Recientemente, el modelo de lenguaje grande de código abierto LlaMA-2 se ha vuelto popular. Según la clasificación de modelos de lenguaje grande de código abierto Open LLM de Huggingface, podemos ver que LlaMA-2 sigue siendo uno de los modelos comerciales de lenguaje grande de código abierto con gran potencial. con InstructGPT, LlaMA-2 Se han realizado una gran cantidad de actualizaciones técnicas en calidad de datos, tecnología de capacitación, evaluación de capacidades, evaluación de seguridad y liberación de responsabilidad. Además, también ha tenido un desempeño relativamente bueno en términos de licencias comerciales, huggingface y otros apoyo de la comunidad Este artículo utiliza el modelo 7B como ejemplo para presentar la inferencia, el entrenamiento y la aplicación de LlaMA -2.
Relativamente hablando, la estructura del modelo LlaMA-2 es más simple que Transformer. Para Transformer, consulte el blog " La atención es todo lo que necesita: Transformer, uno de los grandes modelos de lenguaje ". Este artículo se centra en el documento oficial de LlaMA (Meta ).
LlaMA-2 se basa en la parte Decoder del Transformer, sus datos de entrenamiento son 45 TB, 2 billones de tokens y la longitud del contexto previo al entrenamiento es 4096. Utiliza GQA (Mecanismo de atención de consultas grupales) para mejorar la velocidad de razonamiento y usa más Para entrenar el modelo SFT, Nathan Lambert, doctor en inteligencia artificial de la Universidad de Berkeley, dijo en su blog que después de una serie de pruebas comparativas, además de la capacidad de programación, LlaMA- 2 alcanzó el nivel de ChatGPT y Meta propuso una forma de mejorar la coherencia de múltiples rondas. El nuevo método GAtt, inspirado en el método de destilación de contexto, también tiene algunas opiniones sobre el modelo de recompensa, el proceso RLHF, la evaluación de seguridad y la declaración de permiso en el papel.
El modelo de recompensa es la clave para el aprendizaje reforzado. Para obtener un buen modelo de recompensa, Meta recopiló una gran cantidad de datos de preferencias, que excede con creces la cantidad de datos utilizados actualmente por la comunidad de código abierto. Meta utiliza un modelo de puntuación de clasificación binaria. para evaluar indicadores, que no es más complicado que usar el modelo de retroalimentación, la recopilación de datos se centra en la utilidad y la seguridad, utiliza diferentes pautas para cada fuente de datos, agrega metadatos de seguridad, método de recopilación de datos iterativo, asigna anotaciones manuales semanales y según se recopilan Más preferencia Los datos y el modelo de recompensa también se han mejorado. El elemento de datos LlaMA-2 probablemente cueste alrededor de 20 millones de dólares estadounidenses. La parte del modelo de recompensa Meta ha entrenado dos modelos de recompensa independientes, uno está optimizado para su utilidad y el otro está optimizado. por seguridad;
En términos de hardware de entrenamiento, Meta preentrenó el modelo en su Research Super Cluster (RSC), así como en su cluster de producción interno. Ambos clústeres utilizaron NVIDIA A100. En la evaluación de Meta, múltiples resultados de la evaluación muestran que Llama 2 supera a otros modelos de lenguaje de código abierto en muchos puntos de referencia externos, incluidas pruebas de inferencia, codificación, competencia y conocimientos.
Por supuesto, para los modelos grandes actuales, la "seguridad" es un indicador tan importante como el "rendimiento". Durante el desarrollo de Llama 2, Meta utilizó tres puntos de referencia comunes para evaluar su seguridad:
- Autenticidad, se refiere a si el modelo de lenguaje generará información de error, utilizando el punto de referencia TruthfulQA;
- Toxicidad, se refiere a si el modelo de lenguaje producirá contenido "tóxico", grosero y dañino, utilizando el punto de referencia ToxiGen;
- Sesgo, se refiere a si el modelo de lenguaje producirá contenido sesgado, utilizando el punto de referencia BOLD.
huggingface creó un script que utiliza QLoRA y SFTTrainer de trl para ajustar las instrucciones de Llama 2. , ¡ahora puedes entrenar todos los modelos Llama-2 con tus propios datos en solo unas pocas líneas de código! Al utilizar 4 bits y PEFT, este script se puede utilizar para entrenar modelos 70B incluso en una sola GPU A100. Puede realizar 7B de entrenamiento en una GPU T4 (que está disponible gratuitamente en Colab) o 70B de entrenamiento en una GPU A100.
TRL - Aprendizaje por refuerzo de transformadores. Esta es la biblioteca completa ultracompleta de Huggingface que incluye un conjunto de herramientas para entrenar modelos de lenguaje transformador mediante el aprendizaje por refuerzo (Reinforcement Learning). Desde el paso de ajuste supervisado (SFT), hasta el modelo de recompensa de capacitación (modelado de recompensa) y la optimización de políticas próximas (optimización de políticas próximas), ¡se ha logrado una cobertura integral! ¡Y la biblioteca TRL se ha integrado con transformadores, lo cual es conveniente para uso directo!

PEFT (Ajuste fino eficiente de parámetros) es una técnica para ajustar modelos de redes neuronales que tiene como objetivo reducir significativamente los recursos informáticos y el tiempo necesarios para el ajuste mientras se mantiene el rendimiento del modelo. Esto es útil para ajustar el modelo en entornos con recursos limitados. La idea principal de PEFT es ajustar algunos de los parámetros del modelo utilizando una pequeña tasa de aprendizaje en lugar de ajustar todos los parámetros de todo el modelo. Específicamente, PEFT divide los parámetros del modelo en diferentes grupos y luego aplica diferentes tasas de aprendizaje en cada grupo. Esto puede distribuir la sobrecarga computacional del ajuste fino en múltiples minilotes, reduciendo así la carga computacional de cada minilote, lo que permite que el modelo se ajuste eficientemente en dispositivos más pequeños.
En la fase de inferencia, para diferentes modelos, las sugerencias de Huggingface son las siguientes:
- Para inferir sobre el modelo 7B, se recomienda seleccionar "GPU [mediana] - 1x Nvidia A10G".
- Para inferir sobre el modelo 13B, se recomienda seleccionar "GPU [xlarge] - 1x Nvidia A100".
- Para inferir sobre el modelo 70B, se recomienda seleccionar "GPU [xxxlarge] - 8x Nvidia A100".
Sin embargo, esta no es la única opción, sino que el paralelismo de los resultados del modelo determina que la eficiencia de la GPU será mucho mayor que la de la CPU.
Razonamiento y estructura del modelo LlaMA-2
Aquí nos referimos a karpathy/llama2.c y tomamos la entrada rápida "¡Hola!" como ejemplo para ilustrar el proceso de razonamiento. Aquí está el modelo 7B.
- Primero, encuentre la representación vectorial correspondiente del token "usted" en la tabla token_embedding_table (matriz de incrustación) obtenida del entrenamiento, es decir, un vector compuesto por 4096 números de punto flotante (debido a que representa una palabra, a menudo se le llama palabra vector, y la palabra se usa más tarde Representación unificada de vector), después de obtener la palabra vector, realice RMSNorm. , como lo indica el círculo 1 en la figura siguiente, la longitud del vector de cada token (32000 tokens en LlaMA-2) es 4096, es decir, el tamaño de la tabla token_embedding_table es [32000, 4096].
float* content_row = &(w->token_embedding_table[token * dim]);
- Después de obtener el vector de palabras, se realiza la operación RMSNorm, como se muestra en la segunda posición del círculo. Es inútil usar LayerNorm aquí, ya que RMSNorm puede suavizar la pérdida durante el descenso del gradiente. La fórmula de LayerNorm se ha modificado en el artículo RMSNorm. En el LayerNorm original, los parámetros se ajustaban con la ayuda de la media y la varianza de las estadísticas de cada capa, pero RMSNorm cree que la propiedad de invariancia de recentrado es innecesaria y solo se reserva la propiedad de invariancia de reescalado.
// attention rmsnorm
rmsnorm(s->xb, x, w->rms_att_weight + l*dim, dim);
-
Después de RMS, ingrese la capa lineal para obtener QKV. En la figura, el círculo 3, el círculo 4 y el círculo 5 son matrices de tamaño [4096,4096] respectivamente. Después de pasar por Lineal, se obtienen Q, K y V. Cabe señalar aquí que K, V es el valor histórico que debe conservarse. Por ejemplo, cuando se ingresa el token "bueno" en la figura, su KV se mantiene aquí. Aquí se puede hacer una explicación sencilla sobre QKV.
Una palabra muy importante en el texto original de Transformer es Atención. Por ejemplo, si te preguntas "¿Qué anime es Naruto?", pondrás tu atención (Atención) en "Naruto" y buscarás en tu memoria. Luego darás la respuesta. Naruto, que muestra que la importancia de cada ficha en una oración no es igual, y a algunas fichas se les debe prestar más atención (Atención).
La función de QKV es la que sugiere el nombre, porque Google es un motor de búsqueda, por lo que el significado de Qurey, Clave y Valor aquí puede referirse al siguiente diagrama de comparación de resultados del motor de búsqueda.
Se puede ver desde aquí que la Consulta y la Clave son similares, y el contenido del Valor se muestra de acuerdo con la similitud entre la Consulta y la Clave. Entonces la fórmula central de la Atención es.
softmax ( QKT ) ∗ V softmax(\mathbf Q \mathbf K^T)* \mathbf Ventonces f t ma x ( Q KT )∗V
mejorasoftmax ( QKT ) ∗ softmax(\mathbf Q \mathbf K^T)*entonces f t ma x ( Q KT )∗se basa en la similitud entre Consulta y Clave para obtenerV \mathbf VLa máscara a la que se debe prestar atención en V (no todos los tokens en Query tienen la misma importancia, y la importancia de cada token en Value también es diferente), esta diferencia se puede pasar a través de softmax (por suma, etc. y uno- Transformación a uno) asigna pesos a cada token de Valor.

-
Con la comprensión inicial del QKV anterior, echemos un vistazo al Multi-Head de LlaMA-2. Los parámetros del modelo LlaMA-2 7B (Meta oficial) son los siguientes:
(venv) ➜ localGPT git:(main) ✗ cat ~/llama/llama-2-7b/params.json
{"dim": 4096, "multiple_of": 256, "n_heads": 32, "n_layers": 32, "norm_eps": 1e-05, "vocab_size": -1}
El n_heads:32 aquí corresponde a 32 en la puntuación de Atención, divida el QKV (longitud 4096) en el paso 3 en 32 cabezas, la longitud de cada cabeza es 128 (128*32=4096), círculo 6 y Círculo 7, círculo 8 Y el círculo 9 se debe a que existe una relación de dependencia en el tiempo. Por ejemplo, el token "bueno" y el token "usted" tienen una relación en el tiempo. Los círculos 6 y 8 son para calcular el puntaje de Atención de "usted", los círculos 7 y 8 son para calcular el puntaje de Atención de "bueno" y luego superponer la influencia de los puntajes de Atención actuales "buenos" y de todos los tokens en la historia anterior en el actual "bueno" "Este token obtiene la puntuación de Atención acumulada calculada por el Círculo 10.
El mecanismo de atención de LLama2 utiliza GQA
MHA (Atención de múltiples cabezas) es un mecanismo de atención de múltiples cabezas estándar, matrices h Query, Key y Value.
MQA (Atención de consultas múltiples, decodificación rápida de transformadores: todo lo que necesita es un cabezal de escritura) es una variante de atención de consultas múltiples y un mecanismo de atención para la decodificación autorregresiva. A diferencia de MHA, MQA permite que todos los cabezales compartan la misma matriz de clave y valor, y cada cabezal solo conserva una copia separada de los parámetros de consulta, lo que reduce en gran medida los parámetros de las matrices de clave y valor.
GQA (Atención de consultas agrupadas, GQA: entrenamiento de modelos de transformadores de consultas múltiples generalizados a partir de puntos de control de múltiples cabezales) es una atención de consultas grupales. GQA divide el encabezado de la consulta en grupos G, y cada grupo comparte una matriz de clave y valor. GQA-G se refiere a la atención de consultas agrupadas con grupos G. GQA-1 tiene un único grupo y, por tanto, una única clave y valor, equivalente a MQA. Mientras que GQA-H tiene grupos iguales al número de cabezas, lo que equivale a MHA.
- Calcular la atención es realizar un cálculo lineal en la puntuación de atención acumulada y Wo, luego agregar la atención a RMSNorm del círculo de paso 2 (estructura resnet) y luego calcular RMSNorm para obtener el resultado de la norma de atención, que es el círculo 13.
- En la operación FFN, los resultados del círculo 13 se calculan mediante W1, W3 y W2 respectivamente para obtener la salida de la red directa, y luego se realiza un paso de resnet similar al paso 5 para obtener la salida de un bloque Transformador.
- El bloque Transformador se repite 32 veces y luego se genera a través de RMSNorm, y luego la salida se obtiene después de la operación logits.
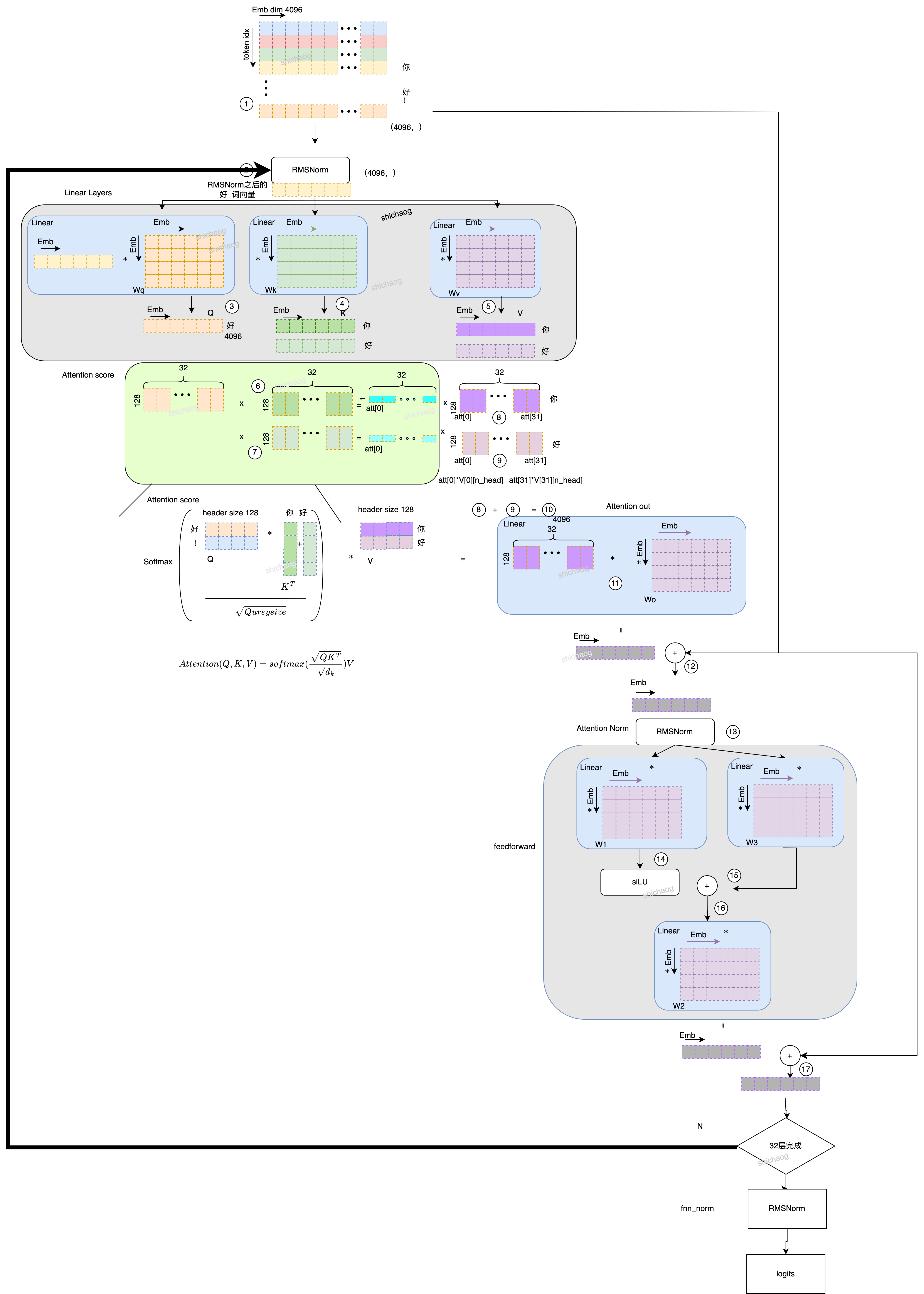
En este punto, se completa la parte de inferencia del modelo.
Debido a que llama2.c se basa en código c, su eficiencia y velocidad teóricamente pueden ser más rápidas (SIMD). Además, el autor de la biblioteca también le dio a tinystories una versión mucho más simplificada del ejemplo de preentrenamiento del modelo LlaMA con menos parámetros. El conjunto de datos de tinystories es la dirección descargada de Hugging face .
Relacionado con el entrenamiento de modelos grandes
El modelo de preentrenamiento se puede ver en las pequeñas historias anteriores, esto no es difícil, el siguiente paso es el ajuste de la instrucción y el aprendizaje reforzado basado en la retroalimentación humana. La mayor diferencia entre el ajuste fino de instrucciones (SFT) y el modelo de preentrenamiento radica en el conjunto de datos. Por supuesto, para requerir menos potencia informática para SFT, también se utilizarán métodos como LoRA. Por supuesto, Hugging face ha creado estas API para llamar. Hay muchos conjuntos de datos en Huggingface. Además del modelo de lenguaje grande aquí, también hay conjuntos de datos multimodales. Consulte el sitio web oficial de Huggingface para obtener más detalles .
conjunto de datos de ajuste fino de instrucciones
Los conjuntos de datos de entrenamiento de modelos de lenguaje grandes de código abierto se pueden encontrar básicamente en Huggingface.
- El conjunto de datos de código abierto de Stanford, alpaca_data.json , contiene 52k datos de seguimiento de instrucciones para ajustar el modelo Alpaca. El archivo json es una lista de diccionarios, y cada diccionario contiene instrucción:str, que describe las tareas que debe realizar el modelo. llevar a cabo.
- Generated_Chat_0.4M, contiene alrededor de 400.000 datos de diálogos de personajes personalizados generados por el proyecto BELLE, incluidas las presentaciones de los personajes.
Nota: Este conjunto de datos es generado por ChatGPT y no ha sido verificado estrictamente, y las preguntas o el proceso de resolución de problemas pueden contener errores. Preste atención a esto durante el uso. - School Math 0.25M , que incluye alrededor de 250.000 datos de problemas matemáticos chinos generados por el proyecto BELLE, incluido el proceso de resolución de problemas.
Nota: Este conjunto de datos es generado por ChatGPT y no ha sido verificado estrictamente, y las preguntas o el proceso de resolución de problemas pueden contener errores. Preste atención a esto durante el uso. - JosephusCheung/GuanacoDataset , el conjunto de datos tiene un total de 534.530 elementos y cuesta 6.000 dólares estadounidenses. Es un conjunto de datos multilingüe que incluye inglés, chino y japonés.
Además, existen conjuntos de datos de Fifefly, alpaca_chinese_datase, etc.
La API proporcionada por la biblioteca trl de Huggingface es la siguiente:
- Clases de modelo: una breve descripción general de lo que hace cada clase de modelo público.
- SFTTrainer: Supervise y ajuste su modelo fácilmente con SFTTrainer
- RewardTrainer: entrene fácilmente su modelo de recompensa usando RewardTrainer.
- PPOTrainer: ajuste aún más el modelo supervisado y ajustado utilizando el algoritmo PPO
- Muestreo lo mejor de N: utilice el muestreo lo mejor de n como forma alternativa de muestrear predicciones de su modelo activo.
- DPOTrainer: Entrenamiento de Optimización Directa de Preferencias usando DPOTrainer.
Y adjunto algunos ejemplos detalladamente - Ajuste de sentimiento: ajuste su modelo para generar contenidos de película positivos
- Entrenamiento con PEFT: Entrenamiento RLHF eficiente en memoria utilizando adaptadores con PEFT
- LLM desintoxicantes: desintoxice su modelo lingüístico a través de RLHF
- StackLlama: entrenamiento RLHF de extremo a extremo de un modelo Llama en un conjunto de datos de intercambio Stack
- Entrenamiento con múltiples adaptadores: use un único modelo base y múltiples adaptadores para un entrenamiento de un extremo a otro con eficiencia de memoria
lloviendo con PEFT
Este ejemplo utiliza la tecnología LoRA para brindar un ejemplo de capacitación previa eficiente para pruebas internas.
LoRA (adaptación de bajo rango de modelos de lenguaje grandes) es una tecnología propuesta por Microsoft para abordar el ajuste fino de modelos de lenguaje grandes. El modelo de lenguaje grande tiene miles de millones de parámetros. Para que sea adecuado para tareas específicas, el costo del proceso de El ajuste fino es muy alto Alto, el método LoRA recomienda congelar los parámetros del modelo de preentrenamiento e inyectar la capa entrenable (matrices de descomposición de rangos) en cada bloque Transformer, porque los parámetros del modelo de preentrenamiento congelados no participan en el gradiente. cálculo, que reduce en gran medida los parámetros entrenables Además de los requisitos de memoria de la GPU, los investigadores descubrieron que al centrarse solo en los bloques de atención Transform del modelo de lenguaje grande, la calidad de ajuste fino de LoRA es comparable al ajuste fino del modelo completo, al tiempo que es más rápido y requiere menos cálculo.
Aunque LoRA se propone para modelos de lenguaje grandes y esta tecnología se ha verificado en bloques Transformer, esta tecnología se puede usar en otros modelos, como el ajuste fino del modelo de Difusión Estable, y LoRA se puede aplicar a la representación y descripción de imágenes. Sus señales están asociadas con capas de atención cruzada.
Los principios y fragmentos de código no se enumerarán más aquí. Si está interesado, puede ir al sitio web oficial de Huggingface para verlo.
Construir GPT localizado
Si no desea compartir información o datos privados (como financieros, médicos y otras industrias y empresas específicas) con OpenAI, Xunfei, Baidu u otros proveedores de IA similares, o si algún conocimiento nuevo no está en el modelo de preentrenamiento, entonces Tienes que utilizar una base de conocimientos externa para resolver estos problemas. Este artículo describe cómo utilizar la API LocalGPT para crear su propio asistente personal de IA.
LocalGPT es una herramienta poderosa para cualquiera que busque ejecutar un modelo similar a GPT localmente, lo que permite privacidad, personalización y uso sin conexión.
Proporciona una manera de hacer preguntas sobre documentos o conjuntos de datos específicos, encontrar respuestas en esos documentos y realizar estas operaciones sin depender de una conexión a Internet o servidores externos.
LocalGPT es muy sencillo de usar y admite modelos de razonamiento en varios tipos de arquitecturas. Pero debe confirmar con Huggingface y el modelo deseado. Debajo de la descripción de la tarjeta Modelo, hay una arquitectura compatible con el modelo. Puede descargar la versión deseada del modelo (dígitos de cuantificación, etc.) en Archivo y versiones.

LangChain
LangChain es un conjunto de marcos desarrollados para aplicaciones de modelos de lenguaje grandes. Admite las siguientes características:
- Consciente de los datos: conectar modelos lingüísticos con otras fuentes de datos
- Agente: permite que el modelo de lenguaje interactúe con su entorno. El inicio rápido
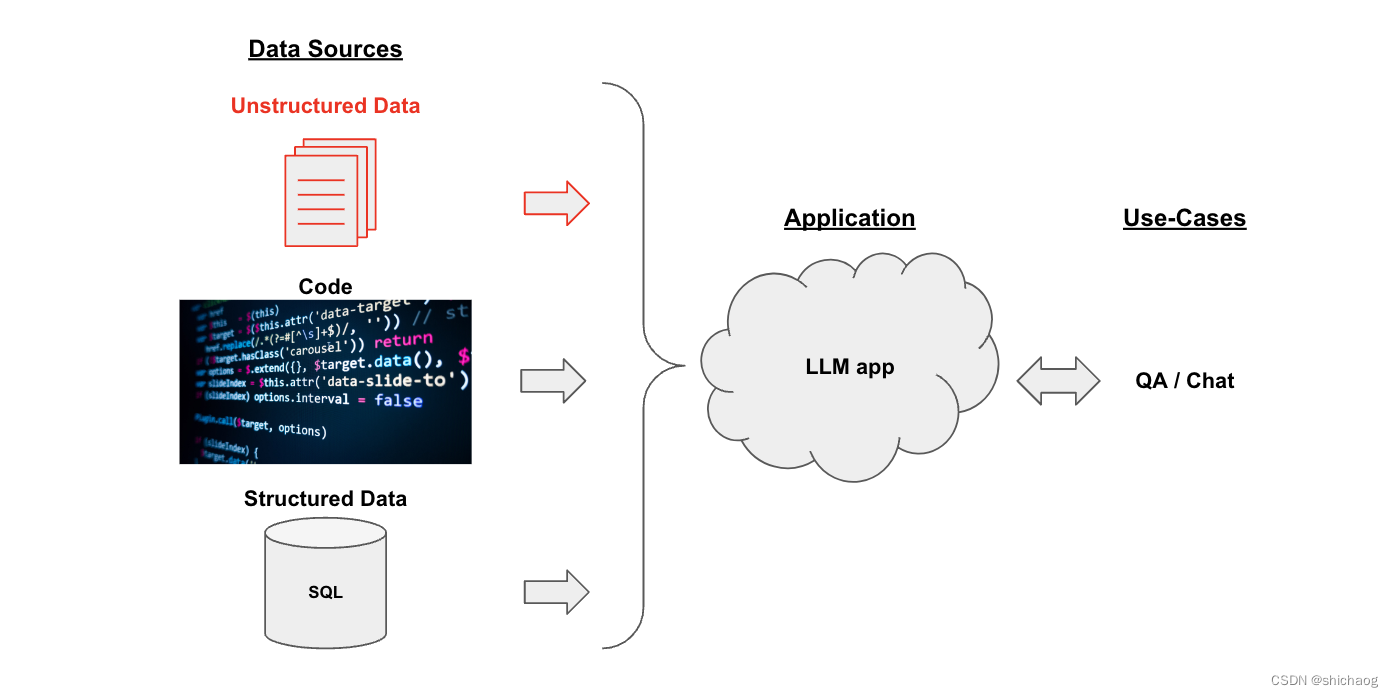
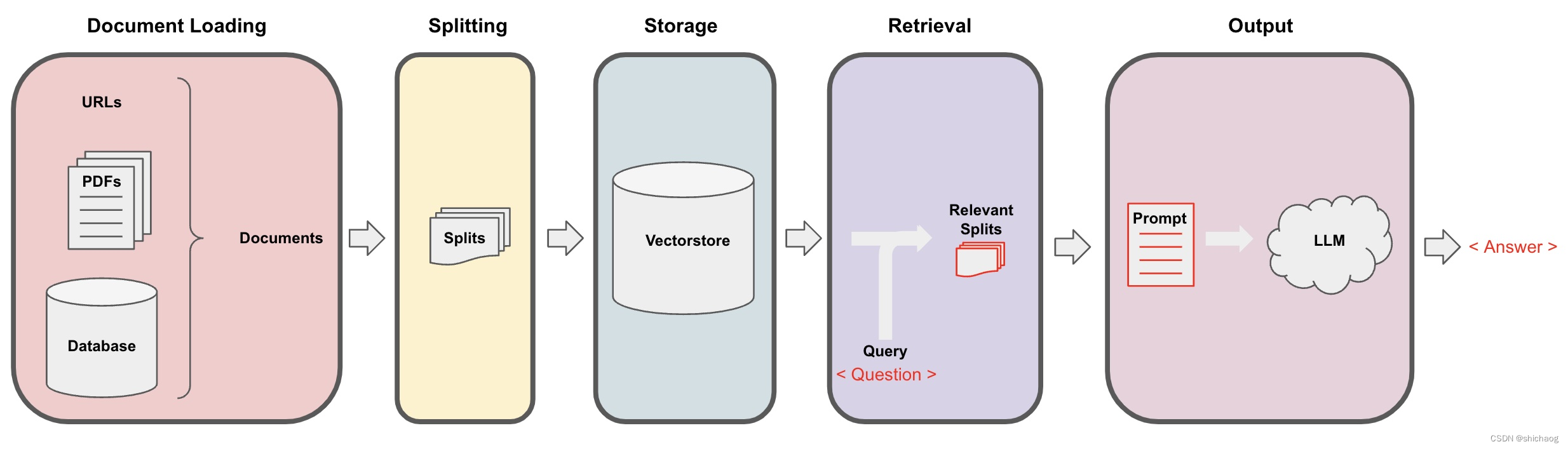
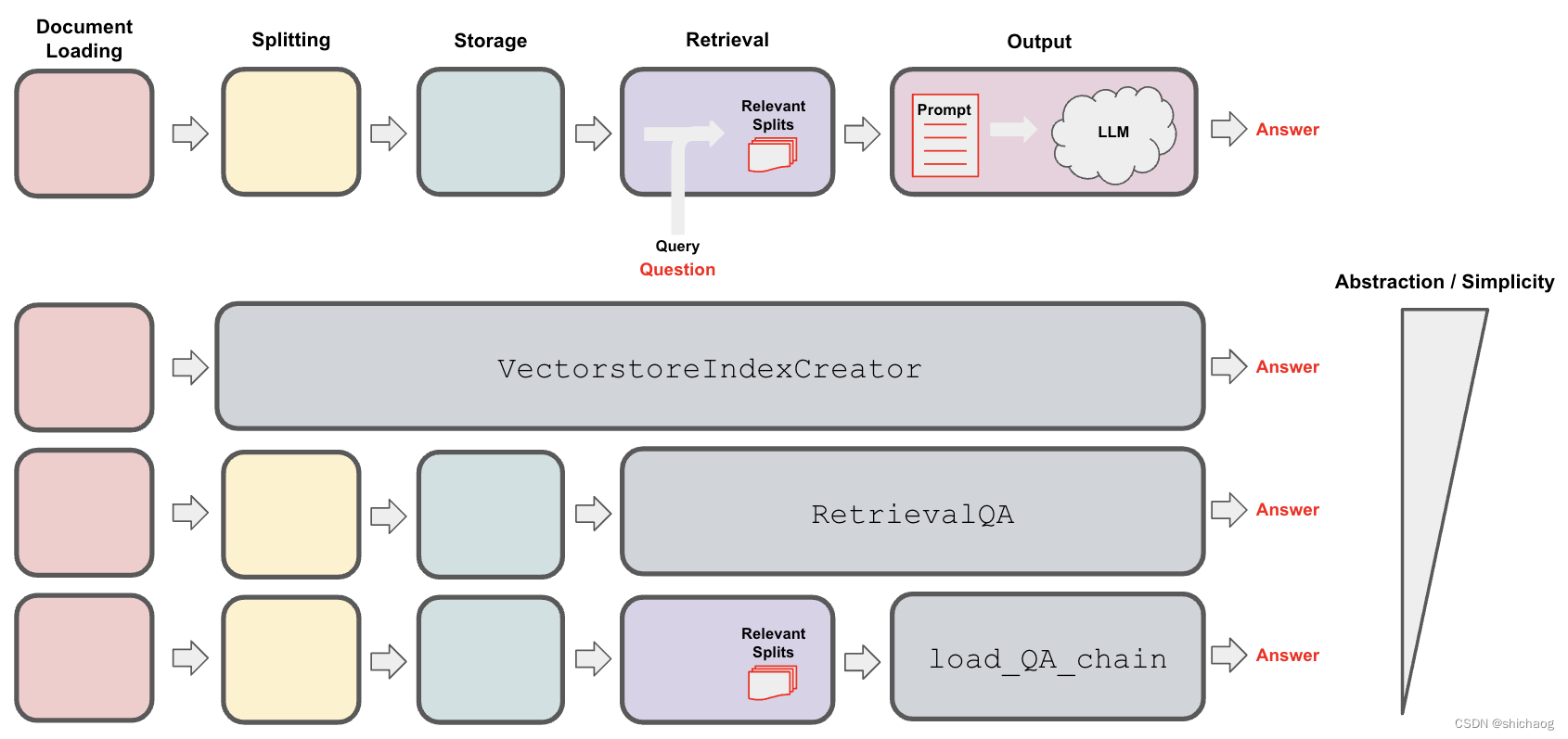
en el sitio web oficial de LangChain se basa en openAI como ejemplo, pero aquí tomamos LlaMA-2 como ejemplo y LocaGPT ya está empaquetado. Para el escenario de control de calidad, primero es necesario convertir la fuente de datos (datos no estructurados) en datos estructurados y luego inyectarlos en el modelo de lenguaje grande. El diagrama de relación aproximado es el siguiente. La conversión a una estructura estructurada se divide en varios pasos de segmentación, almacenamiento y extracción. El proceso general es el siguiente: El proceso detallado de control de calidad es el siguiente.