(T4 16G) El script de colaboración previo al entrenamiento del modelo se encuentra en la página principal de github. Consulte Finetuning_LLama_2_0_on_Colab_with_1_GPU.ipynb para obtener más detalles.
En el blog anterior, mencioné dos formas de mejorar el rendimiento del modelo previamente entrenado: recuperación-generación aumentada (RAG) o ajuste fino. Este blog analiza el ajuste del modelo.
Ajuste fino: este es el proceso de tomar un LLM previamente capacitado y entrenarlo aún más en un conjunto de datos específico más pequeño para que se ajuste a una tarea específica o mejore su desempeño. Con el ajuste fino, ajustamos los pesos del modelo en función de nuestros datos para satisfacer mejor las necesidades únicas de nuestra aplicación.
Desde la clasificación de modelos grandes de código abierto open_llm_leaderboard de Hugging Face, podemos ver que Llama 2 es un modelo base de alto rendimiento y su licencia es gratuita, por lo que se puede usar para modelos de lenguaje grandes con fines comerciales. Por lo tanto, este artículo toma Llama-2 ajuste del modelo como ejemplo.
Preentrenamiento de Llama-2
Entrenar un modelo de preentrenamiento similar a LlaMA 2 desde cero requiere una gran cantidad de datos y potencia informática, y el costo total estimado es de unos 100 millones de dólares estadounidenses, esto se debe a que muchas empresas y particulares no cuentan con esta condición económica, por lo que Es más fácil hacerlo: el ajuste fino sobre la base del modelo previamente entrenado de código abierto reduce en gran medida la demanda de conjuntos de datos y potencia informática, y también se puede lograr como individuo.
El script de colab previo al entrenamiento del modelo se encuentra en la página principal de github. Consulte Finetuning_LLama_2_0_on_Colab_with_1_GPU.ipynb para obtener más detalles.
Cuantización del modelo
Para que el modelo razone más rápido, es una buena opción cuantificar el modelo, y el ajuste fino de la cuantificación perceptiva puede mejorar el rendimiento del modelo cuantificado en el proceso de ajuste fino. Esta sección presenta primero la cuantificación de el modelo, y la siguiente sección presenta la cuantificación perceptiva de LlaMA-2.
Requisitos de memoria y disco
Dado que el modelo en el disco se carga completamente en la memoria y luego se ejecuta, el espacio requerido para la memoria es el mismo que el espacio en disco.
| Modelo | Modelo tamaño original | Tamaño de cuantificación de 4 bits. |
|---|---|---|
| 7b | 13GB | 3,9GB |
| 13b | 24GB | 7,8GB |
| 30B | 60GB | 19,5GB |
| 65b | 120GB | 38,5GB |
La cuantificación del modelo se basa en el proyecto Llama2.cpp en github. Puede realizar la cuantificación del modelo y el razonamiento eficiente. Las características oficiales de llama2.cpp se presentan a continuación:
- Implementación simple de C/C++ sin dependencias
- Ciudadano de primera clase del silicio de Apple: optimizado a través de los marcos ARM NEON, Accelerate y Metal
- Soporte AVX, AVX2 y AVX512 para arquitecturas x86
- Precisión mixta F16/F32
- Soporte de cuantificación de enteros de 2 bits, 3 bits, 4 bits, 5 bits, 6 bits y 8 bits
- Soporte de backend de GPU CUDA, Metal y OpenCL
Método cuantitativo
Hay muchos métodos de cuantificación, y el método de denominación sigue "q" + bits de cuantificación + variantes. Los métodos de cuantificación factibles y sus ejemplos de uso se enumeran a continuación según la biblioteca de modelos TheBloke en Huggingface.
- q2_k: cuantiza atención.wv y feed_forward.w2 con Q4_k, y cuantiza otros con Q2_K;
- q3_k_l: cuantiza atención.wv, atención.wo y feed_forward.w2 con Q5_k, y cuantiza otros con Q2_K;
- q3_k_m: cuantiza atención.wv, atención.wo y feed_forward.w2 con Q4_k, y cuantiza otros con Q2_K;
- q3_k_s: Cuantiza todos los tensores con Q3_K;
- q4_0: método de cuantificación original de 4 bits;
- q4_l: la precisión está entre q4_0 y q5_0, pero la velocidad de inferencia es más rápida que el modelo q5;
- q4_k_m: use Q6_K para cuantizar la primera mitad de los tensores atención.wv y feed_forward.w2, y use Q4_K para cuantizar los demás
- q4_k_s: usa Q4_K para cuantificar todos los tensores
- q5_0: mayor precisión, mayor uso de recursos, menor velocidad de inferencia;
- q5_1: en comparación con q5_0, puede tener mayor precisión, mayor uso de recursos y menor velocidad de inferencia;
- q5_k_m: use Q6_K para cuantizar la primera mitad de los tensores atención.wv y feed_forward.w2, y use Q5_K para cuantizar los demás
- q5_k_s: Cuantiza todos los tensores con Q5_K
- q6_k_s: usa Q8_K para cuantificar todos los tensores
- q8_0: Casi lo mismo que float16 de punto flotante de media precisión, el uso de recursos y la velocidad son muy lentos y no se recomienda para la mayoría de los usuarios, los significados
de los wv y wo anteriores son los siguientes. -2 modelo, se puede usar un modelo de lenguaje grande Cuarto: LlaMA-2 del modelo a la aplicación
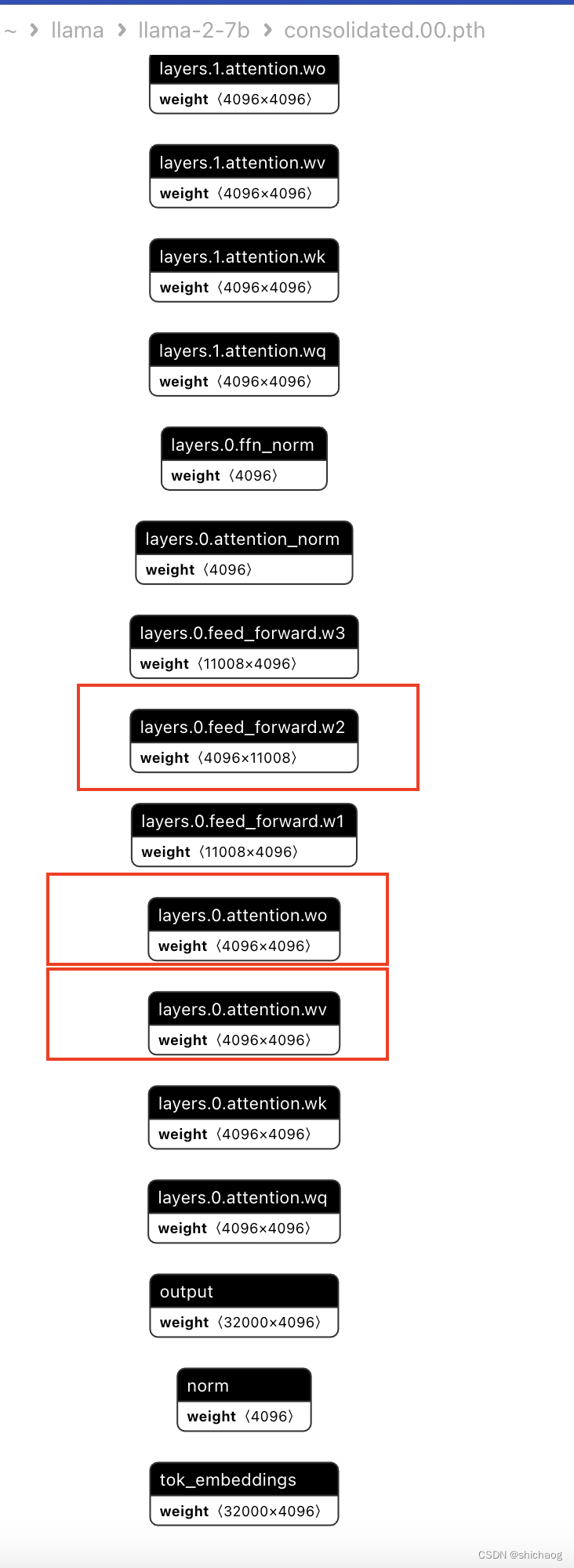
De muchas experiencias, Q5_K_M es un modelo con un buen equilibrio entre el rendimiento del modelo y el consumo de recursos. Si puede sacrificar aún más el rendimiento para reducir el consumo de recursos, puedes considerar Q4_K_M. En general, la cuantización de la versión K_M es mejor que la de la versión K_S. Las versiones cuantificadas de Q2_K y Q3_* no se recomiendan porque sacrifican más rendimiento.
| Modelo | Medida | F 16 | Q4_0 | Q4_1 | Q5_0 | Q5_1 | Q8_0 |
|---|---|---|---|---|---|---|---|
| 7b | perplejidad | 5.9066 | 6.1565 | 6.0912 | 5.9862 | 5.9481 | 5.9070 |
| 7b | tamaño del archivo | 13,0G | 3,5G | 3,9G | 4,3G | 4,7g | 6,7g |
| 7b | ms/tok @ 4to | 127 | 55 | 54 | 76 | 83 | 72 |
| 7b | ms/tok @ 8 | 122 | 43 | 45 | 52 | 56 | 67 |
| 7b | bits/peso | 16.0 | 4.5 | 5.0 | 5.5 | 6.0 | 8.5 |
| 13b | perplejidad | 5.2543 | 5.3860 | 5.3608 | 5.2856 | 5.2706 | 5.2548 |
| 13b | tamaño del archivo | 25,0G | 6,8G | 7,6G | 8,3G | 9,1G | 13G |
| 13b | ms/tok @ 4to | - | 103 | 105 | 148 | 160 | 131 |
| 13b | ms/tok @ 8 | - | 73 | 82 | 98 | 105 | 128 |
| 13b | bits/peso | 16.0 | 4.5 | 5.0 | 5.5 | 6.0 | 8.5 |
Evaluación de la calidad del modelo de perplejidad
El cálculo de perplejidad se basa en la probabilidad predicha del modelo de cada palabra en el conjunto de datos de prueba, tomando el logaritmo de estas probabilidades y tomando el promedio, y luego tomando el índice negativo del resultado para obtener el valor de perplejidad. . Cuanto menor sea el valor de Perplejidad, mejor será la capacidad predictiva del modelo en el conjunto de datos de prueba.
Las mediciones de perplejidad en la tabla anterior se realizan en el conjunto de datos de prueba wikitext2 con una longitud de contexto de 512. El tiempo por token se mide en una MacBook M1 Pro de 32 GB de RAM con 4 y 8 subprocesos.
# Variables
MODEL_ID = "mlabonne/EvolCodeLlama-7b"
QUANTIZATION_METHODS = ["q4_k_m"]
# Constants
MODEL_NAME = MODEL_ID.split('/')[-1]
GGML_VERSION = "gguf"
# Install llama.cpp
!git clone https://github.com/ggerganov/llama.cpp
!cd llama.cpp && git pull && make clean && LLAMA_CUBLAS=1 make
!pip install -r llama.cpp/requirements.txt
# Download model
!git lfs install
!git clone https://huggingface.co/{MODEL_ID}
# Convert to fp16
fp16 = f"{MODEL_NAME}/{MODEL_NAME.lower()}.{GGML_VERSION}.fp16.bin"
!python llama.cpp/convert.py {MODEL_NAME} --outtype f16 --outfile {fp16}
# Quantize the model for each method in the QUANTIZATION_METHODS list
for method in QUANTIZATION_METHODS:
qtype = f"{MODEL_NAME}/{MODEL_NAME.lower()}.{GGML_VERSION}.{method}.bin"
!./llama.cpp/quantize {fp16} {qtype} {method}
La salida del terminal es la siguiente:
Cloning into 'llama.cpp'...
remote: Enumerating objects: 7959, done.
remote: Counting objects: 100% (30/30), done.
remote: Compressing objects: 100% (22/22), done.
remote: Total 7959 (delta 11), reused 19 (delta 8), pack-reused 7929
Receiving objects: 100% (7959/7959), 7.71 MiB | 15.48 MiB/s, done.
Resolving deltas: 100% (5477/5477), done.
Already up to date.
I llama.cpp build info:
I UNAME_S: Linux
I UNAME_P: x86_64
I UNAME_M: x86_64
I CFLAGS: -I. -O3 -std=c11 -fPIC -DNDEBUG -Wall -Wextra -Wpedantic -Wcast-qual -Wdouble-promotion -Wshadow -Wstrict-prototypes -Wpointer-arith -Wmissing-prototypes -pthread -march=native -mtune=native -DGGML_USE_K_QUANTS
I CXXFLAGS: -I. -I./common -O3 -std=c++11 -fPIC -DNDEBUG -Wall -Wextra -Wpedantic -Wcast-qual -Wno-unused-function -Wno-multichar -pthread -march=native -mtune=native -DGGML_USE_K_QUANTS
I LDFLAGS:
I CC: cc (Ubuntu 11.4.0-1ubuntu1~22.04) 11.4.0
I CXX: g++ (Ubuntu 11.4.0-1ubuntu1~22.04) 11.4.0
Git LFS initialized.
Cloning into 'EvolCodeLlama-7b'...
remote: Enumerating objects: 35, done.
remote: Counting objects: 100% (32/32), done.
remote: Compressing objects: 100% (32/32), done.
remote: Total 35 (delta 8), reused 0 (delta 0), pack-reused 3
Unpacking objects: 100% (35/35), 483.46 KiB | 2.78 MiB/s, done.
- Gguf
GGUF es un formato de archivo para almacenar modelos propuestos para el razonamiento GGML. GGUF es un formato de archivo binario para cargar, guardar y leer modelos rápidamente. Por lo general, los modelos entrenados por Pytorch u otros marcos deben exportarse al formato GGUF y luego razonarse con GGML. En uso, GGUF es el sucesor de GGML, GGMF y GGJT.
enum ggml_type {
GGML_TYPE_F32 = 0,
GGML_TYPE_F16 = 1,
GGML_TYPE_Q4_0 = 2,
GGML_TYPE_Q4_1 = 3,
// GGML_TYPE_Q4_2 = 4, support has been removed
// GGML_TYPE_Q4_3 (5) support has been removed
GGML_TYPE_Q5_0 = 6,
GGML_TYPE_Q5_1 = 7,
GGML_TYPE_Q8_0 = 8,
GGML_TYPE_Q8_1 = 9,
// k-quantizations
GGML_TYPE_Q2_K = 10,
GGML_TYPE_Q3_K = 11,
GGML_TYPE_Q4_K = 12,
GGML_TYPE_Q5_K = 13,
GGML_TYPE_Q6_K = 14,
GGML_TYPE_Q8_K = 15,
GGML_TYPE_I8,
GGML_TYPE_I16,
GGML_TYPE_I32,
GGML_TYPE_COUNT,
};
Consulte https://github.com/philpax/ggml/blob/gguf-spec/docs/gguf.md para obtener detalles de GGUF
Proceso de formación modelo
Entorno de instalación—>cargar modelo previamente entrenado—>modelo de ajuste fino—>guardar modelo
Por supuesto, también puede usar directamente la biblioteca de ajuste fino de modelos TRL desarrollada por huggingface, que será más concisa.
Entorno de instalación
!pip install huggingface_hub
!pip install transformers==4.31.0
!pip install accelerate==0.21.0 peft==0.4.0 bitsandbytes==0.40.2 trl==0.4.7
!pip install sentencepiece
Transformers es una arquitectura común para modelos de lenguaje grandes, y peft (Parameter Efficiency Fine-Tuning) es una integración que permite técnicas de entrenamiento avanzadas como la cuantificación de k-bits, la aproximación de bajo rango y los puntos de control de gradiente, lo que resulta en un uso más eficiente y eficiente de los recursos. modelo amigable y eficiente.
trl es una biblioteca de aprendizaje por refuerzo proporcionada por Hugging face. Este artículo es solo un modelo de ajuste de instrucciones y no incluye el modelo de recompensa ni el entrenamiento RLHF.
bitsandbytes es un contenedor liviano para funciones personalizadas de CUDA, especialmente para optimizador de 8 bits, multiplicación de matrices (LLM.int8()) y funciones de cuantificación.
modelo de carga
Importe el modelo previamente entrenado. Utilice la clase AutoTokenizer y la clase AutoModelForCausalLM de la biblioteca de transformadores para descargar y crear automáticamente instancias de modelo. La clase BitsAndBytesConfig se utiliza para establecer los parámetros de cuantificación del modelo. Por ejemplo, 4 bits es el número de bits de cuantificación, y torch.bfloat16 son los datos utilizados para el ajuste fino del tipo.
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
# Activate 4-bit precision base model loading
use_4bit = True
# Compute dtype for 4-bit base models
bnb_4bit_compute_dtype = "float16"
# Quantization type (fp4 or nf4)
bnb_4bit_quant_type = "nf4"
# Load tokenizer and model with QLoRA configuration
compute_dtype = getattr(torch, bnb_4bit_compute_dtype)
# Activate nested quantization for 4-bit base models (double quantization)
use_nested_quant = False
bnb_config = BitsAndBytesConfig(
load_in_4bit=use_4bit,
bnb_4bit_quant_type=bnb_4bit_quant_type,
bnb_4bit_compute_dtype=compute_dtype,
bnb_4bit_use_double_quant=use_nested_quant,
)
model_name = "meta-llama/Llama-2-7b-chat-hf"
#Load LLaMA tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
# needed for llama tokenizer
tokenizer.pad_token = tokenizer.eos_token
####Below is for mlabonne/guanaco-llama2-1k dataset
#tokenizer.padding_side = "right" # Fix weird overflow issue with fp16 training
#Load the entire model on the GPU 0
device_map = {"": 0}
#Load base model
model = AutoModelForCausalLM.from_pretrained(
model_name,
quantization_config=bnb_config,
device_map=device_map
)
Importe la función prepare_model_for_kbit_training de la biblioteca peft y use esta función para prepararse para la cuantificación de bits K. La función gradient_checkpointing_enable() habilita la función de control de gradiente que puede reducir el uso de memoria durante la fase de entrenamiento.
from peft import prepare_model_for_kbit_training
model.gradient_checkpointing_enable()
model = prepare_model_for_kbit_training(model)
parámetros entrenables
La función print_trainable_parameters se utiliza para imprimir los parámetros entrenables del modelo. Importe las funciones LoraConfig y get_peft_model de la biblioteca peft. LoraConfig se utiliza para configurar el método LORA (aproximación de rango bajo) para reducir los parámetros de entrenamiento. get_peft_model aplica el método LORA al modelo. Lo que se imprime es el caso de los parámetros entrenables del modelo.
Desde la salida del terminal, se puede ver que aproximadamente el 11% de los parámetros se actualizarán cuando se utilice el método LORA, lo que reduce en gran medida la memoria. Diferentes parámetros LORA requerirán memoria diferente. Las dos configuraciones en la siguiente figura corresponden a entrenamiento Cuando se necesita la situación de la memoria.
Con diferentes configuraciones de parámetros LORA, la cantidad de parámetros entrenables variará.
def print_trainable_parameters(model):
"""
Prints the number of trainable parameters in the model.
"""
trainable_params = 0
all_param = 0
for _, param in model.named_parameters():
all_param += param.numel()
if param.requires_grad:
trainable_params += param.numel()
print(
f"trainable params: {trainable_params} || all params: {all_param} || trainable%: {100 * trainable_params / all_param}"
)
from peft import LoraConfig, get_peft_model
# LoRA attention dimension 64, 8
lora_r = 8
# Alpha parameter for LoRA scaling 16,32
lora_alpha = 32
# Dropout probability for LoRA layers 0.1 0.05
lora_dropout = 0.1
peft_config = LoraConfig(
r=lora_r,
lora_alpha=lora_alpha,
target_modules=["q_proj","v_proj"],
lora_dropout=lora_dropout,
bias="none",
task_type="CAUSAL_LM"
)
model = get_peft_model(model, peft_config)
print_trainable_parameters(model)
Un ejemplo del resultado de esta función es:
trainable params: 32768 || all params: 139493376 || trainable%: 0.02349072116513977
trainable params: 65536 || all params: 139526144 || trainable%: 0.04697040864255519
trainable params: 98304 || all params: 156336128 || trainable%: 0.06287989939216097
trainable params: 131072 || all params: 156368896 || trainable%: 0.08382229673093043
trainable params: 163840 || all params: 240820224 || trainable%: 0.06803415314487873
trainable params: 196608 || all params: 240852992 || trainable%: 0.08162987653481174
trainable params: 229376 || all params: 257662976 || trainable%: 0.08902171493975138
trainable params: 262144 || all params: 257695744 || trainable%: 0.10172616587722923
trainable params: 294912 || all params: 342147072 || trainable%: 0.086194512282718
trainable params: 327680 || all params: 342179840 || trainable%: 0.09576250897773522
trainable params: 360448 || all params: 358989824 || trainable%: 0.10040618867235634
trainable params: 393216 || all params: 359022592 || trainable%: 0.10952402683338658
trainable params: 425984 || all params: 443473920 || trainable%: 0.09605615590652997
trainable params: 458752 || all params: 443506688 || trainable%: 0.10343744805038882
trainable params: 491520 || all params: 460316672 || trainable%: 0.1067786656226086
trainable params: 524288 || all params: 460349440 || trainable%: 0.11388913604413203
trainable params: 557056 || all params: 544800768 || trainable%: 0.10224948875255624
trainable params: 589824 || all params: 544833536 || trainable%: 0.10825765321465088
trainable params: 622592 || all params: 561643520 || trainable%: 0.11085180863477247
trainable params: 655360 || all params: 561676288 || trainable%: 0.11667930692491686
trainable params: 688128 || all params: 646127616 || trainable%: 0.10650032330455289
trainable params: 720896 || all params: 646160384 || trainable%: 0.11156610925871926
trainable params: 753664 || all params: 662970368 || trainable%: 0.11367989225123257
trainable params: 786432 || all params: 663003136 || trainable%: 0.11861663351167015
trainable params: 819200 || all params: 747454464 || trainable%: 0.10959864974463515
trainable params: 851968 || all params: 747487232 || trainable%: 0.11397759901803915
trainable params: 884736 || all params: 764297216 || trainable%: 0.11575810842676156
trainable params: 917504 || all params: 764329984 || trainable%: 0.1200402992433174
trainable params: 950272 || all params: 848781312 || trainable%: 0.11195722461900763
trainable params: 983040 || all params: 848814080 || trainable%: 0.11581334748829802
...
Cargar el conjunto de datos de entrenamiento
from datasets import load_dataset
dataset = load_dataset("Abirate/english_quotes")
dataset = dataset.map(lambda samples: tokenizer(samples["quote"]), batched=True)
Descargando archivo Léame: 0%| | 0.00/5.55k [00:00<?, ?B/s]
Descargando archivos de datos: 0%| | 0/1 [00:00<?, ?it/s]
Descargando datos: 0 %| | 0.00/647k [00:00<?, ?B/s]
Extrayendo archivos de datos: 0%| | 0/1 [00:00<?, ?it/s]
Generando división de trenes: 0 ejemplos [00: 00, ? ejemplos/s]
Mapa: 0%| | 0/2508 [00:00<?, ? ejemplos/s]
Importe la función load_dataset de la biblioteca de conjuntos de datos de Huggingface y úsela para cargar las "comillas" en "Abirate /english_quotes" conjunto de datos ", y luego use el tokenizador LLaMA para tokenizarlo.
Definir parámetros de entrenamiento y entrenar el modelo.
El ajuste fino se puede lograr de dos maneras utilizando transformadores y bibliotecas trl. TRL es una biblioteca de ajuste fino de modelos desarrollada por huggingface, cuyo objetivo es simplificar y simplificar el proceso de ajuste fino de los modelos de lenguaje. Con su interfaz intuitiva y amplias funciones, TRL permite a investigadores y profesionales ajustar de manera fácil y eficiente modelos de lenguaje grandes como LLaMA-v2-7B.
Al aprovechar TRL, podemos liberar todo el potencial del modelado de lenguajes. Proporciona un conjunto completo de herramientas y técnicas para diversas tareas de PNL, incluida la clasificación de texto, el reconocimiento de entidades con nombre, el análisis de sentimientos y más. Con TRL, es posible ajustar la funcionalidad del modelo personalizado LLaMA-v2-7B según necesidades específicas.
Aquí se utiliza la clase Trainer en la biblioteca de transformadores, y se crea una instancia del Trainer usando el modelo, el conjunto de datos de entrenamiento y los parámetros de entrenamiento. El conjunto de datos de entrenamiento establece varios parámetros durante el entrenamiento, como el tamaño del lote, la tasa de aprendizaje y el algoritmo de optimización ( paginado_adamw_8bit). DataCollatorForLanguageModeling se utiliza para recopilar y agrupar datos tokenizados. Finalmente, llame al método trainer.train() para comenzar a ajustar el entrenamiento. Más adelante se proporciona una interfaz más sencilla basada en la biblioteca trl.
import transformers
################################################################################
# TrainingArguments parameters
################################################################################
# Output directory where the model predictions and checkpoints will be stored
output_dir = "./results"
# Number of training epochs
num_train_epochs = 1
# Enable fp16/bf16 training (set bf16 to True with an A100)
fp16 = False
bf16 = False
# Batch size per GPU for training
per_device_train_batch_size = 4
# Batch size per GPU for evaluation
per_device_eval_batch_size = 4
# Number of update steps to accumulate the gradients for
gradient_accumulation_steps = 1
# Enable gradient checkpointing
gradient_checkpointing = True
# Maximum gradient normal (gradient clipping)
max_grad_norm = 0.3
# Initial learning rate (AdamW optimizer)
learning_rate = 2e-4
# Weight decay to apply to all layers except bias/LayerNorm weights
weight_decay = 0.001
# Optimizer to use, paged_adamw_8bit paged_adamw_32bit etc...
optim = "paged_adamw_8bit"
# Learning rate schedule
lr_scheduler_type = "cosine"
# Number of training steps (overrides num_train_epochs)
max_steps = -1
# Ratio of steps for a linear warmup (from 0 to learning rate)
warmup_ratio = 0.03
# Group sequences into batches with same length
# Saves memory and speeds up training considerably
group_by_length = True
# Save checkpoint every X updates steps
save_steps = 0
# Log every X updates steps
logging_steps = 25
# Fine-tuned model name
new_model = "llama-2-7b-shichaog"
# Set training parameters
training_arguments = transformers.TrainingArguments(
output_dir=output_dir,
num_train_epochs=num_train_epochs,
per_device_train_batch_size=per_device_train_batch_size,
gradient_accumulation_steps=gradient_accumulation_steps,
optim=optim,
save_steps=save_steps,
logging_steps=logging_steps,
learning_rate=learning_rate,
weight_decay=weight_decay,
fp16=fp16,
bf16=bf16,
max_grad_norm=max_grad_norm,
max_steps=max_steps,
warmup_ratio=warmup_ratio,
group_by_length=group_by_length,
lr_scheduler_type=lr_scheduler_type,
report_to="tensorboard"
)
## needed for llama tokenizer
tokenizer.pad_token = tokenizer.eos_token
trainer = transformers.Trainer(
model=model,
train_dataset=dataset["train"],
# args=transformers.TrainingArguments(
# per_device_train_batch_size=1,
# gradient_accumulation_steps=4,
# warmup_steps=2,
# max_steps=10,
# learning_rate=2e-4,
# fp16=True,
# logging_steps=1,
# output_dir="outputs",
# optim="paged_adamw_8bit"
# ),
args=training_arguments,
data_collator=transformers.DataCollatorForLanguageModeling(tokenizer, mlm=False),
)
model.config.use_cache = False # silence the warnings. Please re-enable for inference!
trainer.train()
trainer.model.save_pretrained(new_model)
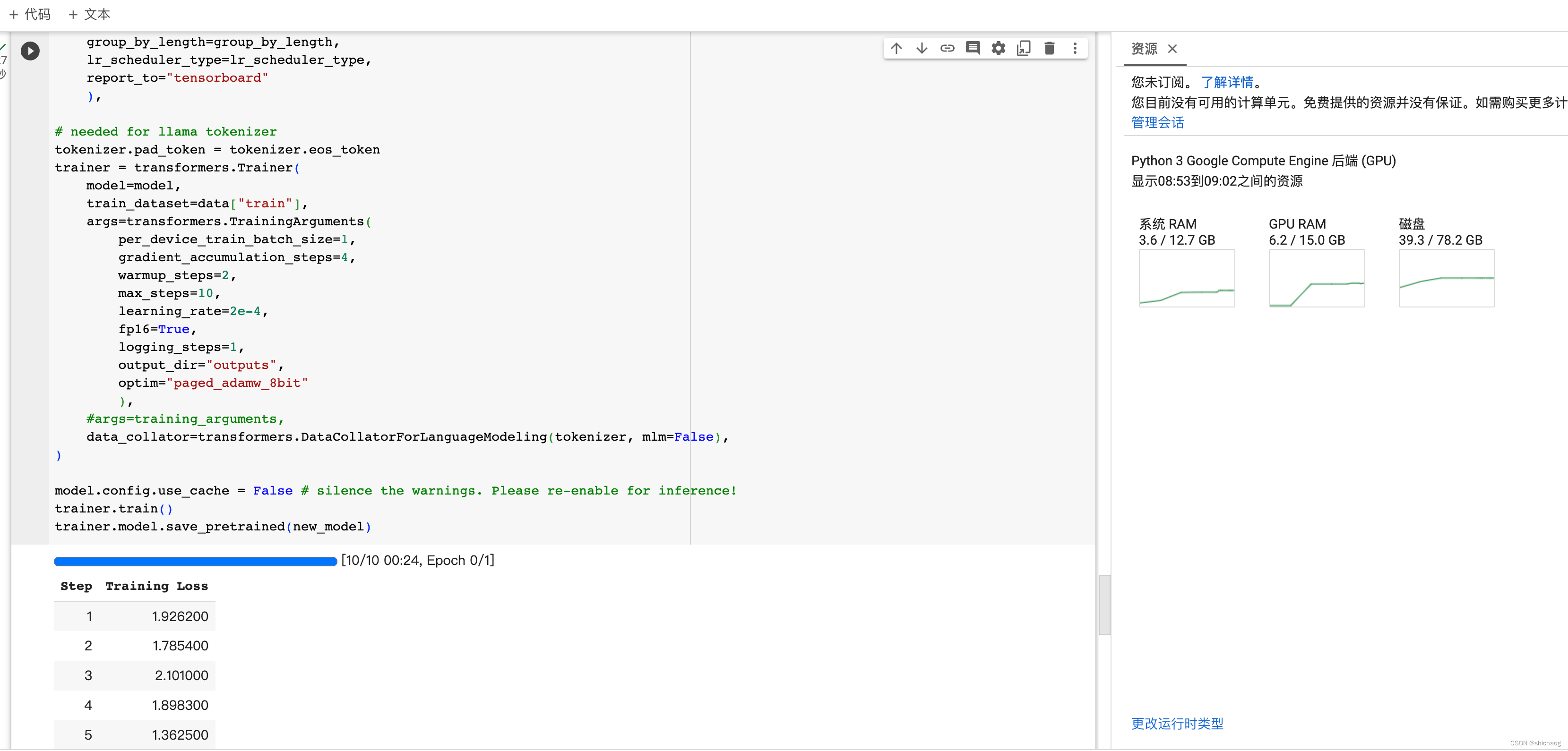
El lado derecho de la figura muestra el uso de memoria de la GPU.
Puede usar la interfaz de la biblioteca trl para implementar las funciones anteriores, que serán más simples que las anteriores y las funciones son consistentes.
################################################################################
# SFT parameters
################################################################################
from trl import SFTTrainer
# Maximum sequence length to use
max_seq_length = None
# Pack multiple short examples in the same input sequence to increase efficiency
packing = False
# Load the entire model on the GPU 0
device_map = {"": 0}
# Set supervised fine-tuning parameters from trl library
trainer2 = SFTTrainer(
model=model,
train_dataset=dataset["train"],
peft_config=peft_config,
dataset_text_field="quote",
max_seq_length=max_seq_length,
tokenizer=tokenizer,
args=training_arguments,
packing=packing,
)
# Train model
trainer2.train()
# Save trained model
trainer2.model.save_pretrained(new_model)
Este código tiene el mismo significado y función que el Entrenador que usa la biblioteca de transformadores en el párrafo anterior. El SFTTrainer aquí es la encapsulación del Entrenador anterior y el significado de los parámetros es el mismo. Debido a que la biblioteca trl admite RLHF como PPO, la compatibilidad con SFT hará que la biblioteca trl sea más completa.