Texto original: https://www.toutiao.com/article/7256433230780531234/?log_from=5d399b2e108f8_1689637770403
Tecnología de ajuste fino del modelo de lenguaje grande de inteligencia artificial: ajuste fino supervisado SFT, método de ajuste fino LoRA, método de ajuste fino P-tuning v2, método de ajuste fino supervisado Freeze
1. Ajuste fino supervisado por SFT
1.1 Concepto básico del ajuste fino supervisado por SFT
El ajuste fino supervisado SFT (Supervised Fine-Tuning) se refiere al entrenamiento previo de un modelo de red neuronal en el conjunto de datos de origen, es decir, el modelo de origen. A continuación, cree un nuevo modelo de red neuronal, el modelo de destino. El modelo de destino replica todo el diseño del modelo y sus parámetros en el modelo de origen excepto la capa de salida. Estos parámetros del modelo contienen el conocimiento adquirido en el conjunto de datos de origen y este conocimiento también se aplica al conjunto de datos de destino. La capa de salida del modelo de origen está estrechamente relacionada con las etiquetas del conjunto de datos de origen, por lo que no se adopta en el modelo de destino. Al realizar el ajuste fino, agregue una capa de salida cuyo tamaño de salida sea el número de categorías del conjunto de datos de destino para el modelo de destino e inicialice los parámetros del modelo de esta capa de forma aleatoria. Al entrenar el modelo de destino en el conjunto de datos de destino, la capa de salida se entrenará desde cero y los parámetros de las capas restantes se ajustarán en función de los parámetros del modelo de origen.
1.2 Pasos del ajuste fino supervisado
Específicamente, el ajuste fino supervisado incluye los siguientes pasos:
- Entrenamiento previo: primero entrene un modelo de aprendizaje profundo en un conjunto de datos a gran escala, por ejemplo, entrenamiento previo utilizando algoritmos de aprendizaje autosupervisado o de aprendizaje no supervisado;
- Ajuste fino: el modelo preentrenado se ajusta usando el conjunto de entrenamiento de la tarea de destino. Por lo general, solo se ajusta con precisión una parte de las capas del modelo preentrenado, como solo las últimas capas del modelo o algunas capas intermedias. En el proceso de ajuste fino, el modelo se optimiza a través del algoritmo de propagación hacia atrás para que el modelo funcione mejor en la tarea de destino;
- Evaluación: use el conjunto de prueba de la tarea de destino para evaluar el modelo ajustado para obtener el índice de rendimiento del modelo en la tarea de destino.
1.3 Características del ajuste fino supervisado
El ajuste fino supervisado puede aprovechar los parámetros y la estructura del modelo preentrenado y evitar entrenar el modelo desde cero, acelerando así el proceso de entrenamiento del modelo y mejorando el rendimiento del modelo en la tarea de destino. El ajuste fino supervisado se ha utilizado ampliamente en la visión artificial, el procesamiento del lenguaje natural y otros campos. Sin embargo, la supervisión también tiene algunas desventajas. En primer lugar, se requiere una gran cantidad de datos etiquetados para ajustar la tarea de destino. Si los datos etiquetados son insuficientes, puede dar lugar a un rendimiento deficiente del modelo ajustado. En segundo lugar, dado que los parámetros y la estructura del modelo preentrenado tienen un gran impacto en el rendimiento del modelo ajustado, también es importante elegir un modelo preentrenado adecuado.
1.4 Casos comunes
- muestra 1
En la visión por computadora, la red de bajo nivel aprende principalmente los bordes o puntos de color de la imagen, la red de nivel medio aprende principalmente la parte y la textura del objeto, y la red de alto nivel reconoce la semántica abstracta, como se muestra en la figura. abajo. Por lo tanto, una red neuronal se puede dividir en dos partes:
- La red de bajo nivel realiza la extracción de características, convirtiendo la información original en características que se utilizan fácilmente en tareas posteriores;
- La red en la capa de salida realiza predicciones específicas de la tarea. La capa de salida no se puede reutilizar en diferentes tareas porque involucra tareas específicas, pero la red de bajo nivel es general y se puede aplicar a otras tareas.
- La siguiente figura muestra que los parámetros de la primera capa L-1 del modelo de preentrenamiento se copian en el modelo de ajuste fino, y los parámetros de la capa de salida del modelo de ajuste fino se inicializan aleatoriamente. Durante el proceso de entrenamiento, el propósito de ajuste fino se logra estableciendo una pequeña tasa de aprendizaje.
- Muestra 2
El modelo BERT es un modelo de preentrenamiento propuesto por Google AI Research Institute. A través de preentrenamiento y ajuste, ha alcanzado el nivel más avanzado en ese momento en múltiples tareas posteriores de NLP, como reconocimiento de entidades, coincidencia de texto, y comprensión lectora. Como en el Ejemplo 1, al ajustar el modelo BERT, los parámetros del modelo previamente entrenados se copian en el modelo de ajuste fino y los parámetros de la capa de salida se inicializan aleatoriamente.
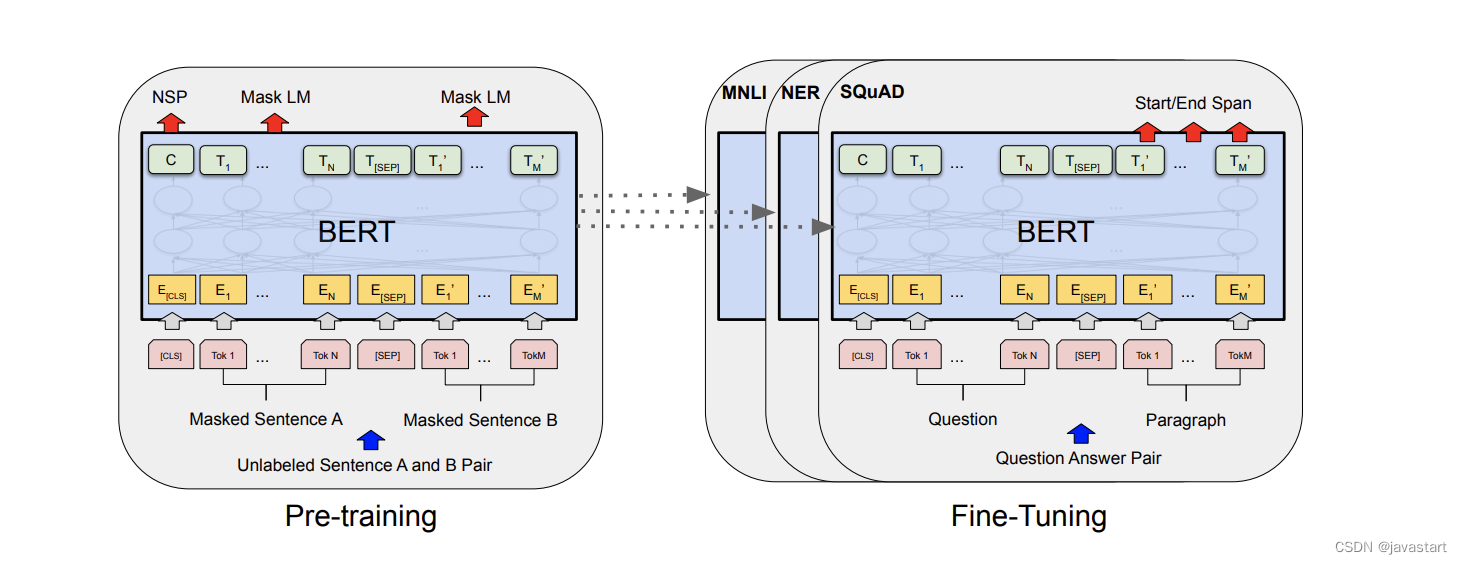
1.5 Métodos convencionales de ajuste fino supervisado por SFT
Con el desarrollo de la tecnología, han surgido más y más modelos de lenguaje grandes con más y más parámetros de modelo. Por ejemplo, GPT3 ha alcanzado los 175 mil millones de parámetros. El método de ajuste fino supervisado tradicional ya no es aplicable al modelo de lenguaje grande actual. Para resolver el problema de demasiados parámetros de ajuste fino y garantizar el efecto de ajuste fino, es urgente desarrollar un método de ajuste fino eficiente de parámetros (Parameter Efficient Fine Tuning, PEFT). En la actualidad, han surgido muchos métodos de ajuste fino de parámetros eficientes, y los métodos principales incluyen:
- LoRA
- P-ajuste v2
- Congelar
2. Método de ajuste fino de LoRA
2.1 Concepto básico del método de ajuste fino de LoRA
LoRA (Adaptación de bajo rango de modelos de lenguaje grande), traducido literalmente como adaptación de bajo nivel de modelos de lenguaje grande . El principio básico de LoRA es congelar los parámetros de peso del modelo previamente entrenados. En el caso de congelar los parámetros del modelo original, al agregar capas de red adicionales al modelo, y solo entrenar estos nuevos parámetros de capa de red . Debido a la pequeña cantidad de estos nuevos parámetros, no solo se reduce significativamente el costo del ajuste fino, sino que también se puede obtener un efecto similar al de los parámetros del modelo completo que participan en el ajuste fino.
Con el desarrollo de grandes modelos de lenguaje, la cantidad de parámetros en el modelo es cada vez mayor. Por ejemplo, la cantidad de parámetros en GPT-3 ha llegado a 175 mil millones. Por lo tanto, el ajuste fino de todos los parámetros del modelo se vuelve inviable. El método de ajuste fino de LoRA fue propuesto por Microsoft. Al ajustar solo los nuevos parámetros, la cantidad de parámetros entrenables para tareas posteriores se reduce considerablemente.
2.2 Principio básico del método de ajuste fino de LoRA
Cada capa de una red neuronal consiste en una multiplicación de matrices. Las matrices de peso en estas capas suelen tener rango completo. Los modelos de lenguaje preentrenados tienen una "dimensionalidad intrínseca" baja cuando se adaptan a una tarea específica, y aún pueden aprender de manera eficiente cuando se proyectan al azar en un subespacio más pequeño.
En el proceso de ajuste fino del modelo de lenguaje grande, LoRA congela los pesos del modelo previamente entrenados e inyecta una matriz de factorización de rango entrenable en cada capa de la arquitectura de Transformer. Por ejemplo, para la matriz de pesos preentrenados W0, su actualización puede estar sujeta a que esta última se exprese mediante una descomposición de bajo rango:
$W0+△W=W0+BA$
en:
$W0∈Rd×k,B∈Rd×r,A∈Rr×k$
Además, el rango r≪min(d,k),
en este momento, la fórmula de cálculo de propagación directa revisada se convierte en:
$h=W0x+△Wx=W0x+BAx$
Al ajustar el modelo, W0se congela, no acepta actualizaciones de gradiente y solo ajusta los parámetros A y B. En comparación con todos los parámetros que participan en el ajuste fino del modelo, la cantidad de parámetro del ajuste fino del modelo en este paso cambia de d×k a d×r+r×k, y r≪min(d,k), por lo que la cantidad de parámetros de ajuste fino se reduce considerablemente.
Como se muestra en la siguiente figura, durante el ajuste fino de LoRA, se usa una inicialización gaussiana aleatoria para A y una inicialización cero para B, por lo que ΔW=BA es cero al comienzo del entrenamiento.
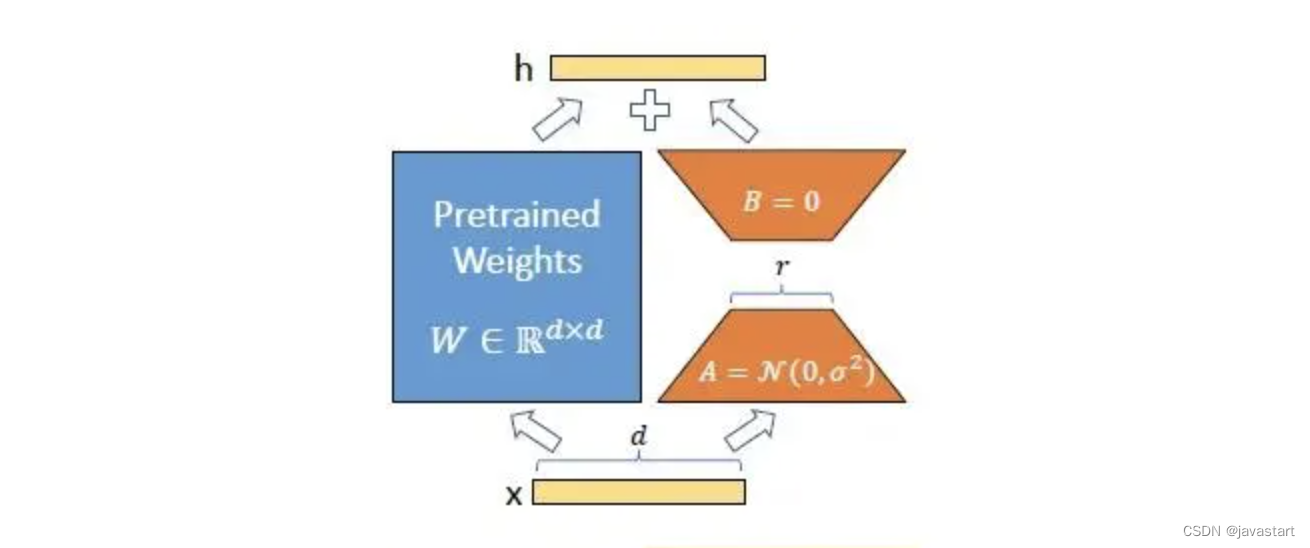
El método de ajuste fino de LoRA se adopta para cada estructura de capa de Transformer, lo que finalmente puede reducir en gran medida la cantidad de parámetros de ajuste fino del modelo. Cuando se implementa en producción, solo es necesario calcular y almacenar W=W0+BA, y la inferencia se realiza como de costumbre. En comparación con otros métodos, no hay demora adicional porque no es necesario adjuntar más capas.
En la arquitectura Transformer, hay cuatro matrices de peso (Wq, Wk, Wv, Wo) en el módulo del mecanismo de autoatención y dos matrices de peso en el módulo MLP. Cuando LoRA ajusta las tareas posteriores, solo ajusta los pesos del módulo del mecanismo de autoatención y congela el módulo MLP. Entonces, para Transformers grandes, el uso de LoRA puede reducir hasta 2/3 del uso de la memoria de video (VRAM). Por ejemplo, en GPT-3 175B, el uso de LoRA puede reducir el consumo de VRAM durante el entrenamiento de 1,2 TB a 350 GB.
2.3 Principales ventajas del método de ajuste fino de LoRA
- Los parámetros del modelo previamente entrenados se pueden compartir para construir muchos módulos LoRA pequeños para diferentes tareas. El modelo compartido se congela y las tareas se pueden cambiar de manera eficiente al reemplazar las matrices A y B, lo que reduce significativamente los requisitos de almacenamiento y el costo del cambio de múltiples tareas.
- Cuando se utiliza un optimizador adaptativo, dado que no hay necesidad de calcular gradientes y guardar demasiados parámetros del modelo, LoRA mejora el ajuste fino y reduce el umbral de hardware para el ajuste fino en 3 veces.
- La descomposición de bajo rango emplea un diseño lineal de tal manera que es posible fusionar matrices de parámetros entrenables con matrices de parámetros congelados en el momento de la implementación, sin introducir demoras en la inferencia en comparación con los enfoques totalmente ajustados.
- LoRA no entra en conflicto con otros métodos de ajuste fino y se puede combinar con otros métodos de ajuste fino, como el método de ajuste de prefijo que se presentará en la siguiente sección de capacitación.
3. Método de ajuste fino P-tuning v2
3.1 Tecnologías relacionadas del método de ajuste fino P-tuning v2
El método de ajuste fino tradicional necesita ajustar todo el modelo de lenguaje preentrenado. El ajuste fino de un modelo de lenguaje grande requiere muchos recursos y tiempo, y se necesita urgentemente un método de ajuste fino más eficiente. Para comprender el método de ajuste fino de P-tuning v2, primero debe comprender el método de ajuste fino de prefijo y el método de ajuste fino de P-tuning v1.
3.1.1 Método de ajuste fino de ajuste de prefijo
El método de ajuste fino Prefix-tuning agrega un prefijo al modelo, es decir, un vector de tarea específico continuo, y solo optimiza este pequeño segmento de parámetros durante el ajuste fino. Para la tarea de generación condicional, como se muestra en la figura a continuación, la entrada es el texto x y la salida es la secuencia y.
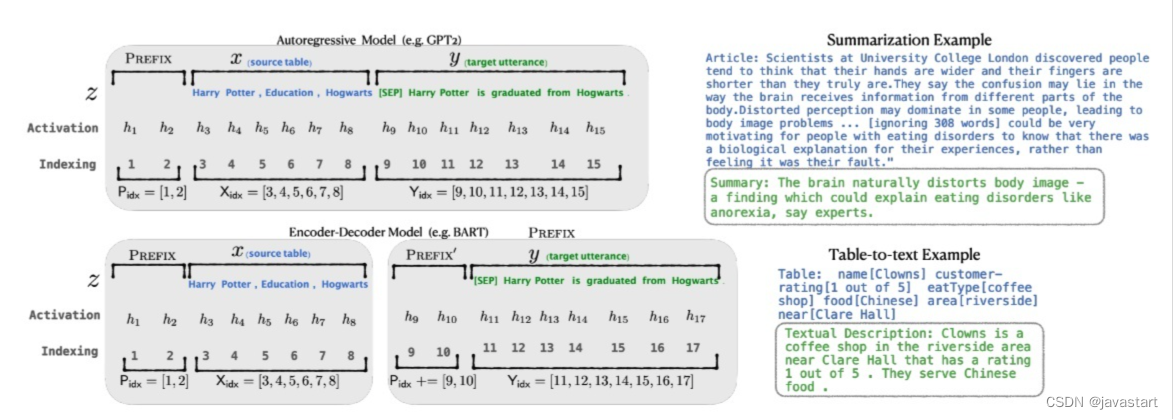
En la figura anterior, z=[x;y] es la concatenación de x e y, Xidxe Yidxrepresentan el índice de la secuencia, hi∈Rd representa el valor de activación en cada momento i, hi=[hi ( 1);...;hi(n)] representa la concatenación de todos los vectores de salida de capa en el momento actual, hi(j) es la salida del Transformador de capa jth en el momento i, por lo que el lenguaje autorregresivo modelo calcula la salida en cada momento hies decir:
$hi=LMϕ(zi,h<i)$
La última capa de hi se usa para calcular la distribución de la siguiente palabra:
$pϕ(zi+1∣h≤i)=softmax(Wϕhi(n))$
donde ϕ es el parámetro del modelo de lenguaje. Después de agregar un prefijo antes del modelo de lenguaje autorregresivo, z=[PREFIX;x;y] o z=[PREFIX;x;PREFIX;y], Pidxindica el índice del prefijo, |Pidx|indica la longitud del prefijo. El ajuste de prefijo almacena los parámetros de prefijo al inicializar la matriz entrenable Pθ(dimensión ∣Pidx×dim(hi)∣):
$hi={Pθ[i,:],ifi∈PidxLMϕ(zi,h<i),de lo contrario$
El objeto de entrenamiento es el mismo que Ajuste fino, pero el parámetro ϕ del modelo de lenguaje es fijo y solo el parámetro de prefijo θ es un parámetro entrenable. Por tanto, hi es una función de Pθ entrenable.
3.1.2 Método de ajuste fino P-tuning v1
El método de ajuste fino de P-tuning v1 consiste en agregar Prompt al proceso de ajuste fino y solo entrenar los parámetros de la parte Prompt, mientras que los parámetros del modelo de lenguaje son fijos . Como se muestra abajo:

P-tuning v1 diseña un método automático para generar indicaciones continuas para mejorar el efecto de ajuste fino del modelo. A partir de la figura anterior, la plantilla de P-tuning v1 se puede expresar mediante la siguiente fórmula:
${h0,…,hola,e(x),hola+1,…,hm,e(y)}$
Donde h representa la representación de solicitud continua de P-tuning v1, e representa un modelo de lenguaje entrenado previamente, x representa la entrada original de los datos e y representa la etiqueta de los datos. Frente al ajuste fino de tareas aguas abajo, el ajuste fino del modelo se realiza optimizando los parámetros de h:
$h^0:m=arghminL(M(x,y))$
3.1.3 Deficiencias
El método de ajuste fino P-tuning v1 carece de generalidad. Los experimentos muestran que P-tuning v1 es comparable a los métodos de ajuste fino de parámetros completos cuando el tamaño del modelo supera los 10 mil millones de parámetros, pero para esos modelos más pequeños, el rendimiento del método P-tuning v1 y los métodos de ajuste fino de parámetros completos es muy diferente, que funciona mal. Al mismo tiempo, P-tuning v1 carece de versatilidad entre tareas y no se ha verificado su eficacia en las tareas de etiquetado de secuencias. El etiquetado de secuencias necesita predecir una serie de etiquetas, y la mayoría de ellas son etiquetas sin sentido, lo cual es extremadamente desafiante para el método de ajuste fino de P-tuning v1. Además, cuando el número de capas del modelo es muy grande, es difícil garantizar la estabilidad del modelo durante el ajuste fino. Cuanto mayor sea el número de capas del modelo, el impacto de la entrada de solicitud en la primera capa en la última es difícil de predecir.
3.2 El principio del método de ajuste fino P-tuning v2
El método de ajuste fino P-tuning v2 es una versión mejorada del método de ajuste fino P-tuning v1 y, al mismo tiempo, se basa en el método de ajuste fino de prefijo. Como se muestra abajo:

En comparación con el método de ajuste fino P-tuning v1, el método de ajuste fino P-tuning v2 adopta el enfoque de ajuste de prefijo, agregando parámetros ajustables a cada capa delante de la entrada. En la parte del prefijo, la entrada de incrustación del transformador de cada capa debe ajustarse con precisión, mientras que P-tuning v1 solo se ajusta con precisión en la primera capa. Al mismo tiempo, para la parte del prefijo, la entrada de cada capa del transformador no se emite desde la capa anterior, sino que se inicializa aleatoriamente como entrada.
Además, P-Tuning v2 incluye las siguientes mejoras:
- Eliminar el método de entrenamiento acelerado de reparamerización;
- Uso de la optimización del aprendizaje multitarea: entrenamiento previo basado en el aviso del conjunto de datos multitarea y luego adaptación de las tareas posteriores.
- Abandone el uso de Verbalizer para el mapeo de vocabulario, reutilice [CLS] y etiquetas de caracteres, y use la salida de cls o tokens para la comprensión del lenguaje natural como los métodos tradicionales de ajuste fino para mejorar la versatilidad y adaptarse a las tareas de etiquetado de secuencias.
3.3 Ventajas del método de ajuste fino P-tuning v2
El método de ajuste fino P-tuning v2 resuelve las deficiencias del método P-tuning v1 y es un método de ajuste fino eficiente en parámetros para modelos de lenguaje grandes.
- El método de ajuste fino P-tuning v2 solo ajusta el 0,1% de los parámetros (parámetros LM fijos) y logra un rendimiento comparable al ajuste fino en modelos de lenguaje de varias escalas de parámetros, lo que resuelve el problema de parámetros insuficientes en P- tuning v1 El problema de un pobre ajuste fino en el modelo. Como se muestra en la siguiente figura (las abscisas indican la cantidad de parámetros del modelo y las ordenadas indican el efecto de ajuste fino):
- Extienda la tecnología de ajuste rápido a tareas NLU complejas, como el etiquetado de secuencias por primera vez, y P-tuning v1 no puede funcionar en esta tarea.
4. Congelación del método de ajuste fino supervisado
4.1 Concepto del método de ajuste fino Freeze
El método Freeze, es decir, la congelación de parámetros, congela parte de los parámetros del modelo original, y solo entrena parte de los parámetros , de modo que el modelo grande se puede entrenar en una sola tarjeta o sin operaciones TP o PP. En el ajuste fino del modelo de lenguaje, el método de ajuste fino Freeze solo ajusta los parámetros de capa completamente conectados de las últimas capas de Transformer, mientras congela todos los demás parámetros.
4.2 Principio del método de ajuste fino Freeze
¿Por qué el método de ajuste fino de Freeze solo ajusta los parámetros de capa completamente conectados de las últimas capas de Transformer? Las razones de esto se describen a continuación.
El modelo Transformer consta principalmente de una capa de autoatención y una capa totalmente conectada (capa FF). Para cada estructura de capas de Transformer, la cantidad de parámetros de la capa de autoatención es 4⋅d2, es decir, WQ, WQ, WQ y WQ ∈ Rd×d; la cantidad de parámetros de la capa FF es 8⋅d2, es decir , W1∈Rd×4d ,W2∈Rd×4d. Por lo tanto, la capa FF ocupa 32 parámetros del modelo, lo que tiene un valor de investigación importante. El diagrama de estructura de red de capa totalmente conectada de Transformer se muestra en la siguiente figura:
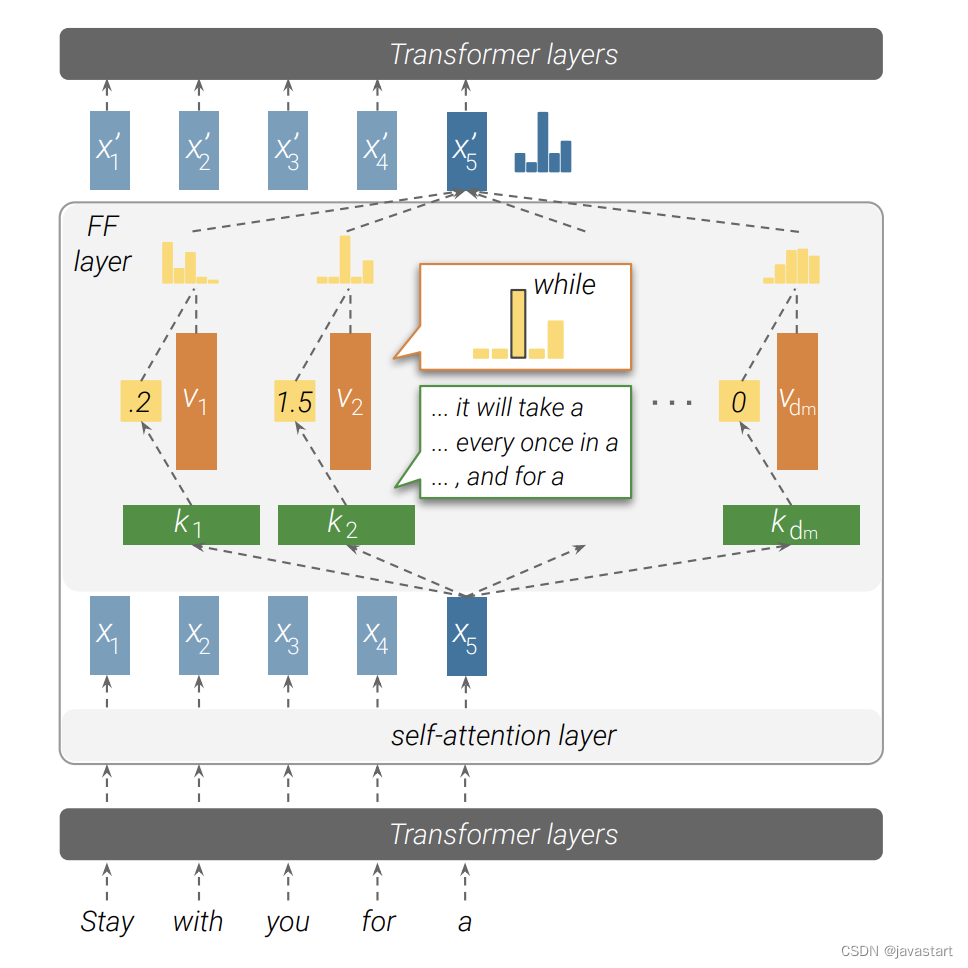
La capa FF de Transformer se puede considerar como una memoria de clave-valor, en la que la clave de cada capa se usa para capturar las características de la secuencia de entrada, y el valor puede proporcionar la distribución de vocabulario del siguiente token en función de las características capturadas. por la llave La capa FF de cada capa de Transformer se compone de varios valores clave y luego se combina con la conexión residual para refinar los resultados de cada capa y, finalmente, generar el resultado de predicción del modelo. La fórmula de la capa FF se puede expresar como:
$FF(x)=f(x⋅KT)⋅V$
donde K,V∈Rdm×d es una matriz de parámetros entrenable y f es una función de activación no lineal, como ReLU.
Además, los experimentos muestran que la capa superficial de Transformer tiende a extraer características superficiales y la capa profunda tiende a extraer características semánticas, como se muestra en la siguiente figura. Cuanto más profunda es la capa, mayor es la proporción de características semánticas extraídas.
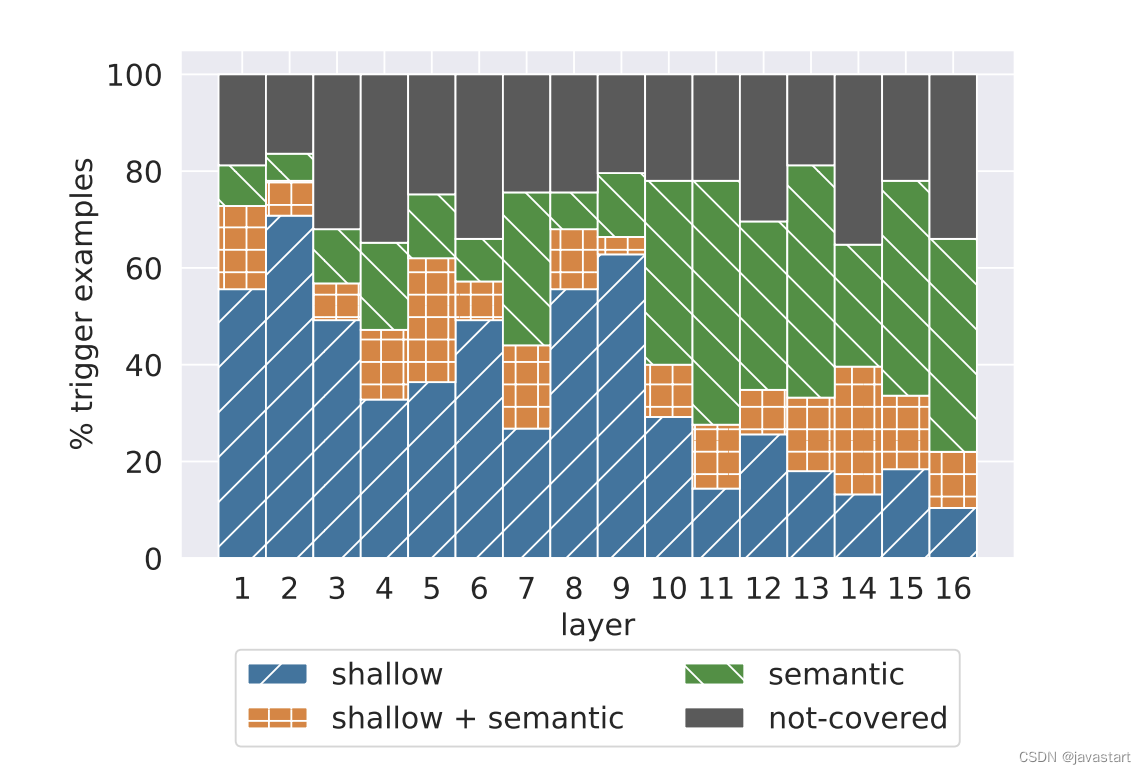
Para varias tareas de PNL, las características superficiales a menudo tienen "común", pero la principal diferencia radica en sus características semánticas profundas. Por lo tanto, al ajustar solo los parámetros de la capa completamente conectada de las últimas capas del Transformador, el efecto de ajuste fino del modelo de lenguaje grande se puede maximizar con la premisa de garantizar un ajuste fino eficiente de los parámetros.
4.3 Ventajas del método de ajuste fino Freeze
- Reduce en gran medida los parámetros de ajuste fino del modelo de lenguaje grande, que es un método de ajuste fino de parámetros eficientes;
- Dado que solo es necesario ajustar las características de alto nivel, se acelera la convergencia del modelo y se ahorra el tiempo de ajuste;
- La "comunidad" del lenguaje aprendido en el entrenamiento previo del modelo de lenguaje grande se conserva en la mayor medida y la interpretabilidad es sólida.
5. Resumen de los puntos clave de conocimiento
- Durante el ajuste fino supervisado de SFT, la tasa de aprendizaje suele establecerse muy pequeña
Malentendidos comunes: 1. El ajuste fino supervisado requiere mucho tiempo de entrenamiento y datos 2. El ajuste fino supervisado copiará todos los parámetros del modelo de origen al modelo de destino 3. El ajuste fino supervisado solo necesita docenas de datos supervisados
- Tareas comunes supervisadas y ajustadas: 1. Usar el modelo BERT preentrenado chino para completar la tarea de reconocimiento de entidades chinas 2. Entrenar el modelo de idioma GPT3 3. Ajustar el modelo UIE en el conjunto de datos en el campo vertical
Malentendido común: el modelo preentrenado en ImageNet se usa para entrenar la tarea de detección de objetivos (no)
- Actualmente, los principales métodos de supervisión de SFT incluyen: LoRA, P-tuning v2, Freeze
- Los parámetros del modelo previamente entrenados del método de ajuste fino de LoRA no participan en el ajuste fino. El método de ajuste fino de LoRA generalmente agrega nuevos parámetros en cada capa. La idea central del método de ajuste fino de LoRA es utilice la descomposición del rango de la matriz de orden superior para reducir la cantidad de parámetros de ajuste fino.
- Ventajas del método de ajuste fino de LoRA: reduzca la cantidad de parámetros para el ajuste fino del modelo de preentrenamiento de idiomas grandes, ahorre costos y obtenga resultados similares a los del ajuste fino del modelo completo
- El método de ajuste fino de LoRA no utiliza la descomposición de rangos para cada matriz de peso de Transformer.
- El método de ajuste fino P-tuning v2 introduce la idea de ajuste de prefijo sobre la base de P-tuning v1
Malentendidos comunes: 1. El método de ajuste fino P-tuning v1 puede ajustar la tarea de reconocimiento de entidades, 2. El efecto del método de ajuste fino P-tuning v1 se puede comparar con el método de ajuste fino de parámetros completos 3 El método de ajuste fino P-tuning v2 se puede utilizar para tareas de comprensión del lenguaje natural bajo rendimiento
- Principio del método de ajuste fino P-tuning v2: 1. El método de ajuste fino P-tuning v2 agrega un prefijo a cada capa del transformador, 2. El método de ajuste fino P-tuning v2 utiliza aprendizaje multitarea, 3. Ajuste P Método de ajuste fino v2 Los parámetros de la parte del prefijo no se ingresan mediante la salida del prefijo de la capa anterior
Malentendido común: el objeto de parámetro del método de ajuste fino P-tuning v2 es el prefijo de la representación discreta de cada capa
- El método de ajuste fino P-tuning v2 resuelve los problemas de las tareas de etiquetado de secuencias deficientes y la escasa universalidad en el método de ajuste fino P-tuning v1.
- Ventajas del ajuste fino de Freeze: 1. El método de ajuste fino de Freeze es un método de ajuste fino de parámetros eficientes 2. Las últimas capas del modelo de lenguaje grande extraen principalmente características semánticas, y las primeras capas extraen principalmente las características superficiales del texto 3. Los parámetros completos de la capa de conexión del transformador son más que parámetros de la capa de autoatención