escribir delante
Hola a todos, soy Liu Cong PNL.
En la era de los modelos grandes, no sólo los modelos grandes son cada vez más voluminosos, sino que también las revisiones relacionadas con los modelos grandes son cada vez más voluminosas. Hoy les traigo la última revisión del ajuste de instrucciones para modelos de lenguaje grandes. El nombre completo es "Ajuste de instrucciones para modelos de lenguaje grandes: una encuesta", que proviene de Zhihu @ Turtle Shell.
Paper: https://arxiv.org/pdf/2308.10792.pdf
知乎:https://zhuanlan.zhihu.com/p/656733177El ajuste de instrucciones (TI) es una tecnología clave para mejorar la capacidad y la controlabilidad de grandes modelos de lenguaje. Esta revisión presenta principalmente la metodología general de TI, la construcción de conjuntos de datos de TI, el entrenamiento de modelos de TI, la aplicación de diferentes modos, dominios y aplicaciones, así como el análisis de aspectos que afectan los resultados de TI (por ejemplo, generación de instrucción). producción, tamaño del conjunto de instrucciones, etc.), también revisa las posibles deficiencias de la TI y sus críticas, señala las deficiencias de las estrategias existentes y propone algunas vías de investigación fructíferas.
¡Advertencia de artículo largo! ¡Se recomienda leerlo lentamente después de recolectarlo! !
1. Introducción
En los últimos años, la investigación sobre grandes modelos de lenguaje (LLM) ha logrado avances significativos. Un problema importante de los LLM es la falta de coincidencia entre los objetivos de capacitación y los objetivos del usuario: los LLM generalmente realizan predicciones contextuales de palabras en grandes corpus para minimizar los errores. modelo para que siga sus instrucciones de forma "útil y segura". Para resolver este problema, se propone la tecnología de ajuste de instrucciones, que es una tecnología eficaz para mejorar la capacidad y la controlabilidad de modelos de lenguaje grandes. Implica una capacitación adicional de los LLM utilizando (Instrucción, salida), donde Instrucción representa las instrucciones manuales para el modelo y salida representa la salida esperada correspondiente a la instrucción. Los beneficios de la TI son triples: (1) el ajuste fino de los LLM en el conjunto de datos de instrucciones cierra la brecha entre el objetivo de los LLM de predecir la siguiente palabra y el objetivo del usuario de seguir instrucciones; (2) En comparación con los LLM estándar, la TI permite Comportamiento del modelo más confiable, controlable y predecible. La función de las instrucciones es restringir la salida del modelo para que se ajuste a las características de respuesta esperadas o al conocimiento del dominio, y proporciona un canal para que los humanos intervengan en el comportamiento del modelo; (3) la TI es computacionalmente eficiente y puede ayudar Los LLM se adaptan rápidamente a campos específicos sin requerir una gran cantidad de reentrenamiento o cambios de arquitectura.
A pesar de su eficacia, la TI también plantea una serie de desafíos: (1) Producir instrucciones de alta calidad que cubran adecuadamente el comportamiento objetivo previsto no es trivial: los conjuntos de datos de instrucción existentes a menudo son inferiores en número, variedad y creatividad limitada; (2 ) existe una creciente preocupación de que TI solo mejore en tareas que están fuertemente respaldadas por conjuntos de datos de capacitación de TI; (3) TI solo puede capturar patrones y estilos superficiales en lugar de comprender y aprender tareas, lo que siempre es un fuerte crítico. Mejorar el cumplimiento de las instrucciones y manejar respuestas modelo inesperadas siguen siendo preguntas de investigación abiertas. Estos desafíos resaltan la importancia de una mayor investigación, análisis y resumen en esta área para optimizar el proceso de ajuste y comprender mejor el comportamiento de los LLM ajustados por instrucción.
2. Métodos de investigación
2.1 Construcción del conjunto de datos de instrucciones
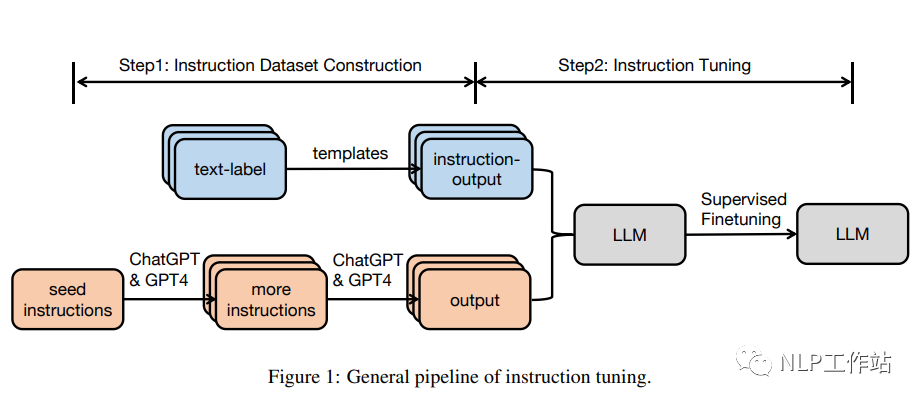
Cada instancia del conjunto de datos de instrucciones consta de tres elementos: una instrucción, que es una secuencia de texto en lenguaje natural que especifica una tarea (por ejemplo, escribir una carta de agradecimiento a XX por XX, escribir un blog sobre un tema XX, etc.) ; Una entrada opcional que proporciona información complementaria al contexto y el resultado esperado según la directiva y la entrada.
Generalmente hay dos formas de construir un conjunto de datos de instrucciones:
Integre datos de conjuntos de datos anotados en lenguaje natural. En este enfoque, los pares de etiquetas de texto se convierten en pares (instrucción, salida) mediante plantillas.
Utilice LLM para generar resultados: dadas las instrucciones, utilice LLM, como GPT-3.5-Turbo o GPT4, para generar resultados rápidamente. Las instrucciones provienen de dos fuentes: (1) recopilación manual; (2) uso de llm para ampliar una pequeña instrucción semilla escrita a mano. A continuación, envíe las instrucciones recopiladas a llm para obtener el resultado.
2.2 Ajuste de instrucciones
Con base en el conjunto de datos de TI recopilados, un modelo previamente entrenado se puede ajustar directamente de manera totalmente supervisada, entrenando el modelo prediciendo cada token en las instrucciones y entradas dadas de salida.
3. Conjunto de datos
3.1 Instrucciones naturales
Natural Instrucciones es un conjunto de datos de instrucciones en inglés hecho a mano que contiene 193.000 instancias de 61 tareas diferentes de PNL. Los conjuntos de datos constan de "instrucciones" e "instancias". Cada instancia de una "instrucción" es una descripción de la tarea que consta de 7 partes: título, definición, cosas que se deben evitar, énfasis/advertencias, consejos, ejemplos positivos y ejemplos negativos. La subfigura (a) de la Figura 2 ofrece un ejemplo de una "instrucción". Una "instancia" consta de pares ("entrada", "salida"), que son datos de entrada y resultados textuales que siguen correctamente las instrucciones dadas. La subfigura (b) de la Figura 2 ofrece un ejemplo de esto.

3.2P3
P3 (Grupo público de indicaciones) es un conjunto de datos de ajuste fino de comandos creado a partir de 170 conjuntos de datos de PNL en inglés y 2052 indicaciones en inglés. Las indicaciones, a veces denominadas plantillas de tareas, son funciones que asignan instancias de datos en tareas tradicionales de PNL (por ejemplo, respuesta a preguntas, clasificación de texto) a pares de entrada-salida en lenguaje natural.
Cada instancia en P3 tiene tres componentes: "entradas", "opciones_respuestas" y "objetivos". La "entrada" es una secuencia de texto que describe la tarea en lenguaje natural (por ejemplo, "Si es cierto que le gusta Mary, ¿es también cierto que le gusta el gato de Mary?"). "Opciones de respuesta" es una lista de cadenas de texto que son respuestas apropiadas para una tarea determinada (por ejemplo, ["sí", "no", "indeterminado"]). "Objetivos" es una cadena de texto que es la respuesta correcta a una "entrada" determinada (por ejemplo, "sí"). El autor creó PromptSource, una herramienta para la creación colaborativa de indicaciones de alta calidad y un archivo de indicaciones de alta calidad de código abierto. El conjunto de datos P3 se construye muestreando aleatoriamente un mensaje a partir de múltiples mensajes en PromptSource y asignando cada instancia a un triple ("entrada", "elección de respuesta", "destino").
3.3xP3
xP3 (Grupo de mensajes públicos en varios idiomas) es un conjunto de datos de instrucción multilingüe que consta de 16 tareas diferentes en lenguaje natural en 46 idiomas. Cada instancia del conjunto de datos tiene dos componentes: "entrada" y "destino". La "entrada" es una descripción en lenguaje natural de la tarea. Los "objetivos" son los resultados textuales de seguir correctamente la directiva "entradas".
Los datos originales en xP3 provienen de tres fuentes: el conjunto de datos de instrucciones en inglés P3, 4 tareas implícitas en inglés en P3 (como traducción, síntesis de programas) y 30 conjuntos de datos de PNL multilingües. Los autores construyeron el conjunto de datos xP3 extrayendo plantillas de tareas escritas por humanos de PromptSource y luego completando las plantillas para convertir diferentes tareas de PNL en una formalización unificada. Por ejemplo, la plantilla de la tarea de razonamiento en lenguaje natural es la siguiente: "Si la premisa es verdadera, ¿la hipótesis también es verdadera?"; "Sí", "Posible", "No" son relativas a las etiquetas de la tarea original " Implicación (0)", "Neutralidad (1)" y "Contradicción (2)".
3.4 Flan 2021
Flan 2021 es un conjunto de datos de instrucción en inglés creado mediante la conversión de 62 puntos de referencia de PNL ampliamente utilizados (como SST-2, SNLI, AG News, MultiRC) en pares de entrada y salida de idiomas. Cada instancia de Flan 2021 tiene componentes de "entrada" y "destino". Una "entrada" es una secuencia de texto que describe una tarea mediante instrucciones en lenguaje natural (por ejemplo, "Determinar el sentimiento de la oración 'Le gustan los gatos'. ¿Positivo o negativo?"). "Objetivo" es el resultado textual de ejecutar correctamente la instrucción de "entrada" (por ejemplo, "positivo"). Convierta conjuntos de datos tradicionales de procesamiento de lenguaje natural en pares de entrada-destino: Paso 1: escriba manualmente instrucciones y plantillas de destino; Paso 2: complete las plantillas con instancias de datos del conjunto de datos.
3.5 Instrucciones antinaturales
Unnatural Instrucciones es un conjunto de instrucciones con aproximadamente 240.000 instancias, creado con InstructGPT (text-davinci-002). Cada instancia del conjunto de datos tiene cuatro componentes: instrucciones, entradas, restricciones y salidas. Las "instrucciones" son descripciones de tareas de enseñanza en lenguaje natural. Una entrada en lenguaje natural es un parámetro utilizado para crear una instancia de una tarea de instrucción. Las restricciones son límites en el espacio de salida de la tarea. La salida es una secuencia de texto que ejecuta correctamente las instrucciones dadas los parámetros y restricciones de entrada. Los autores primero toman muestras de instrucciones iniciales de un conjunto de datos de instrucciones paranormales construido manualmente. Luego, propusieron a InstructGPT introducir un nuevo par (instrucción, entrada, restricción), que contiene tres instrucciones semilla a modo de demostración. A continuación, los autores ampliaron el conjunto de datos reescribiendo instrucciones o entradas aleatoriamente. Las conexiones de instrucciones, entradas y restricciones se introducen en InstructGPT para obtener resultados.
3.6 Autoinstrucción
Self-Instruct (Wang et al., 2022c) es un conjunto de datos de enseñanza de inglés creado con InstructGPT y que contiene 52.000 instrucciones de entrenamiento y 252 instrucciones de evaluación. Cada instancia de datos consta de "instrucciones", "entradas" y "salidas". Las "instrucciones" son definiciones de tareas en lenguaje natural (por ejemplo, "Responda las siguientes preguntas"). "Entrada" es opcional y se utiliza como contenido complementario a la descripción (por ejemplo, "¿La capital de qué país es Beijing?"), y "salida" es un resultado de texto que coincide con la descripción (por ejemplo, "Beijing"). Genere el conjunto de datos completo de acuerdo con los siguientes pasos:
Paso 1: el autor seleccionó al azar 8 instrucciones en lenguaje natural de 175 tareas iniciales como ejemplos y solicitó a InstructGPT que generara más instrucciones de tareas.
Paso 2: el autor determina si la instrucción generada en el paso 1 es una tarea de clasificación. Si es así, le piden a InstructGPT que genere todas las opciones posibles de salida según las instrucciones dadas, y seleccionan aleatoriamente una categoría de salida específica, lo que solicita a InstructGPT que genere el contenido de "entrada" correspondiente. Debería haber numerosas opciones de "salida" para instrucciones que no son tareas clasificadas. El autor propuso una estrategia de "entrada primero", que primero solicita a InstructGPT que genere "entradas" basadas en las "instrucciones" dadas, y luego genera "salidas" basadas en las "instrucciones" y las "entradas" generadas.
Paso 3: según los resultados del paso 2, el autor utiliza InstructGPT para generar la "entrada" y la "salida" de la tarea de instrucción correspondiente, utilizando la estrategia "salida primero" o "entrada primero".
Paso 4: el autor realizó un posprocesamiento de las tareas de instrucción generadas (por ejemplo, filtrar instrucciones similares, eliminar datos de entrada y salida duplicados) y finalmente obtuvo 52K instrucciones en inglés.
3.7 Evol-Instrucción
Evol-Instruct es un conjunto de datos de instrucción en inglés que consta de un conjunto de entrenamiento de 52.000 instrucciones y un conjunto de evaluación de 218 instrucciones. Los autores solicitaron a ChatGPT (OpenAI, 2022) que reescribiera instrucciones utilizando estrategias de evolución profundas e impresionantes. La estrategia de evolución profunda incluye cinco tipos de operaciones: agregar restricciones, agregar pasos de razonamiento y aumentar la complejidad de la entrada. La estrategia de evolución inspiratoria actualiza instrucciones simples o las actualiza directamente a instrucciones complejas para generar una nueva instrucción para aumentar la diversidad. El autor utiliza primero pares de 52K (comando, respuesta) como conjunto inicial. Luego seleccionaron al azar una estrategia evolutiva y le pidieron a ChatGPT que reescribiera las instrucciones originales en función de la estrategia evolutiva elegida. Utilice ChatGPT y reglas para filtrar pares de instrucciones no evolucionadas y actualice el conjunto de datos con pares de instrucciones evolucionadas recién generados. Después de repetir el proceso anterior 4 veces, el autor recopiló 250.000 pares de instrucciones. Además del conjunto de capacitación, los autores también recopilaron 218 instrucciones generadas por humanos a partir de escenarios reales (por ejemplo, proyectos, plataformas y foros de código abierto), denominado conjunto de pruebas Evol-Instruct.
3.8 LIMA
LIMA es un conjunto de datos de instrucción en inglés que consta de un conjunto de entrenamiento con 1K instancias y un conjunto de prueba con 300 instancias. El conjunto de entrenamiento contiene 1K pares ("instrucción", "respuesta"). Para los datos de capacitación, el 75% de las muestras provienen de tres sitios web comunitarios de preguntas y respuestas (es decir, conjuntos de datos Stack Exchange, wikiHow y PushshiftReddit (Baumgartner et al., 2020)), y el 20% están codificados a mano por un grupo de autores inspirados por sus intereses. El 5% de las muestras provienen del conjunto de datos de Instrucciones Paranormales (Wang et al., 2022d). Para el conjunto de validación, los autores tomaron muestras de 50 instancias del conjunto escrito por los autores del Grupo A. El conjunto de pruebas contiene 300 ejemplos, el 76,7% de los cuales fueron obtenidos por otro grupo (escrito por los autores del Grupo B), el 23,3% de las muestras provienen del conjunto de datos Pushshift Reddit, que es una colección de preguntas y respuestas dentro de la comunidad de Reddit.
3.9 Instrucciones sobrenaturales
Supernatural Instrucciones (Wang et al., 2022f) es un conjunto de instrucciones multilingüe que consta de 1616 tareas de PNL y 5 millones de instancias de tareas, que cubren 76 tipos diferentes de tareas (por ejemplo, clasificación de texto, extracción de información, reescritura de texto, creación de texto, etc.) y 55 idiomas. . Cada tarea del conjunto de datos consta de una "instrucción" y una "instancia de tarea". En concreto, la "instrucción" consta de 3 partes: una "definición" que describe la tarea en lenguaje natural; un ejemplo positivo, es decir, una muestra de salida correcta, y dé una breve explicación de cada muestra, y "ejemplos negativos", es decir, muestras de entrada y salida no deseada, y una breve explicación de cada muestra, como se muestra en la Figura 3(a). Una "instancia de tarea" es una instancia de datos que consta de una entrada de texto y una lista de salidas de texto aceptables, como se muestra en la Figura 3(b). Los datos sin procesar en SupernaturalDirective provienen de tres fuentes: (1) conjuntos de datos públicos de PNL existentes (como CommonsenseQA); (2) anotaciones intermedias aplicables generadas a través de un proceso de crowdsourcing (por ejemplo, en el conjunto de datos de QA de crowdsourcing (interpretación de un problema determinado). ; (3) Tareas sintéticas, que se transforman a partir de tareas simbólicas y se expresan en unas pocas oraciones (como comparaciones numéricas y otras operaciones algebraicas).

3.10 plataforma rodante
Dolly es un conjunto de datos de instrucciones en inglés que contiene 15.000 ejemplos de datos generados por humanos y diseñados para permitir a los LLM interactuar con usuarios de forma similar a ChatGPT. Este conjunto de datos está diseñado para simular una amplia gama de comportamientos humanos e incluye 7 tipos específicos: preguntas y respuestas abiertas, preguntas y respuestas cerradas, extracción de información de Wikipedia, resumen de información de Wikipedia, lluvia de ideas, clasificación y escritura creativa. En la Tabla 2 se muestran ejemplos de cada tipo de tarea en el conjunto de datos.

3.11 Conversaciones de OpenAssistant
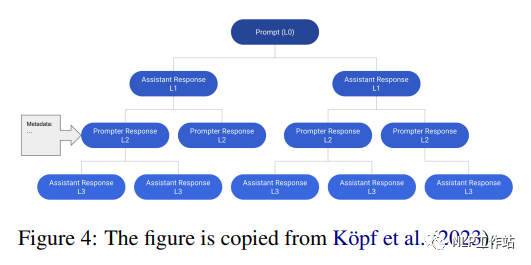
OpenAssistant Conversations es un corpus conversacional estilo asistente multilingüe construido por humanos que consta de 161,443 mensajes (es decir, 91,829 mensajes de usuario, 69,614 respuestas de asistente) de 66,497 árboles de conversación en 35 idiomas y 461,292 calificaciones masivas anotadas por humanos. Cada instancia del conjunto de datos es un árbol de conversación (CT). Específicamente, cada nodo en el árbol de sesión representa un mensaje generado por un rol en la sesión (es decir, mensaje, asistente). El nodo raíz del CT representa el aviso inicial del apuntador, mientras que los otros nodos representan las respuestas del apuntador o del asistente. La ruta desde la raíz a cualquier nodo en el CT representa una conversación válida entre el mensaje y el asistente en secuencia, denominada subproceso. La Figura 4 muestra un ejemplo de un árbol de sesión que contiene
12 mensajes en 6 hilos. El autor primero recopiló un árbol de diálogo basado en un proceso de cinco pasos:
Paso 1: Mensaje: los contribuyentes actúan como promotores y elaboran el mensaje inicial;
Paso 2: Etiquetar indicaciones: los participantes califican las indicaciones iniciales del primer paso y los autores seleccionan indicaciones de alta calidad como nodos raíz utilizando una estrategia de muestreo equilibrada;
Paso 3: expandir el nodo del árbol: el colaborador agrega un mensaje de respuesta como mensaje o asistente;
Paso 4: Anotación de respuesta: los contribuyentes califican las respuestas de los nodos existentes;
Paso 5: Clasificación: Clasifique a los contribuyentes de acuerdo con las Pautas para contribuyentes.
La máquina de estado del árbol gestiona y rastrea el estado (por ejemplo, estado inicial, estado de crecimiento, estado final) durante la construcción de la sesión. Posteriormente, el conjunto de datos OpenAssistantConversations se construye filtrando árboles de conversación ofensivos e inapropiados.
3.12 Sí
Baize (Conover et al., 2023b) es un corpus de chat de varios turnos en inglés creado con 111,5 000 instancias que utilizan ChatGPT. Cada ronda consta de las indicaciones del usuario y las respuestas del asistente. Cada instancia en Baize v1 contiene sesiones de 3,4 rondas. Para crear el conjunto de datos de Baize, los autores propusieron el autochat, donde ChatGPT se turna para desempeñar los roles de usuario y asistente de IA, y genera mensajes en forma de conversación. Específicamente, el autor primero diseñó una plantilla de tareas que definía los roles y tareas de ChatGPT (como se muestra en la Tabla 3). A continuación, tomaron muestras de preguntas (por ejemplo, "¿Cómo se arregla una cuenta de Google Play Store que no funciona?") de conjuntos de datos de Quora y Stack Overflow como semillas de conversación (por ejemplo, temas). Luego solicitaron a ChatGPT plantillas y semillas de muestra. ChatGPT genera continuamente mensajes para ambas partes hasta que llega a un punto de parada natural.

4. Instrucciones para perfeccionar los LLM

4.1 Instrucciones sobre GPT
InstructGPT (176B) (Ouyang et al., 2022) se inicializa utilizando GPT-3(176B) (Brown et al., 2020b) y luego se ajusta según instrucciones humanas. El proceso de ajuste incluye los siguientes tres pasos:
(1) Ajuste fino supervisado (SFT) de conjuntos de datos de instrucciones de filtrado manual basados en el historial de Playground API;
(2) Al muestrear manualmente múltiples respuestas a una instrucción y clasificarlas, se establece un modelo de recompensa basado en conjuntos de datos anotados para predecir las preferencias humanas;
(3) Utilice nuevas instrucciones para optimizar aún más el modelo en el paso 1 y el modelo de recompensa de entrenamiento en el paso 2. Los parámetros se actualizan utilizando el método de optimización de políticas próximas (PPO) (Schulman et al., 2017), que es un método de aprendizaje por refuerzo de gradiente de políticas. Los pasos (2) y (3) se alternan varias veces hasta que el rendimiento del modelo no mejora significativamente.
En general, InstructGPT es mejor que GPT-3. En términos de evaluación automática, InstructGPT es un 10% más veraz que GPT-3 en el conjunto de datos TruthfulQA (Lin et al., 2021) y más tóxico que GPT en el conjunto de datos RealToxicityPrompts (Gehman et al., 2020). 3 es un 7% más alto. En el conjunto de datos de PNL (es decir, WSC), InstructGPT logra un rendimiento comparable al de GPT-3. En la evaluación humana, InstructGPT superó a GPT-3 en un +10%, +20%, -20% y +10% en cuatro aspectos: seguir instrucciones correctas, seguir restricciones claras, reducir las alucinaciones y generar respuestas apropiadas.
4.2 FLORECIMIENTO
BLOOMZ (176B) (muenighoff et al., 2022) se inicializó con BLOOM(176B) (Scao et al., 2022) y luego se ajustó en el conjunto de datos de instrucciones xP3 (muenighoff et al., 2022), un modelo humano de 46 idiomas. Colección de conjuntos de datos de instrucciones, de dos fuentes:
(1) P3, que es un conjunto de pares (comando en inglés, respuesta en inglés);
(2) Un conjunto de (instrucciones en inglés, respuestas multilingües), convertido a partir de un conjunto de datos de PNL multilingüe (como el punto de referencia chino) completando la plantilla de tareas con instrucciones en inglés predefinidas.
En términos de evaluación automática, bajo la configuración de muestra cero, BLOOMZ mejoró en un 10,4%, 20,5% y 9,8% con respecto a BLOOM en resolución de correferencia, finalización de oraciones y conjuntos de datos de razonamiento en lenguaje natural, respectivamente. En el punto de referencia HumanEval (Chen et al., 2021), BLOOMZ obtuvo un rendimiento un 10 % mejor que BLOOM en términos de la métrica Pass@100. Para las tareas de generación, BLOOMZ logra una mejora BLEU del +9 % en comparación con BLOOM en el punto de referencia de evaluación de lm.
4.3 Flan-T5
FLAN-T5 (11B) es un modelo de lenguaje grande inicializado por T5 (11B) (Raffel et al., 2019) y luego ajustado en el conjunto de datos FLAN (Longpre et al., 2023). El conjunto de datos FLAN es un conjunto de pares (instrucción, par) compuesto por 62 conjuntos de datos para 12 tareas de PNL (como razonamiento en lenguaje natural, razonamiento de sentido común, generación de paráfrasis, etc.) completando varias plantillas de instrucciones bajo la tarea unificada. formalización Construcción. Durante el proceso de ajuste, FLAN-T5 ajustó el marco T5X basado en JAX para que cada 2k pasos, se seleccionara el modelo óptimo en función de las tareas de retención evaluadas. En comparación con la fase previa a la capacitación de T5, el ajuste fino requiere un 0,2% más de recursos informáticos (aproximadamente 128 chips TPU v4 y 37 horas). En términos de evaluación, FLAN-T5 (11B) supera al T5 (11B) y logra resultados comparables a modelos más grandes, incluido PaLM (60B) (Chowdhery et al., 2022) en una configuración de pocos disparos. En MMLU (Hendrycks et al., 2020), BBH (Suzgun et al., 2022), TyDiQA (Clark et al., 2020), MGSM (Shi et al., 2022), generación abierta y RealToxicityPrompts (Gehman et al. , 2022) 2020), FLAN-T5 superó a T5 en +18,9%, +12,3%, +4,1%, +5,8%, +2,1% y +8%. En algunos casos, FLAN-T5 supera a PaLM en un +1,4% y un +1,2% en los conjuntos de datos BBH y TyDiQA.
4.4 Alpacas
Alpaca (7B) (Taori et al., 2023) se construye ajustando LLaMA (7B) (Touvron et al., 2023a) en el conjunto de datos de instrucciones de compilación generado por InstructGPT (175B, text-davinci-003) (Ouyang et al., 2022) modelo de lenguaje entrenado. El proceso de ajuste tomó aproximadamente 3 horas en un dispositivo A100 de 80 GB con 8 tarjetas con entrenamiento de precisión mixta y paralelismo total de datos compartidos. En términos de evaluación humana, Alpaca (7B) logró un rendimiento comparable al de InstructGPT (175B, text-davinci-003). Específicamente, Alpaca supera a InstructGPT en el conjunto de datos autoguiado, logrando 90 instancias ganadoras en lugar de 89.
4.5 Vicuña
Vicuna (13B) (Chiang et al., 2023) es un modelo de lenguaje entrenado ajustando LLaMA (13B) (Touvron et al., 2023a) en el conjunto de datos de conversación generado por ChatGPT. El autor recopiló sesiones de ChatGPT compartidas por usuarios del sitio web http://ShareGPT.com y, después de filtrar muestras de baja calidad, se obtuvieron 70.000 registros de sesiones. LLaMA (13B) se ajusta en el conjunto de datos de sesión construido utilizando una función de pérdida modificada diseñada para sesiones de múltiples épocas. Para comprender mejor los contextos largos en conversaciones de varios turnos, los autores amplían la longitud máxima del contexto de 512 a 2048. En términos de capacitación, el autor utiliza las tecnologías de punto de control de gradiente y atención flash (Dao et al., 2022) para reducir los costos de memoria de la GPU durante el ajuste fino. En un dispositivo A100 de 8×80 GB con paralelismo total de datos compartidos, el proceso de ajuste tomó 24 horas. Los autores crearon un conjunto de pruebas diseñado específicamente para medir el rendimiento del chatbot. Recopilaron un conjunto de pruebas que consta de 8 categorías de problemas, como problemas de Fermi, escenarios de juegos de roles, tareas de programación/matemáticas, etc., y luego le pidieron a GP-4 (OpenAI, 2023) que considerara la utilidad, relevancia, precisión y detalle. para evaluar las respuestas del modelo. En el conjunto de prueba construido, Vicuña (13B) supera a Alpaca (13B) (Taori et al., 2023) y LLaMA (13B) produce igual o mejor que ChatGPT en el 90% de los problemas de prueba en el 45% de las respuestas de calificación de problemas. .
4.6 GPT-4-LLM
GPT-4-LLM(7B) (Peng et al., 2023) es un lenguaje entrenado ajustando LLaMA (7B) (Touvron et al., 2023a) en el conjunto de datos de instrucciones generado por GPT-4 (OpenAI, 2023 ) Modelo. GPT-4-LLM se inicializa con LLaMA y luego se ajusta en los dos pasos siguientes:
Ajuste supervisado de conjuntos de datos de instrucciones construidos. Los autores utilizaron las instrucciones de Alpaca (Taori et al., 2023) y luego utilizaron GPT-4 para recopilar comentarios. LLaMA está optimizado en el conjunto de datos generado por GPT-4. El proceso de ajuste tomó aproximadamente 3 horas en una máquina de 8*80GBA100 con precisión mixta y paralelismo total de datos compartidos.
Utilizando el método de optimización de políticas proximales (PPO) (Schulman et al., 2017) para optimizar el modelo del paso 1, el autor primero recopiló GPT-4, InstructGPT (Ouyang et al., 2022) y OPT-IML (Iyer et al. ., 2022) para crear un conjunto de datos de comparación y luego dejar que GPT-4 califique cada respuesta del 1 al 10. Utilice calificaciones para entrenar un modelo de recompensa basado en OPT (Zhang et al., 2022a). Utilice el modelo de recompensa para calcular el gradiente de la política para optimizar el modelo ajustado en el paso 1.
En términos de evaluación, GPT-4-LLM (7B) no solo supera al modelo básico Alpaca (7B), sino también a modelos más grandes, incluidos Alpaca (13B) y LLAMA (13B). En términos de evaluación automática, GPT-4-LLM (7B) tiene el mejor rendimiento en Instrucciones orientadas al usuario-252 (Wang et al., 2022c), Instrucciones de vicuña (Chiang et al., 2023) e Instrucciones no naturales ( Honovich et al., 2022) el conjunto de datos es 0,2, 0,5 y 0,7 veces mayor que el de Alpaca, respectivamente. En términos de evaluación humana, el desempeño de GPT-4-LLM en utilidad, sinceridad e inofensividad es 11,7, 20,9 y 28,6 mayor que el de Alpaca, respectivamente.
4.7 Claudio
Claude es un modelo de lenguaje que se entrena ajustando un modelo de lenguaje previamente entrenado en un conjunto de datos de instrucciones, con el objetivo de generar respuestas útiles e inofensivas. El proceso de ajuste consta de dos etapas:
(1) Supervisar el ajuste fino del conjunto de datos de instrucciones. Los autores crearon un conjunto de datos de instrucciones recopilando 52.000 instrucciones diferentes y emparejándolas con respuestas generadas por GPT-4. El proceso de ajuste tomó aproximadamente 8 horas en una máquina A100 de 80 GB con 8 tarjetas con precisión mixta y paralelismo total de datos compartidos.
(2) Utilice el método de optimización de la estrategia proximal para optimizar el modelo del paso 1. Los autores primero construyen un conjunto de datos de comparación recopilando las respuestas de múltiples modelos de lenguaje grandes (como GPT-3) a un conjunto de instrucciones determinado y luego dejando que GPT-4 califique cada respuesta. Utilizando calificaciones, se entrena un modelo de recompensa. Luego, el modelo de recompensa y el método de optimización de políticas proximales se utilizan para optimizar el modelo de ajuste fino en el paso 1. Claude produjo respuestas más beneficiosas e inofensivas que el modelo de columna vertebral.
En términos de evaluación automática, el rendimiento de toxicidad de Claude en RealToxicityPrompts es un 7% mayor que el de GPT-3. Para la evaluación humana, Claude superó a GPT-3 en +10%, +20%, -20%, respectivamente, en cuatro aspectos diferentes, incluido seguir instrucciones correctas, seguir restricciones claras, reducir las alucinaciones y generar respuestas apropiadas.+10%.
4.8 AsistenteLM
WizardLM (7B) (Xu et al., 2023a) es un modelo de lenguaje entrenado ajustando LLaMA(7B) en el conjunto de datos de instrucciones Evol-Instruct generado por ChatGPT. Está ajustado en un subconjunto (70K) de Evol-Instruct para proporcionar una comparación justa con Vicuña. Basado en la GPU V100 de 8 tarjetas basada en la tecnología Deepspeed Zero-3, el ajuste fino durante 3 épocas lleva aproximadamente 70 horas. Durante la inferencia, la longitud máxima generada es 2048. Para evaluar el rendimiento de los LLM en instrucciones complejas, los autores recopilaron 218 instrucciones generadas por humanos a partir de escenarios reales (por ejemplo, proyectos, plataformas y foros de código abierto), denominado conjunto de pruebas Evol-Instruct.
Evaluado en el equipo de prueba Evol-Instruct y el equipo de prueba Vicuna. En términos de evaluación humana, WizardLM superó ampliamente a Alpaca (7B) y Vicuña (7B), produciendo la misma o mejor respuesta que ChatGPT en el 67% de las muestras de prueba. La evaluación automatizada se logra haciendo que GPT-4 califique las respuestas de los LLM. Específicamente, en comparación con Alpaca, el rendimiento de WizardLM mejoró un 6,2 % y un 5,3 % en el conjunto de pruebas Evol-Instruct y Vicuna, respectivamente. En comparación con Vicuña, es un 5,8% más alto en el equipo de prueba Evol-Instruct y un 1,7% más alto en el equipo de prueba Vicuña.
4.9 ChatGLM2
ChatGLM2 (6B) (Du et al., 2022) es un modelo de lenguaje entrenado ajustando GLM (6B) (Du et al., 2022) en un conjunto de datos bilingüe que contiene instrucciones en chino e inglés. El conjunto de datos de instrucción bilingüe contiene 1,4 T de tokens con una proporción inglés-chino de 1:1. Las instrucciones del conjunto de datos se extraen de tareas de respuesta a preguntas y finalización de conversaciones. ChatGLM utiliza GLM para la inicialización y luego se entrena utilizando una estrategia de ajuste fino de tres pasos similar a InstructGPT (Ouyanget al., 2022). Para simular mejor la información contextual en conversaciones de varios turnos, los autores amplían la longitud máxima del contexto de 1024 a 32K. Para reducir el costo de memoria de la etapa de ajuste fino de la GPU, se adoptan estrategias de atención de consultas múltiples y máscara causal. Durante el proceso de inferencia, ChatGLM2 que usa FP16 requiere 13 GB de memoria GPU. Después de usar la tecnología de cuantificación modelo INT4, se pueden usar 6 GB de memoria GPU para admitir sesiones de hasta 8K. Las evaluaciones se realizan en cuatro puntos de referencia en inglés y chino, incluidos MMLU (inglés), C-Eval (chino), GSM8K (matemáticas) y BBH (inglés). En todos los puntos de referencia, ChatGLM2 (6B) supera a GLM (6B) y al modelo básico ChatGLM (6B). Específicamente, ChatGLM2 es +3,1 mejor que GLM en MMLU, +5,0 mejor que GLM en C-Eval, +8,6 mejor que GLM en GSM8K y +2,2 mejor que GLM en BBH. En MMLU, C-Eval, GSM8K y BBH, el rendimiento de ChatGLM2 mejora en +2,1, +1,2, +0,4 y +0,8 respectivamente en comparación con ChatGLM.
4.10 LIMA
LIMA (65B) (Zhou et al., 2023) es un modelo de lenguaje grande entrenado mediante el ajuste fino de LLaMA (65B) (Touvron et al., 2023a) en el conjunto de datos de instrucciones, que se construye en base a la hipótesis de alineación de superficie propuesta. La suposición de alineación de superficie significa que el conocimiento y las capacidades del modelo se adquieren casi en la etapa previa al entrenamiento, mientras que el entrenamiento alineado (por ejemplo, ajuste de instrucciones) permitirá que el modelo responda en un estado formalizado preferido por el usuario. Con base en la hipótesis de alineación de superficie, los autores afirman que los modelos de lenguaje grandes pueden generar respuestas satisfactorias para el usuario mediante el ajuste de un pequeño conjunto de datos de instrucción. Por lo tanto, el autor construyó el conjunto de entrenamiento de instrucción/conjunto válido/conjunto de prueba para verificar esta hipótesis. Evaluar el conjunto de prueba construido. En términos de evaluación humana, LIMA se desempeña un 17% y un 19% mejor que InstructGPT y Alpaca respectivamente. Además, LIMA logró resultados comparables con BARD, Cladue y GP-4. Para la evaluación automática, que se realiza pidiendo a GPT-4 que califique las respuestas, donde las puntuaciones más altas indican un mejor rendimiento, LIMA supera a InstructGPT y Alpaca en un 20 % y 36 % respectivamente, logrando resultados comparables con BARD, aunque menos efectivo que Claude y GP. -4. Los resultados experimentales validan la hipótesis de alineación de superficies propuesta.
4.11 Otros
También existen algunos otros modelos, sin entrar mucho en detalles, los modelos son los siguientes:
OPT-IML (175B)
Plataforma rodante 2.0 (12B)
Instrucción Halcón (40B)
Guanaco (7B)
Minotauro (15B)
Nosotros-Herme (13B)
TÜLU (6.7B)
YuLan-Chat (13B)
MUSGO (16B)
Airóboros (13B)
UltraLM (13B)
5. Ajuste fino de la instrucción multimodal
5.1 Conjuntos de datos multimodales

MUL-TIINSTRUCT (Xu et al., 2022) es un conjunto de datos de ajuste de instrucciones multimodal que consta de 62 tareas multimodales diferentes en un formato unificado de secuencia a secuencia. El conjunto de datos cubre 10 categorías principales y sus tareas se derivan de 21 conjuntos de datos de código abierto existentes. Cada misión viene con 5 instrucciones escritas por expertos. Para las tareas existentes, los autores crean instancias utilizando pares de entrada/salida de conjuntos de datos de código abierto disponibles para ellos. Para cada nueva tarea, los autores crearon entre 5.000 y 5 millones de instancias extrayendo la información necesaria de instancias de tareas existentes o reconstruyéndolas. Se verifica la eficacia del conjunto de datos MUL-TIINSTRUCT para mejorar diversas técnicas de aprendizaje por transferencia. Por ejemplo, ajustar el modelo OFA (930M) utilizando múltiples estrategias de aprendizaje por transferencia, como el ajuste de instrucción híbrida y el ajuste de instrucción secuencial en MUL-TIINSTRUCT (Wang et al., 2022a), puede mejorar el cero en todas las tareas invisibles. . En la tarea VQA normal, el OFA optimizado en MUL-TIINSTRUCT alcanza 50,60 en RougeL con una precisión de 31,17, mientras que el OFA RougeL original es 14,97 con una precisión de 0,40.
PMC-VQA (Zhang et al., 2023c) es un conjunto de datos de respuesta a preguntas visuales médicas a gran escala que contiene 227.000 pares de imágenes-preguntas de 149.000 imágenes, que cubren diversas modalidades o enfermedades. Este conjunto de datos se puede utilizar para tareas abiertas y de opción múltiple. El proceso para generar el conjunto de datos PMC-VQA incluye recopilar pares de imágenes y subtítulos del conjunto de datos PMC-OA (Lin et al., 2023), usar ChatGPT para generar pares de preguntas y respuestas y verificar manualmente la calidad de un subconjunto del conjunto de datos. . Los autores proponen MedVInT, un modelo de comprensión visual médica de base generativa que alinea la información visual con modelos de lenguaje grandes. MedVInT, previamente entrenado en PMC-VQA, logra un rendimiento de última generación y supera a los modelos existentes en los puntos de referencia VQA-rad (Lau et al., 2018) y SLAKE (Liu et al., 2021a), superando a los modelos existentes en VQA. -rad La precisión en SLAKE es del 81,6% y la precisión en SLAKE es del 88,0%.
LAMM (Yin et al., 2023) es un conjunto de datos integral multimodal ajustado por instrucciones para comprender imágenes 2D y nubes de puntos 3D. LAMM contiene pares de comando-respuesta de imagen de idioma de 186K y pares de comando-respuesta de nube de puntos de idioma de 10K. Los autores recopilan imágenes y nubes de puntos de conjuntos de datos disponibles públicamente y utilizan GPT-API y métodos de autoinstrucción para generar instrucciones y respuestas basadas en las etiquetas originales de estos conjuntos de datos. LAMM-Dataset incluye pares de datos para responder preguntas de conocimiento de sentido común mediante la integración del sistema de etiquetado de gráficos de conocimiento jerárquico y las correspondientes descripciones de Wikipedia del conjunto de datos Bamboo (Zhang et al., 2022b). Los autores también propusieron LAMM-Benchmark para evaluar el rendimiento de los modelos de lenguaje multimodal (MLLM) existentes en diversas tareas de visión por computadora. Incluye 9 tareas de imágenes públicas y 3 tareas de nubes de puntos públicas, así como el marco LAMM, que es un marco de capacitación principal de MLLM para distinguir entre codificador, proyector y bloques de ajuste fino de LLM para evitar conflictos modales entre diferentes modos.
5.2 Modelo de ajuste fino de instrucciones multimodal
InstructPix2Pix (983M) (Brooks et al., 2022) es un modelo de difusión condicional ajustado con Stable Diffusion (983M) (Rombach et al., 2022) en un conjunto de datos multimodal construido que contiene más de 450.000 textos Instrucciones de edición e imágenes correspondientes antes y después de editar. Los autores combinaron las capacidades de dos modelos preentrenados a gran escala, un modelo de lenguaje GPT-3 (Brown et al., 2020b) y un modelo de difusión estable de texto a imagen (Rombach et al., 2022), para generar el conjunto de datos de entrenamiento. GPT-3 está optimizado para generar ediciones de texto basadas en señales de imagen, y Difusión estable se utiliza para convertir ediciones de texto generadas en ediciones de imágenes reales. Luego, InstructPix2Pix se entrena en este conjunto de datos generado utilizando objetivos de difusión latentes. La Figura 5 muestra el proceso de generar un conjunto de datos de edición de imágenes y entrenar un modelo de difusión en este conjunto de datos. Los autores compararon cualitativamente el método propuesto en este artículo con trabajos anteriores como SDEdit (Meng et al., 2022) y Text2Live (Bar-Talet et al., 2022), enfatizando que el modelo sigue instrucciones de edición de imágenes en lugar de descripciones o Capacidad de edición de capas. Los autores también realizaron una comparación cuantitativa con SDEdit (Meng et al., 2022) mediante el uso de métricas que miden la consistencia de la imagen y la calidad de la edición.

LLaVA (13B) (Liu et al., 2023b) es un modelo grande multimodal que combina el codificador visual CLIP (400M) (Radford et al., 2021) con el decodificador de lenguaje LLaMA(7B) (Touvron et al., 2023a) desarrollado conectando. LLaVA se ajusta utilizando un conjunto de datos de lenguaje visual instruido generado que consta de 158.000 instrucciones de imágenes verbales únicas que siguen muestras. El proceso de recopilación de datos incluyó la creación de diálogos, descripciones detalladas y pautas de razonamiento complejas. GPT-4 se utiliza para convertir pares de imagen y texto a un formato de seguimiento de instrucciones apropiado para este conjunto de datos. Para codificar imágenes se utilizan características visuales como títulos y bordes. En comparación con GPT-4, LLaVA logra una puntuación relativa del 85,1 % en instrucciones multimodales sintéticas basadas en el conjunto de datos. Cuando se ajustó en Science QA, la sinergia de LLaVA y GPT-4 logró una precisión de última generación del 92,53%.
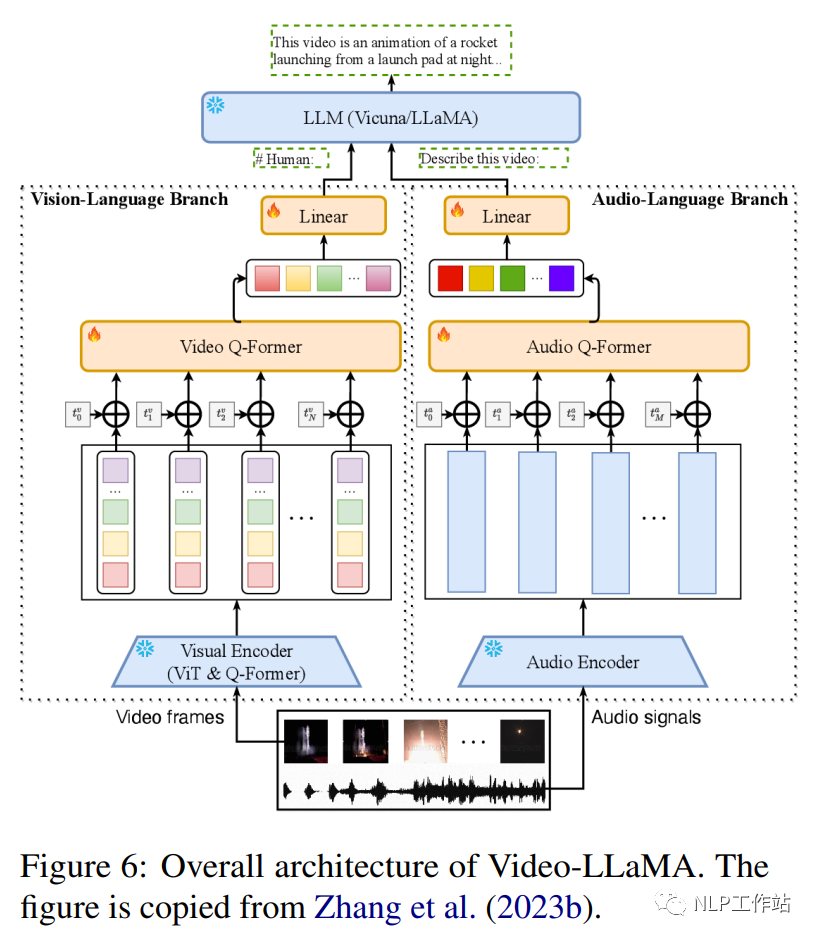
Video-LLaMA (Zhang et al., 2023b) es un marco multimodal que mejora la capacidad de modelos de lenguaje a gran escala para comprender contenido visual y auditivo en videos. Incluye dos codificadores de rama: la rama de lenguaje visual (VL) y la rama de lenguaje audiovisual (AL), y un decodificador de lenguaje (Vicuña (7B/13B), LLaMA (7B). La rama VL incluye un codificador de imagen congelado previamente entrenado. (el componente visual previamente entrenado de BLIP-2, que incluye un ViT-G/14 y un Q-former previamente entrenado), una capa de incrustación de posición, un Q-former de video y una capa lineal. La rama AL incluye un Codificador de audio previamente entrenado (ImageBind (Girdhar et al., 2023)) y un formador Q de audio. La Figura 6 muestra la arquitectura general de Video-LLaMA, incluida la rama del lenguaje visual y la rama del lenguaje audiovisual. La rama VL está implementada en Webvid-2M (Bain et al., 2021) conjunto de datos de subtítulos de video y realiza tareas de generación de video a texto y afina los datos de ajuste de instrucciones de MiniGPT-4, LLaVA y VideoChat. La rama AL está entrenada en video/imagen. datos de descripción, conecte la salida de ImageBind a un decodificador de lenguaje. Después de un ajuste fino, Video-LLaMA puede percibir y comprender contenido de video, demostrando su capacidad para integrar información auditiva y visual, comprender imágenes estáticas, reconocer conceptos de sentido común y capturar datos temporales. Dinámica en vídeos.
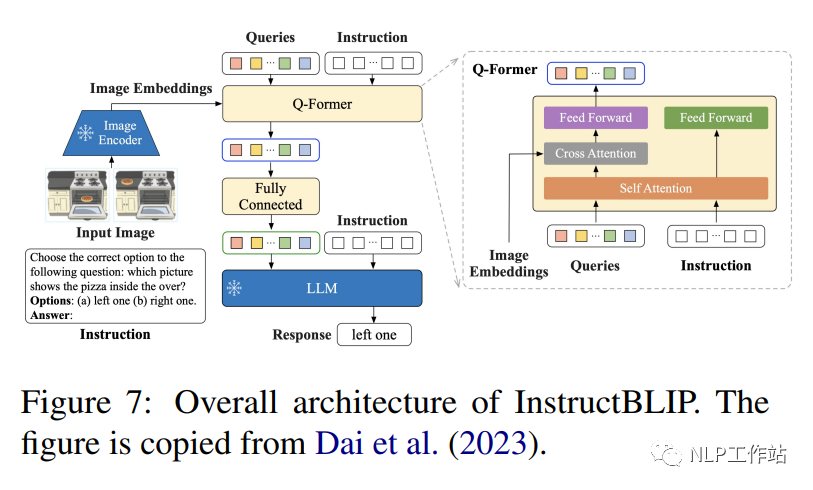
InstructBLIP (1.2B) (Dai et al., 2023) es un marco de ajuste de instrucción de lenguaje visual, inicializado con BLIP-2 previamente entrenado, y el modelo consta de un codificador de imágenes, un modelo de lenguaje grande (FlanT5 (3B/11B) o Vicuña (7B/13B) y transformador de consulta (Q-Former) para conectar los dos. Como se muestra en la Figura 7, Q-Former extrae características visuales con reconocimiento de instrucciones de la incrustación de salida del codificador de imágenes congeladas e ingresa las características visuales. como entrada de indicaciones suaves en un LLM congelado. Los autores evaluaron el rendimiento del modelo InstructBLIP en una variedad de tareas de lenguaje visual, incluyendo clasificación de imágenes, subtítulos de imágenes, respuesta a preguntas con imágenes y razonamiento visual. Utilizaron 26 conjuntos de datos disponibles públicamente, dividiéndolos en 13 conjuntos de datos de entrenamiento y 13 conjuntos de datos de evaluación. Los autores demuestran que InstructBLIP logra un rendimiento de vanguardia en una variedad de tareas de lenguaje visual. En comparación con BLIP-2, InstructBLIP logra una mejora relativa promedio del 15,0%, con el InstructBLIP más pequeño (4B) logra una mejora relativa promedio del 24,8% en los 6 conjuntos de datos de evaluación compartidos, superando a Flamingo (80B) (Alayrac et al., 2022).
Otter (Li et al., 2023b) es un modelo multimodal entrenado mediante el ajuste fino de OpenFlamingo (9B) (Awadalla et al., 2023). El lenguaje y los codificadores visuales son fijos, y solo el módulo de remuestreo del perceptrón y el cross- La atención está afinada: capas e incrustaciones de entrada/salida. Los autores organizaron una variedad de tareas multimodales que cubrían 11 categorías y construyeron un conjunto de datos de ajuste de instrucción contextual multimodal MIMIC-IT que contiene 2,8 millones de pares instrucción-respuesta multimodal, que consta de una composición de triplete imagen-instrucción-respuesta, donde se adapta la instrucción-respuesta. a la imagen. Cada muestra de datos también incluye contexto, que contiene una secuencia de tripletas imagen-instrucción-respuesta asociadas contextualmente con las tripletas de la consulta. En comparación con OpenFlamingo, Otter demuestra la capacidad de seguir las instrucciones del usuario con mayor precisión y proporcionar descripciones de imágenes más detalladas.
MultiModal-GPT (Gong et al., 2023) es un modelo de ajuste de instrucciones multimodal capaz de ejecutar diferentes instrucciones, generar subtítulos detallados, calcular objetos específicos y resolver consultas generales. MultiModal-GPT se entrena mediante ajustes en el conjunto de datos abiertos OpenFlamingo (9B) en una variedad de datos de instrucciones visuales creados, incluidos VQA, subtítulos de imágenes, razonamiento visual, OCR de texto y diálogo visual. Los experimentos demuestran la capacidad de MultiModal-GPT para mantener conversaciones continuas con las personas.
6. Ajuste de instrucciones en áreas específicas
6.1 Diálogo
InstructDial (Gupta et al., 2022) es un marco de ajuste de instrucciones diseñado para conversaciones. Contiene una colección de 48 tareas de diálogo en un formato consistente de texto a texto creado a partir de 59 conjuntos de datos de diálogo. Cada instancia de tarea incluye una descripción de la tarea, entradas de instancia, restricciones, instrucciones y salidas. Para garantizar la ejecución de instrucciones, el marco introduce dos metatareas: (1) la tarea de selección de instrucciones, donde el modelo selecciona instrucciones correspondientes a un par de entrada-salida determinado; (2) la tarea binaria de instrucciones, si la instrucción va de la entrada a la salida a una salida dada, el modelo predice "sí" o "no". Se ajustaron dos modelos básicos, T0-3B (versión paramétrica 3B de T5) y BART0 (modelo 406M basado en Bart-large) en la tarea de InstructDial. InstructDial logra resultados impresionantes en conjuntos de datos y tareas de diálogo invisibles, incluida la evaluación del diálogo y la detección de intenciones. Además, proporciona mejores resultados cuando se aplica a un número reducido de muestras.
6.2 Clasificación de intenciones y etiquetado de espacios (Slot Tagging)
LINGUIST, basado en el ajuste fino de AlexaTM 5B, es un modelo multilingüe de 5 mil millones de parámetros para la tarea de clasificación de intenciones y etiquetado de ranuras de conjuntos de datos de instrucciones. Cada instrucción consta de cinco bloques: (i) el lenguaje en el que se genera la salida, (ii) la intención, (iii) el tipo de ranura y el valor contenidos en la salida (por ejemplo, el número 3 en [3,snow] corresponde según el tipo de ranura, nieve es el valor utilizado por esta ranura), (iv) un mapeo de etiquetas de tipo de ranura a números y (v) hasta 10 ejemplos que indican el formato de la salida. En una nueva configuración de intención que utiliza 10 tomas del conjunto de datos SNIPS, LINGUIST logra mejoras significativas con respecto a los métodos de última generación. En la configuración de probabilidad cero entre idiomas del conjunto de datos mATIS++, LINGUIST supera las sólidas líneas de base para la traducción automática alineada con ranuras en 6 idiomas, al tiempo que mantiene el rendimiento de clasificación de intenciones.
6.3 Extracción de información
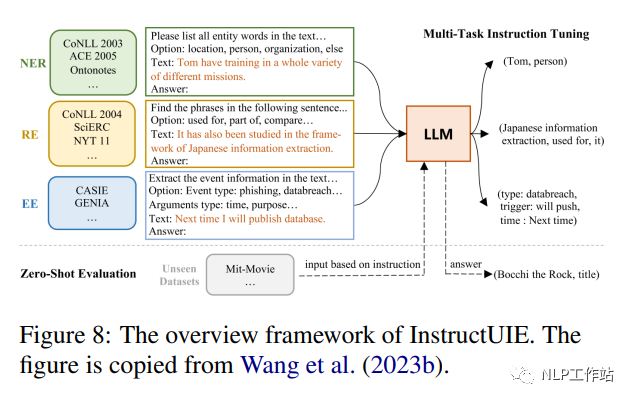
InstructUIE (Wang et al., 2023b) es un marco de extracción de información (IE) unificado basado en el ajuste de instrucciones, que convierte la tarea de IE al formato seq2seq y la resuelve ajustando estas preguntas en 11B FlanT5 en el conjunto de datos de TI construido. La Figura 8 muestra la arquitectura general de InstructUIE. Este artículo presenta el comando IE, un punto de referencia basado en 32 conjuntos de datos de extracción de información diferentes en un formato unificado de texto a texto, con comandos escritos por expertos. Cada instancia de tarea se describe mediante cuatro atributos: instrucciones de tarea, opciones, texto y resultados. Las instrucciones de la tarea contienen información como el tipo de información que se extraerá, el formato de la estructura de salida y restricciones o reglas adicionales que deben seguirse durante el proceso de extracción. Las opciones se refieren a las restricciones de la etiqueta de salida de la tarea y el texto se refiere a las oraciones de entrada. El resultado se obtiene convirtiendo la etiqueta original de la muestra (por ejemplo: "etiqueta de entidad: intervalo de entidad" en NER). En el entorno supervisado, InstructUIE funciona a la par de BERT (Devlin et al., 2018) y supera al GPT3.5 de última generación en el entorno de disparo cero.
6.4 Análisis de sentimiento basado en aspectos
Varia y otros (2022) propusieron un marco unificado de ajuste de instrucciones para resolver tareas de análisis de sentimiento basado en aspectos (ABSA) basado en el modelo T5 (220M) ajustado (Raffel et al., 2019). La subtarea multifactorial manejada por este marco involucra los cuatro elementos de ABSA, a saber, términos de aspecto, categorías de aspecto, términos de opinión y emociones. Trata estas subtareas como una combinación de cinco tareas de preguntas y respuestas, transformando cada oración en el corpus utilizando la plantilla de instrucciones proporcionada para cada tarea. Por ejemplo, una plantilla de instrucción utilizada es “¿Cuál es el término de aspecto en texto:$texto?” El marco demuestra una mejora sustancial (8,29 F1 en promedio) con respecto al escenario de aprendizaje de pocas oportunidades de última generación y lo mantiene en el escenario de ajuste global reduce la comparabilidad.
6.5 Escritura
Zhang y otros (2023d) propusieron Writing-Alpaca-7B, que afina LLaMa-7B en el conjunto de datos de instrucciones de escritura para brindar asistencia en la escritura. El conjunto de datos de instrucciones propuesto es una extensión del punto de referencia EDITEVAL basado en datos de instrucciones, eliminando la tarea de actualización e introduciendo una tarea sintáctica. El esquema de instrucción sigue estrictamente el esquema de instrucción del proyecto Stanford Alpaca, incluido un prefacio general, un campo de instrucción que guía la finalización de la tarea, un campo de entrada que proporciona texto para editar y un campo de respuesta que debe completar el modelo. . Writing-Alpaca-7B mejora el rendimiento de LLaMa en todas las tareas de escritura y supera a otros LLM más grandes disponibles en el mercado.
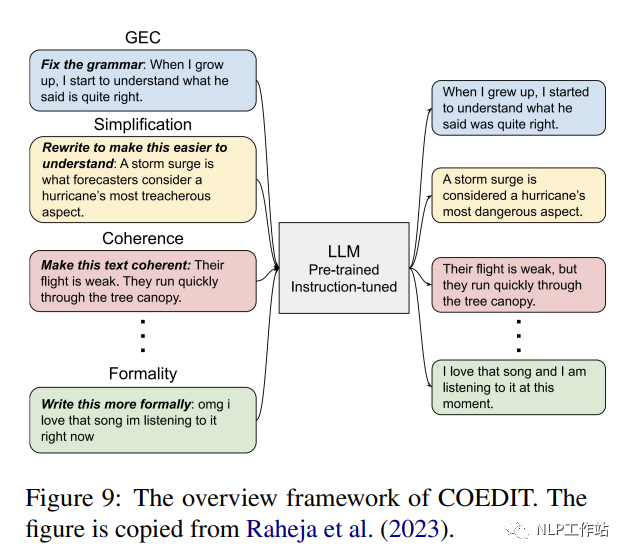
CoEdIT (Raheja et al., 2023) ajusta FLANT5 (parámetros 770M, parámetros 3B y parámetros 11B) para la edición de texto en el conjunto de datos de instrucciones para brindar asistencia en la escritura. El conjunto de instrucciones consta de aproximadamente 82 KB de pares de <instrucción: origen, destino>. Como se muestra en la Figura 9, el modelo acepta instrucciones del usuario para especificar las características del texto deseadas, como "simplificar la oración", y genera el texto editado. CoEdIT logra un rendimiento de vanguardia en varias tareas de edición de texto, incluida la corrección de errores gramaticales, la simplificación de texto, la edición de texto iterativa y tres tareas de edición estilística: transferencia de estilo formal, neutralización y paráfrasis. Además, se generaliza bien a tareas nuevas y adyacentes que no se ven en el ajuste fino.
CoPoet (Chakrabarty et al., 2022) es una herramienta colaborativa de escritura de poesía que aprovecha modelos de lenguaje grandes (como los modelos T5-3B, T5-11B y T0-3B) entrenados en una colección diversa de instrucciones de escritura de poesía. Cada ejemplo del conjunto de datos de instrucciones contiene un par <instruction,poe_line>. Hay tres tipos principales de indicación: continuación, moderación léxica y técnica retórica. CoPoet se activa mediante instrucciones del usuario que especifican los atributos deseados del poema, como escribir una oración sobre "amor" o terminar una oración con "volar". Este sistema no solo compite con los LLM disponibles públicamente capacitados en instrucciones (como InstructGPT), sino que también es capaz de satisfacer instrucciones sintéticas invisibles.
6.6 Médico
Radiology-GPT (Liu et al., 2023c) es un modelo Alpaca-7B ajustado para radiología que utiliza un método de ajuste de instrucciones en un amplio conjunto de datos de conocimiento del dominio de la radiología. Los informes de radiología suelen constar de dos secciones correspondientes: "Hallazgos" e "Impresiones". La sección “Hallazgos” contiene observaciones detalladas de las imágenes radiológicas, mientras que la sección “Impresiones” resume las interpretaciones derivadas de estas observaciones. Radiología-GPT proporciona una breve descripción del texto "hallazgos": "Impresiones derivadas de hallazgos en informes de radiología". El texto "Impresión" del mismo informe se genera como destino. En comparación con modelos de lenguaje general como StableLM, Dolly y LLaMA, Radiology-GPT es significativamente más versátil en diagnóstico, investigación y comunicación radiológica.
ChatDoctor (Li et al., 2023g) se basa en el modelo LLaMA-7B ajustado, aprovechando el conjunto de datos de instrucciones de alpaca y el conjunto de datos de conversación médico-paciente HealthCareMagic100k. Las plantillas de mensajes están diseñadas para buscar bases de conocimiento externas, como bases de datos de enfermedades y búsquedas en Wikipedia, durante conversaciones médico-paciente para obtener resultados más precisos del modelo. ChatDoctor mejora significativamente la capacidad del modelo para comprender las necesidades de los pacientes y brindar recomendaciones informadas, y la precisión de sus respuestas mejora enormemente a través de la recuperación de información autodirigida de fuentes confiables en línea y fuera de línea.
ChatGLM-Med, basado en el modelo ChatGLM-6B, perfeccionó el conjunto de datos de enseñanza médica china (Wang Haochun, 2023). El conjunto de datos de instrucciones incluye pares de preguntas y respuestas relacionadas con la medicina creados utilizando la API GPT3.5 y el gráfico de conocimiento médico. Este modelo mejora el rendimiento de respuesta a preguntas de ChatGLM en el campo médico.
6.7 Aritmética
Goat (Liu y Low, 2023) es un modelo ajustado basado en instrucciones de LLaMA-7B diseñado para resolver problemas aritméticos. Genera cientos de plantillas de instrucciones utilizando ChatGPT para representar preguntas aritméticas en forma de preguntas y respuestas en lenguaje natural, como "¿Qué es 8914/64?" El modelo emplea una variedad de técnicas para mejorar su adaptabilidad a diferentes formatos de preguntas, como como aleatorización Elimine espacios entre números y símbolos en expresiones aritméticas y reemplace "*" con "x" o "veces". El modelo Goat logra un rendimiento de última generación en subtareas de algoritmos de BIG-bench. En particular, el Goat7B de muestra cero iguala o supera al PaLM-540B de pocas muestras.
6.8 Código
WizardCoder (Luo et al., 2023) utiliza StarCoder 15B como base para realizar ajustes de instrucciones complejas adaptando el método de instrucción de evolución (Xu et al., 2023) al dominio del código. El conjunto de datos de entrenamiento se obtiene aplicando iterativamente la técnica Evol-Instruct en el conjunto de datos de Code Alpaca, que incluye las siguientes propiedades de cada muestra: instrucciones, entradas y salidas esperadas. Por ejemplo, cuando la instrucción es "Modificar la siguiente consulta SQL para seleccionar diferentes elementos", la entrada es la consulta SQL y la salida esperada es la respuesta generada. WizardCoder supera a todos los demás LLM de código abierto, incluso HumanEval y HumanEval+ superan a los LLM más grandes como Claude de Anthropic y Bard de Google.
7. Técnicas de ajuste efectivas
Las técnicas eficientes de ajuste fino tienen como objetivo optimizar un pequeño conjunto de parámetros de múltiples maneras, a saber, basadas en sumas, basadas en especificaciones y basadas en reparametrización, adaptando así los LLM a tareas posteriores. Los métodos basados en sumas introducen parámetros o módulos entrenables adicionales que no están presentes en el modelo original. Los métodos representativos incluyen el ajuste del adaptador (Houlsby et al., 2019) y el ajuste basado en indicaciones (Schick y Schütze, 2021). Los métodos basados en especificaciones especifican ciertos parámetros intrínsecos del modelo que se ajustarán mientras congelan otros parámetros. Por ejemplo, BitFit (Zaken et al., 2022) ajusta el término de sesgo del modelo previamente entrenado. El método de reparametrización convierte los pesos del modelo en una forma de ajuste más eficiente en parámetros. La clave es asumir que la adaptabilidad del modelo es de rango bajo, por lo que los pesos se pueden volver a parametrizar en factores de rango bajo o subespacios de baja dimensión ( como LoRA (Hu et al., 2021)). El aviso intrínseco descubre un subespacio de baja dimensión que se comparte mediante el ajuste de avisos en diferentes tareas.
7.1 LORA
La adaptación de rango bajo (LoRA) (Hu et al., 2021) puede lograr una adaptación eficiente de LLM mediante actualizaciones de rango bajo. LoRA utiliza DeepSpeed (Rasley et al., 2020) como columna vertebral del entrenamiento. La idea clave de LoRA es que los cambios reales en los pesos de LLM necesarios para adaptarse a nuevas tareas existen en un subespacio de baja dimensión. Específicamente, para una matriz de peso W0 previamente entrenada, los autores modelan la matriz de peso ajustada como W0 + ΔW, donde ΔW es una actualización de rango bajo. ΔW está parametrizado como ΔW = BA, donde A y B son matrices entrenables mucho más pequeñas. Elegimos que el rango r de ΔW sea mucho más pequeño que la dimensión de W0. La intuición del autor no es entrenar todos los W0 directamente, sino entrenar A y B de baja dimensión, que entrenan indirectamente a W0 en un subespacio de bajo rango en la dirección relevante para la tarea posterior. Esto da como resultado muchos menos parámetros entrenables en comparación con el ajuste completo. Para GPT-3, LoRA reduce la cantidad de parámetros entrenables en 10,000 veces y el uso de memoria en 3 veces en comparación con el ajuste fino completo.
7.2 CONSEJO
HINT (Ivison et al., 2022) combina las ventajas generales del ajuste de instrucciones con un ajuste fino bajo demanda eficiente, evitando el procesamiento repetido de instrucciones largas. La esencia de HINT radica en una hiperred que genera módulos adaptativos llm eficientes en parámetros basados en instrucciones en lenguaje natural y una pequeña cantidad de ejemplos. La hiperred empleada convierte instrucciones y algunos ejemplos en instrucciones codificadas y genera parámetros de adaptador y prefijo utilizando un codificador de texto previamente entrenado y un generador de parámetros basado en atención cruzada. Los adaptadores y prefijos generados luego se insertan en el modelo principal como módulos de ajuste eficientes. En el momento de la inferencia, la hiperred realiza la inferencia solo una vez por tarea para generar módulos adaptados. La ventaja de esto es que, a diferencia de los métodos habituales de ajuste fino o concatenación de entradas, HINT puede combinar instrucciones más largas y fragmentos pequeños adicionales sin aumentar la carga computacional.
7,3 harina
QLORA (Dettmers et al., 2023) incluye cuantificación optimizada y optimización de la memoria, con el objetivo de proporcionar un ajuste eficiente y eficaz de los LLM. QLORA incluye cuantificación NormalFloat (NF4) de 4 bits, un esquema de cuantificación optimizado para la distribución normal típica de pesos LLM. Al cuantificar basándose en los cuantiles de la distribución normal, NF4 proporciona un mejor rendimiento que la cuantificación estándar de punto flotante o entero de 4 bits. Para reducir aún más la memoria, la propia constante de cuantificación se cuantifica a 8 bits. Este segundo nivel de cuantificación ahorra una media de 0,37 bits por parámetro. QLORA aprovecha la función de memoria unificada de NVIDIA: cuando se excede la memoria de la GPU, el estado del optimizador de página se transfiere a la RAM de la CPU, evitando así una cantidad insuficiente de memoria durante el proceso de entrenamiento. QLORA puede entrenar un LLM de parámetros de 65 B en una sola GPU de 48 GB sin degradación en comparación con el ajuste fino completo de 16 bits. QLORA funciona congelando la base de cuantificación LLM de 4 bits y luego propagándola hacia atrás.
7.4 LOMO
La optimización de memoria baja (LOMO) (Lv et al., 2023) logra un ajuste completo de los parámetros de llm con recursos informáticos limitados fusionando el cálculo y la actualización del gradiente. Su esencia es integrar el cálculo de gradiente y la actualización de parámetros en un solo paso de retropropagación, evitando así el almacenamiento de tensores de gradiente completos. Primero, LOMO proporciona un análisis teórico que explica por qué SGD funciona bien para ajustar grandes modelos preentrenados, a pesar de los desafíos que presenta para modelos más pequeños. Además, LOMO actualiza cada tensor de parámetros tan pronto como se calcula su gradiente en la retropropagación. Almacenar gradientes un parámetro a la vez reduce la memoria de gradiente a O(1). LOMO utiliza recorte de valor de gradiente, cálculo de norma de gradiente de separación y escala de pérdida dinámica para estabilizar el entrenamiento. La integración de puntos de control activados y métodos de optimización cero ahorra memoria.
7.5 Sintonización delta
El ajuste delta (Ding et al., 2023b) proporciona una perspectiva de optimización y control óptimo para el análisis teórico. Intuitivamente, el ajuste delta realiza una optimización subespacial restringiendo el ajuste a variedades de baja dimensión. Los parámetros ajustados sirven como controladores óptimos para guiar el comportamiento del modelo para tareas posteriores.
8. Evaluar, analizar y criticar
8.1 Evaluación HELM
HELM (Liang et al., 2022) es una evaluación holística de modelos de lenguaje (LM) para aumentar la transparencia de los modelos de lenguaje y proporcionar una comprensión más completa de las capacidades, riesgos y limitaciones de los modelos de lenguaje. Específicamente, a diferencia de otros métodos de evaluación, HELM cree que la evaluación general de un modelo lingüístico debe centrarse en los tres factores siguientes:
(1) Amplia cobertura. Durante el desarrollo, los modelos de lenguaje se pueden adaptar a diversas tareas de PNL (como anotación de secuencias y respuesta a preguntas), por lo que la evaluación de los modelos de lenguaje debe realizarse en una amplia gama de escenarios. Teniendo en cuenta todos los escenarios posibles, HELM propone una taxonomía de arriba hacia abajo que primero compila todas las tareas existentes en una gran conferencia de PNL (ACL2022) en un espacio de tareas y divide cada tarea en escenarios (forma como el lenguaje) y medidas (por ejemplo, precisión). Luego, ante una tarea específica, la taxonomía seleccionará uno o más escenarios e indicadores en el espacio de tareas para cubrirla. HELM aclara el contenido de la evaluación (escenarios de tareas e indicadores) analizando la estructura de cada tarea, aumentando la tasa de cobertura de escena del modelo de lenguaje del 17,9% al 96,0%.
(2) Medición multimétrica. Para permitir a los humanos medir modelos de lenguaje desde diferentes perspectivas, HELM propone métricas multimétricas. HELM cubre 16 escenarios diferentes y 7 indicadores. Para garantizar los resultados de mediciones multimétricas intensivas, HELM midió 98 de 112 escenarios centrales posibles (87,5%).
(3) Estandarización. El aumento en el tamaño y la complejidad del entrenamiento de los modelos de lenguaje ha dificultado seriamente la comprensión de la estructura de cada modelo de lenguaje por parte de las personas. Para establecer una comprensión unificada de los modelos de lenguaje existentes, HELM comparó 30 modelos de lenguaje conocidos, incluidos Google (UL2 (Tay et al., 2022)), OpenAI (GPT-3 (Brown et al., 2020b)) y EleutherAI (GPT-NeoX (Black et al., 2022)) y otras instituciones. Curiosamente, HELM señaló que LLM como T5 (Raffel et al., 2019) y Anthropic-LMv4-s3 (Bai et al., 2022a) no se compararon directamente en el trabajo original, mientras que LLM como GPT-3 y YaLM Después de múltiples evaluaciones, todavía existen discrepancias con los informes correspondientes.
8.2 Ajuste de instrucción de bajos recursos
Gupta y otros (2023) intentaron estimar los datos mínimos de entrenamiento posteriores necesarios para que los modelos de TI coincidan con los requisitos de los modelos supervisados por SOTA para diversas tareas. Gupta y otros (2023) realizaron experimentos con 119 tareas de Instrucciones Súper Naturales (SuperNI) en entornos de aprendizaje de una sola tarea (STL) y de aprendizaje multitarea (MTL). Los resultados muestran que en la configuración STL, solo el 25% de los datos de entrenamiento posteriores para el modelo de TI supera al modelo SOTA en estas tareas, mientras que en la configuración MTL, solo el 6% de los datos de entrenamiento posteriores pueden guiar el modelo de TI para lograr Rendimiento SOTA. Estos hallazgos sugieren que el ajuste de las instrucciones puede ayudar eficazmente a los modelos a aprender rápidamente tareas con datos limitados.
8.3 Conjunto de datos de instrucciones más pequeño
TI requiere grandes cantidades de datos de instrucción especializados para la capacitación. Zhou y otros (2023) plantearon la hipótesis de que el LLM previamente capacitado solo necesita aprender estilos o formatos para interactuar con los usuarios, y propusieron que LIMA lograra un rendimiento sólido ajustando el LLM en solo 1000 ejemplos de capacitación cuidadosamente seleccionados. Específicamente, LIMA primero selecciona manualmente 1000 ejemplos con indicaciones y respuestas de alta calidad. Luego, se utilizaron 1000 ejemplos para ajustar el LLaMa-65B previamente entrenado (Touvron et al., 2023b). En comparación, LIMA supera a GPT-davinci003 (Brown et al., 2020b), que se ajustó en 5200 ejemplos con ajustes de retroalimentación humana, en más de 300 tareas desafiantes. Además, con solo la mitad de los ejemplos, LIMA logra resultados comparables a GPT-4 (OpenAI, 2023), Claude (Bai et al., 2022b) y Bard. Lo más importante es que LIMA demuestra que los poderosos conocimientos y capacidades de los LLM se pueden demostrar a los usuarios con solo algunas instrucciones de ajuste cuidadosamente planificadas.
8.4 Conjunto de datos de evaluación de ajuste de instrucciones
El rendimiento de los modelos de TI depende en gran medida de los conjuntos de datos de TI. Sin embargo, falta una evaluación subjetiva y abierta de estos conjuntos de datos de tecnología de la información. Para abordar este problema, Wang et al. (2023c) realizaron una evaluación de conjuntos de datos ajustando el modelo LLaMa (Touvron et al., 2023b) en varios conjuntos de datos de TI abiertos y midieron diferentes modelos ajustados mediante evaluación automática y manual. Entrene un modelo adicional sobre la combinación de conjuntos de datos de TI. En cuanto a los resultados, Wang y otros (2023c) demostraron que no existe un único conjunto de datos de TI que sea el mejor para todas las tareas, y que el mejor rendimiento general se puede lograr combinando conjuntos de datos manualmente. Además, Wang y otros (2023c) señalaron que, aunque las TI pueden aportar grandes beneficios a los LLM de todos los tamaños, los modelos más pequeños y los modelos base de alta calidad son los mayores beneficiarios de las TI. Para la evaluación humana, cuanto más grande sea el modelo, mayor será la puntuación de aceptabilidad.
8.5 ¿Es la TI sólo una réplica del modelo de aprendizaje?
Para abordar la falta de claridad en el conocimiento específico que los modelos adquieren a través del ajuste de instrucciones, Kung y Peng (2023) realizaron un análisis en profundidad de cómo los modelos utilizan las instrucciones en los procesos de TI comparando el ajuste cuando proporcionan instrucciones modificadas e instrucciones originales.
En particular, Kung y Peng (2023) crearon definiciones de tareas simplificadas que eliminaron todos los componentes semánticos y dejaron solo información de salida. Además, Kung y Peng (2023) introdujeron ejemplos fantasma que contenían asignaciones de entrada-salida incorrectas. Sorprendentemente, los experimentos muestran que los modelos entrenados con estas definiciones de tareas simplificadas o con ejemplos erróneos pueden lograr un rendimiento comparable al de los modelos entrenados con las instrucciones y ejemplos originales. Además, este documento también presenta una línea de base para tareas de clasificación de tiro cero, logrando un rendimiento similar al de TI en entornos de bajos recursos.
En resumen, según Kung y Peng (2023), las importantes mejoras de rendimiento observadas en los modelos de TI actuales pueden atribuirse a su capacidad para capturar patrones a nivel superficial, como aprender formatos de salida y adivinar, en lugar de comprender y aprender tareas específicas.
8.6 Imitación de LLM propietarios
La clonación de LLM es un método para recopilar resultados de modelos más potentes (sistemas propietarios como ChatGPT) y utilizar estos resultados para ajustar el LLM de código abierto. De esta forma, el LLM de código abierto gana la capacidad de competir con cualquier modelo propietario.
Gudibande y otros (2023) realizaron múltiples experimentos para analizar críticamente la efectividad de la imitación de modelos. Específicamente, Gudibande y otros (2023) recopilaron por primera vez un conjunto de datos a partir de la extensa tarea realizada por ChatGPT. Estos conjuntos de datos se utilizaron luego para ajustar una variedad de modelos, incluidos los modelos base GPT-2 y LLaMA, con tamaños que van desde 1,5 mil millones a 13 mil millones, con tamaños de datos que van desde 0,3 millones de tokens a 1,5 millones de tokens.
Para la evaluación, Gudibande y otros (2023) demostraron que el modelo de imitación es mucho mejor que antes en la tarea de respaldar el conjunto de datos, con resultados similares a ChatGPT. En tareas sin conjuntos de datos simulados, la precisión del modelo de simulación no mejoró o incluso disminuyó.
Por lo tanto, Gudibande et al. (2023) señalaron que es el fenómeno de que el modelo de imitación es bueno para imitar el estilo de ChatGPT (como fluido, seguro y bien estructurado) lo que hace que los investigadores tengan una ilusión sobre la capacidad general de El modelo de imitación. Por lo tanto, Gudibande y otros (2023) sugieren que sería mejor para los investigadores centrarse en mejorar la calidad de los modelos base y los ejemplos de instrucción en lugar de imitar modelos propietarios.
Resumir
En la era de los grandes modelos, si no avanzas, retrocederás, espero que todos aprendan de ello.
Preste más atención a "Liu Cong NLP" en Zhihu. Los amigos que tengan preguntas también pueden agregarme a WeChat "logCong" para chatear en privado. Hagamos amigos, aprendamos juntos y progresemos juntos. Nuestro lema es "La vida es infinita, el aprendizaje es infinito".
PD: Se ha publicado el nuevo libro "Principios y combate práctico de ChatGPT", bienvenido a comprarlo ~~.
Recomendado en el pasado:
El informe técnico de BaiChuan2 detalla el intercambio y los pensamientos personales
Resumen de la experiencia de ajuste fino del LLM de modelo grande y actualización del proyecto
Una breve discusión sobre la extrapolación de longitud de LLM
La era de los grandes modelos: repensar la implementación de la industria
Investigación sobre el problema de las alucinaciones en modelos grandes