El 17 de enero se llevaron a cabo en Shanghai la conferencia de prensa de Scholar Puyuan 2.0 (InternLM2) y la ceremonia de lanzamiento del Scholar Puyuan Large Model Challenge. El Laboratorio de Inteligencia Artificial de Shanghai y SenseTime, junto con la Universidad China de Hong Kong y la Universidad de Fudan, lanzaron oficialmente la nueva generación del gran modelo de lenguaje académico Puyu 2.0 (InternLM2) .

Dirección de código abierto
- Github: https://github.com/InternLM/InternLM
- HuggingFace: https://huggingface.co/internlm
- ModelScope: https://modelscope.cn/organization/Shanghai_AI_Laboratory
Según los informes, InternLM2 se entrenó con un corpus de alta calidad de 2,6 billones de tokens. Siguiendo la configuración del académico de primera generación Puyu (InternLM), InternLM2 incluye dos especificaciones de parámetros de 7B y 20B, así como versiones base y de diálogo para satisfacer las necesidades de diferentes escenarios de aplicaciones complejas. Siguiendo el concepto de "potenciar la innovación con código abierto de alta calidad", el Laboratorio de IA de Shanghai continúa proporcionando licencia comercial gratuita para InternLM2.
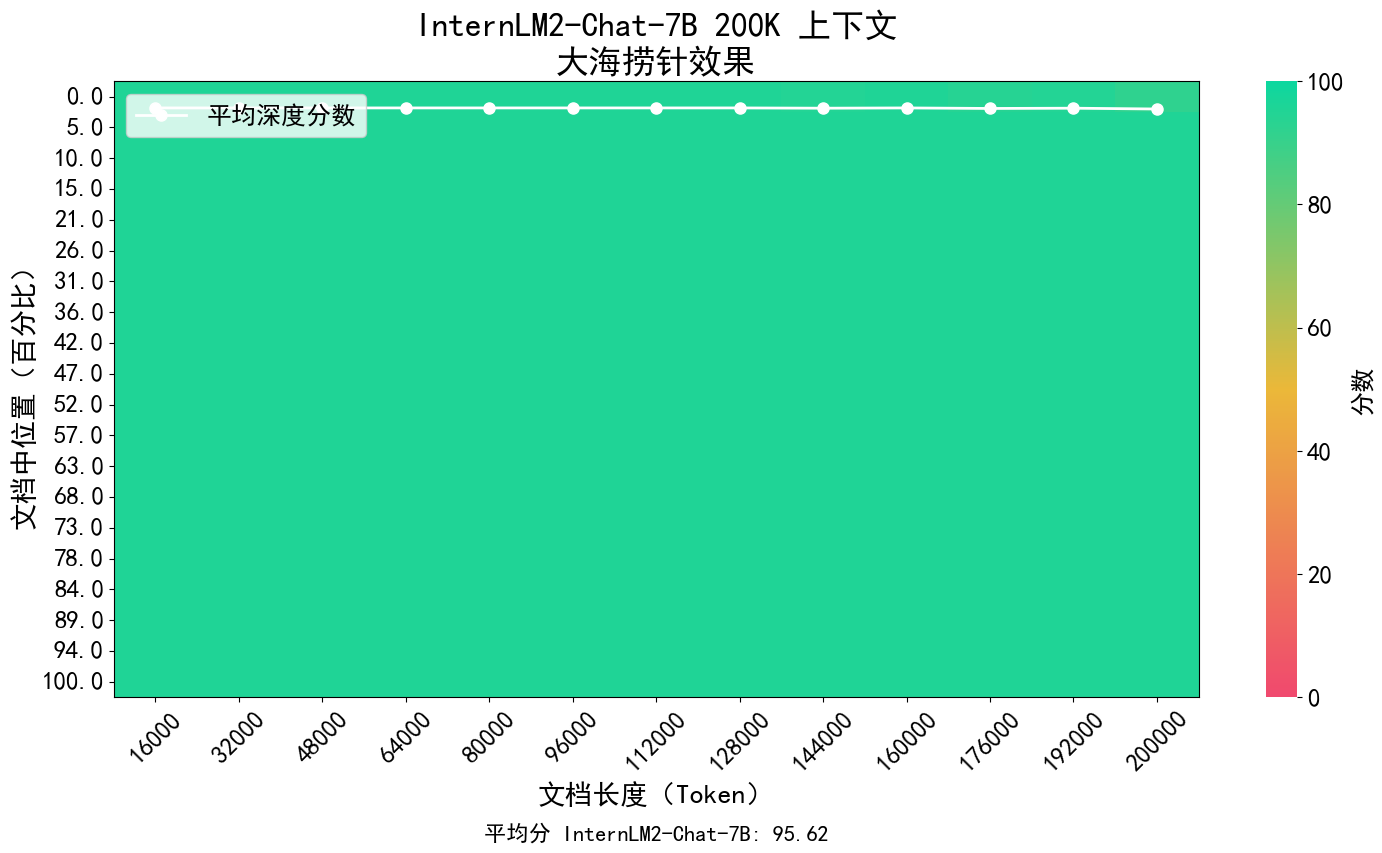
El concepto central de InternLM2 es volver a la esencia del modelado del lenguaje y se compromete a lograr una mejora cualitativa en las capacidades de modelado del lenguaje de la base del modelo mejorando la calidad del corpus y la densidad de la información, y luego lograr grandes avances en matemáticas. codificación, diálogo, creación, etc. Se han logrado avances y el rendimiento integral ha alcanzado el nivel líder de modelos de código abierto de la misma magnitud. Admite el contexto de 200.000 tokens, recibe y procesa contenido de entrada de aproximadamente 300.000 caracteres chinos a la vez, extrae con precisión información clave y logra "encontrar la aguja en el pajar" de textos largos.
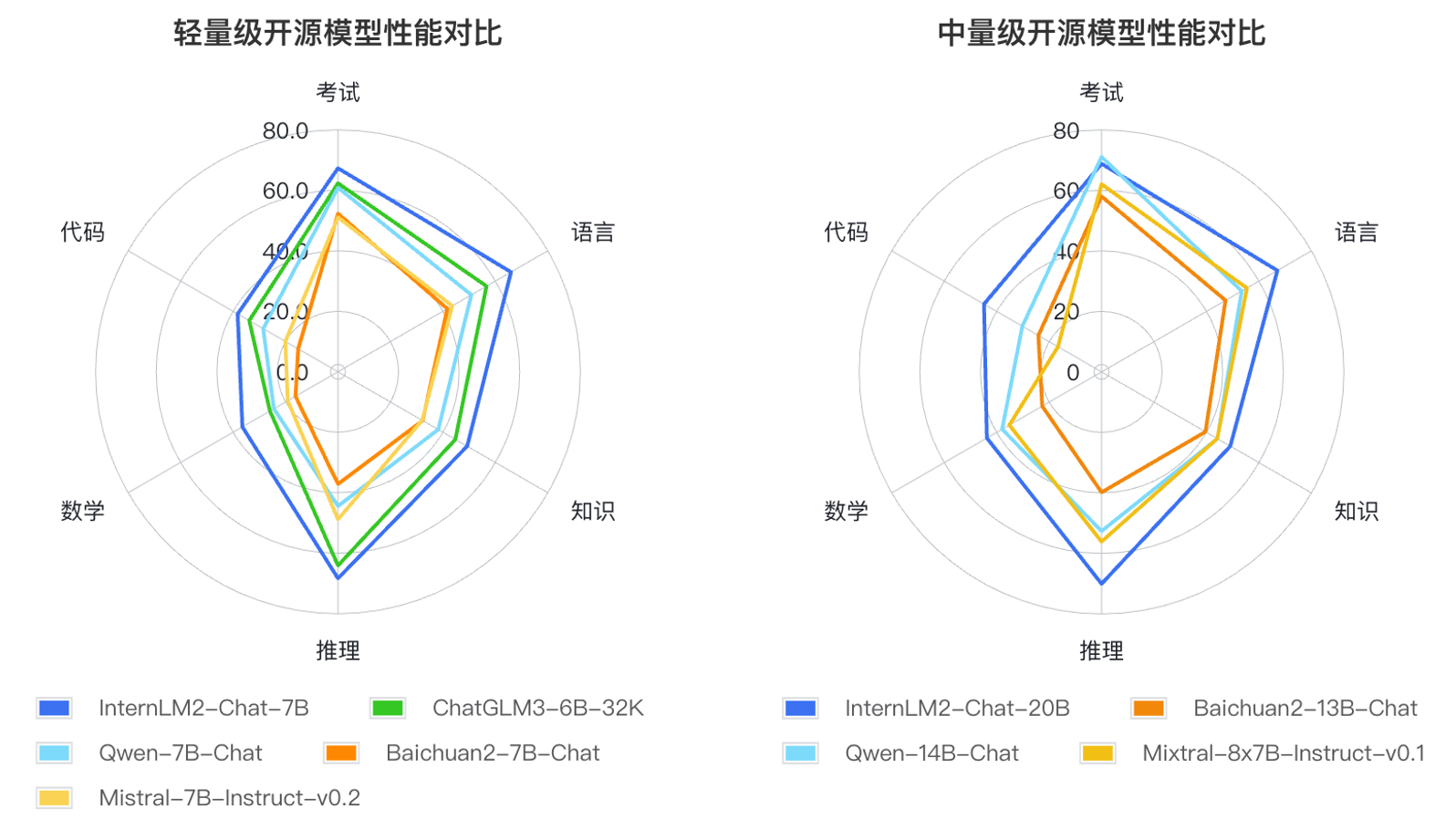
Además, InternLM2 ha logrado avances integrales en varias capacidades: en comparación con el InternLM de primera generación, sus capacidades en razonamiento, matemáticas, codificación, etc. se han mejorado significativamente y sus capacidades integrales están por delante del mismo nivel de modelos de código abierto.
Con base en los métodos de aplicación de grandes modelos de lenguaje y las áreas clave que preocupan a los usuarios, los investigadores definieron seis dimensiones de competencia, como lenguaje, conocimiento, razonamiento, matemáticas, código y examen, y probaron el desempeño de múltiples modelos de la misma magnitud en 55 conjuntos de evaluación convencionales. El desempeño se evaluó de manera integral. Los resultados de la evaluación muestran que las versiones liviana (7B) y mediana (20B) de InternLM2 funcionan bien entre modelos del mismo tamaño.