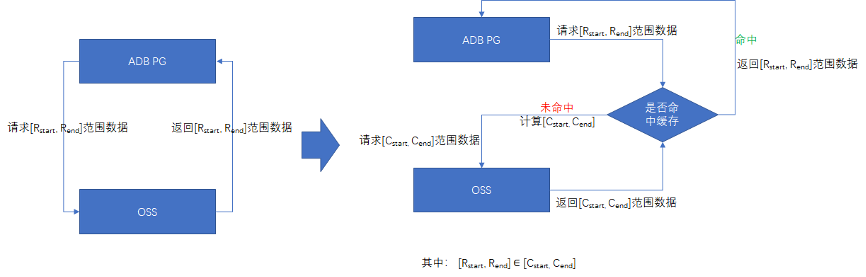
Sabemos que, en comparación con la E / S de disco local, el retardo de ida y vuelta generado por la E / S de red a menudo puede amplificarse en varios órdenes de magnitud. Por lo tanto, si se analizan algunos formatos de almacenamiento de columna (como ORC / PARQUET), si la solicitud de red se trata como una solicitud de disco local, la reducción en el uso del ancho de banda de la red causada por la alta relación de compresión no es suficiente para compensar el viaje de ida y vuelta. tiempo causado por solicitudes fragmentadas Amplificación retrasada, por lo que los resultados de la prueba de rendimiento son más bajos de lo esperado. La solución al problema es reducir las solicitudes de red fragmentadas mediante el almacenamiento en caché. Cada vez que ADB PG escanea datos de OSS, "precargará" suficientes datos y los almacenará en caché. Cuando lo solicite, determinará si la caché está activada o no. Si llega, volverá directamente a la caché; de lo contrario, continúe con la siguiente ronda de "precarga", lo que reduce la red El número de solicitudes mejora la eficiencia de una sola solicitud. El tamaño de la caché de "precarga" está abierto para la configuración y el tamaño predeterminado es de 1 MB.
3.2 filtrado de columnas y empuje de predicado
Dado que el rendimiento de E / S de la red en sí es a menudo menor que el rendimiento de E / S del almacenamiento local, es necesario minimizar el consumo de recursos de ancho de banda de E / S al escanear datos externos. ADB PG utiliza el filtrado de columnas y la tecnología de empuje hacia abajo de predicados para lograr este objetivo al procesar archivos en formato ORC y Parquet.
El filtrado de columnas, es decir, la tabla externa solo solicita las columnas de datos requeridas por la consulta SQL e ignora las columnas de datos innecesarias. Debido a que ORC y Parquet son formatos de almacenamiento en columnas, cuando la tabla externa inicia una solicitud de red, solo necesita solicitar el rango de datos donde se encuentra la columna requerida, lo que reduce en gran medida la E / S de la red. Al mismo tiempo, ORC y Parquet comprimirán los datos de la columna para reducir aún más la E / S.
La inserción de predicados consiste en mover las condiciones del filtro superior en el plan de ejecución (como las condiciones en la cláusula WHERE) al nodo de escaneo de apariencia inferior, de modo que cuando el escaneo de apariencia realiza solicitudes de red, filtra los bloques de datos que no cumplen con los requisitos. condiciones de consulta, reduciendo así las E / S de la red. En archivos de formato ORC / Parquet, las estadísticas como mínimo / máximo / suma de cada columna de datos en el bloque se guardarán en el encabezado de cada bloque. Cuando se escanea la tabla externa, las estadísticas del encabezado del bloque se leerán primero y Compare las condiciones de la consulta presionadas hacia abajo. Si la información estadística de la columna no cumple con las condiciones de la consulta, puede omitir los datos de la columna directamente.
Aquí hay una breve introducción a la implementación del predicado pushdown de la apariencia del formato ORC. Un archivo ORC se divide en varias bandas de acuerdo con las filas de datos, y los datos de la banda se almacenan en columnas. Cada raya se divide en varios grupos de filas y cada 10.000 filas de todas las columnas forman un grupo de filas. Como se muestra abajo.
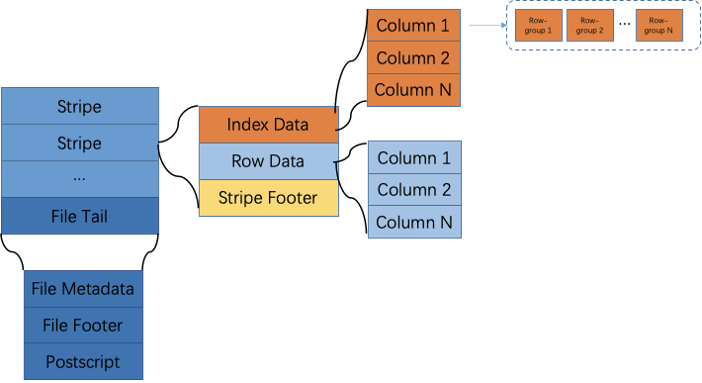
Los archivos ORC almacenan 3 niveles de información estadística: las estadísticas de nivel de archivo y de banda se almacenan al final del archivo ORC, y las estadísticas de nivel de grupo de filas se almacenan en la cabecera de cada bloque de banda. Usando estos tres niveles de información estadística, la tabla exterior ORC puede lograr filtrado a nivel de archivo, filtrado a nivel de banda y filtrado a nivel de grupo de filas. El método específico es que cada vez que se escanea un nuevo archivo ORC, las estadísticas a nivel de archivo al final del archivo se leerán primero. Si no se cumplen las condiciones de la consulta, se omitirá el escaneo de todo el archivo; luego todos los Stripe -Las estadísticas de nivel al final del archivo se leerán Información, filtre los bloques de franjas que no cumplan con las condiciones; para cada bloque de franjas que cumpla las condiciones, lea la información estadística de nivel de grupo de filas en el encabezado del bloque para filtrar los datos innecesarios .
3.3 Problema "996"
OSS C SDK define un tipo de código de error para indicar condiciones anormales, donde 996 es el código de error -996 definido en OSS C SDK. Hay códigos de error similares -998, -995, -992, etc. Este tipo de error generalmente es causado por la falla en la importación y exportación de apariencia OSS causada por anomalías en la red. -996 es el más común.
OSS C SDK utiliza internamente CURL para interactuar con el servidor OSS en la red. Los códigos de error CURL correspondientes son comunes CURL 56 (Restablecimiento de conexión por par), 52, etc. Estas anomalías en la red suelen ser causadas por el servidor OSS que elimina activamente las conexiones de los clientes que considera "inactivas" cuando la carga es alta. Cuando es necesario importar o exportar datos de OSS a gran escala, debido a que el cliente se encuentra en una etapa diferente del plan de ejecución, no puede mantener la conexión durante mucho tiempo para una comunicación continua, por lo que se considera un cliente "inactivo". conexión por el servidor OSS y cerrado.
Por lo general, para esta situación, el cliente debe intentar resolverlo nuevamente. En el proceso de desarrollo real, se descubrió que incluso si se agrega un mecanismo de reintento de excepción automático a la interfaz del cliente, esta excepción aún no se puede mejorar. Después del posicionamiento, se descubrió que OSS C SDK aumentó el grupo de conexiones de los identificadores CURL para mejorar la eficiencia de la conexión. Sin embargo, estos identificadores CURL anormales en la red también se almacenarán en el grupo. Por lo tanto, incluso si lo intenta de nuevo, seguirá use el mango CURL anormal para el procesamiento Comunicación, por lo que el problema de la anormalidad 996 no se puede mejorar.
Ahora que se conoce la causa raíz, la solución también es muy intuitiva. En la interfaz de recuperación del identificador CURL, agregamos una verificación en el estado del identificador CURL y destruimos el identificador CURL anormal en lugar de volver a agregarlo al grupo de conexiones. Esto evita identificadores CURL no válidos en el grupo de conexiones. Cuando la interfaz del cliente vuelva a intentarlo, seleccione una conexión CURL válida o cree una nueva para comunicarse nuevamente. Por supuesto, el mecanismo de reintento de excepción automática solo puede apuntar a aquellas situaciones que se pueden reintentar.
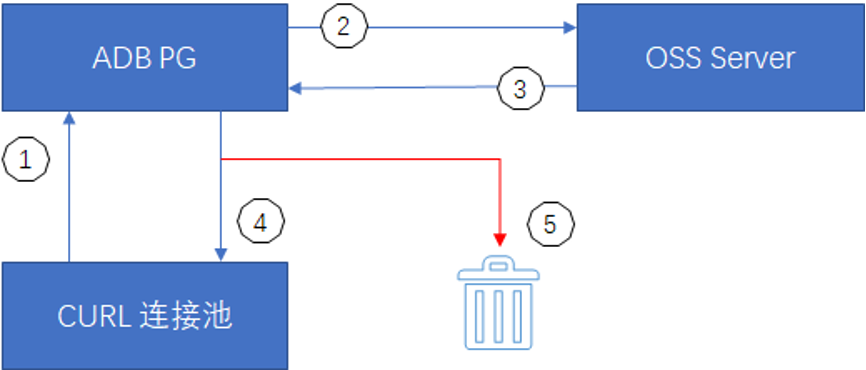
① Cuando ADB PG accede a la tabla externa OSS, primero obtiene la conexión del grupo de conexiones CURL y crea una nueva si no existe.
② ADB PG utiliza el identificador de conexión CURL para solicitar comunicación con el servidor OSS.
③ El servidor OSS devuelve el resultado de la comunicación a través del identificador de conexión CURL.
④ El identificador de conexión CURL devuelto normalmente se volverá a agregar al grupo de conexiones para ser utilizado la próxima vez después de su uso.
⑤ El identificador de conexión CURL en estado anormal está destruido.
3.4 Problemas de compatibilidad de los esquemas de administración de memoria
ADB PG se basa en el kernel de PostgreSQL y hereda el mecanismo de gestión de memoria de PostgreSQL. La gestión de memoria de PostgreSQL utiliza un contexto de memoria MemoryContext seguro para procesos, mientras que OSS C SDK es un grupo APR de contexto de memoria seguro para subprocesos. En el entorno de memoria MemoryContext, cada memoria asignada se puede liberar explícitamente llamando a free, y la fragmentación de la memoria la realiza MemoryContext, pero en el APR Pool, solo vemos la creación del pool de memoria, la aplicación de la memoria y la memoria. Operaciones como la destrucción del grupo, pero no hay una interfaz de liberación explícita para la memoria.
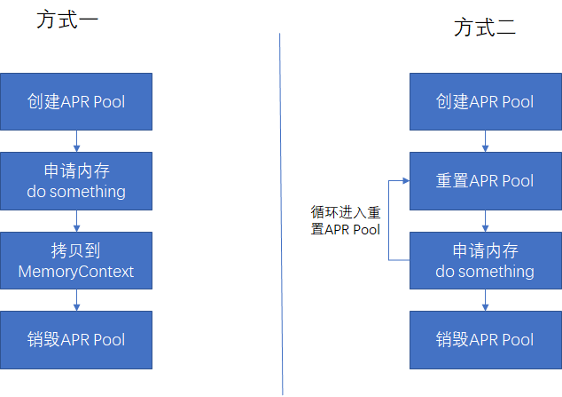
Esta situación significa que debemos tener una comprensión clara del ciclo de vida de la memoria en la interfaz OSS C SDK, de lo contrario, problemas como pérdidas de memoria y acceso a la memoria liberada son extremadamente fáciles de ocurrir. Por lo general, solicitaremos la memoria APR Pool de las dos formas siguientes.
· El método 1 es adecuado para volver a ingresar en interfaces de operación de baja frecuencia, como obtener una lista de archivos OSS.
· El método 2 es adecuado para múltiples interfaces de operación reentrante, como solicitar periódicamente datos del rango especificado del archivo especificado del OSS.
De esta forma, la incompatibilidad de gestión de memoria entre ADB PG y OSS C SDK se puede solucionar bien.
3.5 Compatibilidad y optimización del formato de datos
La mayoría de los datos en OSS utilizan CSV, ORC, Parquet y otros formatos. Dado que ORC / Parquet y otros formatos codifican el almacenamiento subyacente de datos, no es coherente con la codificación de datos de ADB PG, por lo que al realizar escaneos de tablas externas, la conversión del tipo de datos es un paso indispensable. La conversión de tipos consiste esencialmente en cambiar los datos de una codificación a otro método de codificación. Por ejemplo, la representación de ORC del tipo Decimal es diferente de la de ADB PG. En ORC, el tipo Decimal64 contiene un int64 para almacenar el valor numérico de los datos, y luego la precisión y la escala representan el número de dígitos y el número de decimales. En ADB PG, el tipo decimal El valor digital de los datos es almacenado por la matriz int16. El algoritmo de conversión de formato necesita realizar operaciones de módulo y división cíclica en cada dato, lo cual es muy intensivo en la CPU.
Para reducir el consumo de CPU causado por la conversión de tipo y optimizar aún más el rendimiento de la consulta de la tabla externa, cuando se utilizan tablas externas para exportar datos, ADB PG omite el paso de conversión de tipo y escribe directamente los datos de ADB PG en el archivo de la tabla externa en forma binaria. Al consultar la tabla externa, no es necesario realizar ninguna conversión de tipo de datos. Por ejemplo, al exportar la tabla externa ORC, la tabla externa puede escribir cualquier tipo de datos directamente como el tipo binario del ORC. Los datos binarios almacenados en el ORC se codifican de acuerdo con el tipo de datos del ADB PG correspondiente, por lo que la consulta En el caso de la aparición de ORC, el paso de conversión de tipo se puede omitir directamente, lo que reduce el consumo de CPU. De acuerdo con los resultados de la prueba de consulta de TPCH, el rendimiento general de la consulta se puede mejorar entre un 15% y un 20%.
4. Prueba de rendimiento
Para saber cómo utilizar la función de análisis de apariencia en ADB PG, consulte el manual del producto Alibaba Cloud ( https://help.aliyun.com/document_detail/164815.html?spm=a2c4g.11186623.6.602.78db2394eaa9rq ). Excepto por las diferentes declaraciones de construcción de tablas, casi no hay diferencia entre el funcionamiento de la mesa externa y el funcionamiento de la mesa local, y la dificultad de aprendizaje es muy baja. Comparemos los problemas de rendimiento del escenario de análisis de apariencia de OSS con el escenario de análisis de tabla local.
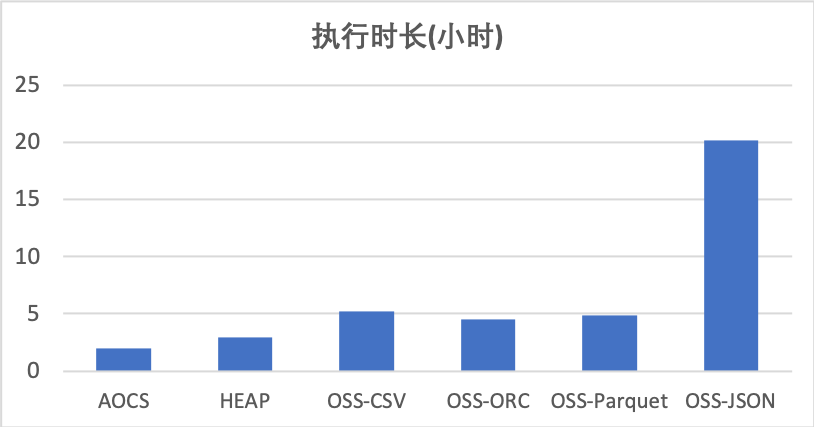
Configuración ambiental. La máquina utilizada en nuestra prueba es el modelo Alibaba Cloud ECS d1ne.4xlarge. Una sola máquina está configurada con 16 núcleos Intel Xeon E5-2682v4, 64 GB de memoria y cada ECS está configurado con 4 discos locales HDD. La velocidad de lectura y escritura de cada disco es de aproximadamente 200 MB / s. En la prueba 1, se utilizaron 4 ECS, dos se utilizaron como nodos maestros y 4 como nodos de segmento, se desplegaron un total de 16 segmentos. Esta prueba usa la consulta TPCH, usando el conjunto de datos de 1TB generado por la herramienta oficial.
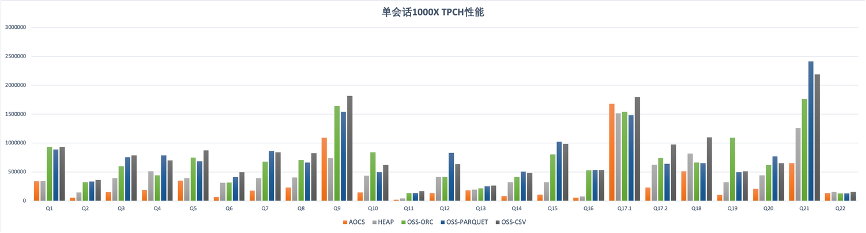
Para la tabla local, probamos los formatos de tabla de almacenamiento de columnas comprimidas (AOCS) y HEAP. Para la tabla externa OSS, probamos los formatos CSV, ORC, Parquet y JSON. El tiempo total de ejecución de 22 consultas TPCH se muestra en la siguiente tabla. Puede verse en los datos de prueba que entre las dos tablas locales, el rendimiento de la consulta de la tabla AOCS es ligeramente mejor que el de la tabla HEAP. En términos de apariencia, el rendimiento de las consultas de los formatos CSV, ORC y Parquet es ligeramente más lento que el de las tablas locales, con una brecha de aproximadamente el 50%. El rendimiento de la consulta de apariencia del formato JSON es significativamente más lento que el de otros formatos. Esto se debe principalmente a la lenta velocidad de análisis del formato JSON en sí y no tiene nada que ver con la apariencia.
La siguiente figura muestra el tiempo detallado de 22 consultas TPCH. La brecha de rendimiento entre la tabla local y la tabla externa difiere en diferentes consultas. Teniendo en cuenta las ventajas de la apariencia en términos de costo de almacenamiento, flexibilidad y escalabilidad, el potencial del análisis de apariencia de ADB PG en escenarios de aplicación es enorme.
V. Resumen
La integración de lago y almacén es una capacidad importante de la próxima generación de productos de almacén de datos. Como producto de almacén de datos potente y extensible, ADB PG ha desarrollado una variedad de capacidades de análisis y escritura de fuentes de datos basadas en la apariencia de PG, y ha acumuló mucha tecnología de optimización del rendimiento. En el futuro, ADB PG continuará esforzándose en las funciones del producto, la rentabilidad, las capacidades nativas de la nube y la integración de lagos y almacenes para brindar a los usuarios más funciones, rendimiento y optimización de costos.