En un abrir y cerrar de ojos, mi blog está a punto de ser 0. El instructor comenzó a dejarme ver el video para comprender el contenido de la dirección multimodal y sentar las bases nuevamente, desde Python, PNL, comprensión de video y finalmente agregar optimización convexa, paso a paso, aprendizaje loco para unas vacaciones de verano. Escriba este blog como mis notas y enlaces a buenos artículos para futuras revisiones.
¿Cuáles son las direcciones de investigación y los logros más importantes en el campo de la comprensión de video en Python desde el comienzo hasta el abandono de la visión artificial?
Artículo largo de mil caracteres que habla sobre la comprensión del video Descripción general de la comprensión del video
: reconocimiento de acción, posicionamiento temporal de la acción, incrustación de videoResumen del
modelo de clasificación de acción/comprensión del video (actualización 2022.06.28
) Modelo de recuperación/
preentrenamiento multimodal de video Modelo de recuperación/preentrenamiento
multimodal de video (2) Posicionamiento temporal de texto de video multimodal
Notas de artículo de preentrenamiento multimodal
1. Modelo grande multimodal
1.1 Arquitectura unificada
Los modelos grandes multimodales son Transformer basedarquitecturas, texto incrustado de NLP, parches de imagen de incrustación de CV, extracción de características de datos de imagen, video, texto y voz, conversión en tokens, alineación de diferentes características modales y envío a Transformer para su cálculo.
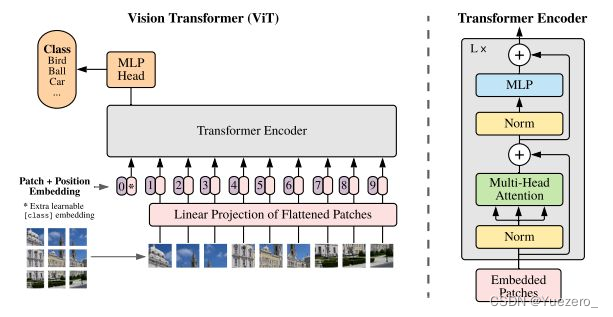
1.2 Base del modelo
1.2.1 Transformador
Transformer es un modelo de secuencia a secuencia basado en la autoatención. Utiliza un mecanismo de atención de múltiples cabezas capaz de prestar atención a la información en diferentes ubicaciones en paralelo. Los transformadores se utilizan ampliamente en el campo del procesamiento del lenguaje natural, como la traducción automática y la generación de texto.
1.2.2 ViT
ViT (Vision Transformer) es un método para aplicar el modelo Transformer a las tareas de clasificación de imágenes. Divide la imagen en una serie de parches y alimenta cada parche como una secuencia en el modelo de Transformador. A través del mecanismo de autoatención, ViT puede capturar información visual global y local en la imagen para lograr la clasificación de la imagen.
1.2.3 Berto
Bert (Representaciones de codificador bidireccional de Transformers) es un modelo de codificador de transformador bidireccional que proporciona capacidades de comprensión profunda del idioma a través del entrenamiento previo y el ajuste. A diferencia del modelo tradicional de lenguaje unidireccional, Bert también considera la información del contexto, lo que hace que tenga ventajas en tareas como la desambiguación del sentido de las palabras y el reconocimiento de entidades nombradas.
1.2.4 Atención cruzada
CrossAttention es un mecanismo de atención en el modelo Transformer. A diferencia del mecanismo de autoatención, CrossAttention permite que el modelo se centre simultáneamente en otra secuencia relacionada mientras procesa la secuencia de entrada. CrossAttention se usa a menudo en tareas multimodales, como alinear imágenes y texto o generar representaciones multimodales.
1.2.5 CLIP
CLIP (Contrastive Language-Image Pretraining) es un modelo de preentrenamiento multimodal que puede procesar imágenes y texto simultáneamente. Mediante el aprendizaje contrastivo de imágenes y textos, CLIP proporciona un espacio visual y semántico compartido, lo que permite la comparación directa y la recuperación de imágenes y textos.
1.2.6 GPT
GPT (Transformador preentrenado generativo) es un modelo de generación de lenguaje preentrenado basado en el modelo Transformer. GPT aprende la sintaxis y la semántica del lenguaje a través de un entrenamiento no supervisado a gran escala y puede generar textos coherentes y realistas. GPT ha logrado resultados notables en tareas como la generación de texto y los sistemas de diálogo.
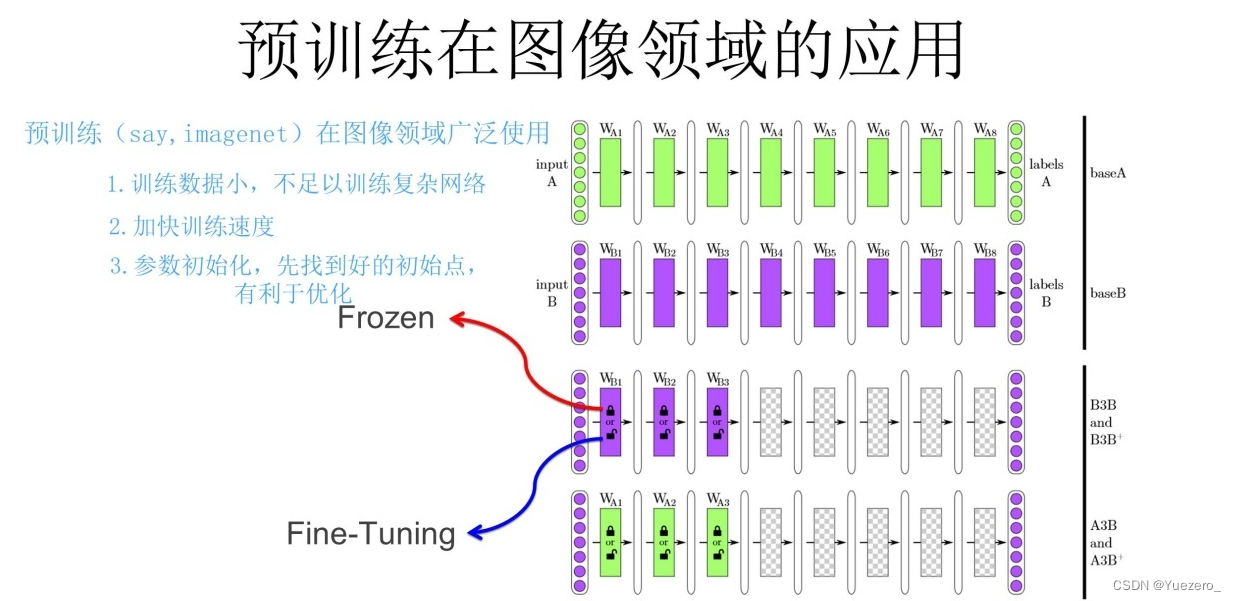
1.2.7 Pre-entrenamiento
Entrenamos un modelo A a través del conjunto de datos de ImageNet. Dado que las funciones de aprendizaje superficial de la CNN mencionadas anteriormente son particularmente versátiles, podemos hacer algunas mejoras en el modelo A para obtener el modelo B (dos métodos):
- Congelación: los parámetros de la capa superficial usan los parámetros del modelo A, los parámetros de la capa alta se inicializan aleatoriamente y los parámetros de la capa superficial permanecen sin cambios, y luego usan las 30 imágenes proporcionadas por el líder para entrenar los parámetros.
- Ajuste fino: los parámetros de la capa poco profunda usan los parámetros del modelo A, los parámetros de alto nivel se inicializan aleatoriamente y luego usan las 30 imágenes proporcionadas por el líder para entrenar los parámetros, pero aquí los parámetros de la capa poco profunda seguirán cambiando con el entrenamiento de la tarea.
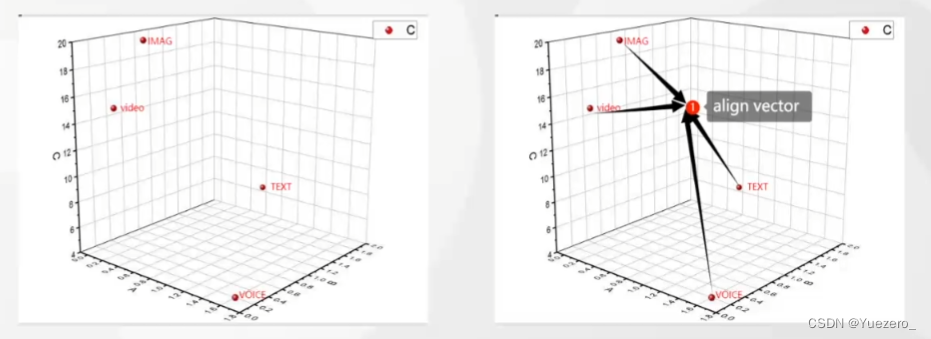
1.2.6 Alineación modal
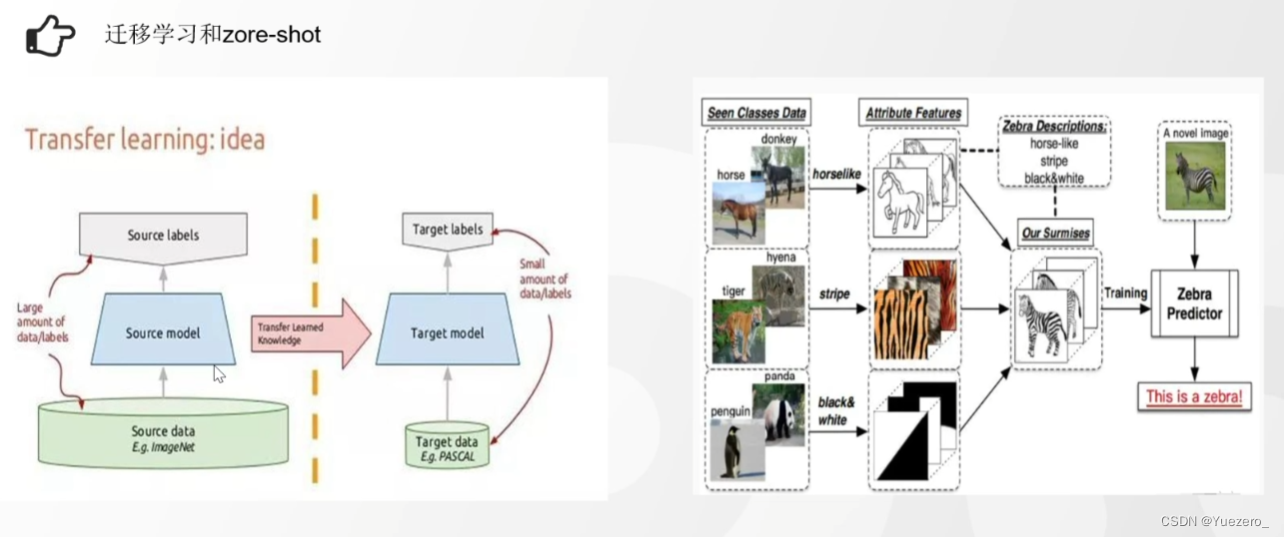
1.2.7 Migración y aprendizaje de tiro cero
El aprendizaje de transferencia (modelo pequeño) generalmente usa un modelo más pequeño, y el conocimiento y los parámetros entrenados en el dominio de origen se pueden transferir al dominio de destino, acelerando así el proceso de aprendizaje de la tarea de destino. Este método puede mejorar la capacidad de generalización y el efecto del modelo, y también puede lograr mejores resultados cuando los datos son escasos.
Zero-shot (modelo grande) resuelve el problema de clasificar muestras de categorías no vistas. En el aprendizaje de disparo cero, generalmente usamos modelos grandes, como GPT-3, etc. Estos modelos adquieren un amplio conocimiento mediante el aprendizaje de datos a gran escala durante la fase de entrenamiento y son capaces de clasificar mediante la asociación de conocimientos de diferentes dominios. Al explotar las capacidades de generalización de estos grandes modelos, podemos clasificar en categorías invisibles, lo que permite un aprendizaje de tiro cero.
1.2.8 Lectura ampliada
CLIP——Coincidencia de imagen y texto
(1) Preentrenamiento de codificadores de imagen y texto : <图片,文本>pares de entrenamiento, continuar 对比学习. Para N imágenes y N textos, use la Bertsuma ViTpara extraer las características del texto y las imágenes (768 dimensiones), y multiplique los vectores en pares para obtener la <图片,文本>similitud del coseno entre pares (multiplicación de vectores). Aprendizaje de comparación de etiquetas : las imágenes y los textos coincidentes en la diagonal son muestras positivas (par correcto = 1), y los otros no coincidentes son muestras negativas (par incorrecto = 0). Estas dos etiquetas calculan la retropropagación de pérdida, maximizan la similitud de coseno de los pares de muestras positivas, minimizan la similitud de coseno superior de los pares de muestras negativas y restringen los parámetros de modificación de descenso de gradiente y Bertanteriores ViT. BertEl pre-entrenamiento final da como resultado codificadores de texto e imagen ViT.
(2) y (3) Zero-shot para lograr la coincidencia de imagen y texto : De acuerdo con el entrenamiento previo de ahora, cualquier texto dado (perro, automóvil, gato...) y la imagen se utilizan para calcular la similitud del coseno (<图片,文本> multiplicar ) . (Atención bidireccional de Bert) (2) Tarea de dos categorías ITM : el vector extraído por el codificador de imagen y el vector extraído por el segundo codificador de texto realizan atención cruzada, y el vector fusionado realiza una tarea de dos categorías (el texto y la imagen describen lo mismo), para alinear las muestras difíciles del texto y la imagen con una granularidad más fina. (atención bidireccional de bert) (3) Generar tarea LM
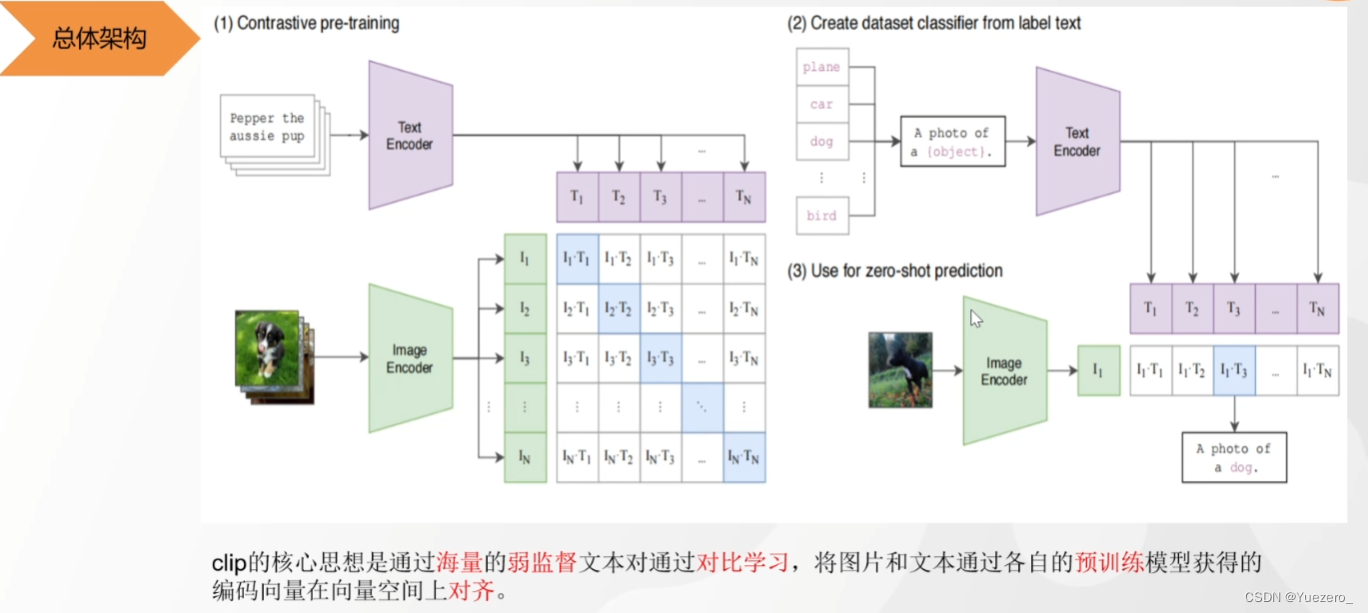
: El vector extraído por el codificador de imagen y el vector extraído por el tercer codificador de texto realizan atención cruzada, y el vector fusionado realiza la tarea de generación de texto (generar texto de descripción basado en la imagen). (Atención unidireccional de gpt)
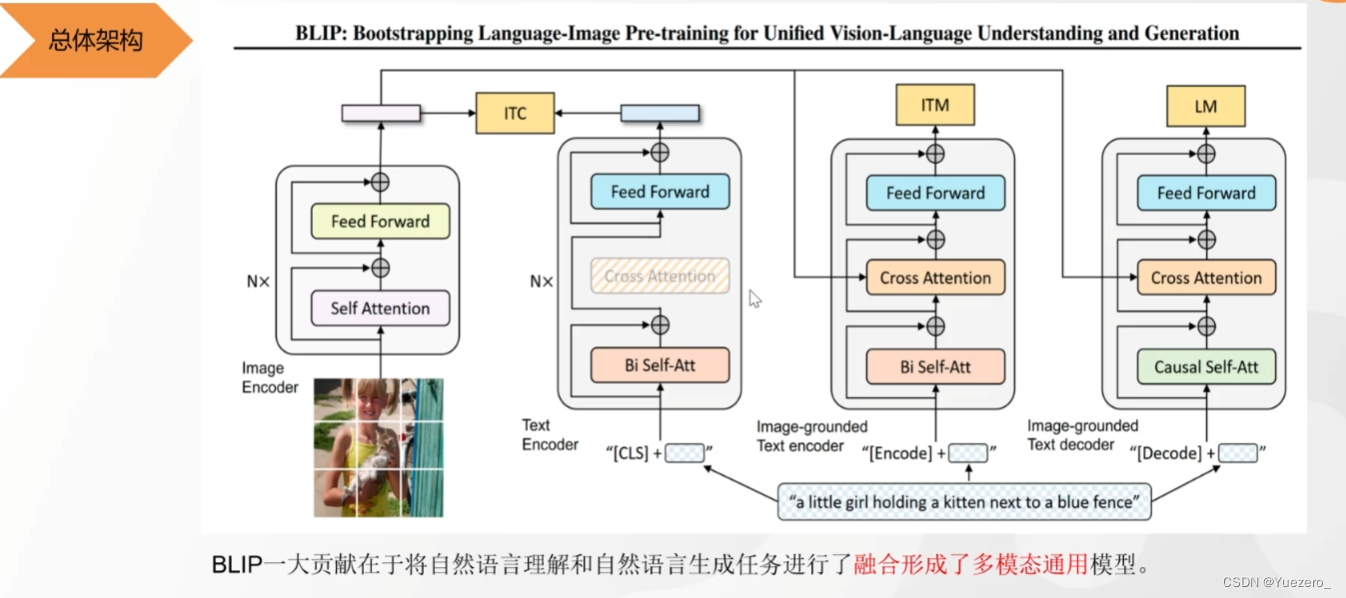
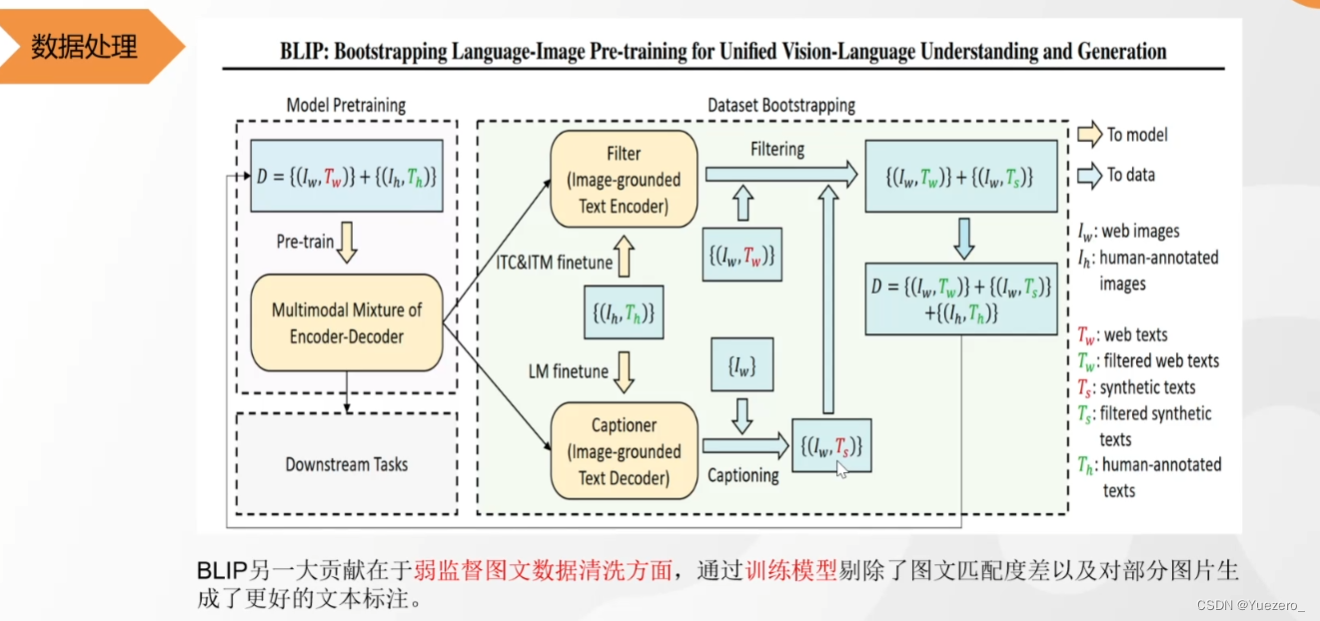
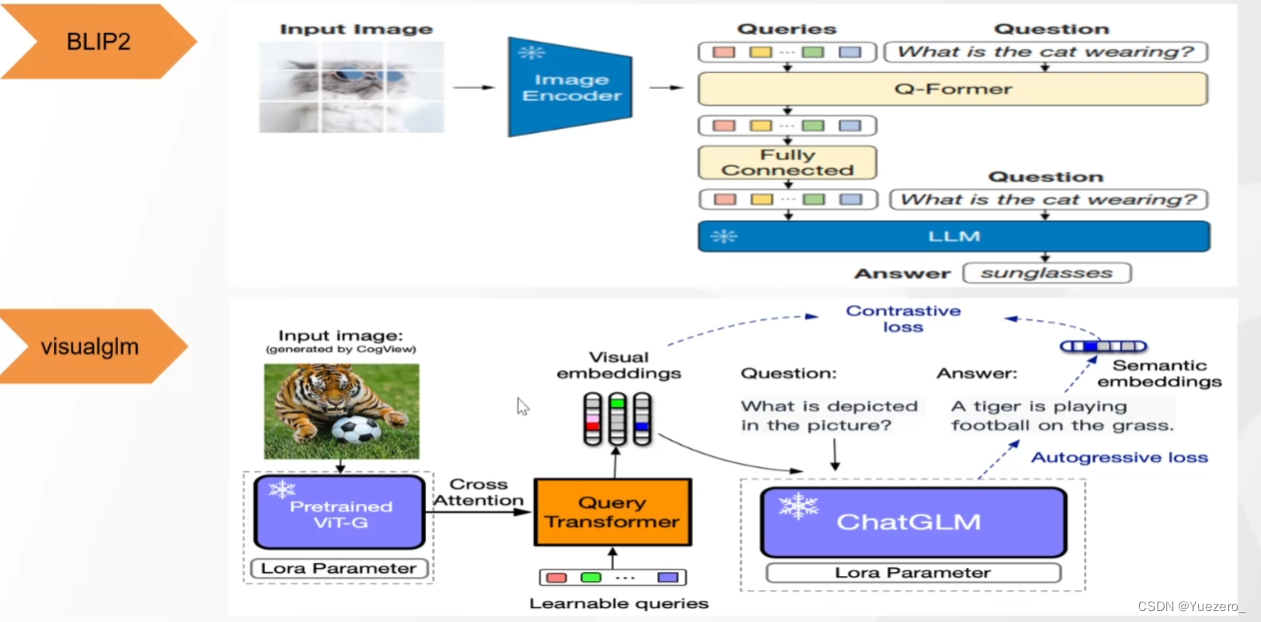
BLIP2——Coincidencia de texto gráfico y texto gráfico
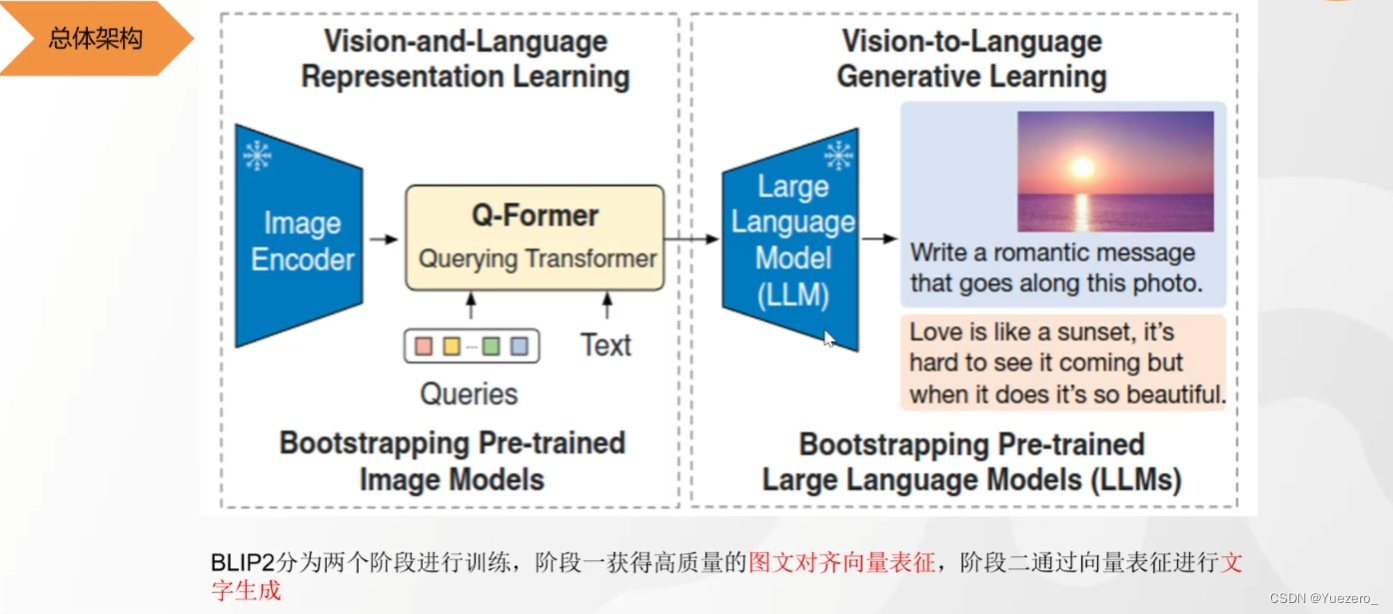
(1) Fase 1: use QFormer para proyectar el vector de características de la imagen en el espacio de características del texto, de modo que LLM pueda comprender las características del vector de la imagen.
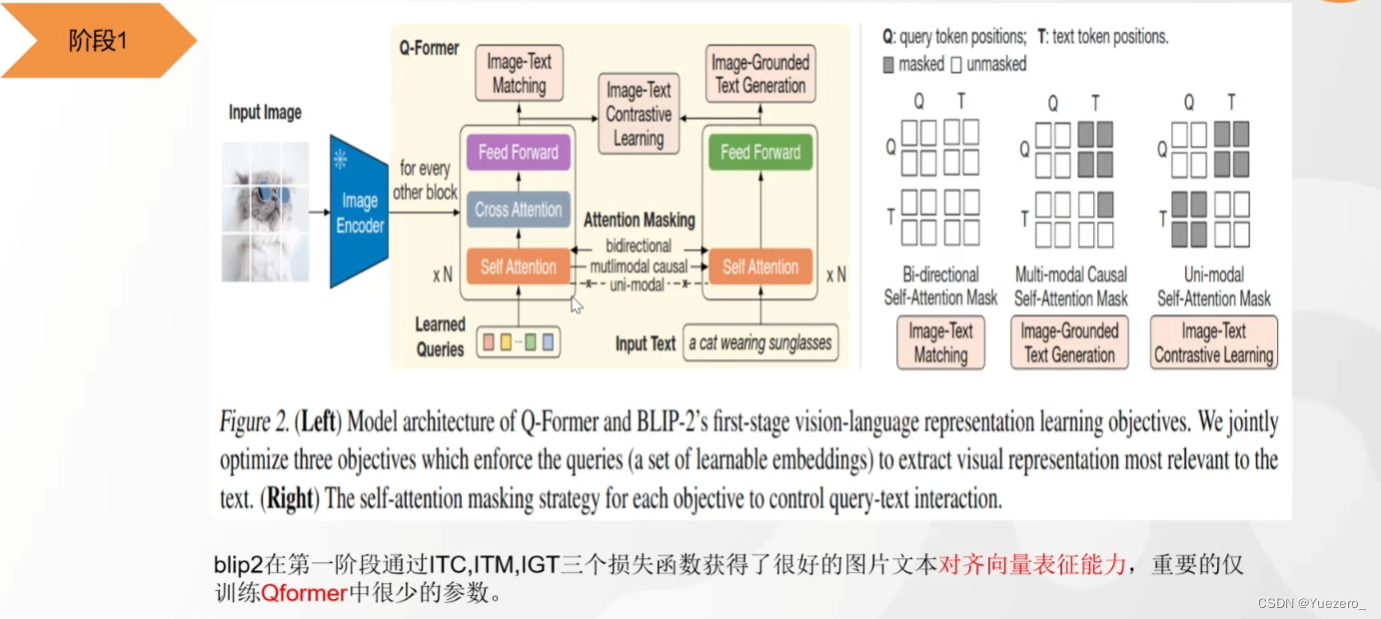
(2) Fase 2: Ingrese las características de la imagen en LLM (como un aviso) para generar una descripción de texto de la imagen correspondiente.
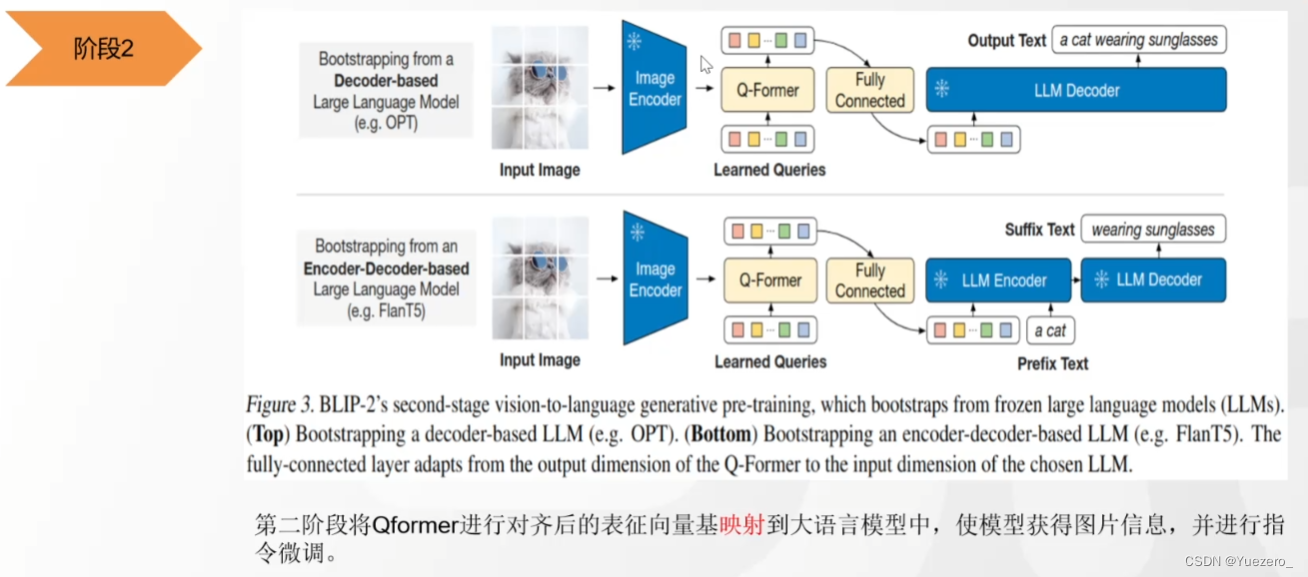
La razón por la que BLIP2 no comprende los detalles en su lugar: la tokenización a nivel de parche de ViT no maneja los detalles en su lugar.

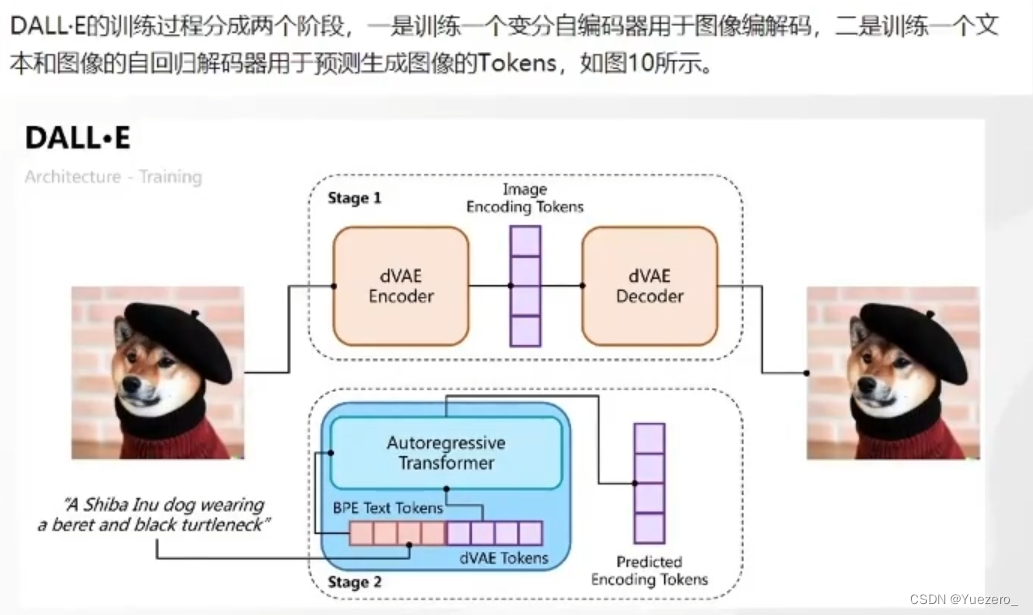
DALL·E——Gráfico de Vensen
(1) Proceso de entrenamiento: Codifique la imagen en un vector caliente y luego decodifique en un perro para lograr una compresión de imagen sin pérdidas. (pérdida es la diferencia entre la imagen original y la imagen decodificada)
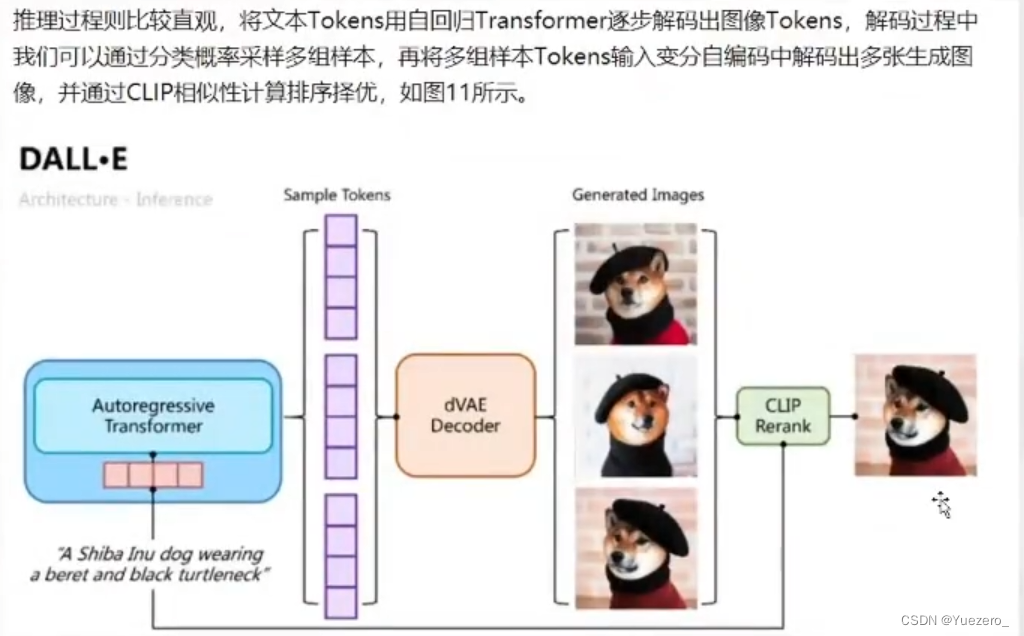
(2) Proceso de razonamiento: el codificador autorregresivo (GPT) predice varios tokens de imagen a través de tokens de texto, y luego los decodifica en las imágenes correspondientes.Finalmente, CLIP se usa para la coincidencia de imagen y texto para obtener la imagen más similar al texto en la imagen decodificada.
VisualGLM: versión china de BLIP2
entrenada con Lora.
Pero la generación de texto a menudo no tiene sentido, la razón es que el tamaño del modelo de ChatGLM es demasiado pequeño 7B.
2. Base modelo grande
¿Qué modelos grandes aprender? (Maquetas de trenes de diferentes escalas para adaptarse a diferentes escenarios)
- Mockups en línea: el grupo de Mockups de la serie OpneAI

- Modelos grandes de código abierto: ChatGLM 6B y VisualGM 6B

2.1 Modelo grande en línea
Se requiere la clave de OpenAI, y OpenAI comparte los datos privados, que no se pueden implementar localmente y solo pueden llamar a la interfaz API para ajustar el gran modelo de OpenAI en línea.
Modelo de lenguaje:

Modelo grande multimodal gráfico:

modelo de voz:

Modelo de incrustación de texto grande: de acuerdo con la codificación semántica del texto, cuanto más cerca está la semántica, más cerca están los vectores.

Revisa la maqueta:

Programación modelo grande:

2.2 Modelo grande de código abierto
Utilice el marco de ajuste fino de código abierto para ajustar la capacitación de acuerdo con las tareas posteriores, y también se puede implementar localmente.
Tabla de clasificación OPEN LLM actualizada en tiempo real
ChatGLM: modelo grande de código abierto en chino




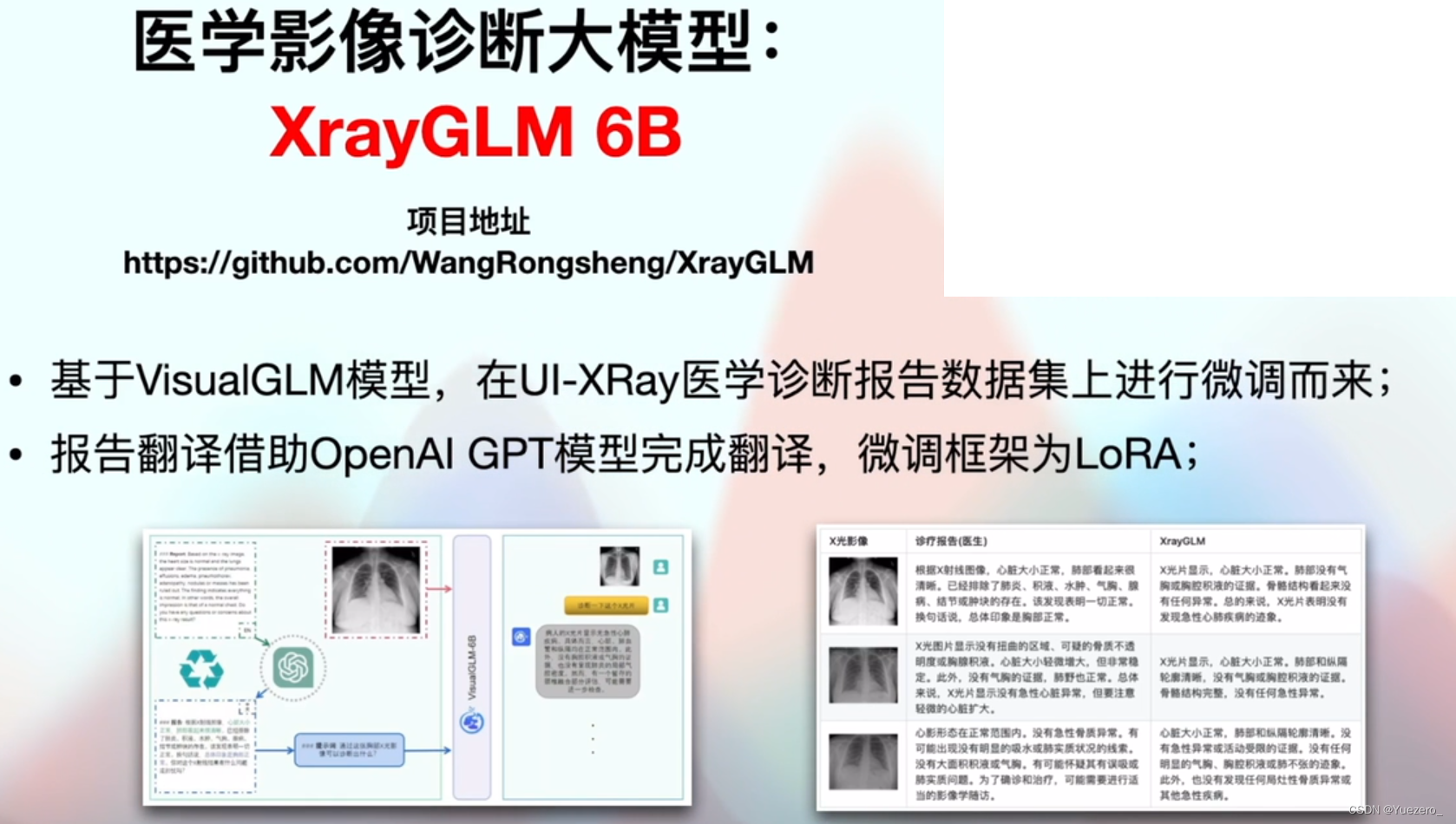
VisualGLM: modelo grande de código abierto multimodal chino


3. Ajuste fino del modelo grande
-
Full Fine-tuning (FT) ajusta con precisión todos los parámetros del modelo preentrenado, incluido el extractor de características subyacente y el clasificador de nivel superior. Este método generalmente requiere grandes recursos informáticos y mucho tiempo de capacitación, pero puede lograr un rendimiento relativamente bueno.
-
El ajuste fino parcial (PEFT) es un método de ajuste fino más eficiente, que solo ajusta algunos parámetros. Específicamente, congelamos los parámetros subyacentes del modelo preentrenado (como el extractor de características) sin realizar un ajuste fino y solo ajustamos el clasificador de nivel superior o una parte de los parámetros de nivel superior. Esto puede completar el proceso de ajuste más rápido, reducir el consumo de recursos informáticos y el tiempo de capacitación, al tiempo que conserva el conocimiento de los parámetros subyacentes hasta cierto punto.
-
El ajuste jerárquico basado en el aprendizaje por refuerzo (RLHF) utiliza ideas de aprendizaje por refuerzo para guiar el proceso de ajuste. Por lo general, durante el ajuste fino, definimos una función de recompensa y usamos el aprendizaje por refuerzo para maximizar la recompensa. De esta manera, el modelo puede actualizar los parámetros de manera más inteligente durante el proceso de ajuste fino, para obtener un mejor rendimiento y capacidad de generalización.


3.1 Ajuste fino eficiente de PEFT

3.1.1 LoRA


3.1.2 Sintonización de prefijos

3.1.3 Sintonización rápida

3.1.4 Ajuste P V2

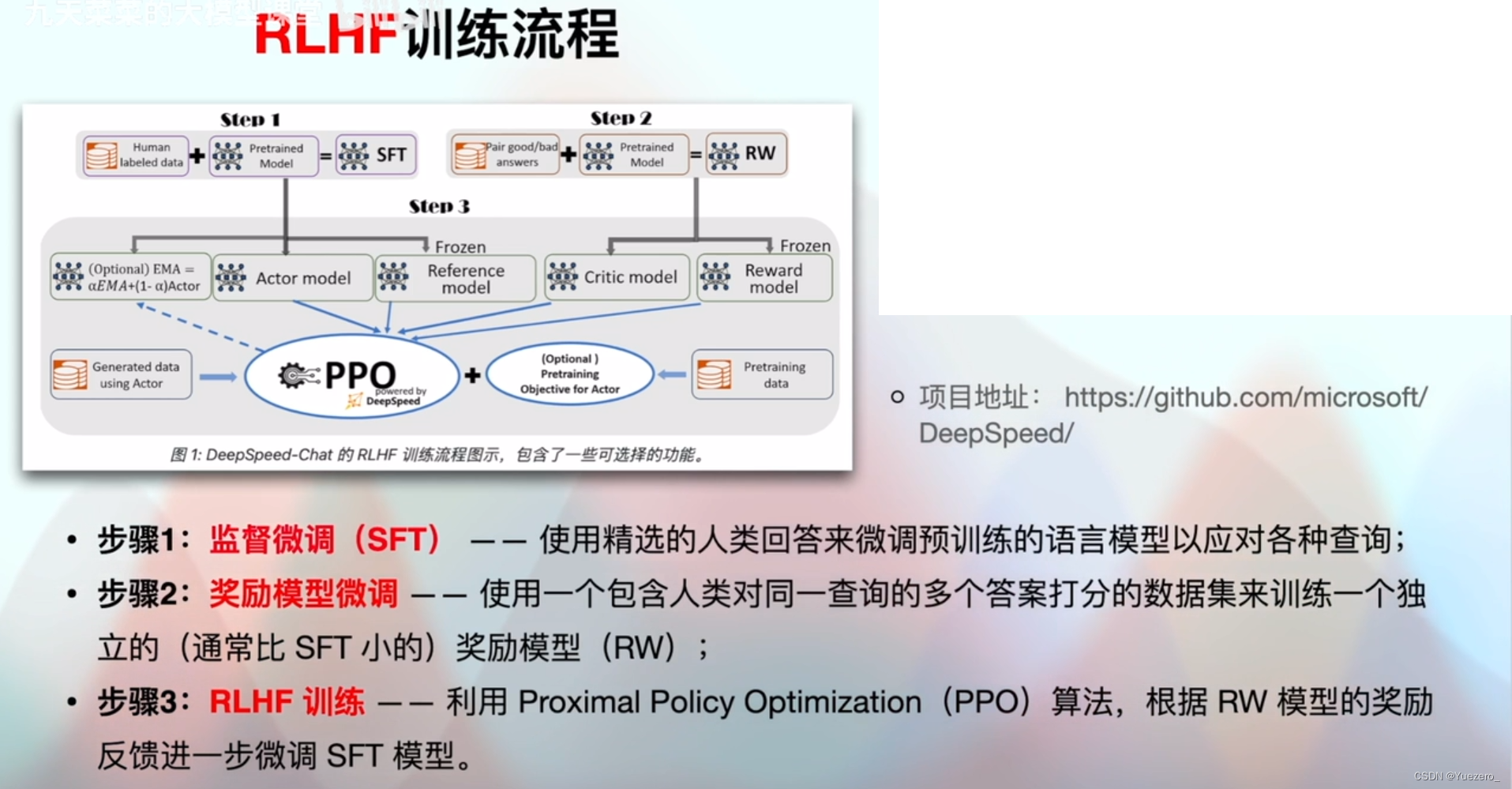
3.2 RLHF

4. Requisitos de hardware y sistema operativo

4.1 Tarjeta gráfica
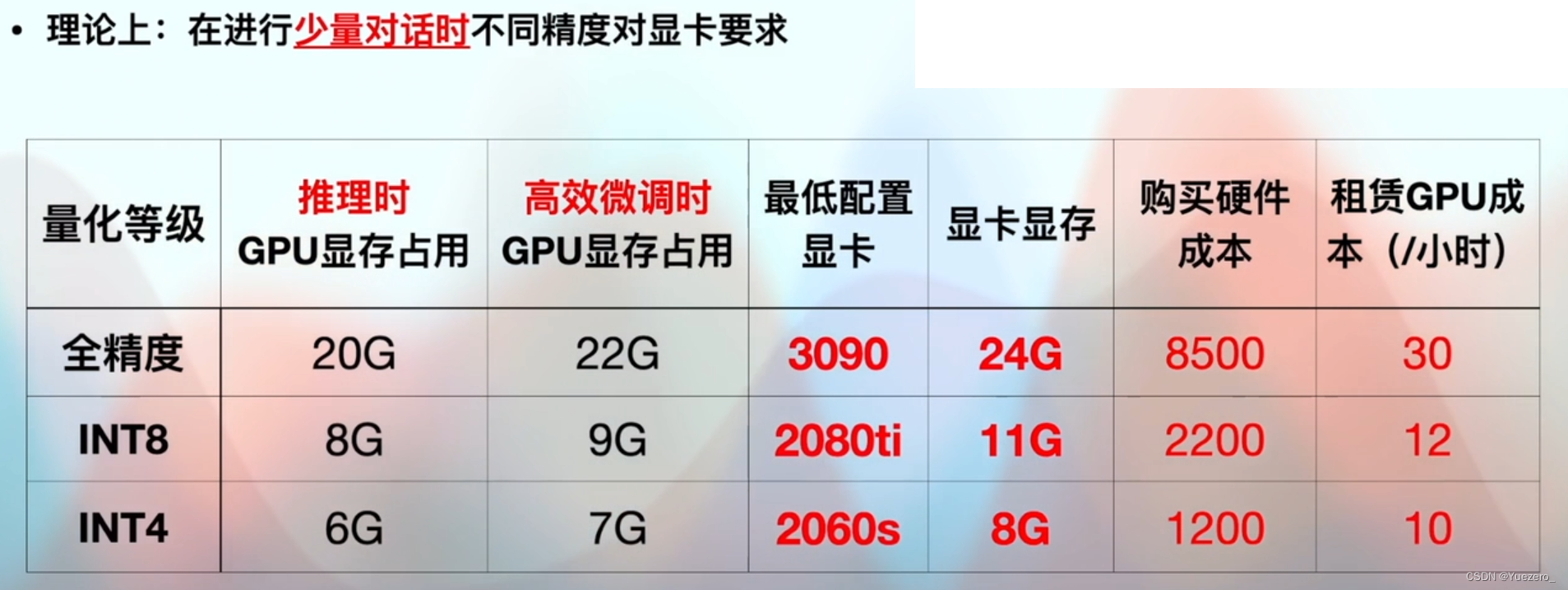
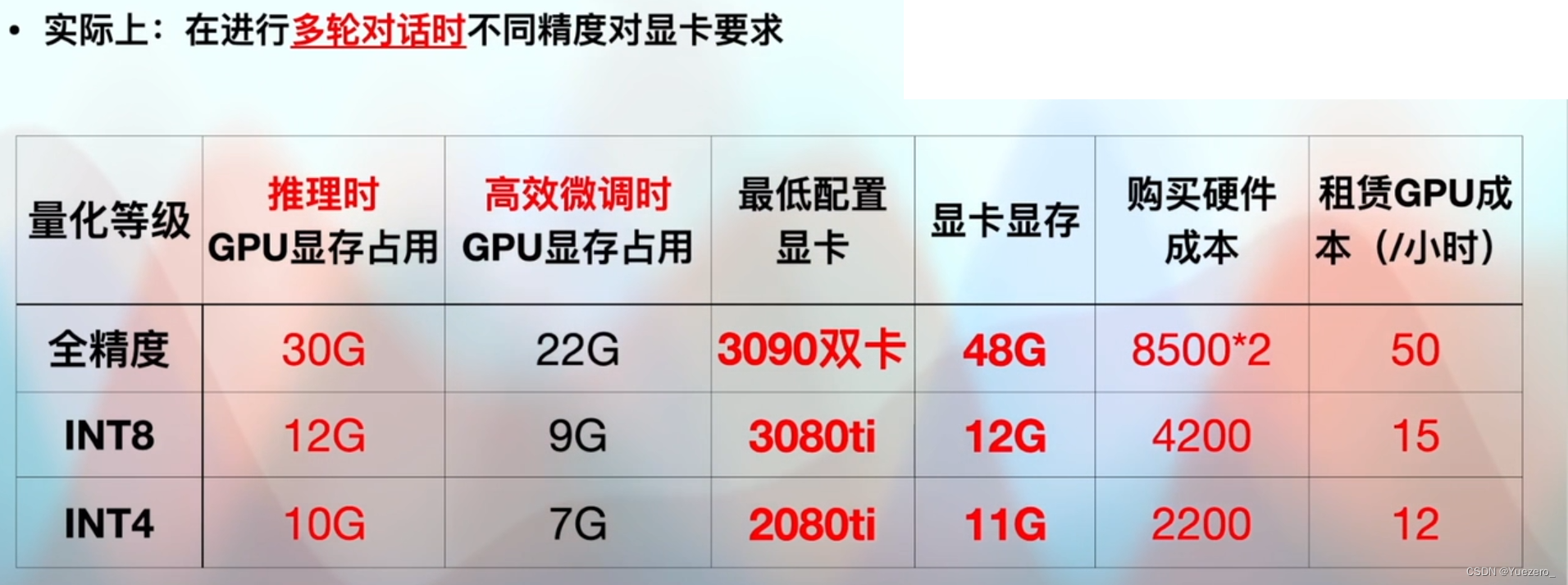



4.2 Sistema operativo

5. LangChian









