prefacio
Continuando con lo anterior, ya podemos usar la función de generación de texto de bloom a través de ejemplos simples ¿Cuáles son las estrategias específicas para la generación de texto? ¿Cómo controlamos la floración para generar el efecto que queremos? Este artículo comenzará con la estrategia de decodificación e introducirá las dos estrategias más básicas: búsqueda codiciosa (búsqueda codiciosa) y búsqueda de haz (búsqueda de haz de partículas).
búsqueda codiciosa
La estrategia de búsqueda voraz es muy simple. Como las palabras se generan una por una, después de cada palabra generada, seleccione la palabra con la probabilidad calculada más alta y conéctelas. Aquí cito la imagen de otra persona: La entrada es El, el
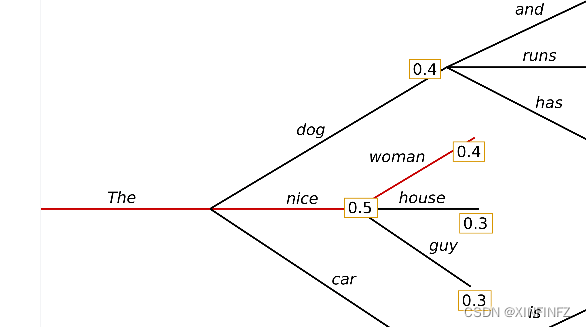
primero la elección es agradable con la probabilidad más alta de 0,5, y la segunda opción es la mujer con la probabilidad más alta de 0,4 en esta rama, y la probabilidad total de la rama es 0,5x0,4=0,2.
Un ejemplo de model.generate utilizando cara abrazada es el siguiente:
from transformers import AutoModelForCausalLM, AutoTokenizer
import time
a1 = time.time()
checkpoint = "bigscience/bloom-1b1"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForCausalLM.from_pretrained(checkpoint)
inputs = tokenizer.encode("我和我的猫都很想你", return_tensors="pt") #prompt
outputs = model.generate(inputs,min_length=150,max_length=200)
print(tokenizer.decode(outputs[0])) #使用tokenizer对生成结果进行解码
a2 = time.time()
print(f'time cost is {
a2 - a1} s')
Tenga en cuenta que en este ejemplo solo se utilizan los dos parámetros min_length y max_length. La búsqueda codiciosa se utilizará cuando no se establezcan otros parámetros que afecten a la estrategia de forma predeterminada.
El efecto generado es el siguiente:

Se puede encontrar que era normal al principio, y luego se convirtió en una repetición sin sentido.Esta es la desventaja más obvia de usar esta estrategia.
búsqueda de haz de partículas
Haz de partículas, como su nombre indica, es la probabilidad conjunta de una oración completa.Aquí asumimos primero que num_beams=2, es decir, el caso de dos haces de partículas: se puede ver que la línea sólida con la probabilidad más alta es
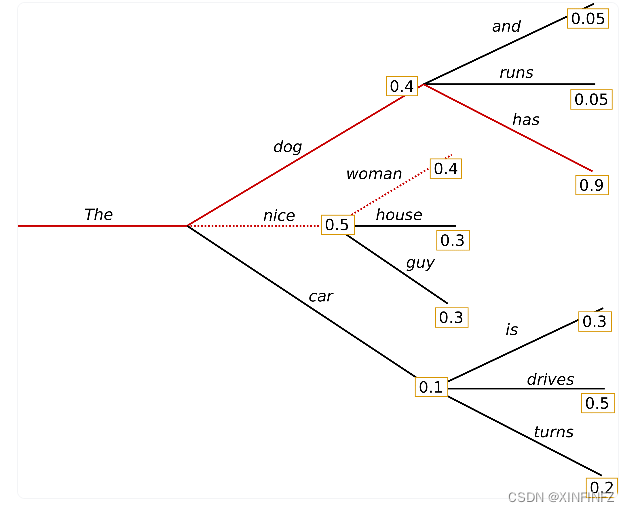
0.4 *0.9=0.36, que es más alto que lo que usamos originalmente. La probabilidad de la línea punteada de 0.2 obtenida por la búsqueda codiciosa es más alta, y el beneficio de la búsqueda por haz de partículas está aquí. Las palabras con alta probabilidad se pueden considerar más adelante, como tiene una probabilidad de 0.9 aquí. Por supuesto, la búsqueda del haz de partículas es esencialmente solo una parte limitada de la búsqueda en anchura . Es heurística y no puede obtener la solución óptima global, por lo que tiene los mismos problemas que debería.
Un ejemplo de model.generate utilizando cara abrazada es el siguiente:
outputs = model.generate(inputs,min_length=150,max_length=200,
num_beams=5,early_stopping=True)
La diferencia en el uso de la búsqueda codiciosa es solo establecer el número de num_beams y el mecanismo de parada anticipada. Cuando la detención temprana se establece en True, la búsqueda se detendrá una vez que num_beams encuentre suficientes haces candidatos. Si es False, se agregará una búsqueda heurística y la búsqueda se detendrá cuando sea poco probable encontrar un candidato. Si se establece en nunca, la búsqueda sólo se detendrá cuando se determine que no habrá mejores candidatos.
El efecto generado es el siguiente:

El efecto es muy pobre. No solo contiene repetición , sino que el tiempo es 30S más lento que antes . Aumentar num_beams puede mejorar el efecto, pero el aumento en el tiempo también se multiplica . Por ejemplo, el efecto cuando num_beams=10:

Búsqueda de haz de partículas restringida
Aquí solo presento dos técnicas, estableciendo condiciones para limitar el vocabulario repetido y forzando el vocabulario que queremos. Para obtener más técnicas, consulte la documentación de huggingface.
Limite las palabras repetidas:
outputs = model.generate(inputs,min_length=150,max_length=200,num_beams=5,
no_repeat_ngram_size=2,early_stopping=True)
Es decir, establezca el parámetro no_repeat_ngram_size para indicar el número máximo de palabras repetidas.
El efecto generado es el siguiente:
我和我的猫都很想你,想你的时候,我就会想起你。
猫咪,我爱你。 我爱你,我的小猫。
你是我生命中不可缺少的一部分,你是我生命中的阳光,你的出现,让我的生活多了一抹亮丽的色彩,使我的生命更加丰富多彩。
你的到来,给了我无尽的快乐和幸福,让我感到无比的幸福和快乐。
在你的陪伴下,我不再孤单,不再寂寞,我在你的怀抱中,感受到了家的温暖,感受到家的亲切,感到家的温馨。
我的生命因你而更加精彩,因为有了你的存在,使我的人生更加充实,更加有意义。
因为有你在我身边,我才感到生活的意义,才感到生命的价值。因为有你的相伴,我对生活充满了信心,对未来充满了希望。</s>
time cost is 97.57852363586426 s
Forzar la generación del vocabulario deseado:
from transformers import AutoModelForCausalLM, AutoTokenizer
import time
a1 = time.time()
checkpoint = "bigscience/bloom-1b1"
force_words = ["回家"] #强制词汇
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForCausalLM.from_pretrained(checkpoint)
force_words_ids = tokenizer(force_words, add_special_tokens=False).input_ids #装载
inputs = tokenizer.encode("我和我的猫都很想你", return_tensors="pt")
outputs = model.generate(inputs,force_words_ids=force_words_ids,min_length=150,max_length=200,num_beams=5,no_repeat_ngram_size=2,early_stopping=True)
print(tokenizer.decode(outputs[0]))
a2 = time.time()
print(f'time cost is {
a2 - a1} s')
Aquí forzamos las historias generadas para que contengan vocabulario casero y luego usamos force_words_ids para controlar.
El efecto generado es el siguiente:
我和我的猫都很想你。 猫咪:你什么时候回来?
狗狗:明天。 我:哦,好。 明天,明天,我一定回来。
狗:好,再见。 小狗:再见,小猫。 你什么时候回家? 小猫:今天。 今天,今天,我今天一定回家。
天黑了,狗和猫都睡着了。 一天过去了,猫和狗都睡得香甜。
第二天一大早,天刚蒙蒙亮,就听见狗的叫声,原来是猫回来了。
狗对猫说:"猫,你今天怎么这么晚才回家呢?"
猫对狗说:"我昨天晚上没睡好觉,所以今天才迟到。"
狗说:"那你为什么不早一点回来呢?""我明天还要上班呢!"
猫回答道。 "上班?"
狗又问道,"你明天要上班吗?" "是的,我要上班。""那为什么还迟迟不回来?" "我怕
time cost is 115.72432279586792 s
Se puede ver que toda la historia se genera de acuerdo con nuestros requisitos.
posdata
Presentaremos más estrategias de decodificación en el próximo número. Tardo mucho en actualizar porque la semana pasada me dio gripe A que es mas incomoda que la corona nueva.. Recomiendo tomar oseltamivir cuanto antes si te da.Si tienes la misma enfermedad de base (faringitis) que yo , puede tomarlo al mismo tiempo La amoxicilina es antibacteriana.
cita
https://huggingface.co/blog/how-to-generate
https://huggingface.co/docs/transformers/generation_strategies
https://huggingface.co/blog/constrained-beam-search