
iQiyi creó un almacén de datos tradicional fuera de línea basado en Hive para respaldar las decisiones operativas de la empresa, el crecimiento de usuarios, las recomendaciones de videos, la membresía, la publicidad y otras necesidades comerciales. En los últimos años, las empresas tienen mayores requisitos de datos en tiempo real. Introdujimos la tecnología de lago de datos basada en Iceberg para mejorar significativamente el rendimiento de las consultas de datos y la eficiencia general de la circulación. Desde una perspectiva de rendimiento y costo, es necesario migrar las tablas de Hive existentes al lago de datos. Sin embargo, a lo largo de los años, se han acumulado cientos de petabytes de datos de Hive en la plataforma de big data. Cómo migrar Hive al lago de datos se ha convertido en un gran desafío al que nos enfrentamos. Este artículo presenta la solución técnica de iQiyi para una migración fluida del lago de datos de Hive al Iceberg, ayudando a las empresas a acelerar los procesos de datos y mejorar la eficiencia y los ingresos.
01
Colmena contra Iceberg
Hive es una plataforma de análisis y almacenamiento de datos basada en Hadoop que proporciona un lenguaje similar a SQL para admitir el procesamiento y análisis de datos complejos.
Iceberg es un formato de tabla de datos de código abierto diseñado para proporcionar almacenamiento de tablas escalable, estable y eficiente para soportar cargas de trabajo analíticas. Iceberg proporciona garantías transaccionales y coherencia de datos similares a las bases de datos tradicionales, y admite operaciones de datos complejas como actualizaciones, eliminaciones, etc.
La Tabla 1-1 enumera la comparación entre Hive e Iceberg en términos de puntualidad, rendimiento de consultas, etc.:
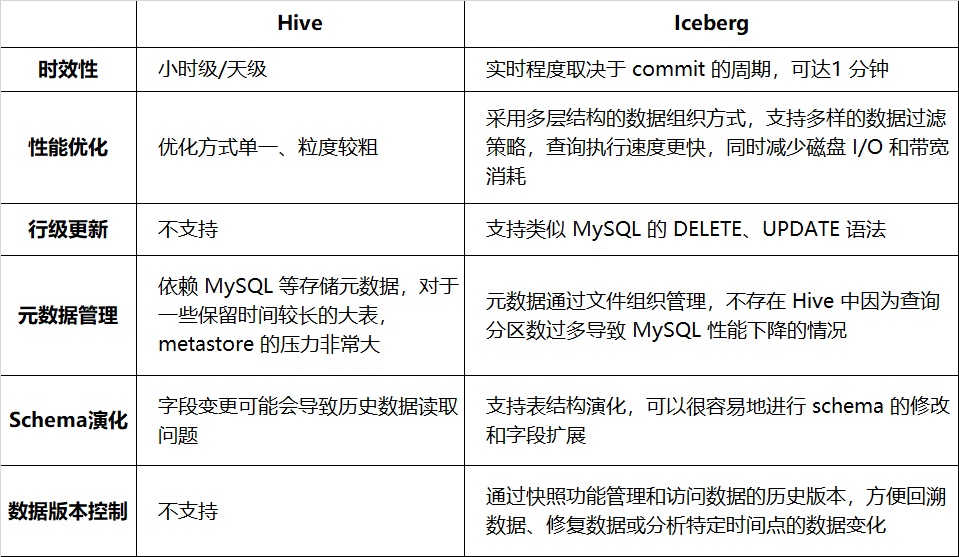
Tabla 1-1 Comparación entre Hive e Iceberg
Cambiar a Iceberg puede mejorar la eficiencia y confiabilidad del procesamiento de datos y brindar un mejor soporte para operaciones de datos complejas. Actualmente, se ha conectado a más de una docena de negocios, como publicidad, membresía, registros de Venus y auditoría. Para obtener más detalles sobre la práctica Iceberg de iQiyi, puede leer la serie de artículos anterior (consulte la cita al final del artículo).
02
Iceberg de cambio fluido de datos de acciones de Hive
Iceberg tiene muchas ventajas sobre Hive, pero los datos comerciales ya se están ejecutando en el entorno de Hive y la empresa no quiere invertir mucha mano de obra en modificar las tareas de inventario. Hemos investigado métodos de conmutación comunes en la industria [1] y brindamos la capacidad de cambiar sin problemas entre Hive de autoservicio e Iceberg en la plataforma del lago de datos. Esta sección describirá el plan de implementación específico.
1. Verificar compatibilidad
Antes del cambio real, verificamos la compatibilidad de Spark con Hive e Iceberg.
La sintaxis de consulta y escritura de Spark para las tablas de Hive y Iceberg es básicamente la misma. Las declaraciones SQL para consultar tablas de Hive pueden consultar tablas de Iceberg sin modificaciones.
Sin embargo, existen grandes diferencias entre Iceberg y Hive en términos de DDL, principalmente en la forma de modificar la estructura de la tabla. Los detalles se describen en la Tabla 2-1. Es necesario que exista una correspondencia uno a uno entre el esquema real y el esquema del archivo de datos; de lo contrario, afectará la consulta de datos. Por lo tanto, no se recomienda vincular al procesar declaraciones DDL. tales declaraciones DDL con tareas.
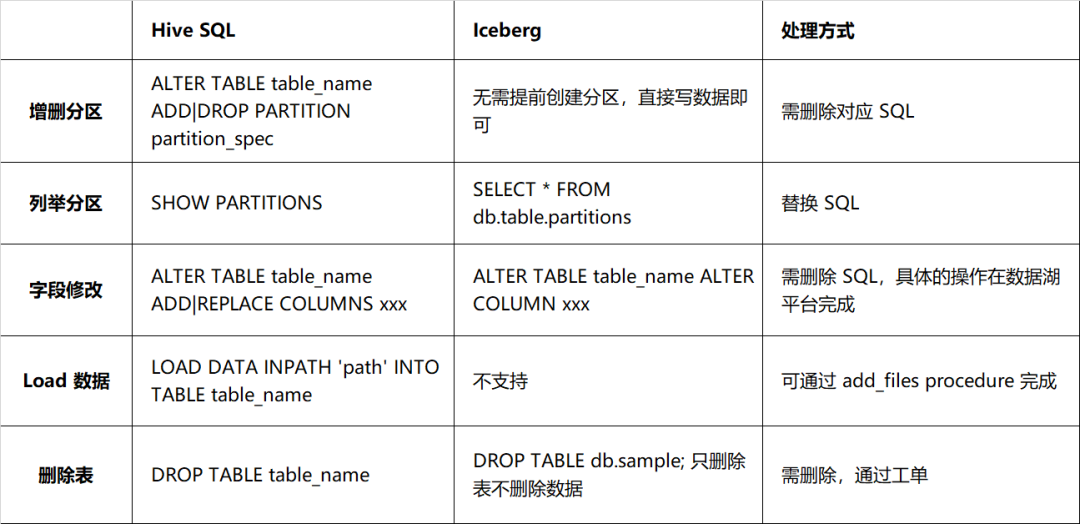
Tabla 2-1 Comparación de compatibilidad de sintaxis entre Hive e Iceberg
2. Solución de cambio de industria
2.1 Conmutación empresarial de doble escritura
La empresa replica el proceso existente para implementar la escritura dual de Hive e Iceberg. Una vez que los pares de canales antiguos y nuevos sean consistentes, cambie al canal Iceberg y cierre sesión en el canal original. Esta solución requiere que la empresa invierta mano de obra en desarrollo y cálculo, lo que requiere mucho tiempo y mano de obra.
2.2 Cambio en su lugar, el cliente deja de escribir
Si a la empresa se le permite dejar de escribir por un período de tiempo y cambiar, se pueden utilizar los siguientes métodos:
-
El procedimiento de migración de Spark es una función proporcionada oficialmente por Iceberg, que puede cambiar una tabla de Hive a Iceberg. El ejemplo es el siguiente:
LLAMAR catalog_name.system.migrate('db.sample'); |
Este programa no modifica los datos originales, solo escanea los datos de la tabla original y luego construye metainformación Iceberg, haciendo referencia al archivo original. Por lo tanto, el programa de migración se ejecuta muy rápidamente, pero los datos existentes no pueden utilizar funciones como índices de archivos para acelerar las consultas. Si desea que los datos existentes también se aceleren, puede utilizar el método rewrite_data_files de Spark para reescribir los datos históricos.
El programa de migración no elimina la tabla de Hive, pero le cambia el nombre a sample__BACKUP__. El sufijo __BACKUP__ aquí está codificado. Si necesita revertir, puede descartar la tabla Iceberg recién creada y cambiarle el nombre.
-
Usando la declaración CTAS , el ejemplo de Spark es el siguiente:
CREAR TABLA db.sample_iceberg USANDO Iceberg PARTICIONADO POR dt UBICACIÓN 'qbfs://....' TBLPROPERTIES('write.target-file-size-bytes' = '512m', ...) COMO SELECCIONAR * DESDE db.sample; |
Una vez completada la escritura, se realiza el logaritmo. Una vez que se cumplen los requisitos, se completa el cambio cambiando el nombre.
ALTERAR TABLA db.sample RENOMBRAR A db.sample_backup; ALTERAR TABLA db.sample_iceberg RENOMBRAR A db.sample; |
La ventaja de CTAS en comparación con la migración es que los datos existentes se reescriben, por lo que puede optimizar la partición, la clasificación de columnas, los formatos de archivo, los archivos pequeños, etc. La desventaja es que si hay muchos datos existentes, reescribirlos requiere mucho tiempo y recursos.
Las dos soluciones anteriores tienen las siguientes características:
ventaja:
La solución es simple, simplemente ejecute SQL existente
Se puede revertir, la tabla original de Hive todavía está allí.
defecto:
Escritura/lector no validado: pueden ocurrir excepciones de escritura o consulta después de cambiar a la tabla Iceberg
Exigir que el proceso de cambio deje de escribir es inaceptable para algunas empresas
3. Plan de migración sin problemas de iQiyi
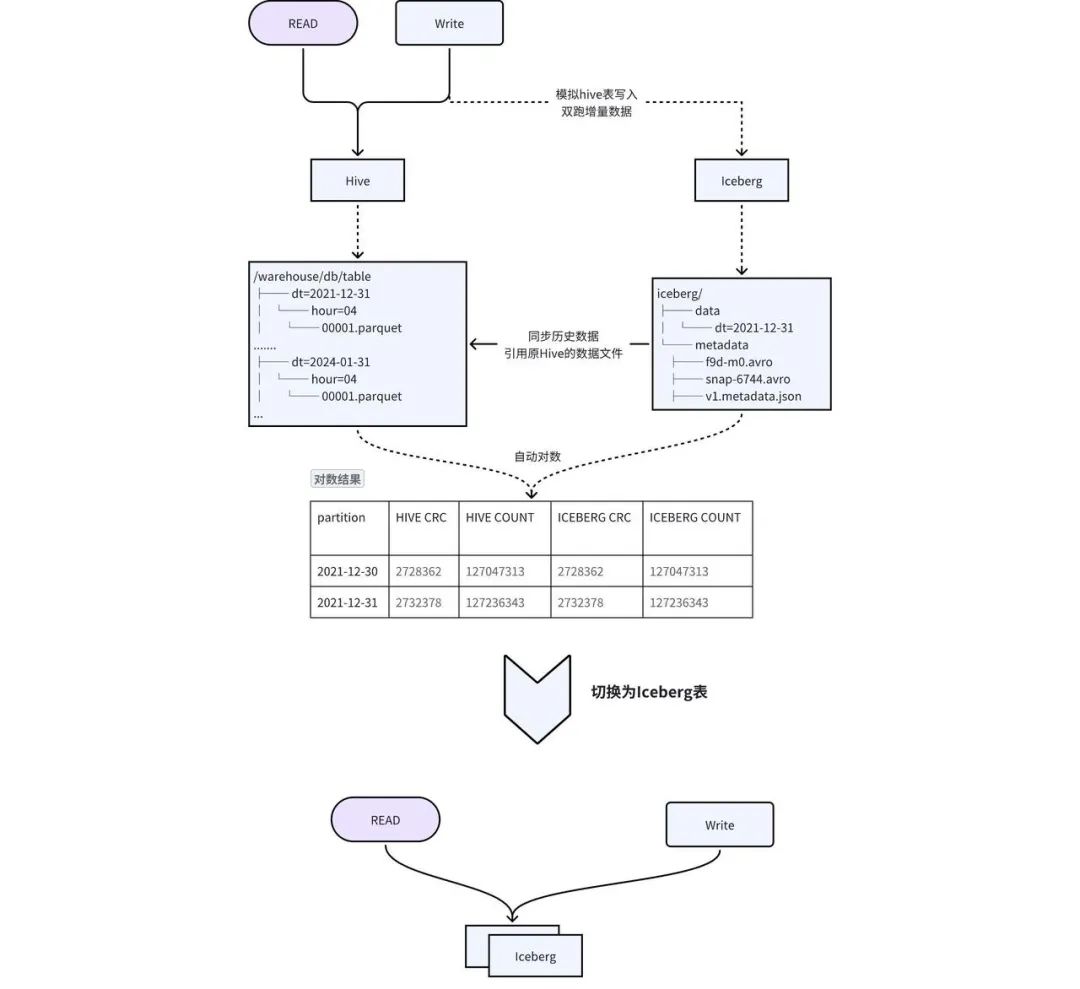
Teniendo en cuenta las deficiencias de la solución anterior, diseñamos una solución de escritura dual local + conmutación transparente para lograr una migración fluida, como se muestra en la Figura 2-1:
-
Creación de tablas : cree una tabla Iceberg con el mismo esquema que Hive y sincronice metainformación como TTL y permisos de la tabla Hive con la tabla Iceberg. -
Migración de datos históricos a Iceberg : los datos históricos de Hive se agregan a Iceberg mediante el procedimiento add_file . Esta operación construirá los metadatos de Iceberg basándose en los datos de Hive. De hecho, los metadatos de Iceberg apuntan a los archivos de datos de Hive, lo que reduce la redundancia de datos y el tiempo de sincronización de datos históricos. -
Doble escritura de datos incrementales : La puerta de enlace Pilot SQL de desarrollo propio de iQIYI detecta tareas de escritura en la tabla Hive, copia y escribe SQL automáticamente y reemplaza la salida con la tabla Iceberg para lograr una doble escritura. -
数据一致性 校验: 当历史数据同步完成且增量双写到一定次数之后,后台会自动发起对数,校验 Hive 和 Iceberg 中的数据是否一致。对于历史数据与增量数据会选取一部分数据进行 count 以及字段 CRC 数值校验。 -
切换 : 数据一致性校验完成后,进行 Hive 和 Iceberg 的切换,用户不需要修改任务,直接使用原来的表名进行访问即可。正常切换过程耗时在几分钟之内。
03
核心收益 - 加速查询
1. Iceberg 查询加速技术
2. Iceberg 加速技巧
-
配置分区:使用分区剪裁的方式使查询只针对特定分区的数据执行,而不需要扫描整个数据集。 -
指定排序列:通过对数据分布进行合理的组织,最大限度的发挥文件级别的过滤效果,使得查询只集中在特定的文件。例如通过下面的方式使得写入 sample 表的数据按照 category, id 降序写入,注意由于多了一个排序的环节,这种方式会比非排序的写入耗时长。
|
|
-
高基数列应用布隆过滤器:在查询数据时,会自动应用布隆过滤器来快速验证查询数据是否存在于某个数据块,避免不必要的磁盘访问。
|
|
-
使用 Trino 代替 Spark:由于 Trino 自身 MPP 的架构,在查询上相较于 Spark 更有优势,并且 Trino 自身对 Iceberg 也有相应的优化,因此如果有秒级查询的需求,可将引擎由 Spark 切换到 Trino。 -
Alluxio 缓存:使用 Alluxio 作为数据缓存层,将数据缓存在内存中。在查询时可以直接从内存中获取数据,避免从磁盘读取数据的开销,可大大提高查询速度,也可防止 HDFS 抖动对任务的影响。 -
ORC 代替 Parquet:由于 Trino 对 ORC 格式有特定的优化,使得 ORC 的读取性能要优于 Parquet,可以将文件格式设置为 ORC 加速查询。 -
配置合并:写 Iceberg 的任务往往会出现写入文件较小但数量较多的情况,通过将小文件合并成一个或少量更大的文件,有利于减少读取的文件数,降低磁盘 I/O。
3. 性能评测
3.1 文件内过滤性能提升
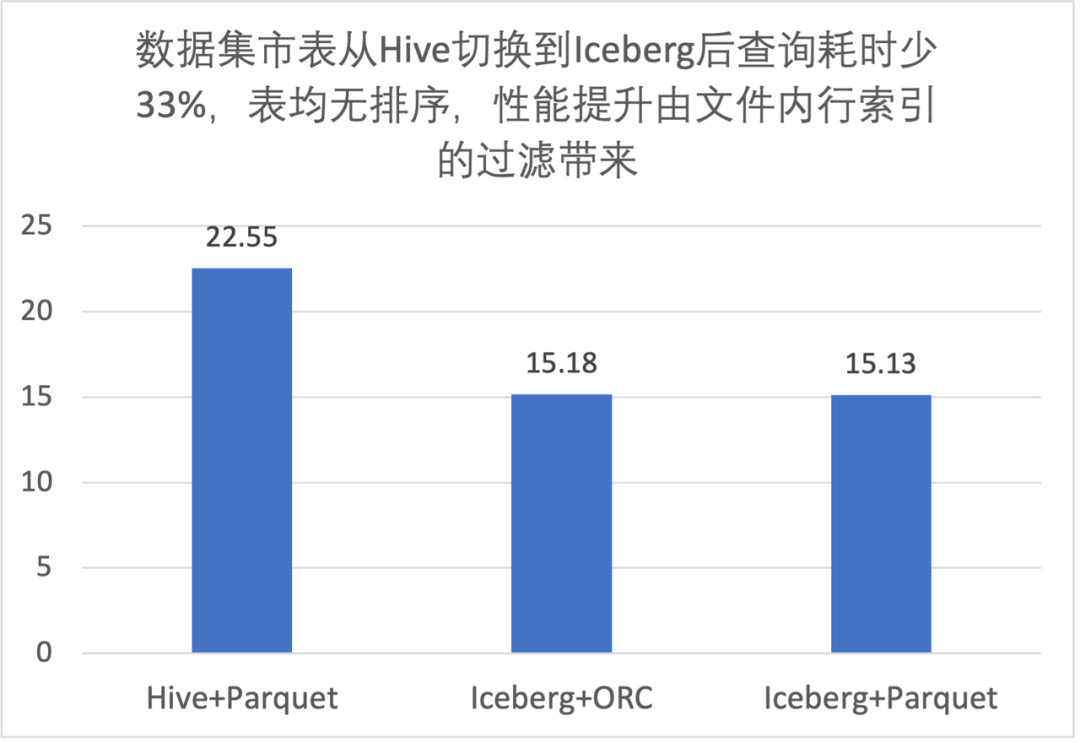
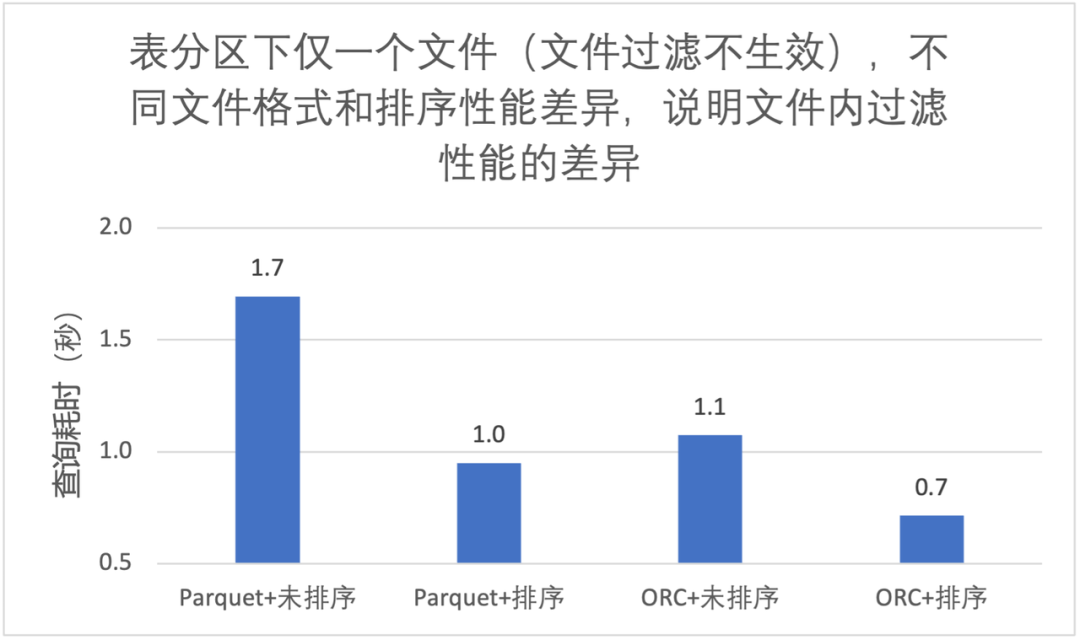
3.2 列排序对文件内过滤性能提升
-
同样的文件格式,排序后文件内过滤效果更好,大致能快 40%; -
ORC 查询性能优于 Parquet; -
使用 Trino 查询,我们推荐 Iceberg 表 + ORC 文件格式 + 列排序;
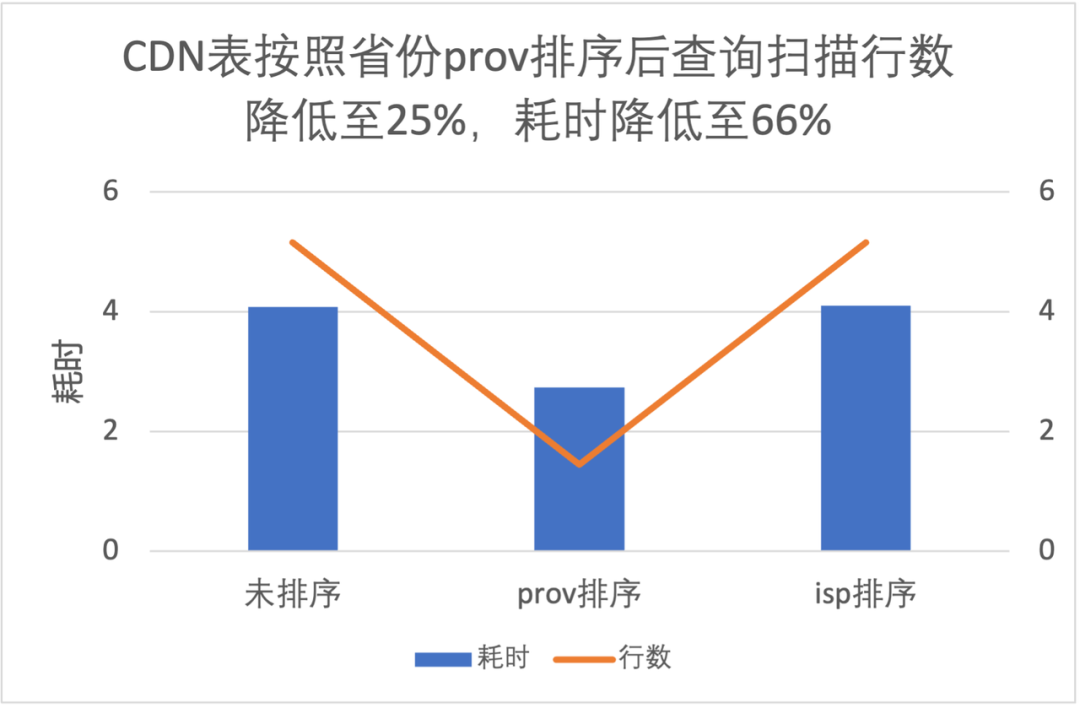
3.3 列排序对文件级过滤性能提升
|
|
-
按照 prov 排序查询读取数据量是不排序的 25%,耗时是 66%; -
按照 isp 排序提升不明显,这是因为 isp 数据量有明显的倾斜,条件中 isp 值占比高达 90%;
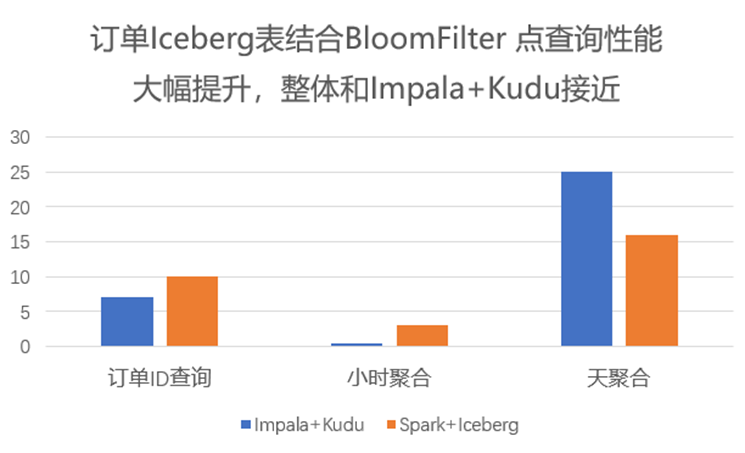
3.4 布隆过滤器的性能提升
3.5 Spark 和 Trino 性能比较
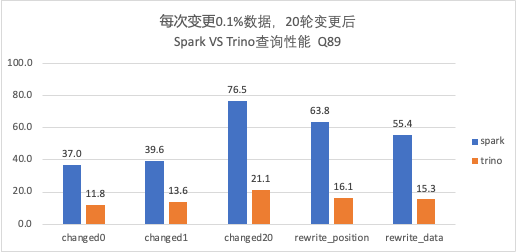
-
Trino 对于 V2 表查询结果与 Spark 一致,且在相同核数性能优于 Spark,耗时是 Spark 的 1/3 左右; -
随着变更轮次的增加(Data File 和 Postition Delete File 数量增加),Trino 查询性能也会逐渐变慢,需要定期进行合并。
04
核心收益 - 支持变更
1. 变更在业务使用场景
-
ETL 计算:如广告计费,通过接入 Iceberg 实现变更,简化业务逻辑,实现了更长时间范围的转化回收; -
数据修正:批量修正,如对某个数据的状态进行修改、批量删除等; -
隐私相关:如播放记录、搜索记录,用户需要删除历史条目等; -
CDC 同步:如订单业务,需要将 MySQL 中的数据进行大数据分析,通过 Flink CDC 技术很方便地将 MySQL 数据入湖,实时性可达到分钟级。
2. Hive 如何实现变更
-
分区覆写 例如修改某个 id 的相关内容,先筛选出要修改的目标行,更新后与历史数据进行合并,最后覆盖原表。这种方式对不需要修改的数据进行了重写,浪费计算资源;且覆写的粒度最小是分区级别,数据无法进一步细分,任务耗时相对较长。 -
标记删除 通常的做法是添加标志位,数据初始写入时标志位置 0,需要删除时,插入相同的数据,且标志位置 1,查询时过滤掉标志位为 1 的数据即可。这种方式在语义上未实现真正的删除,历史数据仍然保存在 Hive 中,浪费空间,而且查询语句较为复杂。
3. Iceberg 支持的变更类型
-
Delete:删除符合指定条件的数据,例如
|
|
-
Update:更新指定范围的数据,例如
|
|
-
MERGE:若数据已存在 UPDATE,不存在执行 INSERT,例如
|
|
4. Iceberg 变更策略
-
Copy on Write(写时合并):当进行删除或更新特定行时,包含这些行的数据文件将被重写。写入耗时取决于重写的数据文件数量,频繁变更会面临写放大问题。如果更新数据分布在大量不同的文件,那么更新的执行速度比较慢。这种方式由于结果文件数较少,读取的速度会比较快,适合频繁读取、低频批次更新的场景。 -
Merge on Read(读时合并):文件不会被重写,而是将更改写入新文件,当读取数据时,将新文件合并到原始数据文件得到最终结果。这使得写入速度更快,但读取数据时必须完成更多工作。写入新文件有两种方式,分别是记录删除某个文件对应的行(position delete)、记录删除的数据(equality detete)。 -
Position Delete:当前 Spark 的实现方式,记录变更对应的文件及行位置。这种方式不需要重写整个数据文件,只需找到对应数据的文件位置并记录,减少了写入的延迟,读取时合并的代价较小。 -
Equality Delete:当前 Flink 的实现方式,记录了删除数据行的主键。这种方式要求表必须有唯一的主键,写入过程无需查询数据文件,延迟最低;然而它的读取代价最大,这是由于读取时需要将 equality delete 记录和所有的原始文件进行 JOIN。
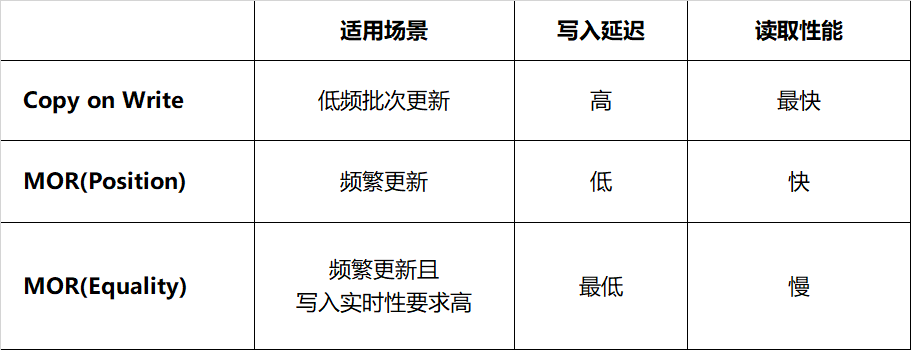 表 4-1 Iceberg 不同变更策略对比
表 4-1 Iceberg 不同变更策略对比
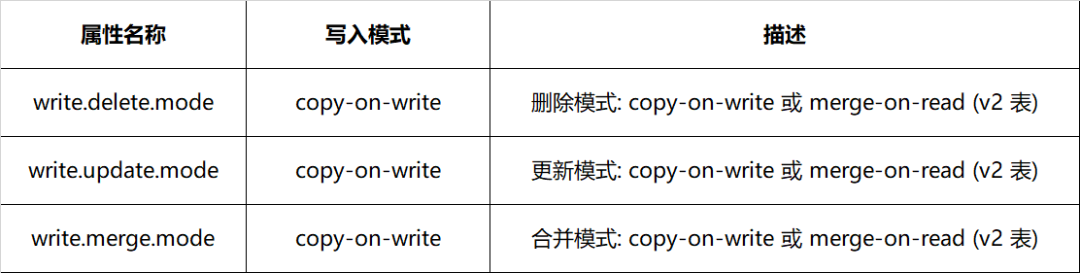 表 4-2 Iceberg 变更属性配置方式
表 4-2 Iceberg 变更属性配置方式
5. 业务接入
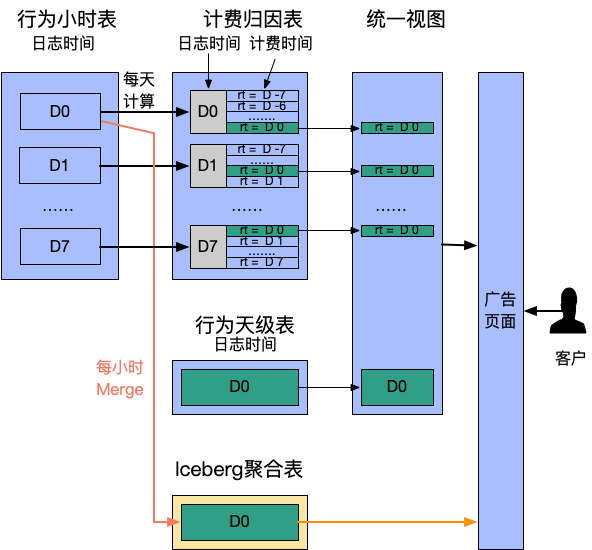
5.1 广告计费转换
-
每天触发一次计算,从行为表聚合出过去 7 天的“计费时间”数据。此处用 rt 字段代表计费时间 -
提供统一视图合并行为数据和计费时间数据,计费归因表 rt as dt 作为分区过滤查询条件,满足同时检索曝光和计费转化的需求
|
|
-
时效性提升:从天级缩短到小时级,客户更实时观察成本,有利于预算引入; -
计算更长周期数据:原先为计算效率仅提供 7 日内转换,而真实场景转换周期可能超过 1 个月; -
表语义清晰:多表联合变为单表查询。
5.2 数据修正
|
|
05
总结
06
引用
-
From Hive Tables to Iceberg Tables: Hassle-Free -
通过数据组织优化加速基于Apache Iceberg的大规模数据分析 -
Row-Level Changes on the Lakehouse: Copy-On-Write vs. Merge-On-Read in Apache Iceberg -
《爱奇艺数据湖实战 - 综述》 -
《爱奇艺数据湖实战 - 广告》 -
《爱奇艺数据湖实战 - 基于数据湖的日志平台架构演进》 -
《爱奇艺数据湖实战 - 数据湖技术在爱奇艺BI场景的应用》 -
《爱奇艺在Iceberg落地相关性能优化与实践》

本文分享自微信公众号 - 爱奇艺技术产品团队(iQIYI-TP)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。