Resumen: Este artículo es una compilación del intercambio del ingeniero de desarrollo senior de Alibaba Cloud, Zeng Qingdong (Xile), en el Streaming Lakehouse Meetup. El contenido se divide principalmente en cuatro partes:
- Introducción al esquema de implementación del análisis tradicional del almacén de datos
- Paimon+StarRocks crea una solución integrada de análisis de datos para lagos y almacenes
- Cómo usar e implementar la combinación de StarRocks y Paimon
- StarRocks Community Lake Warehouse Análisis Planificación futura
Haga clic para ver el video original y el discurso PPT
1. Introducción al esquema de implementación del análisis tradicional del almacén de datos
La implementación del análisis del almacén de datos tradicional es una arquitectura Lambda típica. En la figura siguiente, podemos ver que la arquitectura tradicional se divide principalmente en dos capas: la capa superior es la capa de enlace en tiempo real y la capa inferior es la fuera de línea. capa de enlace. Sus datos pasan a través de la capa de ingestión de datos de la izquierda y los integran en un middleware de cola de mensajes como Kafka a través de diferentes rutas, y luego los dividen en dos datos idénticos, que se dividen en enlaces en tiempo real y enlaces por lotes, respectivamente. Se procesa y finalmente se agrega a la capa de servicio de datos para lograr la capacidad de proporcionar servicios de análisis de datos a los usuarios.
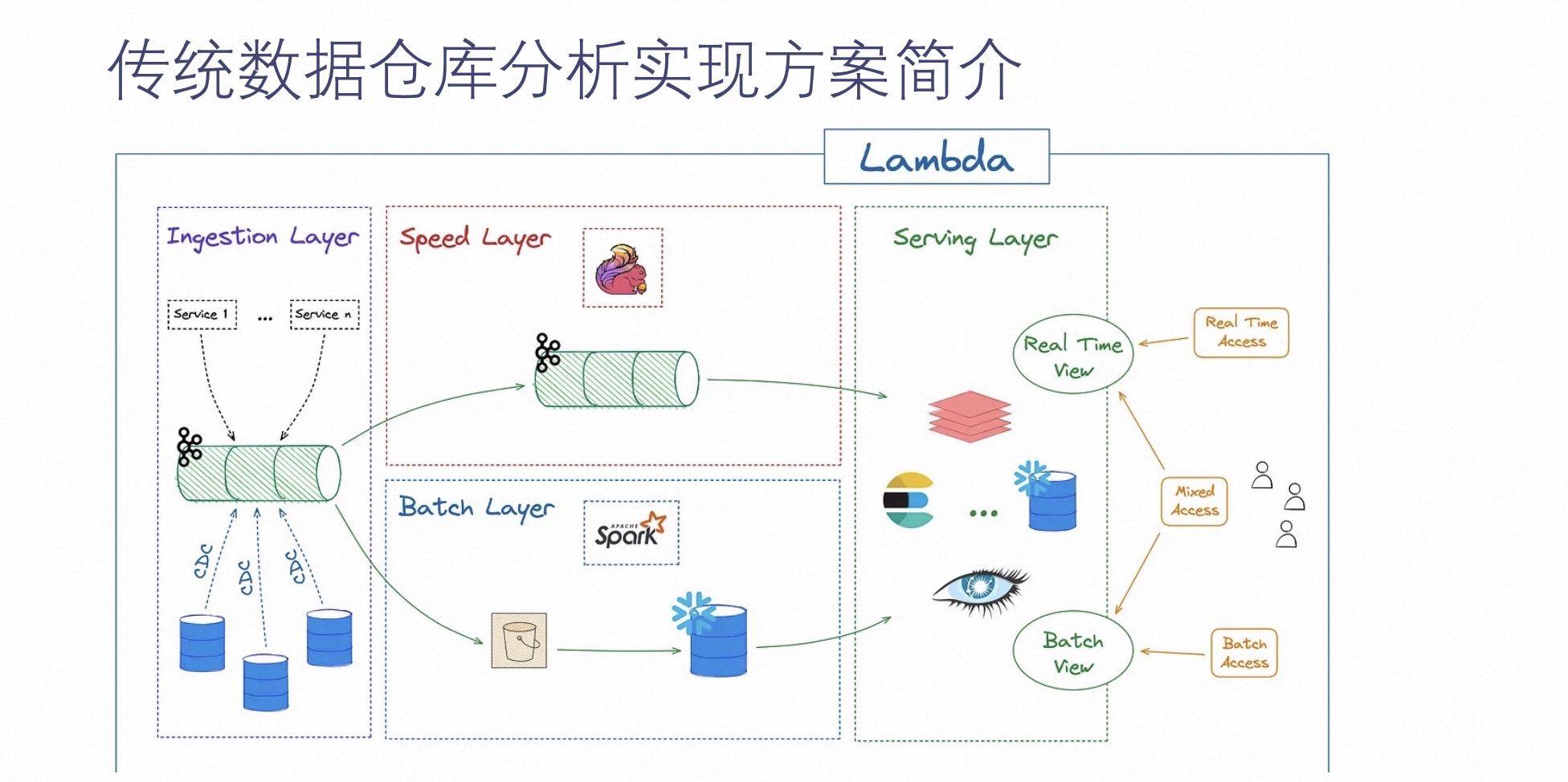
El surgimiento de la arquitectura Lambda se debe principalmente al surgimiento de la demanda de análisis en tiempo real por parte de los usuarios y a la madurez gradual de la tecnología de procesamiento de flujo. Pero también tiene algunas desventajas obvias: como se muestra en la figura anterior, necesita mantener dos sistemas, lo que provocará mayores costos de implementación y mano de obra. Cuando el negocio cambia, los dos sistemas también deben modificarse para adaptarse a los cambios comerciales.
Con la madurez gradual de la tecnología de procesamiento de flujo, la arquitectura Kappa se introdujo después de la arquitectura Lambda, como se muestra en la siguiente figura.
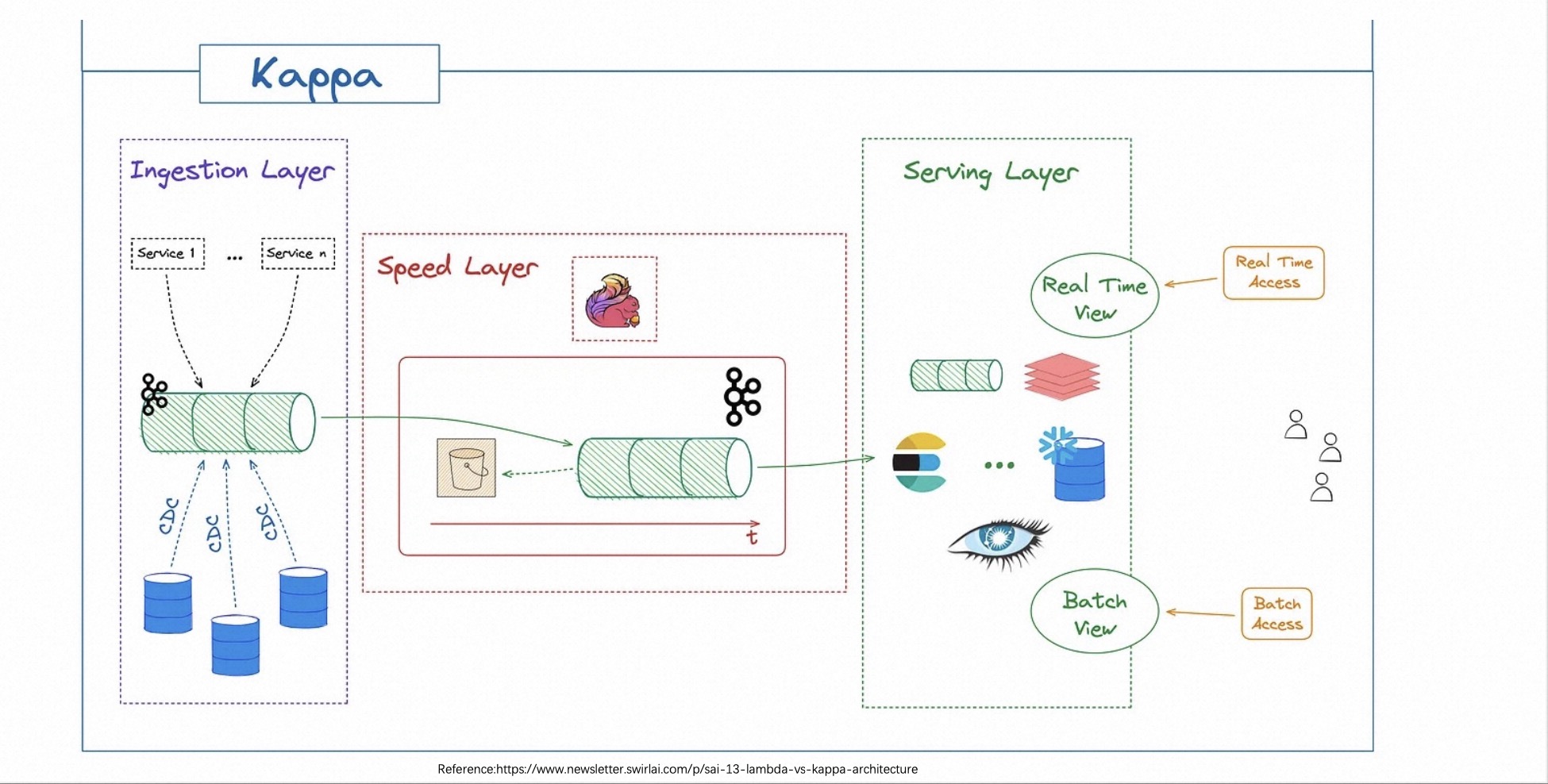
La arquitectura Kappa utiliza enlaces de procesamiento de flujo para reemplazar la arquitectura Lambda original. Debido a la madurez del procesamiento de flujo, es posible completar cálculos en tiempo real y fuera de línea a través de un conjunto de sistemas.
La arquitectura Kappa tiene una premisa: cree que el doble cálculo de datos históricos es innecesario a menos que sea necesario. Esto hace que a menudo sea necesario reproducir todo el proceso de ingesta de datos una vez cuando los usuarios necesitan volver a calcular los datos históricos o se producen nuevos cambios comerciales. En el caso del consumo masivo de datos históricos, inevitablemente provocará un desperdicio de recursos y encontrará algunos cuellos de botella.
2. Paimon+StarRocks crea una solución integrada de análisis de datos para lagos y almacenes
2.1 Centro de lago de datos
La primera solución es una solución de centro de lago de datos para que Paimon y StarRocks creen un análisis de datos integrado del lago y el almacén.
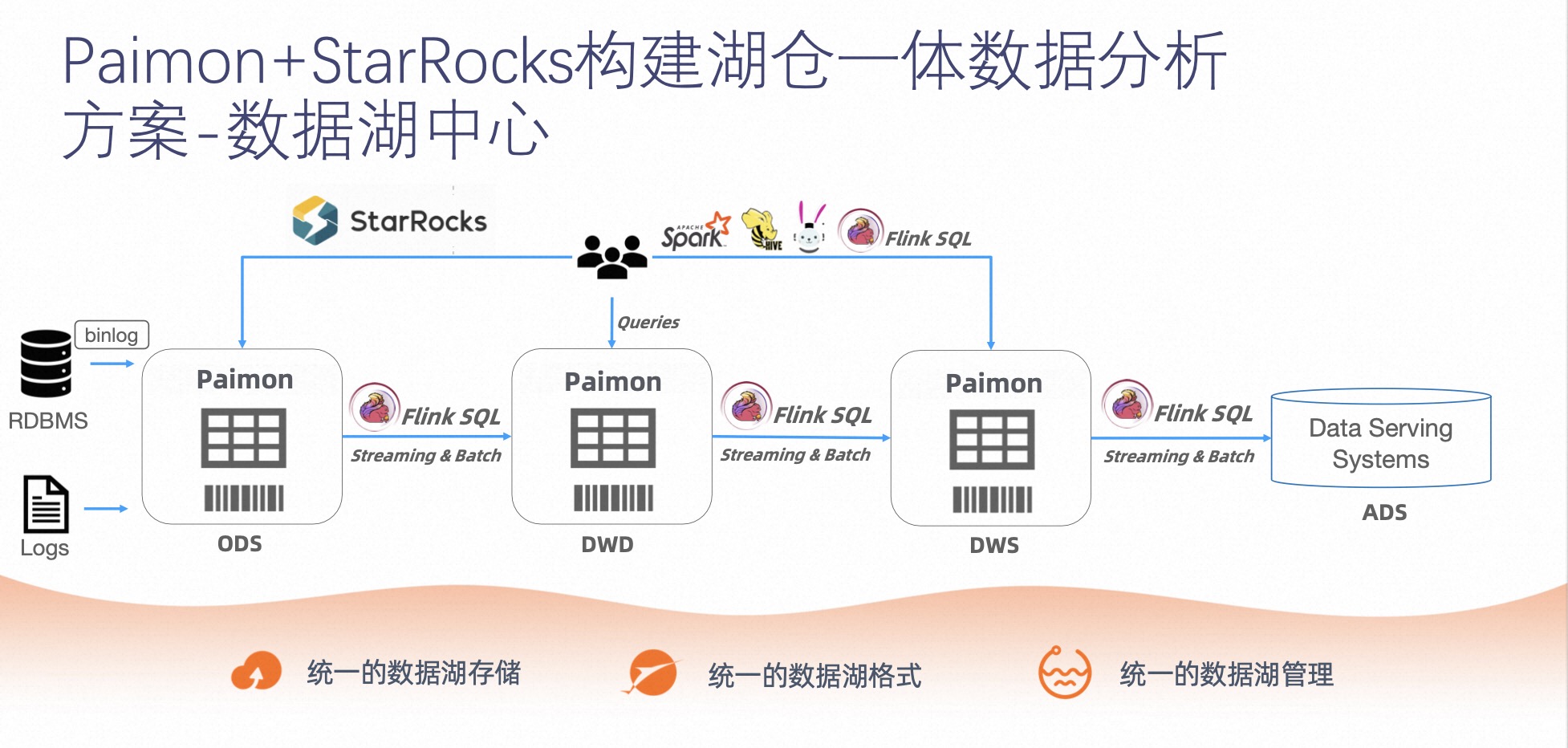
StarRocks en sí es una base de datos MPP y, al mismo tiempo, se puede conectar a componentes del lago de datos en varios formatos y se puede utilizar simplemente como un motor de consulta para conectarse a los componentes del lago de datos para realizar funciones de consulta. Como se muestra en la figura anterior, los componentes de Paimon de la capa de datos, como ODS, se pueden consultar a través de StarRocks o Spark.
En esta arquitectura, Paimon compensa las deficiencias del middleware de cola de mensajes en la arquitectura Kappa presentada anteriormente en términos de modificación de datos, seguimiento y consulta mediante la colocación e indexación de datos, lo que hace que esta arquitectura sea más tolerante a fallas y admita una gama más amplia. gama de capacidades. Al mismo tiempo, en términos de procesamiento por lotes, Paimon también es totalmente compatible con las capacidades de HIVE.
2.2 Consulta acelerada
La segunda solución es una solución de consulta acelerada para que Paimon y StarRocks creen análisis de datos integrados de lagos y almacenes.
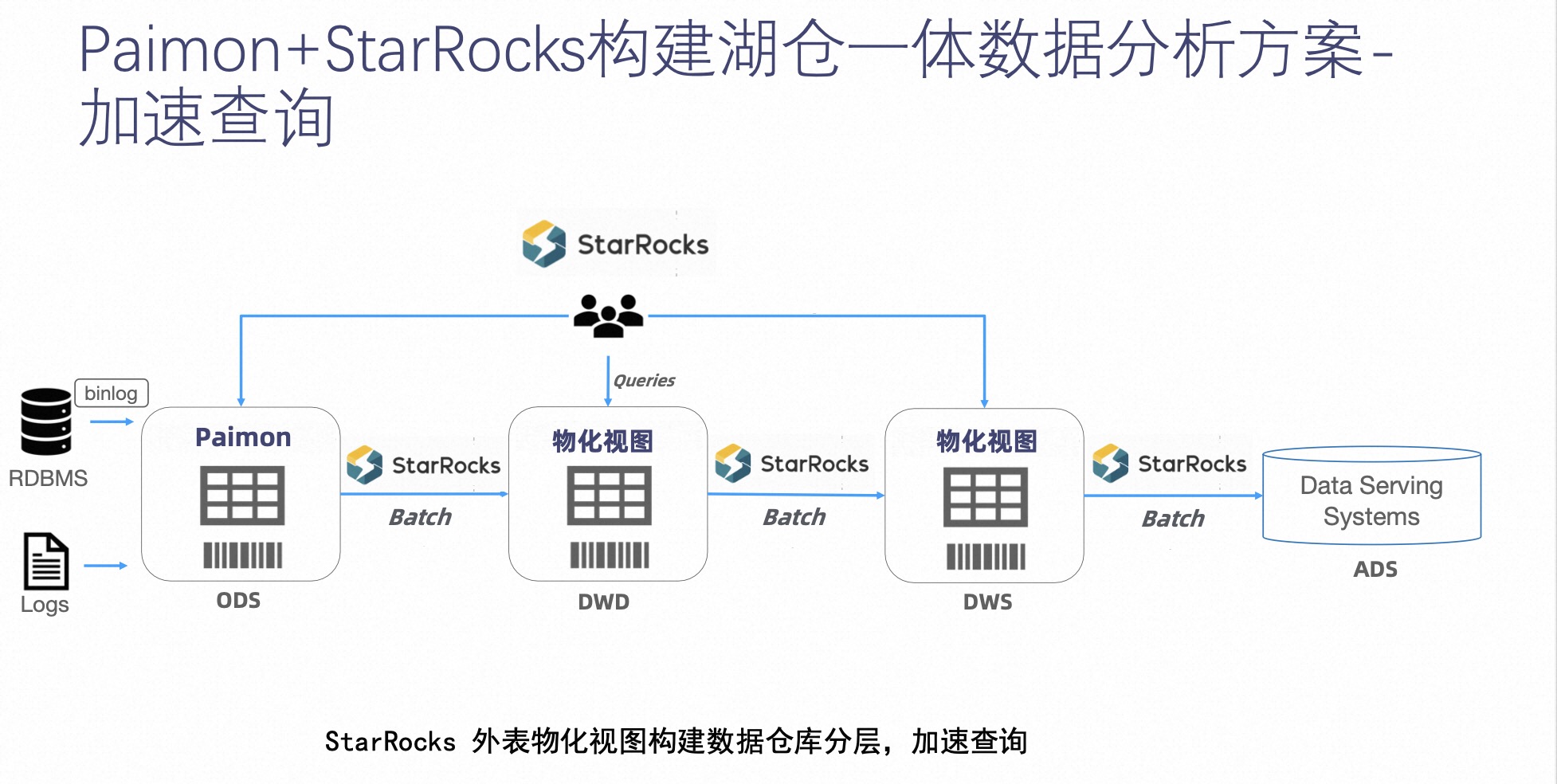
Se diferencia de la primera solución en que casi todo el sistema lo completa StarRocks únicamente. Después de que los datos se conectan a Paimon y se utilizan como capa ODS, los datos de Paimon se leen a través de las características de apariencia de StarRocks y se establece una vista materializada como capa DWD.
La vista materializada de StarRocks tiene ciertas capacidades ETL: después de usarse como capa DWD, se usa como capa DWS a través de la segunda capa de vista materializada anidada y finalmente se proporciona a la capa de servicio de datos para el análisis de datos.
Las dos ventajas de utilizar este sistema de StarRocks para cooperar con la arquitectura de Paimon son:
- Simplifica la operación y el mantenimiento porque no necesita mantener varios componentes y solo necesita StarRocks y Paimon para completar la construcción de la solución de análisis de datos;
- La velocidad de consulta es rápida, porque StarRocks es un motor de lago de datos con un sistema autónomo de creación de índices, almacenamiento de datos y optimización de consultas, por lo que es más rápido que los otros motores de consulta presentados anteriormente.
2.3 Vista materializada

El SQL en el lado derecho de la figura anterior describe cómo construir una vista materializada asincrónica de StarRocks. Tiene principalmente las siguientes características:
- A través de la definición SQL, es fácil de usar y mantener;
- El cálculo previo reduce la latencia de las consultas y la sobrecarga de cálculo doble;
- Enrutamiento automático de consultas, sin necesidad de reescribir SQL, aceleración transparente;
- Admite actualización automática asíncrona de datos, actualización programada y actualización inteligente por partición;
- Admite la construcción de varias mesas, la mesa base puede provenir de una mesa interior, una mesa exterior y una vista materializada existente.
2.4 Separación de frío y calor
Esta es la característica de separación de frío y calor a través de Paimon + StarRocks.
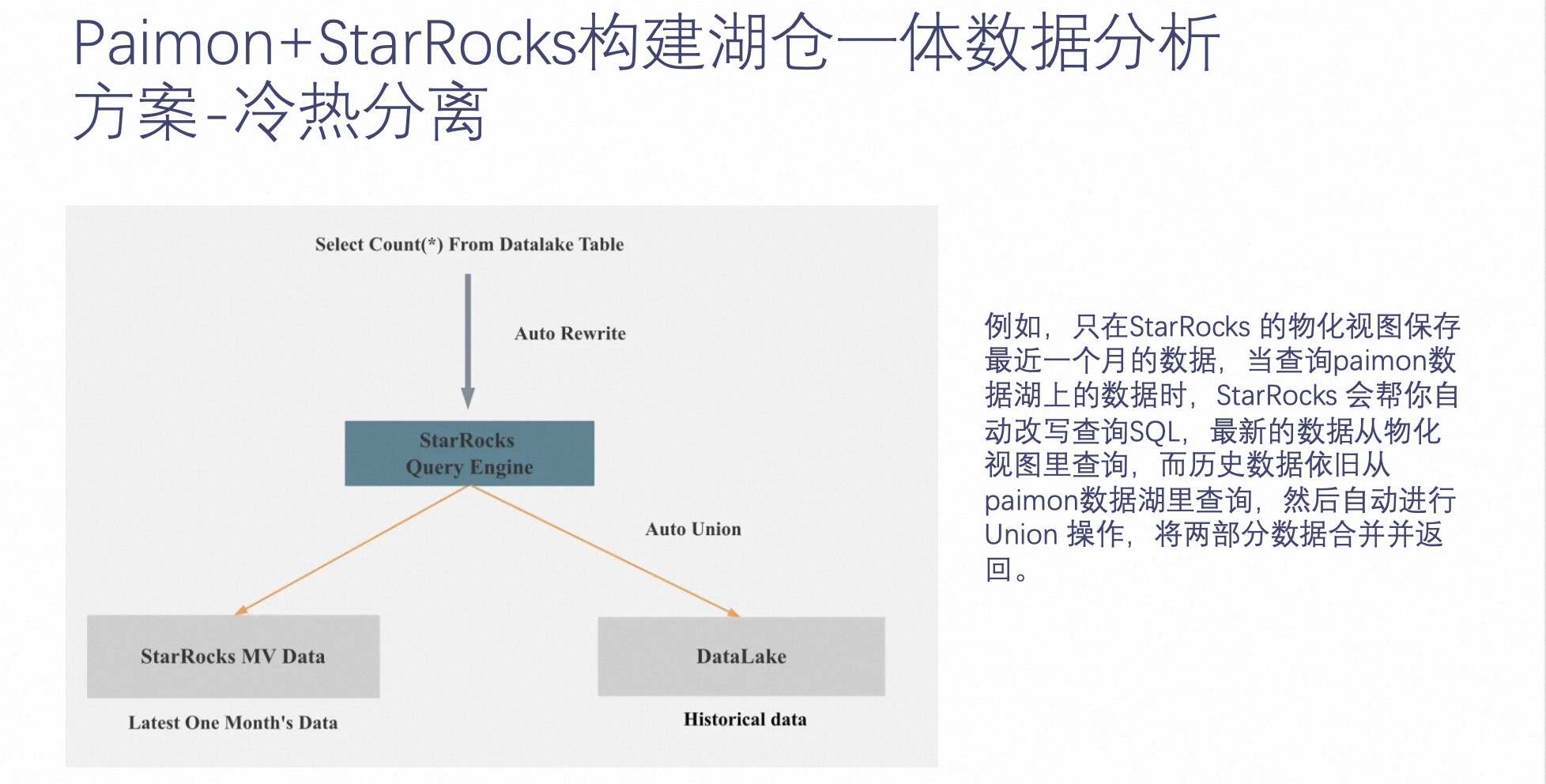
El concepto de separación en frío y en caliente es almacenar datos activos consultados con frecuencia en un motor OLAP como StarRocks con consultas rápidas y almacenar datos fríos consultados con poca frecuencia en componentes de almacenamiento de archivos remotos relativamente baratos, como OSS y HDFS.
Como se muestra en el ejemplo anterior de separación de frío y calor de Paimon + StarRocks, si se construye una tabla MV separada de frío y calor, cuando se consulta esta tabla, los datos calientes distribuidos en StarRocks y los datos fríos distribuidos en Paimon se seleccionarán automáticamente. Luego, los resultados de la consulta se combinan y se devuelven al usuario.
3. Cómo usar e implementar la combinación de StarRocks y Paimon
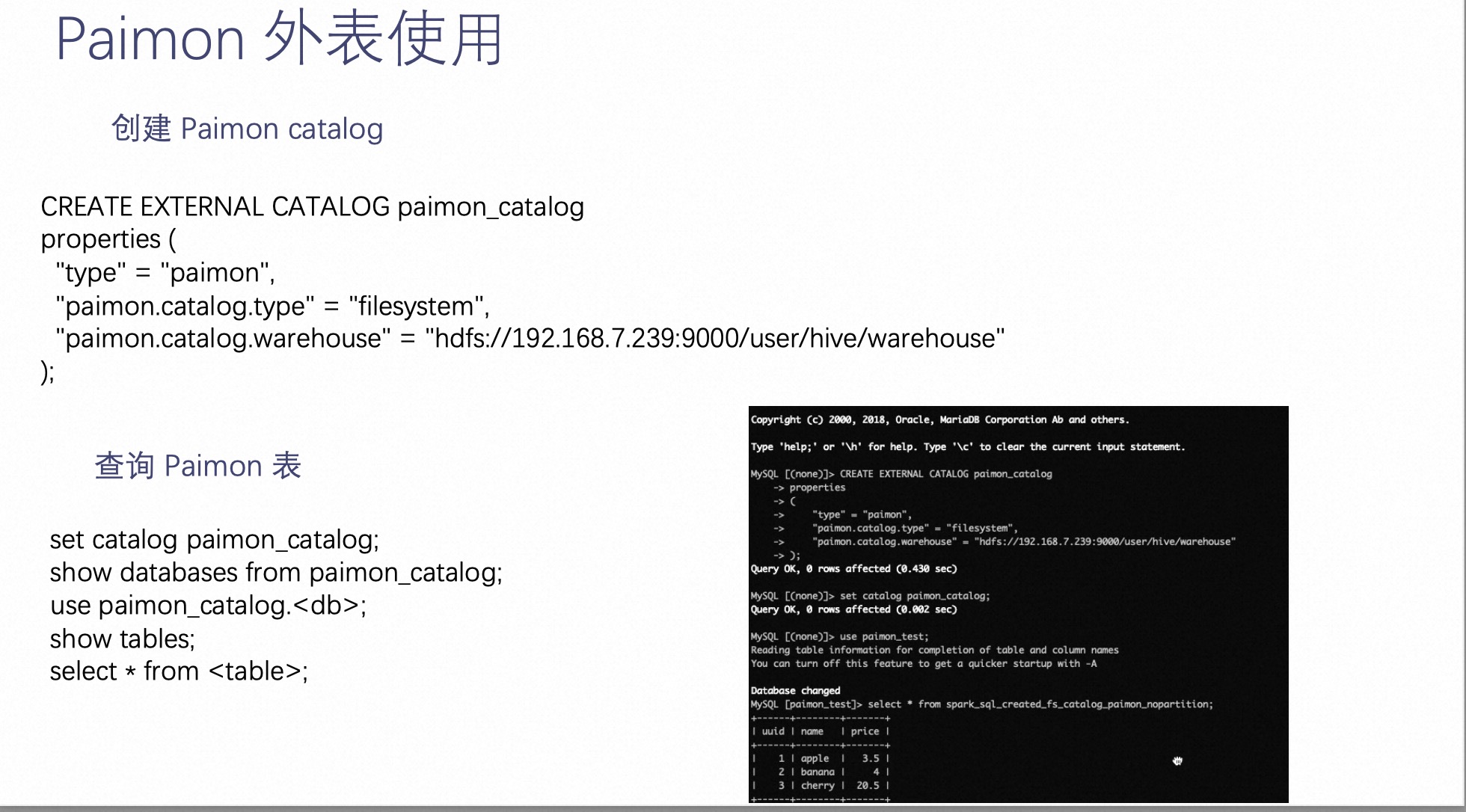
3.1 Uso de la apariencia de Paimon
Gracias a la abstracción del catálogo de apariencias de StarRocks, poco después del lanzamiento de Paimon, StarRocks se dio cuenta del soporte para la apariencia de Paimon implementando la interfaz correspondiente. Al conectarse al catálogo externo de Paimon, solo necesita ejecutar la siguiente instrucción Crear catálogo externo en StarRocks, especificar el Tipo como Paimon, completar la ruta correspondiente y luego podrá consultar directamente los datos en Paimon.
3.2 Conector JNI
JNI Connector es una característica más importante que hace la combinación de StarRocks y Paimon.
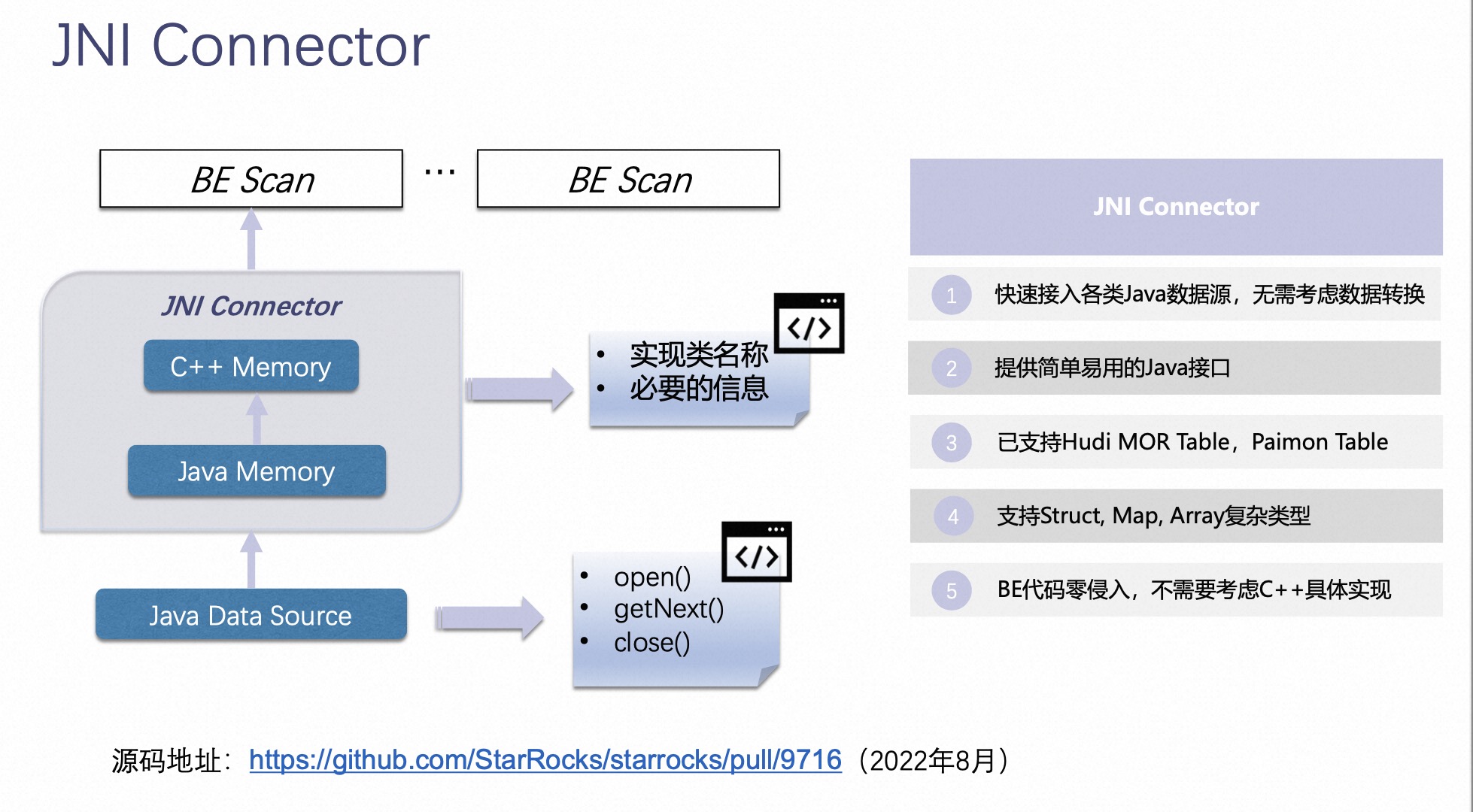
El trasfondo de JNI Connector es que los componentes de procesamiento de datos de StarRocks están escritos en programas C ++, pero la mayoría de los SDK proporcionados por los componentes del lago de datos son Java y no existe un SDK de C ++. Si StarRocks quiere acceder a los datos subyacentes del componentes del lago de datos a través de BE, solo puede acceder a su ORC/Parquet nativo y otros formatos, pero no puede aplicar las funciones avanzadas proporcionadas por estos componentes.
JNI Connector es un conector abstracto aplicable a todos los SDK de Java externos. Se utiliza en el componente BE de StarRocks y es una capa intermedia entre BE y el SDK de Java del componente del lago de datos.
La función principal de JNI Connector es llamar al SDK de Java del componente del lago de datos para leer los datos del lago de datos y luego escribir los datos leídos en una memoria fuera del montón en una disposición de memoria que el BE de StarRocks pueda reconocer, y luego escribe esto La memoria se entrega al programa BE C ++ para que se ejecute, de modo que pueda vincular BE y Java SDK.
El conector JNI tiene las siguientes características:
- Acceda rápidamente a varias fuentes de datos Java sin considerar la conversión de datos;
- Proporciona una interfaz Java fácil de usar;
- Ya es compatible con la Mesa Hudi MOR, la Mesa Paimon;
- Admite tipos complejos de estructura, mapa y matriz;
- El código BE tiene cero intrusiones y no necesita considerar la implementación específica de C++.
La siguiente figura es una introducción a algunos detalles del conector JNI.

El de arriba es el formato de almacenamiento de campos de longitud fija y el de abajo es el formato de almacenamiento de campos de longitud variable.
-
Formato de almacenamiento de campo de longitud fija
- La primera parte es la definición de si cada fila de datos de esta columna es nula.
- La segunda parte es la parte de datos, donde se almacenan datos específicos de longitud fija.
-
Formato de almacenamiento de campo de longitud variable
- La primera parte es una matriz que indica si cada fila de esta columna es nula;
- La segunda parte es describir la dirección inicial de cada fila de datos en la tercera parte de los datos específicos para comenzar a leer;
- La tercera parte son datos específicos.
4. Planificación futura del análisis de Hucanang de la comunidad StarRocks
En la actualidad, StarRocks ya admite algunas funciones de Paimon y algunas aún no se han implementado. Entonces, los planes futuros para mejorar las características del análisis de la tabla Paimon son los siguientes:
-
Soporte para analizar tipos complejos
-
Estadísticas de la columna de soporte
-
Soporte para almacenamiento en caché de metadatos
-
Apoyar el viaje en el tiempo
-
Admite visualización materializada en streaming basada en la apariencia de Paimon
Preguntas y respuestas
P: ¿Cómo se pueden gestionar eficazmente las vistas materializadas?
R: Una vez creada la vista materializada, se puede actualizar y programar automáticamente, sin depender de componentes externos para activar la actualización. La capacidad de reescritura de consultas permite a los usuarios consultar solo la tabla base sin especificar una vista materializada. Estas dos características reducen muchos problemas de gestión. En cuanto a las dependencias entre vistas materializadas y tablas base, y entre vistas materializadas anidadas, EMR-Serverless-StarRocks lanzará una función de visualización web para la programación de tareas y dependencias de tablas.
P: ¿La solución de análisis de datos integrado del almacén del lago Paimon+StarRocks tiene planes específicos para la seguridad de los datos, como control de acceso, auditoría de datos, etc.?
R: En la actualidad, lo que he aprendido sobre los permisos de administración de datos de StarRocks se basa en la visualización, modificación y otros permisos basados en roles, y se otorgan diferentes permisos a diferentes roles. Además, existe una función de autenticación de componentes correspondiente para datos en OSS o HDFS.
P: En la arquitectura integrada del almacén del lago con StarRocks como cuerpo principal, después de leer los datos de Paimon, ¿se volverán a escribir en Paimon?
R: Después de que los datos de la capa ODS se leen de Paimon, fluirán hacia la vista materializada de StarRocks y luego una capa de vistas materializadas de StarRocks anidadas no se volverá a escribir en Paimon.