prefacio
Los artículos anteriores se centraron en la estrategia de decodificación del modelo de lenguaje, hoy entraremos en el artículo avanzado ¿Cómo mejorar el efecto del modelo cuando el efecto de la estrategia de decodificación es limitado y la modificación de las palabras indicadoras no es satisfactoria? En este momento, necesitamos afinar el modelo de lenguaje grande , es decir, afinar . Generalmente, los modelos de lenguaje grande que usamos son entrenados por otros en grandes conjuntos de datos de propósito general, o han sido ajustados en campos especiales, por lo que pueden no ser adecuados para el contenido generado por el modelo que necesitamos actualmente.
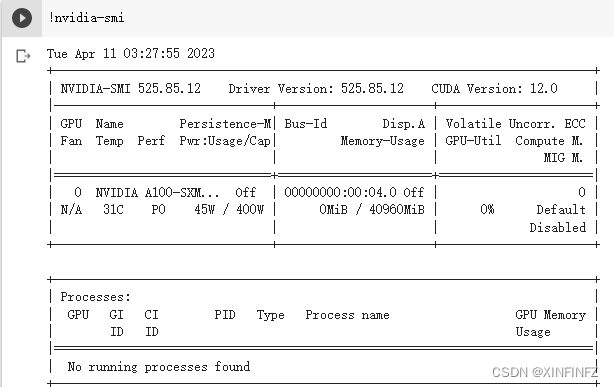
Este artículo tomará el modelo bloom-1b1 como ejemplo y usará la biblioteca xturing para el ajuste fino. Dado que el ajuste fino es particularmente costoso para la memoria de video , aquellos que no tienen una tarjeta de memoria de video grande pueden usar el servicio de colaboración de Google como mí para asegurar 16GiB y más de memoria de video. Puede verificarlo escribiendo nvidia-smi
en la línea de comando , como se muestra en la figura a continuación, hay 40960 MiB, es decir, 40 Gib.
Preparación del conjunto de datos

Primero, prepare un archivo json, que contiene una lista grande que contiene muchos dictados. El formato del diccionario es {"instrucción": xxx, "entrada": "", "salida": xxx}, instrucción significa una pregunta o instrucción, entrada significa entrada, a veces los problemas matemáticos necesitan indicar el valor de la variable, salida significa salida, es decir, el contenido de la generación de texto.
En este ejemplo, utilicé el conjunto de datos de respuesta a preguntas en chino que extraje yo mismo. Estaba escrito en el artículo anterior. Si está interesado en probarlo usted mismo, no se publicará aquí. Y debido a que el bloqueo es muy estricto, solo cavando Más de 500 de las preguntas y respuestas fueron recopiladas como un ejemplo de puesta a punto.
Después de preparar el json, primero instale la biblioteca de conjuntos de datos con pip y luego genere el conjunto de datos de formato a través del siguiente código:
import json
from datasets import Dataset, DatasetDict
def preprocess_alpaca_json_data(alpaca_dataset_path: str):
alpaca_data = json.load(open(alpaca_dataset_path))
instructions = []
inputs = []
outputs = []
for data in alpaca_data:
instructions.append(data["instruction"])
inputs.append(data["input"])
outputs.append(data["output"])
data_dict = {
"train": {
"instruction": instructions, "text": inputs, "target": outputs}
}
dataset = DatasetDict()
# using your `Dict` object
for k, v in data_dict.items():
dataset[k] = Dataset.from_dict(v)
dataset.save_to_disk(str("./alpaca_data"))
preprocess_alpaca_json_data('你的数据集.json')
Después de generar la función de llamada, se generará una carpeta, cuyo contenido se muestra en la figura:
el código
En primer lugar, si se está ejecutando en colab, asegúrese de que el tiempo de ejecución sea el correcto:
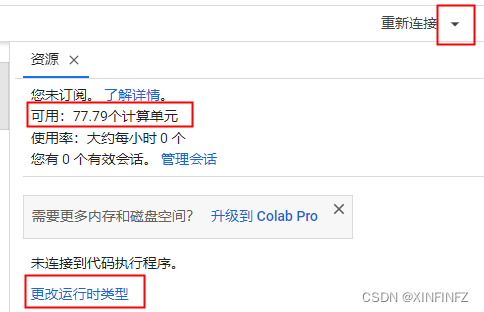
seleccione gpu-estándar o avanzado. Las unidades informáticas se consumirán cada hora. Estoy aquí porque abrí un miembro de colab el mes pasado, por lo que hay unidades informáticas 100. Los usuarios comunes sin membresía solo pueden usar la prostitución gratuita estándar.
Luego instale las bibliotecas necesarias. Se recomienda ejecutar bajo Linux sin usar colab, a menos que tenga la confianza suficiente para compilar VS bajo Windows :
!pip install accelerate
!pip install xturing --upgrade
El siguiente paso es ejecutar el código sin problemas:
from xturing.datasets.instruction_dataset import InstructionDataset
from xturing.models.base import BaseModel
instruction_dataset = InstructionDataset("/content/alpaca_data")
model = BaseModel.create("bloom_lora")
Complete la ruta de la carpeta recién generada y luego complete bloom_lora en el método .create El valor predeterminado es el modelo bloom_1b1 y use lora para acelerar el entrenamiento.
# Finetuned the model
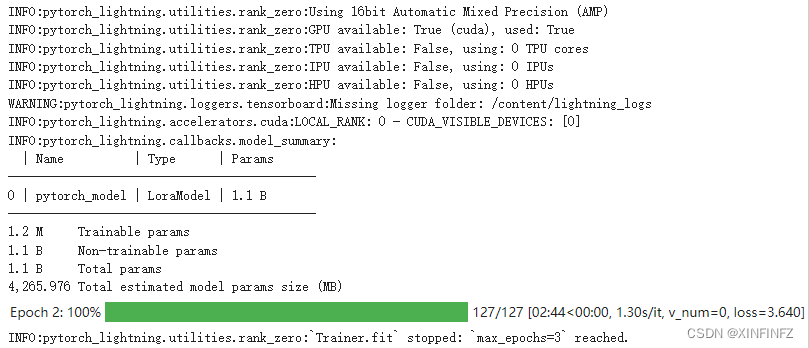
model.finetune(dataset=instruction_dataset)
Comience a entrenar, el valor predeterminado es tres rondas, y el conjunto de datos en este ejemplo tardó unos seis minutos en ajustarse.
Después del entrenamiento, intente generar, primero cambie la configuración de generación, que es la estrategia de decodificación:
generation_config = model.generation_config()
generation_config.top_k = 50
generation_config.do_sample = True
generation_config.top_p = 0.8
generation_config.max_new_tokens=512
Pruebe las preguntas de búsqueda populares de hoy:
# Once the model has been finetuned, you can start doing inferences
output = model.generate(texts=["第一视角进入风暴中心,是种什么体验?"])
print("Generated output by the model: {}".format(output))
El resultado es el siguiente:
登陆后第一时间发现风有多狂,能感觉空气怎么突然就凉爽了。
在云层中翻滚,能感受到海面下风的肆虐,云层下也有很多小冰块在打滚。风会从上向下刮,就像是在刮雪一样,刮的特别猛烈,在云层下翻滚。
风暴中心,是风暴的终点,是整个风暴的中心,风向是逆着往复,风向逆着风向,风暴中心就会变成云层,然后刮的特别快,在云层下翻滚,最后消失。
风暴中心,是风暴的最顶端,风向是顺着往复,风向顺着风向,风暴中心就会变成云层,然后刮的特别快,在云层下翻滚,最后消失。
El mismo problema utiliza el mismo código de configuración para comparar el efecto de generación del modelo predeterminado :
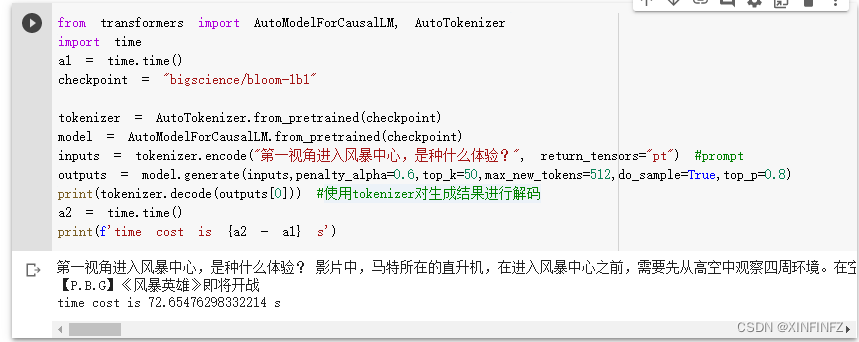
一视角进入风暴中心,是种什么体验?
影片中,马特所在的直升机,在进入风暴中心之前,需要先从高空中观察四周环境。
在空中,除了气象台、直升机、救援队伍,还有各种各样的设备,包括直升机吊舱、直升机降落伞、直升机加油机、直升机导航仪等。
这些设备中,最为核心的部分就是直升机吊舱,
因为直升机吊舱可以搭载直升机和飞机,直升机吊舱的重量相当于一架直升机的载荷,因此可以搭载更多直升机。
Se puede encontrar que el chino del modelo predeterminado tiene que ver con los helicópteros, lo cual está fuera de tema. . . El efecto mejora significativamente.
Luego cambie la generación de oraciones para ver el efecto después del ajuste:
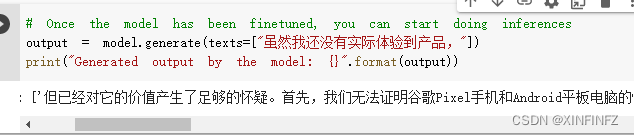
但已经对它的价值产生了足够的怀疑。
首先,我们无法证明谷歌Pixel手机和Android平板电脑的性能有多强。
第二,由于谷歌没有在手机上开发过操作系统,因此谷歌无法从Android平板电脑获得与谷歌Pixel类似的安全性能,即使谷歌Pixel手机使用安卓系统,但Android平板电脑的设备也可能使用非谷歌Android设备,例如,Windows系统。在Android平板电脑上,Android设备运行的是非谷歌Android设备。
第三,谷歌Android平板电脑的电池是无法在谷歌Android平板电脑上长期使用的。
Modelo predeterminado:
虽然我还没有实际体验到产品,所以不敢给一个准确的答案。
但是从实际体验来说,这款产品确实是十分不错的,我个人觉得颜值和外观设计都是十分不错的,而且售价也确实是不错。
不过我还是建议大家在购买前先了解下这款产品的信息。</s>
De lo anterior se puede ver que el ajuste fino tiene un efecto, entonces, ¿cómo guardo el modelo generado? De hecho, ya existe una carpeta modelo_guardado en el directorio, simplemente arrástrela al disco duro de Google para empaquetarla y descargarla.