Una nueva mirada al ajuste fino de modelos grandes
Todo comienza con el reciente incendio de Lora ( 《LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS》), que se presentó en ICLR2022. Se dice que al usar el método de adaptación de rango bajo, solo se necesita entrenar una pequeña cantidad de parámetros para lograr un buen efecto cuando se usa un modelo grande para adaptarse a las tareas posteriores.
¿Cómo ajusta LoRA y se adapta a las tareas posteriores? El proceso es muy simple, LoRA usa los datos correspondientes a las tareas posteriores y solo agrega algunos parámetros a través del entrenamiento para adaptarse a las tareas posteriores. Después de entrenar los nuevos parámetros, los nuevos parámetros y los parámetros del modelo anterior se fusionan mediante el método de reparación de parámetros, de modo que el efecto de ajustar todo el modelo se puede lograr en la nueva tarea, y la inferencia no será aumenta durante la inferencia.
El diagrama esquemático de LoRA es el siguiente: 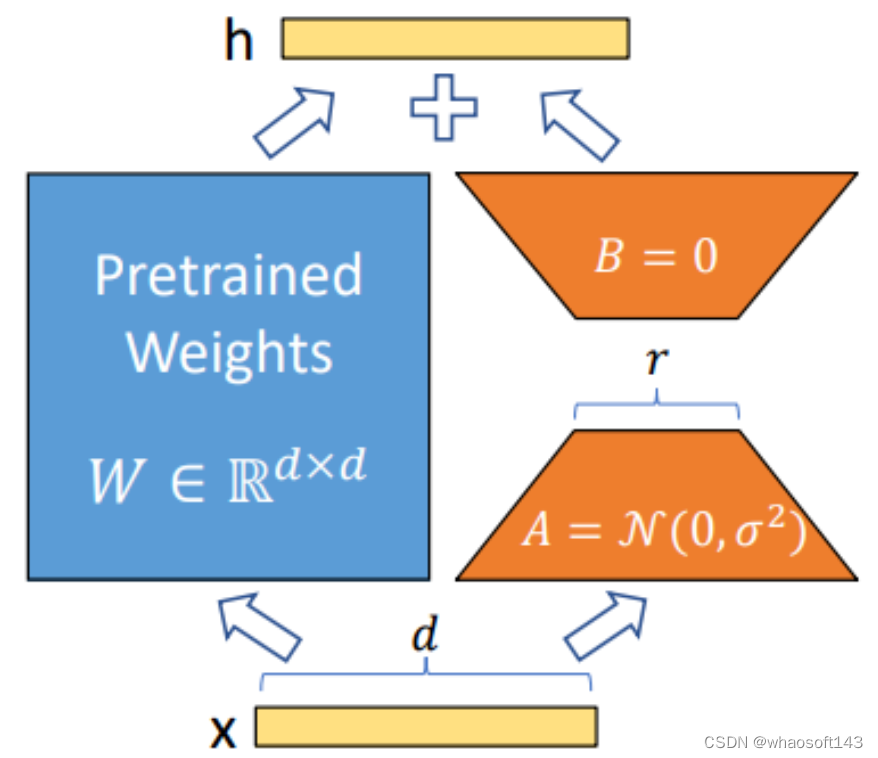 la parte azul de la figura son los parámetros del modelo preentrenado. LoRA agrega dos estructuras A y B junto a la estructura del modelo preentrenado. Los parámetros de estas dos estructuras se inicializan a la distribución gaussiana. y 0 respectivamente, entonces el parámetro adicional al comienzo del entrenamiento es 0. La dimensión de entrada de A y la dimensión de salida de B son las mismas que las dimensiones de entrada y salida del modelo original respectivamente, mientras que la dimensión de salida de A y la dimensión de entrada de B son un valor mucho menor que las dimensiones de entrada y salida de el modelo original, que es la encarnación de bajo rango (Un poco similar a la estructura de Resnet), esto puede reducir en gran medida los parámetros a entrenar. Solo los parámetros de A y B se actualizan durante el entrenamiento y los parámetros del modelo preentrenado son fijos. La idea de reparametrización se puede utilizar durante la inferencia para combinar AB y W, de modo que no se introduzcan cálculos adicionales durante la inferencia. Además, para diferentes tareas posteriores, solo es necesario volver a entrenar AB sobre la base del modelo preentrenado, lo que también puede acelerar el ritmo de entrenamiento de modelos grandes.
la parte azul de la figura son los parámetros del modelo preentrenado. LoRA agrega dos estructuras A y B junto a la estructura del modelo preentrenado. Los parámetros de estas dos estructuras se inicializan a la distribución gaussiana. y 0 respectivamente, entonces el parámetro adicional al comienzo del entrenamiento es 0. La dimensión de entrada de A y la dimensión de salida de B son las mismas que las dimensiones de entrada y salida del modelo original respectivamente, mientras que la dimensión de salida de A y la dimensión de entrada de B son un valor mucho menor que las dimensiones de entrada y salida de el modelo original, que es la encarnación de bajo rango (Un poco similar a la estructura de Resnet), esto puede reducir en gran medida los parámetros a entrenar. Solo los parámetros de A y B se actualizan durante el entrenamiento y los parámetros del modelo preentrenado son fijos. La idea de reparametrización se puede utilizar durante la inferencia para combinar AB y W, de modo que no se introduzcan cálculos adicionales durante la inferencia. Además, para diferentes tareas posteriores, solo es necesario volver a entrenar AB sobre la base del modelo preentrenado, lo que también puede acelerar el ritmo de entrenamiento de modelos grandes.
Dado que este artículo no presenta LoRA específicamente, puede ver el texto original de LoRA para obtener más detalles. Solo necesitamos saber que los experimentos posteriores en el artículo de LoRA han demostrado la efectividad del método. Entonces piensa más, ¿por qué la idea de LoRA puede funcionar bien?
La respuesta es la dimensión intrínseca que se discutirá a continuación. Este punto también se menciona en el texto original de LoRA, que se inspiró en los siguientes dos artículos:
-
MEASURING THE INTRINSIC DIMENSION OF OBJECTIVE LANDSCAPES, publicado en ICLR2018, por conveniencia, el próximo artículo se llama [Paper 1] -
INTRINSIC DIMENSIONALITY EXPLAINS THE EFFECTIVENESS OF LANGUAGE MODEL FINE-TUNING, publicado en ACL2021, por conveniencia, el próximo artículo se llama [Paper 2]
Definición de dimensión intrínseca
El concepto de dimensión intrínseca fue propuesto por [Documento 1].
Entrenar una red neuronal a menudo implica los siguientes pasos:
-
Para un conjunto de datos dado, primero diseñe la estructura de la red y seleccione la pérdida correspondiente
-
Inicializar aleatoriamente los parámetros en la red.
-
Entrenar la red hace que la pérdida sea cada vez menor
La fase de entrenamiento puede considerarse como encontrar un camino efectivo en un paisaje objetivo fijo.
Aquí hay una explicación de por qué es un mapa de destino fijo. Porque después de fijar el conjunto de datos y la estructura de la red, se ha definido el problema a optimizar, por lo que se determina el gráfico de destino.
Como se muestra en la siguiente figura: 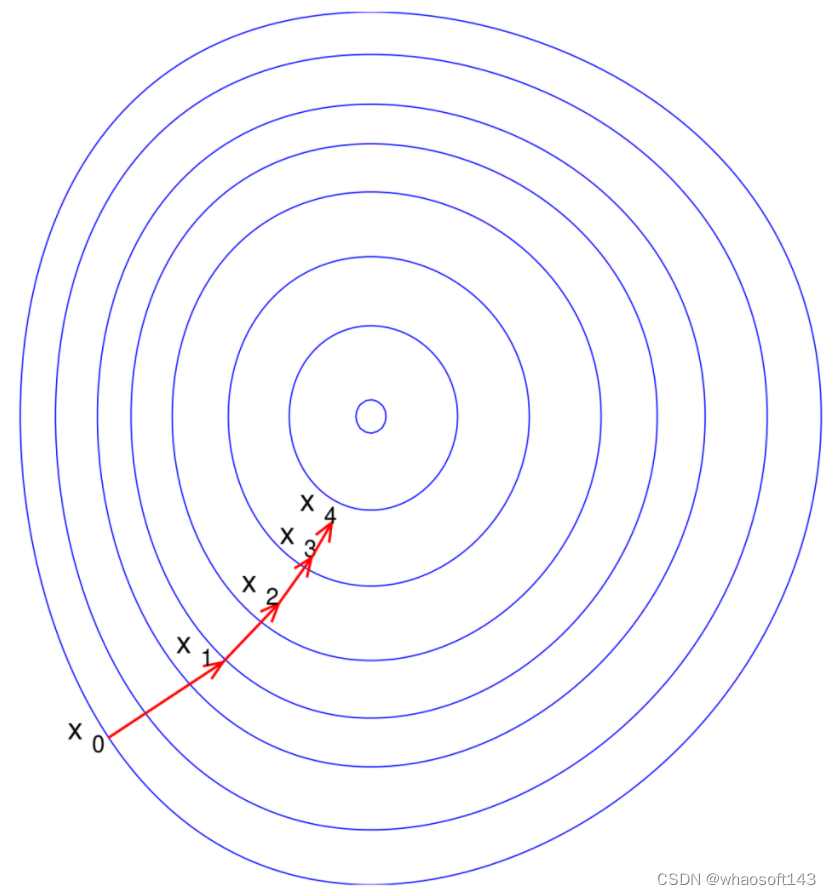
 Es decir, solo los parámetros d-dimensionales pueden actualizarse cuando se entrena la red para lograr el efecto deseado de la red. Entonces esta d es la llamada dimensión intrínseca del modelo.
Es decir, solo los parámetros d-dimensionales pueden actualizarse cuando se entrena la red para lograr el efecto deseado de la red. Entonces esta d es la llamada dimensión intrínseca del modelo.
Puede sentirse un poco mareado después de terminar aquí, echemos un vistazo a la siguiente imagen: 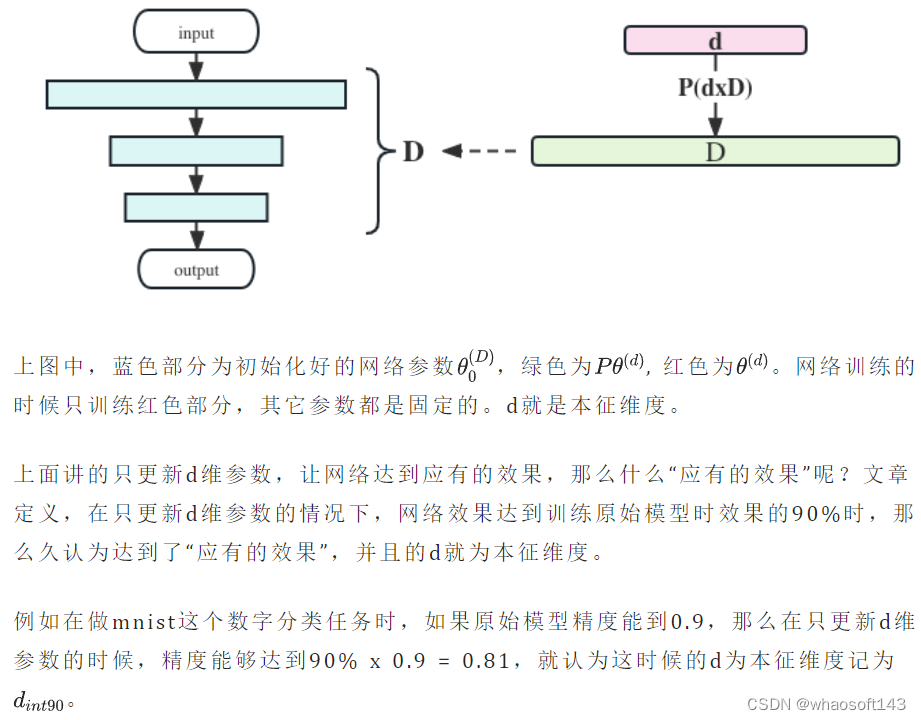 Usar la dimensión intrínseca para pensar en la efectividad del ajuste fino del modelo grande
Usar la dimensión intrínseca para pensar en la efectividad del ajuste fino del modelo grande
[Prueba 2] Usando las dimensiones propias propuestas anteriormente para pensar en la efectividad del ajuste fino de modelos grandes, ¿por qué es posible ajustar modelos grandes de manera efectiva con cientos o miles de imágenes ahora?
De acuerdo con el [Documento 1], para cierto tipo de problema, hay características intrínsecas con cierta precisión (como el 90 % de precisión). Para un modelo grande, la prueba de la dimensión intrínseca puede saber cuántos parámetros deben ajustarse para resolver el problema actual aproximadamente al resolver un determinado tipo de problema aguas abajo. Si realmente hay experimentos que pueden demostrar que solo ajustar unos pocos parámetros puede resolver bien el problema posterior, entonces también se puede responder la pregunta anterior, es decir, una pequeña cantidad de ajuste fino (ajustando una pequeña cantidad de parámetros) en el El modelo grande puede resolver el problema actual. .
A menos que se especifique lo contrario a continuación, "artículo" se refiere al 【Documento 2】
Experimento 1: Para modelos grandes, si hay una dimensión intrínseca  Los resultados experimentales se muestran en la siguiente figura:
Los resultados experimentales se muestran en la siguiente figura: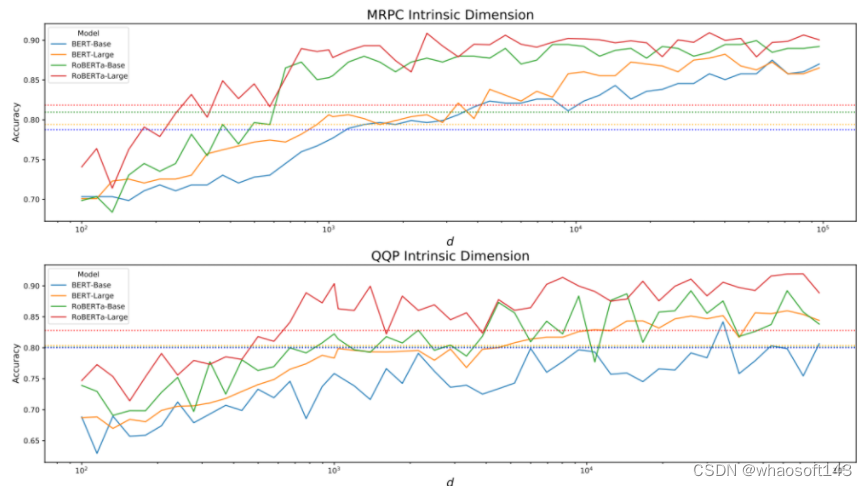
Los subgráficos superior e inferior representan las dos tareas de MRPC y QQP respectivamente. Cada subgráfico tiene cuatro líneas sólidas que representan la precisión de los cuatro modelos y cuatro líneas punteadas que representan el valor que alcanza el 90 % de la precisión de todo el modelo de ajuste fino. .La abscisa representa el tamaño d la dimensión de formación. En la figura se puede ver que dos tareas y cuatro modelos diferentes solo necesitan entrenar parámetros d-dimensionales más pequeños para lograr una precisión del 90 %. El concepto de dimensión intrínseca es válido en modelos grandes.
Por lo tanto, cuando se entrena una tarea posterior, solo es necesario entrenar una pequeña cantidad de parámetros para lograr buenos resultados. En este momento, el problema al principio del artículo ha sido resuelto. Pero el autor hizo algunos otros experimentos y encontró algunas conclusiones interesantes.
La relación entre la calidad de la formación previa y la dimensión intrínseca
El artículo propone tal hipótesis que el modelo de pre-entrenamiento puede implícitamente reducir la dimensión intrínseca del modelo en cada tarea de PNL.
Con base en esta conjetura, el artículo realizó el siguiente experimento: Al entrenar previamente el modelo base RoBERTa, guarde el modelo de entrenamiento previo correspondiente cada 10K y luego pruebe el modelo de entrenamiento previo guardado en MRPC, QQP, Yelp Polarity, SST -2, MNLI, ANLI seis conjuntos de datos de dimensiones propias.
Los resultados son los siguientes: 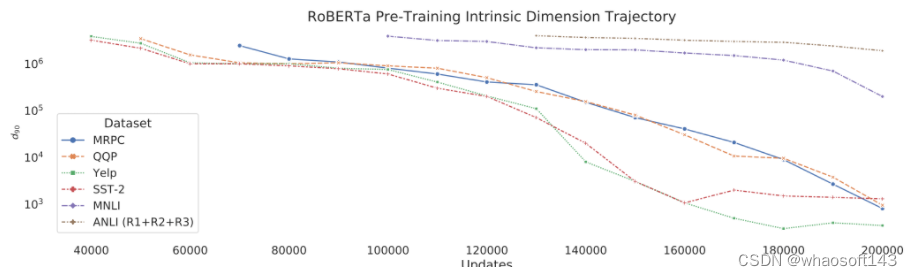 Se puede observar que en diferentes conjuntos de datos, existe la misma tendencia, es decir, cuantos más tiempos de pre-entrenamiento, menor es la dimensión intrínseca del modelo en cada tarea. El experimento no optimizó deliberadamente la llamada dimensión intrínseca, pero el entrenamiento previo fue más prolongado. Por lo tanto, se confirma que cuanto más fuerte es la capacidad de representación del modelo de preentrenamiento (mejor entrenamiento), menor es la dimensión intrínseca.
Se puede observar que en diferentes conjuntos de datos, existe la misma tendencia, es decir, cuantos más tiempos de pre-entrenamiento, menor es la dimensión intrínseca del modelo en cada tarea. El experimento no optimizó deliberadamente la llamada dimensión intrínseca, pero el entrenamiento previo fue más prolongado. Por lo tanto, se confirma que cuanto más fuerte es la capacidad de representación del modelo de preentrenamiento (mejor entrenamiento), menor es la dimensión intrínseca.
La relación entre los parámetros del modelo preentrenado y las dimensiones intrínsecas
Originalmente, al hacer la relación entre los parámetros de pre-entrenamiento y las dimensiones intrínsecas, es necesario unificar la estructura del modelo, que es más convincente. Pero el autor dijo que de esta manera, se requiere entrenar muchos experimentos modelo a gran escala.Para que sea más fácil comparar el artículo, el experimento se realiza en función de la estructura existente. A partir de la tendencia de los resultados experimentales, diferentes estructuras también pueden sacar conclusiones válidas. ¿Qué software es? http://143ai.com
El artículo utiliza el modelo de preentrenamiento existente para calcular la dimensión intrínseca en el conjunto de datos MRPC.
Los resultados experimentales son los siguientes: 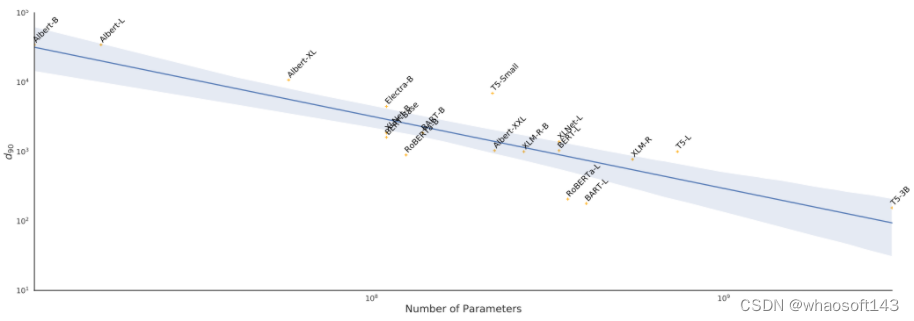 la ordenada en la figura anterior representa el valor de la dimensión intrínseca, y la misma coordenada representa la cantidad del parámetro del modelo. A partir de la tendencia en la figura, se puede ver claramente que cuanto más grande es el modelo, menor es la dimensión intrínseca, es decir, cuanto más fuerte es el modelo, menor es la dimensión intrínseca.
la ordenada en la figura anterior representa el valor de la dimensión intrínseca, y la misma coordenada representa la cantidad del parámetro del modelo. A partir de la tendencia en la figura, se puede ver claramente que cuanto más grande es el modelo, menor es la dimensión intrínseca, es decir, cuanto más fuerte es el modelo, menor es la dimensión intrínseca.
La relación entre la dimensión intrínseca y la capacidad de generalización
La relación entre el ajuste fino (3.1), el preentrenamiento (3.2) y la dimensión intrínseca se introdujo anteriormente, pero la relación entre la dimensión intrínseca y la capacidad de generalización no se ha verificado. Es decir, ahora sabemos cómo hacer que la dimensión propia sea pequeña, pero si la dimensión propia es pequeña, ¿se puede mejorar la capacidad de generalización? 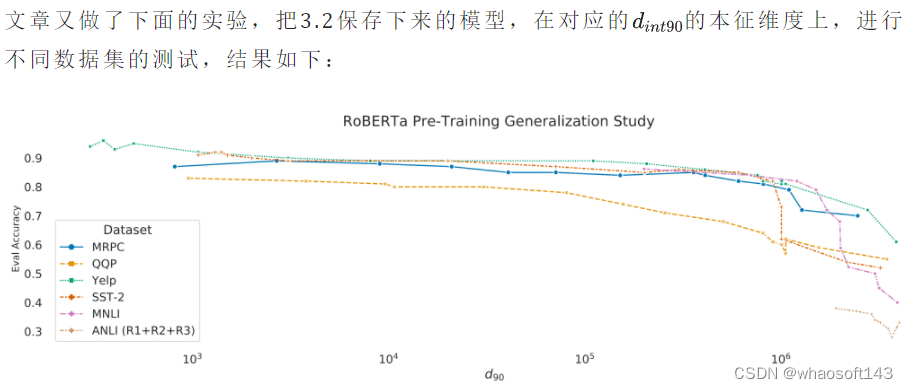 Se puede ver que el modelo con dimensión intrínseca baja tiene una tasa de precisión más alta que el modelo entrenado. Es decir, cuanto menor sea la dimensión intrínseca, mejor será el rendimiento de generalización.
Se puede ver que el modelo con dimensión intrínseca baja tiene una tasa de precisión más alta que el modelo entrenado. Es decir, cuanto menor sea la dimensión intrínseca, mejor será el rendimiento de generalización.
Volviendo a la pregunta de introducción: ¿Por qué puede funcionar la idea de LoRA?
Debido a que el modelo grande tiene el concepto de dimensión intrínseca, solo necesita ajustar algunos parámetros para obtener buenos resultados en las tareas posteriores.