Este artículo fue compartido por Li Jinsong y Hu Zheng, y organizado por los voluntarios comunitarios Yang Weihai y Li Peidian. Principalmente introduce el esquema y el principio de lectura y escritura en tiempo real de datos CDC en la arquitectura del lago de datos. El artículo se divide principalmente en 4 partes:
- Soluciones de análisis comunes de los CDC
- Por qué elegir Flink + Iceberg
- Cómo escribir y leer en tiempo real
- plan futuro
1. Programa común de análisis de los CDC
Primero echemos un vistazo a lo que debe diseñarse para el tema de hoy. La entrada es un CDC o datos upsert, y la salida es una base de datos o almacenamiento para análisis OLAP de big data.
Nuestra entrada común incluye principalmente dos tipos de datos. El primer dato son los datos CDC de la base de datos, que continuamente genera changeLog; el otro escenario son los datos upsert generados por stream computing. La última versión de Flink 1.12 ya ha admitido los datos upsert.
1.1 Datos de CDC de análisis de conglomerados de HBase sin conexión
La primera solución en la que solemos pensar es procesar los datos de inserción de CDC a través de Flink y luego escribirlos en HBase en tiempo real. HBase es una base de datos en línea que puede proporcionar capacidades de consulta en línea. Tiene un rendimiento muy alto en tiempo real, es muy amigable para escribir operaciones, también puede admitir algunas consultas a pequeña escala y el clúster es escalable.
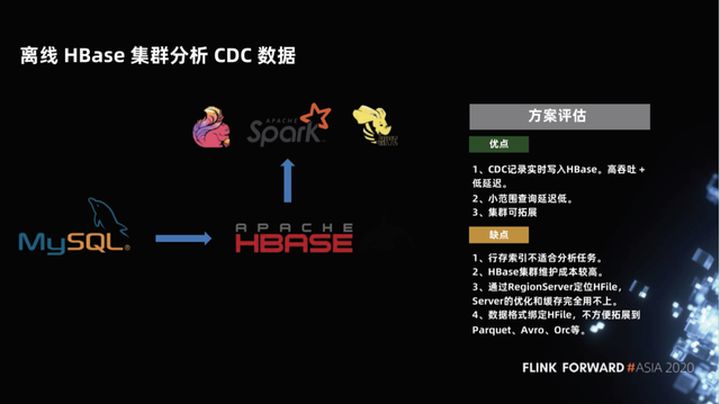
Este tipo de esquema es en realidad el mismo que el enlace ordinario en tiempo real para la verificación de puntos. Entonces, ¿cuál es el problema con el uso de HBase para el análisis de consultas OLAP de big data?
En primer lugar, HBase es una base de datos diseñada para la verificación de puntos y un servicio en línea.Su índice almacenado en filas no es adecuado para tareas de análisis. Se debe enumerar el diseño típico del almacén de datos, de modo que la eficiencia de la compresión y la eficiencia de las consultas sean altas. En segundo lugar, el costo de mantenimiento del clúster de HBase es relativamente alto. Finalmente, el dato de HBase es HFile, que es inconveniente de combinar con los típicos Parquet, Avro, Orc, etc. en el big data warehouse.
1.2 Apache Kudu mantiene el conjunto de datos de CDC
En respuesta a las capacidades de análisis relativamente débiles de HBase, un nuevo proyecto apareció en la comunidad hace unos años, que es el proyecto Apache Kudu. Si bien el proyecto Kudu tiene la capacidad de HBase para verificar, también utiliza el almacenamiento en columna, por lo que la aceleración del almacenamiento en columna es muy adecuada para el análisis OLAP.
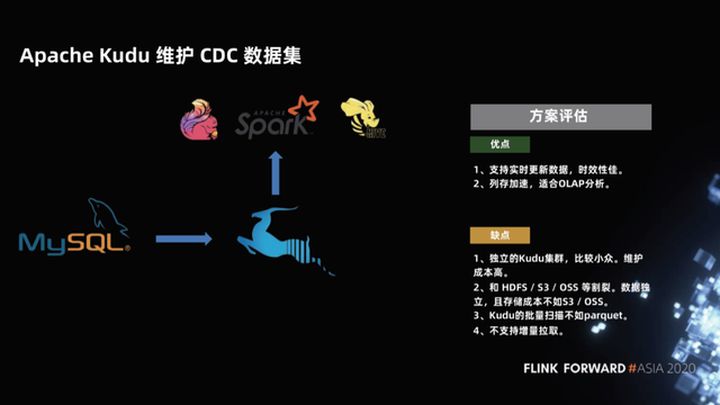
¿Cuáles son los problemas con este esquema?
En primer lugar, Kudu es un clúster independiente relativamente pequeño y su costo de mantenimiento es relativamente alto, más fragmentado de HDFS, S3 y OSS. En segundo lugar, debido a que Kudu conserva la capacidad de verificar su diseño, su rendimiento de escaneo por lotes no es tan bueno como el parquet. Además, el soporte de Kudu para eliminar es relativamente débil y, finalmente, no admite la extracción incremental.
1.3 Importar directamente CDC a análisis de Hive
La tercera solución, que también se usa comúnmente en almacenes de datos, es escribir datos MySQL en Hive. El proceso es: mantener una partición completa, luego hacer una partición incremental todos los días y finalmente escribir la partición incremental. Después de eso, realice una Fusionar y escribir una nueva partición Esto funciona bien en el proceso. La partición completa antes de Hive no se ve afectada por el incremento. Solo después de que la fusión incremental sea exitosa, la partición se puede verificar y es un dato nuevo. Este tipo de datos adjuntos puramente enumerados es muy fácil de analizar.
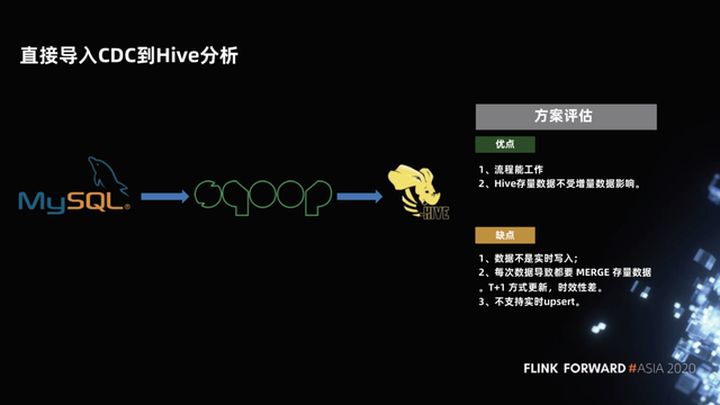
¿Cuáles son los problemas con este esquema?
La combinación de datos incrementales y datos completos tiene un retraso y los datos no se escriben en tiempo real. Normalmente, una combinación se realiza una vez al día, que son datos T + 1. Por lo tanto, la puntualidad es muy baja y no se admite la actualización en tiempo real. Cada combinación necesita releer y reescribir todos los datos, lo cual es relativamente ineficiente y desperdicia recursos.
1.4 Datos de CDC de análisis Spark + Delta
En respuesta a este problema, Spark + Delta proporciona la sintaxis MERGE INTO al analizar datos de CDC. Esto no es solo una simplificación de la sintaxis del almacén de datos de Hive. Spark + Delta, como una nueva arquitectura de lago de datos (como Iceberg, Hudi), administra datos, no particiones, sino archivos. Por lo tanto, Delta optimiza la sintaxis MERGE INTO y sólo explora. Simplemente vuelva a escribir los archivos modificados, por lo que es mucho más eficiente.
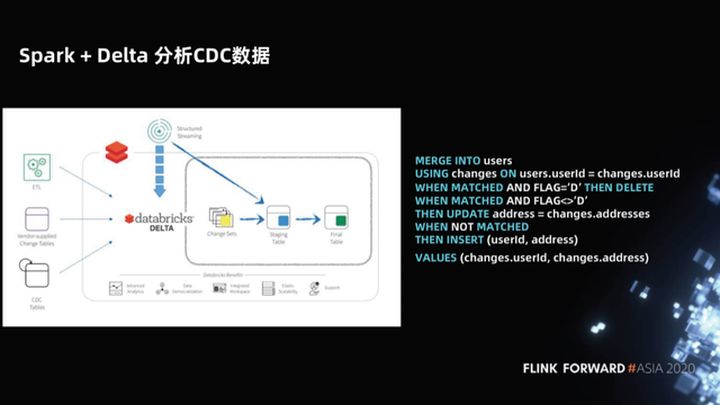
Evaluemos esta solución, sus ventajas son que solo cuenta con Spark + Delta, la arquitectura es simple, no hay servicio en línea, almacenamiento de columnas y la velocidad de análisis es muy rápida. La velocidad de sintaxis optimizada de MERGE INTO es lo suficientemente rápida.
Este programa es un programa de copia en escritura comercial, solo necesita copiar una pequeña cantidad de archivos, lo que puede hacer que la demora sea relativamente baja. Teóricamente, si los datos actualizados no se superponen con el stock existente, el retraso a nivel de día se puede lograr como un retraso a nivel de hora y se puede mantener el rendimiento.
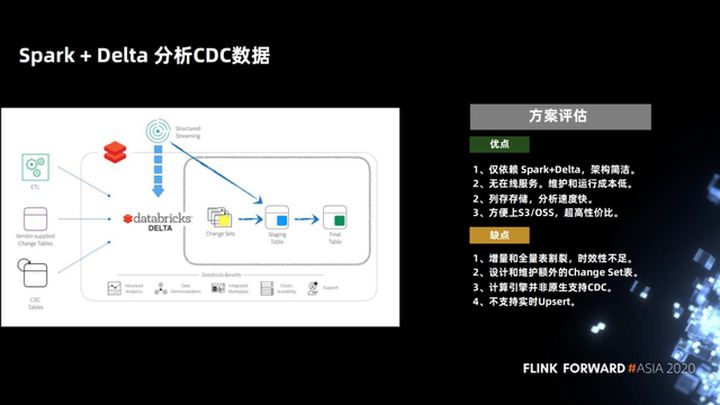
Esta solución ha dado un pequeño paso adelante en la forma de procesar datos de inserción en el almacén de Hive. Pero, después de todo, el retraso horario no es tan efectivo como el tiempo real, por lo que la mayor desventaja de esta solución es que la combinación de copia en escritura tiene una cierta sobrecarga y el retraso no puede reducirse demasiado.
Probablemente haya tantas soluciones existentes en la primera parte. Al mismo tiempo, se debe enfatizar que la razón por la cual upsert es tan importante es que en la solución de lago de datos, upsert es un punto tecnológico clave para realizar el cuasi-real -Acceso a la base de datos en tiempo y tiempo real del lago.
2. ¿Por qué elegir Flink + Iceberg?
2.1 Soporte de Flink para el consumo de datos de CDC
En primer lugar, Flink admite de forma nativa el consumo de datos de los CDC. En la solución Spark + Delta anterior, la gramática de MARGE INTO, los usuarios necesitan percibir el concepto de atributos CDC y luego escribir la gramática de fusión. Pero Flink admite datos CDC de forma nativa. Los usuarios solo necesitan declarar un Debezium u otro formato de CDC, y el SQL en Flink no necesita percibir ningún CDC o atributos de upsert. Flink tiene una columna oculta incorporada para identificar sus datos de tipo CDC, por lo que es más conciso para los usuarios.
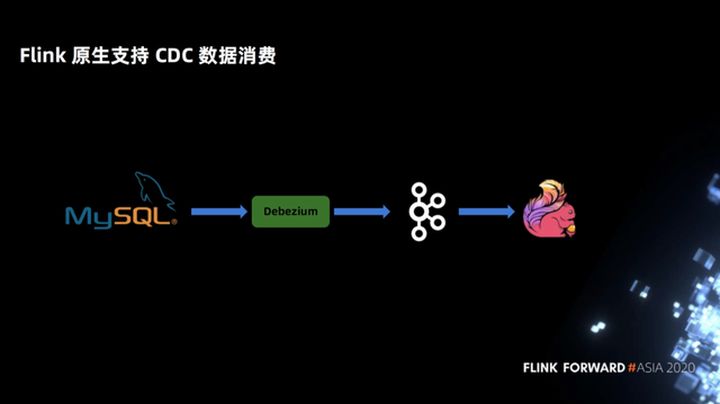
Como ejemplo en la siguiente figura, en el procesamiento de CDC, Flink solo declara una declaración DDL de MySQL Binlog, y la siguiente selección no necesita percibir el atributo CDC.

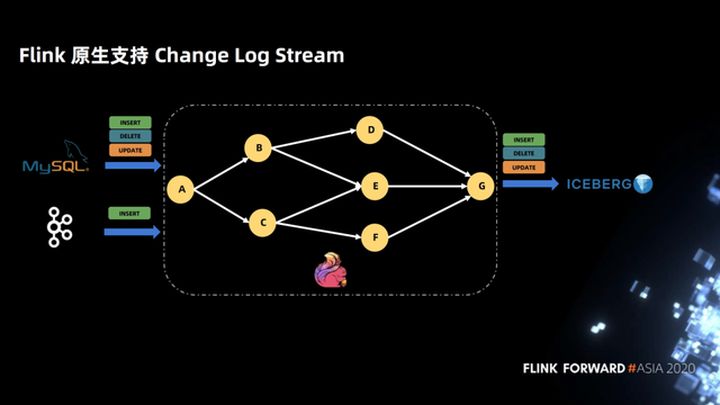
2.2 Soporte de Flink para Change Log Stream
La siguiente figura muestra que Flink admite de forma nativa Change Log Stream. Después de que Flink se conecta a un Change Log Stream, la topología no necesita preocuparse por el SQL de la marca Change Log. La topología está completamente definida de acuerdo con su propia lógica empresarial, y se escribe en Iceberg hasta el final, y no es necesario percibir el indicador de registro de cambios.
2.3 Evaluación del plan de importación de Flink + Iceberg CDC
Finalmente, ¿cuáles son las ventajas de la solución de importación CDC de Flink + Iceberg?
En comparación con el esquema anterior, Copiar al escribir y Combinar al leer tienen escenarios aplicables, con diferentes enfoques. Copy On Write es muy eficiente cuando solo es necesario reescribir una parte de los archivos en la escena de actualización de algunos archivos. Los datos generados son el conjunto de datos completo de pure append, que también es el más rápido cuando se usa para el análisis de datos. la ventaja de Copy On Write.
El otro es Merge On Read, es decir, los datos y la marca CDC se adjuntan directamente a Iceberg. Durante la fusión, los datos incrementales se combinan con la cantidad total de los datos anteriores en un determinado formato organizativo y un determinado método de cálculo eficiente. . La ventaja de esto es que admite la importación casi en tiempo real y la lectura de datos en tiempo real; Flink SQL de esta solución informática admite de forma nativa la entrada de CDC y no se requiere un diseño de campo comercial adicional.
Iceberg es un almacenamiento de lago de datos unificado, admite modelos informáticos diversificados y también admite varios motores (incluidos Spark, Presto, hive) para el análisis; los archivos generados son almacenamiento de columna puro, que es muy rápido para el análisis posterior; Iceberg es una instantánea- diseño basado en el lago de datos y admite lectura incremental; la arquitectura Iceberg es lo suficientemente simple, sin nodos de servicio en línea, formato de tabla puro, lo que brinda a la plataforma ascendente la capacidad suficiente para personalizar su propia lógica y servicio.

Tres, cómo escribir y leer en tiempo real.
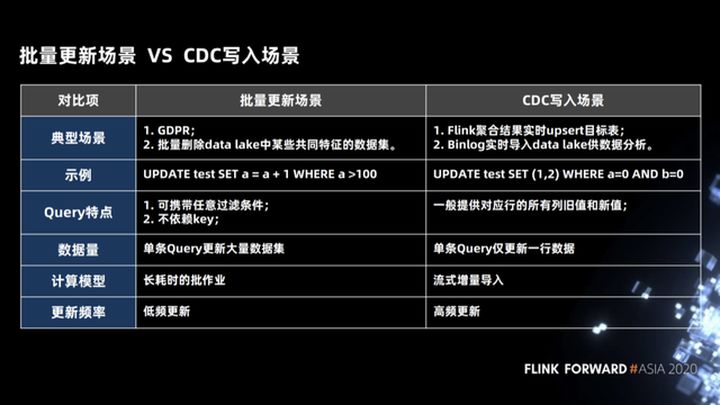
3.1 Escenas de actualización por lotes y escenas de escritura CDC
Primero, echemos un vistazo a dos escenarios para actualizaciones por lotes en todo el lago de datos.
- Este es el primer escenario de actualización por lotes. En este escenario, usamos un SQL para actualizar miles de filas de datos, como la política europea GDPR. Cuando un usuario cierra sesión en su cuenta, el sistema de back-end debe cambiar todos los datos relacionados del usuario se elimina físicamente.
- El segundo escenario es que necesitamos eliminar algunos datos con características comunes en el lago de datos. Este escenario también es un escenario de actualización por lotes. En este escenario, las condiciones de eliminación pueden ser condiciones arbitrarias y no hay una clave principal (clave principal Independientemente de cualquier relación, al mismo tiempo, el conjunto de datos a actualizar es muy grande. Este tipo de trabajo es un trabajo de baja frecuencia y que consume mucho tiempo.
El otro es el escenario escrito por los CDC. Para Flink, hay dos escenarios de uso común. El primer escenario es que Binlog ascendente se puede escribir rápidamente en el lago de datos y luego ser utilizado por diferentes motores de análisis para el análisis; el segundo escenario es para utilice Flink para realizar algunas operaciones de agregación. El flujo de salida es un flujo de datos de tipo upsert, y también debe poder escribir en el lago de datos o en el sistema aguas abajo para su análisis en tiempo real. Como se muestra en el ejemplo de la siguiente figura, el CDC escribe la declaración SQL en la escena. Usamos un solo SQL para actualizar una fila de datos. Este modo de cálculo es una importación incremental de transmisión y es una actualización de alta frecuencia.
3.2 Problemas que Apache Iceberg debe considerar al diseñar una solución de escritura CDC
A continuación, echemos un vistazo a los problemas que Iceberg debe considerar al diseñar el escenario para la redacción de CDC.
- La primera es la corrección, es decir, se debe garantizar la exactitud de la semántica y de los datos. Por ejemplo, los datos ascendentes se insertan en el iceberg. Cuando el upsert se detiene, los datos del iceberg deben ser coherentes con los datos del sistema ascendente.
- La segunda es la escritura eficiente. Debido a que la frecuencia de escritura de upsert es muy alta, necesitamos mantener un alto rendimiento y una alta escritura simultánea.
- El tercero es la lectura rápida. Cuando se escriben los datos, necesitamos analizar los datos. Esto implica dos problemas. El primer problema es la necesidad de admitir la simultaneidad detallada. Cuando el trabajo utiliza varias tareas para leer, puede asegurarse de que cada tarea se asigna de forma equilibrada para acelerar el cálculo de los datos; el segundo problema es que debemos aprovechar al máximo las ventajas del almacenamiento en columnas para acelerar la lectura.
- El cuarto es admitir la lectura incremental, como ETL en algunos almacenes de datos tradicionales, mediante la lectura incremental para una mayor conversión de datos.

3.3 Apache Iceberg Basic
Antes de presentar los detalles específicos del programa, primero comprendamos el diseño de Iceberg en el sistema de archivos. En términos generales, Iceberg se divide en dos partes de datos. La primera parte es el archivo de datos. El archivo de parquet en la figura siguiente. Cada archivo de datos corresponde a una escuela Archivo de verificación (archivo .crc). La segunda parte es el archivo de metadatos de la tabla (archivo de metadatos), incluido el archivo de instantánea ( snap- .avro), el archivo de manifiesto ( .avro), el archivo de metadatos de tabla (* .json), etc.

La siguiente figura muestra la correspondencia entre instantáneas, manifiestos y archivos de partición en iceberg. La siguiente figura contiene tres particiones: la primera partición tiene dos archivos f1 y f3, la segunda partición tiene dos archivos f4 y f5 y la tercera partición tiene un archivo f2. Para cada escritura, se genera un archivo de manifiesto, que registra la correspondencia entre el archivo escrito esta vez y la partición. Existe el concepto de instantánea en el nivel superior. Instantánea puede ayudar a acceder rápidamente a la cantidad total de datos de toda la tabla. Instantánea registra múltiples manifiestos. Por ejemplo, la segunda instantánea contiene manifest2 y manifest3.

3.4 INSERTAR, ACTUALIZAR, ELIMINAR escritura
Después de comprender los conceptos básicos, a continuación se presenta el diseño de las operaciones de inserción, actualización y eliminación en iceberg.
La tabla que se muestra en el ejemplo de SQL en la figura siguiente contiene dos campos, id y data, ambos de tipo int. En una transacción, realizamos la operación de flujo de datos que se muestra en la figura. Primero, se insertó un registro (1, 2) y luego este registro se actualizó a (1, 3). En iceberg, la operación de actualización se dividirá en eliminar E insertar dos operaciones.
La razón de esto es que si se considera a iceberg como una capa de almacenamiento unificada para la transmisión de lotes, el desarmado de la operación de actualización en operaciones de eliminación e inserción puede garantizar la unificación de la ruta de lectura cuando se actualiza la escena de transmisión por lotes. Por ejemplo, en el escenario de eliminación de lotes , Hive se usa como Por ejemplo, Hive escribirá el desplazamiento del archivo de la fila que se eliminará en el archivo delta y luego hará una fusión al leer, porque esto será más rápido. Cuando se realiza la fusión, el archivo original y el delta se mapeará a través de la posición y se obtendrá rápidamente Todos los registros excepto los eliminados.
Luego inserte el registro (3, 5), borre el registro (1, 3), inserte el registro (2, 5), la consulta final es que obtenemos el registro (3, 5) (2, 5).
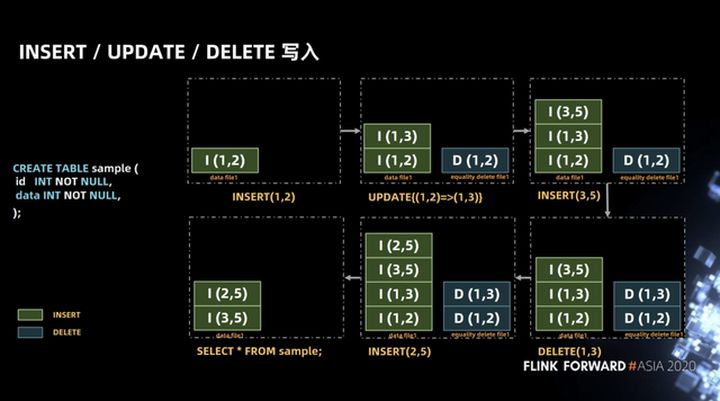
La operación anterior parece muy simple, pero hay algunos problemas semánticos en la implementación. Como se muestra en la figura a continuación, en una transacción, la operación de insertar el registro (1, 2) se realiza primero. Esta operación escribirá INSERT (1, 2) en el archivo de datos file1, y luego realizará la operación de borrar el registro (1, 2). Esta operación escribirá DELETE (1, 2) en ecualizar eliminar archivo1, y luego realizará la operación de inserción de registro (1, 2), que escribirá INSERT (1, 2) en el archivo de datos archivo1, y luego realice la operación de consulta.
En circunstancias normales, el resultado de la consulta debe devolver el registro INSERT (1, 2), pero en la implementación, la operación DELETE (1, 2) no puede saber qué fila en el archivo de datos archivo1 se elimina, por lo que las dos filas de INSERT (1 , 2)) Se eliminarán todos los registros.

Entonces, cómo resolver este problema, la forma actual en la comunidad es adoptar Posición mixta-eliminar e igualdad-eliminar. Equality-delete es eliminar especificando una o más columnas, y position-delete es eliminar según la ruta del archivo y el número de línea.Los dos métodos se combinan para garantizar la corrección de la operación de eliminación.
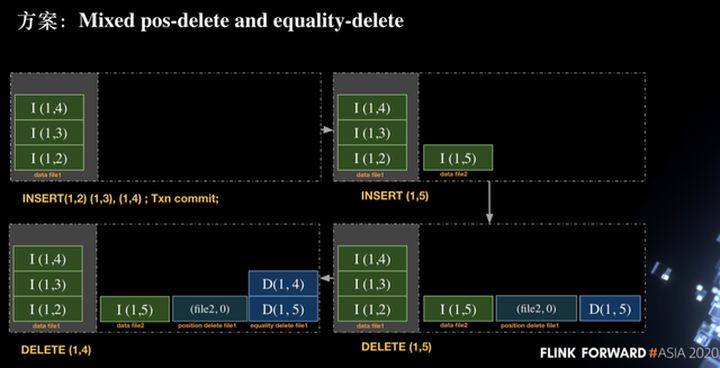
Como se muestra en la figura siguiente, hemos insertado tres filas de registros en la primera transacción, a saber, INSERT (1, 2), INSERT (1, 3), INSERT (1, 4), y luego ejecutamos la operación de confirmación para enviar. A continuación, iniciamos una nueva transacción y ejecutamos insertando una fila de datos (1, 5). Debido a que es una nueva transacción, creamos un nuevo archivo de datos2 y escribimos el registro INSERT (1, 5), y luego ejecutamos el registro de eliminación. (1, 5) Cuando se escribe eliminar, es:
Escriba (archivo2, 0) en la posición eliminar archivo1 archivo, lo que significa eliminar el registro de la fila 0 en el archivo de datos 2. Esto es para resolver el problema semántico de la inserción y eliminación repetidas de la misma fila de datos en la misma transacción.
Escriba DELETE (1,5) en el archivo de eliminación de igualdad file1.La razón para escribir esta eliminación es para asegurarse de que el (1,5) escrito antes de este txn se pueda eliminar correctamente.
Luego, realice la operación de eliminación (1, 4). Dado que (1, 4) no se ha insertado en la transacción actual, esta operación utilizará la operación de eliminación de igualdad, es decir, escribir el registro (1, 4) en la igualdad eliminar archivo 1. En el proceso anterior, se puede ver que hay tres tipos de archivos: archivo de datos, archivo de eliminación de posición y archivo de eliminación de igualdad en la solución actual.
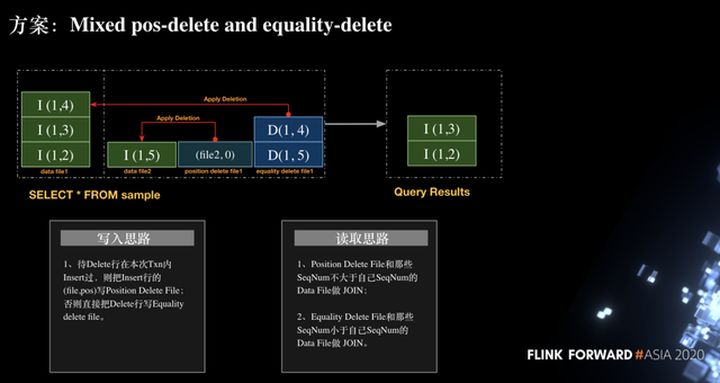
Después de comprender el proceso de escritura, cómo leerlo. Como se muestra en la figura siguiente, para el registro (archivo2, 0) en el archivo de eliminación de posición, solo es necesario unir el archivo de datos de la transacción actual, y el registro del archivo de eliminación de igualdad (1, 4) y los datos se unen los archivos de la transacción anterior. Finalmente, se obtienen los registros INSERT (1, 3) e INSERT (1, 2) para asegurar la corrección del proceso.
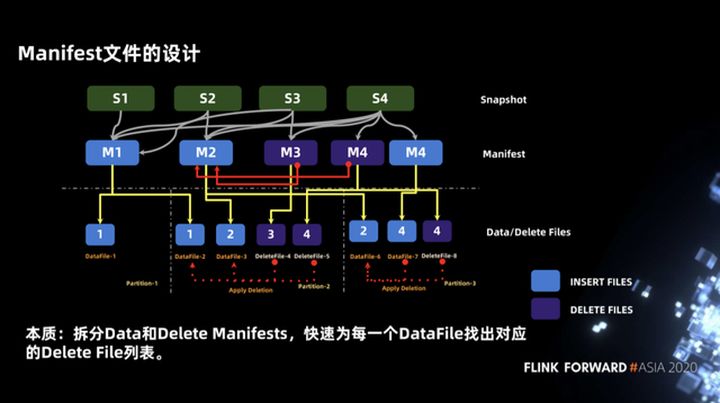
3.5 Diseño de archivo de manifiesto
La inserción, actualización y eliminación se introdujeron anteriormente, pero al diseñar el plan de ejecución de la tarea, hemos diseñado algunos manifiestos. El propósito es encontrar rápidamente el archivo de datos a través del manifiesto y dividirlo según el tamaño de los datos para asegurar Distribuya los datos procesados por cada tarea de la manera más uniforme posible.
El ejemplo que se muestra en la figura siguiente contiene cuatro transacciones. Las dos primeras transacciones son operaciones INSERT, correspondientes a M1 y M2, la tercera transacción es la operación DELETE, correspondiente a M3, y la cuarta transacción es una operación UPDATE, que incluye dos archivos de manifiesto, a saber, manifiesto de datos y manifiesto de eliminación.
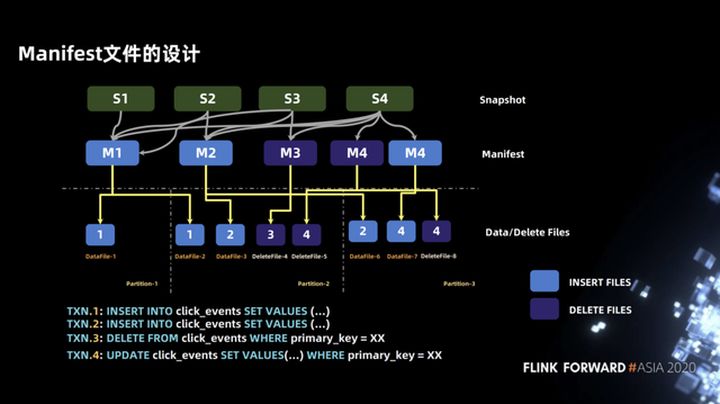
En cuanto a por qué el archivo de manifiesto se divide en manifiesto de datos y manifiesto de eliminación, se trata esencialmente de encontrar rápidamente la lista de archivos de eliminación correspondiente para cada archivo de datos. Puede ver el ejemplo en la figura siguiente. Cuando leemos en la partición-2, necesitamos realizar una operación de unión entre deletefile-4 y datafile-2 y datafile-3, y también necesitamos combinar deletefile-5 con datafile- 2 y archivo de datos 3. Realice una operación de unión.
Tome datafile-3 como ejemplo. La lista de deletefile contiene dos archivos, deletefile-4 y deletefile-5. ¿Cómo encontrar rápidamente la lista de deletefile correspondiente? Podemos consultar de acuerdo con el manifiesto de nivel superior. Cuando dividimos el archivo de manifiesto en manifiesto de datos Después de que el manifiesto de eliminación y M2 (manifiesto de datos) se puedan unir con M3 y M4 (manifiesto de eliminación) primero, la lista de archivos de eliminación correspondiente al archivo de datos se puede obtener rápidamente.
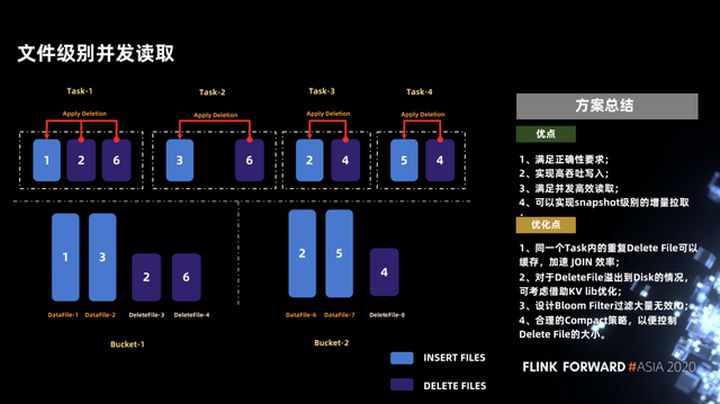
3.6 Simultaneidad a nivel de archivo
Otro problema es que necesitamos asegurar lecturas concurrentes suficientemente altas, lo cual se hace muy bien en iceberg. La lectura simultánea a nivel de archivo se puede lograr en iceberg, e incluso una lectura simultánea más detallada de los segmentos de un archivo. Por ejemplo, un archivo de 256 MB se puede dividir en dos de 128 MB para la lectura simultánea. A continuación, se muestra un ejemplo: suponga que el archivo de inserción y el archivo de eliminación están distribuidos en dos depósitos, como se muestra en la figura siguiente.

A través de la comparación del manifiesto, encontramos que la lista de eliminación de archivos de datafile-2 solo tiene deletefile-4, por lo que estos dos archivos se pueden ejecutar como una sola tarea (Tarea-2 en la figura), y otros archivos son similares , para garantizar que los datos de cada tarea se fusionen de forma equilibrada.

Hemos realizado un breve resumen de este esquema, como se muestra en la figura siguiente. En primer lugar, las ventajas de este esquema pueden cumplir con la corrección y pueden lograr una escritura de alto rendimiento y una lectura simultánea y eficiente. Además, puede lograr una extracción incremental a nivel de instantánea.
El esquema actual todavía es relativamente aproximado y hay algunos puntos que se pueden optimizar a continuación.
- El primer punto es que si el archivo de eliminación en la misma tarea está duplicado, se puede almacenar en caché, lo que puede mejorar la eficiencia de la unión.
- El segundo punto es que kv lib se puede utilizar para la optimización cuando el archivo de eliminación es relativamente grande y debe sobrescribirse en el disco, pero no depende de servicios externos u otros índices pesados.
- En tercer lugar, puede diseñar un filtro Bloom para filtrar E / S no válidas, porque la operación de inserción de uso común en Flink generará una operación de eliminación y una operación de inserción, lo que conducirá al tamaño del archivo de datos y el archivo de eliminación en iceberg La diferencia no es mucho, por lo que la eficiencia de unión no será muy alta. Si se usa el filtro Bloom, cuando llegan los datos de upsert, se dividen en operaciones de inserción y eliminación. Si el filtro de bloom filtra las operaciones de eliminación que no han insertado datos previamente (es decir, si estos datos no se han insertado antes, lo hace no es necesario eliminar los registros se escriben en el archivo de eliminación), lo que mejorará en gran medida la eficiencia de upsert.
- El cuarto punto es que se necesitan algunas estrategias de compactación de fondo para controlar el tamaño del archivo de eliminación. Cuando el archivo de eliminación es más pequeño, la eficiencia del análisis es mayor. Por supuesto, estas estrategias no afectarán la lectura y escritura normales.
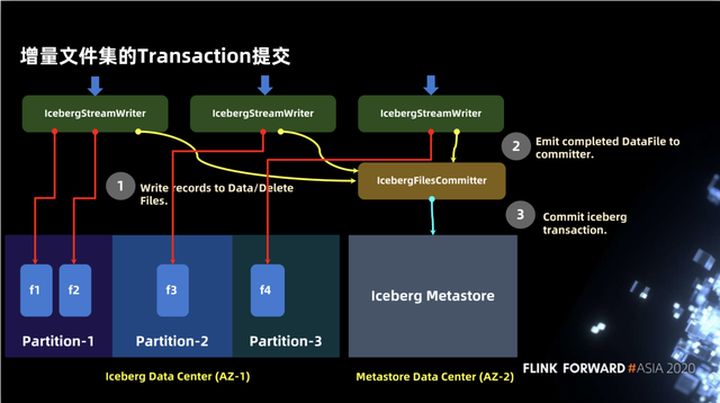
3.7 Envío de transacciones del conjunto de archivos incrementales
En la sección anterior, presentamos la escritura de archivos En la siguiente figura, presentamos cómo escribir de acuerdo con la semántica de iceberg y ponerlo a disposición de los usuarios. Se divide principalmente en dos partes: datos y metastore. Primero, habrá IcebergStreamWriter para escribir datos, pero en este momento la información de metadatos de los datos escritos no se escribe en la metastore, por lo que no es visible para el mundo exterior. El segundo operador es IcebergFileCommitter, que recopila archivos de datos y finalmente completa la escritura a través de la transacción de confirmación.
No hay otra dependencia de servicios de terceros en Iceberg, y Hudi ha realizado algunas abstracciones de servicios en algunos aspectos, como la abstracción de metastore en una línea de tiempo independiente, que puede depender de algunos índices independientes o incluso de otros servicios externos.
Cuatro, planificación futura
Los siguientes son algunos de nuestros planes futuros. El primero son algunas optimizaciones del kernel de Iceberg, incluida la prueba de estabilidad de enlace completa y la optimización del rendimiento involucradas en el plan, y proporciona algunas interfaces de API de tabla relacionadas para la extracción incremental de CDC.
En la integración de Flink, se realizará la capacidad de fusionar de forma automática y manual archivos de datos de datos de CDC, y proporcionará la capacidad de Flink para extraer datos de CDC de forma incremental.
En otra integración ecológica, integraremos Spark, Presto y otros motores, y usaremos Alluxio para acelerar la consulta de datos.

Este artículo es el contenido original de Alibaba Cloud y no se puede reproducir sin permiso.