Tabla de contenido
2.2 Predicción de destino único - DecisionTreeRegressor
2.3 Predicción multiobjetivo MultiOutputRegressor
1 parámetro

n_estimators : Número de árboles de decisión en el bosque. El valor predeterminado de 100
significa que este es el número de árboles en el bosque, es decir, el número de evaluadores base. El impacto de este parámetro en la precisión del modelo de bosque aleatorio es monótono Cuanto mayor sea el n_estimadores, mejor será el efecto del modelo. Pero correspondientemente, cualquier modelo tiene un límite de decisión. Después de que los n_estimadores alcanzan un cierto nivel, la precisión del bosque aleatorio a menudo no aumenta o comienza a fluctuar. Además, cuanto más grandes son los n_estimadores, mayor es la cantidad de cálculo y memoria requerida, y el tiempo de entrenamiento también es más corto, se hará más y más largo. Para este parámetro, estamos ansiosos por lograr un equilibrio entre la dificultad del entrenamiento y el rendimiento del modelo.criterio: El criterio utilizado para dividir el nodo, opcional "gini", "entropía", predeterminado "gini".
max_ depth : La profundidad máxima del árbol. Si es Ninguno, los nodos se expanden hasta que todas las hojas sean puras (solo una clase) o hasta que todas las hojas contengan menos de min_samples_split muestras. El valor predeterminado es Ninguno.
min_samples_split : la cantidad mínima de muestras necesarias para dividir un nodo interno: si es int, min_samples_split se considera el valor mínimo. Si es flotante, min_samples_split es una fracción y ceil(min_samples_split * n_samples) es el número mínimo de muestras por división. El valor predeterminado es 2.
min_samples_leaf : el número mínimo de muestras requeridas en un nodo hoja. Solo se considera si un punto de división de cualquier profundidad deja al menos min_samples_leaf muestras de entrenamiento en cada una de las ramas izquierda y derecha. Esto puede tener el efecto de suavizar el modelo, especialmente en regresión. Si es int, considere min_samples_leaf como el valor mínimo. Si float, min_samples_leaf es la fracción y ceil(min_samples_leaf * n_samples) es el número mínimo de muestras por nodo. El valor predeterminado es 1.
min_weight_fraction_leaf : la fracción ponderada mínima en la suma de pesos en todos los nodos hoja (todas las muestras de entrada). Si no se proporciona sample_weight, las muestras se ponderan por igual.
max_features : número de características a considerar al encontrar la mejor división: si es int, las características max_features se consideran en cada división. Si es flotante, max_features es una fracción y las características int(max_features * n_features) se consideran en cada división. Si es "automático", entonces max_features = sqrt(n_features). Si es "sqrt", entonces max_features = sqrt(n_features). Si es "log2", entonces max_features = log2(n_features). Si ninguno, entonces max_features = n_features. Nota: La búsqueda de divisiones no se detiene hasta que se encuentra al menos una partición válida de muestras de nodos, incluso si requiere verificar de manera eficiente varias características de max_features.
max_leaf_nodes : número máximo de nodos hoja, entero, el valor predeterminado es Ninguno
min_impurity_decrease : dividir si la disminución en la métrica dividida es mayor que este valor.
min_impurity_split : Impureza mínima para el crecimiento del árbol de decisión. El valor predeterminado es 0. En desuso desde la versión 0.19: min_impurity_split está en desuso a favor de min_impurity_decrease de 0.19. El valor predeterminado de min_impurity_split se cambió de 1e-7 a 0 en 0.23 y se eliminará en 0.25.
bootstrap : si se debe realizar la operación de arranque, bool. El defecto es cierto. Si bootstrap==True, las muestras se seleccionarán aleatoriamente cada vez con reemplazo, solo en árboles adicionales, bootstrap=False
oob_score : Si se deben usar muestras listas para usar para estimar la precisión de la generalización. El valor predeterminado es falso.
n_jobs : número de cálculos paralelos. El valor predeterminado es Ninguno.
random_state : controla la aleatoriedad de bootstrap y la aleatoriedad de las muestras seleccionadas.
verbose : controla la verbosidad al ajustar y predecir. El valor predeterminado es 0.class_weight : el peso de cada clase, que se puede pasar en {class_label: peso} en forma de diccionario. Si se selecciona "equilibrado", los pesos de la entrada son n_samples / (n_classes * np.bincount(y)).
ccp_alpha : Se seleccionará el subárbol con mayor complejidad de costos y menor que ccp_alpha. De forma predeterminada, no se realiza ninguna poda.
max_samples: si bootstrap es True, la cantidad de muestras que se extraerán de X para entrenar cada clasificador base. Si Ninguno (predeterminado), se extraen muestras de X.shape[0]. Si es int, dibuja muestras max_samples. Si flota, dibuja max_samples * X.shape[0] samples. Por lo tanto, max_samples debe estar en (0, 1). es nuevo en la versión 0.22.
2 Implementación del cálculo
2.1 Ejemplo de cálculo
Los materiales no tejidos fundidos por soplado son materias primas importantes para la producción de máscaras. Tienen un buen rendimiento de filtración, un proceso de producción simple, bajo costo y peso ligero. Han atraído la atención de empresas nacionales y extranjeras. Sin embargo, dado que las fibras de las telas no tejidas fundidas por soplado son muy delgadas, no se puede garantizar su rendimiento debido a la escasa resiliencia a la compresión durante el uso. Por lo tanto, los científicos han creado el método de soplado en fusión de intercalación, es decir, mediante la inserción de fibras cortadas de poliéster (PET) en la corriente de fibra soplada en fusión durante el proceso de preparación del soplado en fusión de polipropileno (PP), un "Z- "formada" de una capa intercalada de material no tejido fundido por soplado. Hay muchos parámetros de proceso para la preparación de materiales no tejidos fundidos por soplado intercalados, y hay efectos interactivos entre los parámetros, y es más complicado después de agregar el flujo de aire de intercalación.Por lo tanto, las variables estructurales (espesor, porosidad, resistencia a la compresión) , y el estudio de las variables estructurales que determinan las propiedades del producto final (resistencia a la filtración, eficiencia de filtración, permeabilidad al aire) también se ha vuelto más complicado. Si se pueden establecer los modelos de relación entre los parámetros del proceso y las variables estructurales, y entre las variables estructurales y el rendimiento del producto, ayudará a proporcionar una cierta base teórica para el establecimiento del mecanismo de regulación del rendimiento del producto. Consulte la literatura relevante, comprenda los antecedentes profesionales, investigue los datos del tema
y responda las siguientes preguntas:
Pregunta: Investigue la relación entre los parámetros del proceso y las variables estructurales. La Tabla 1 proporciona 8 combinaciones de parámetros de proceso, complete los datos de la variable estructural pronosticada en la Tabla 1 y dibuje la imagen en forma tabular.

2.2 Predicción de destino único - DecisionTreeRegressor
Aquí tomamos la predicción de un solo objetivo como ejemplo, usamos un árbol de decisiones para hacer predicciones y solo predecimos la tasa de rebote de la compresión :
import pandas as pd
from sklearn.tree import DecisionTreeRegressor#决策树
#第一步正常读取数据:
data=pd.read_excel('C题数据.xlsx',sheet_name=2)
chuli=data.iloc[:,:5]
chuli.columns=['接收距离','热风速度','厚度','孔隙率','压缩回弹性率']
#chuli
#第二步:提取变量
X=chuli.drop(['压缩回弹性率','孔隙率','厚度'],axis=1)
y=chuli['压缩回弹性率']
#X
#第三步:分割数据
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test= train_test_split(X, y, test_size= 0.2, random_state=0)
#第四步:建立决策树模型、训练模型
model= DecisionTreeRegressor(max_depth=2) # 设树深度为2
dtr_fit = model.fit(x_train, y_train)
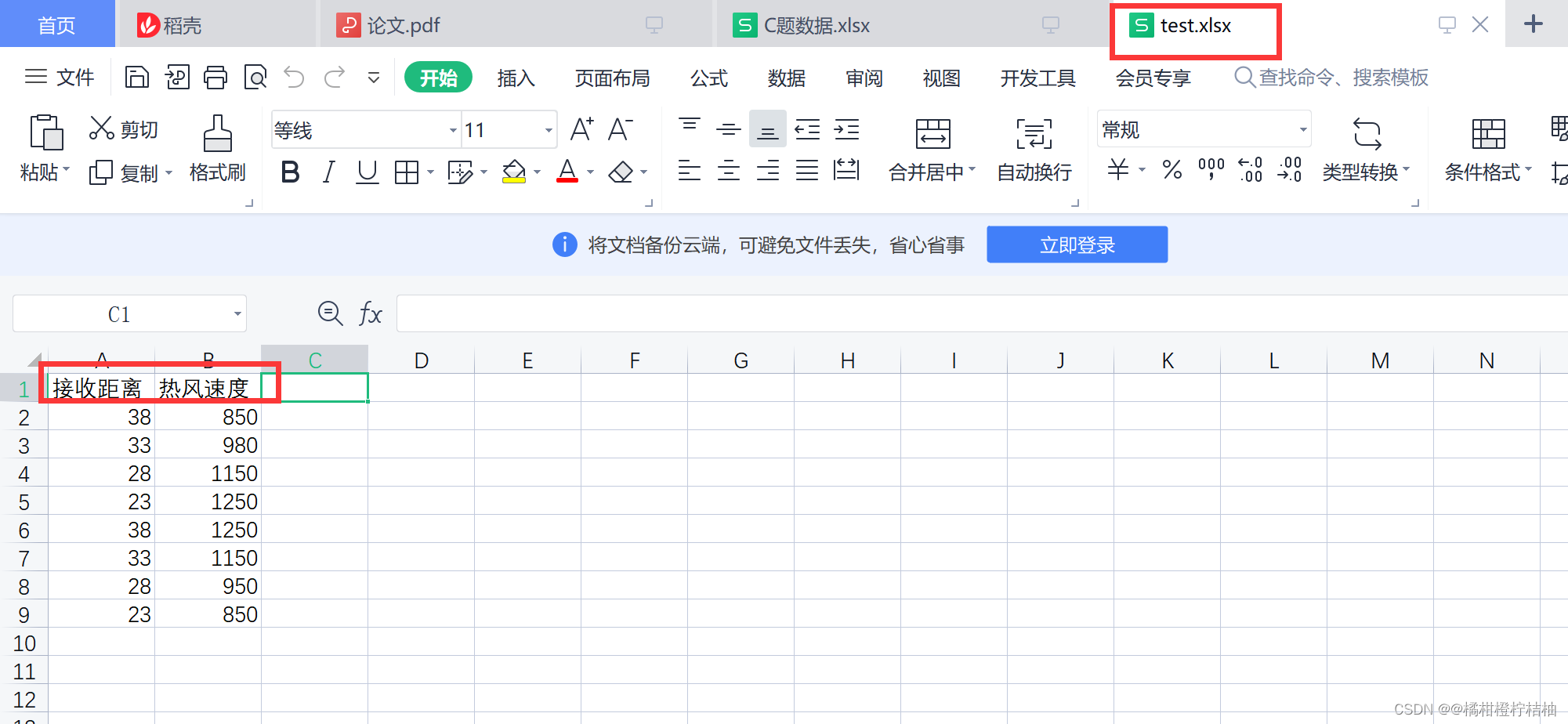
#第五步:读取我们需要预测的数据,整理好了自己下载:test.xlsx
test1=pd.read_excel('test.xlsx')
#test1
#第六步:使用训练好的模型预测数据
ya=dtr_fit.predict(test1)
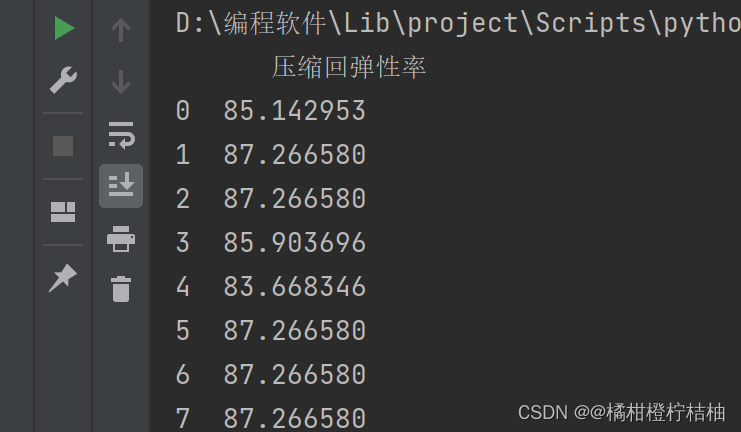
print(pd.DataFrame(ya,columns=['压缩回弹性率']))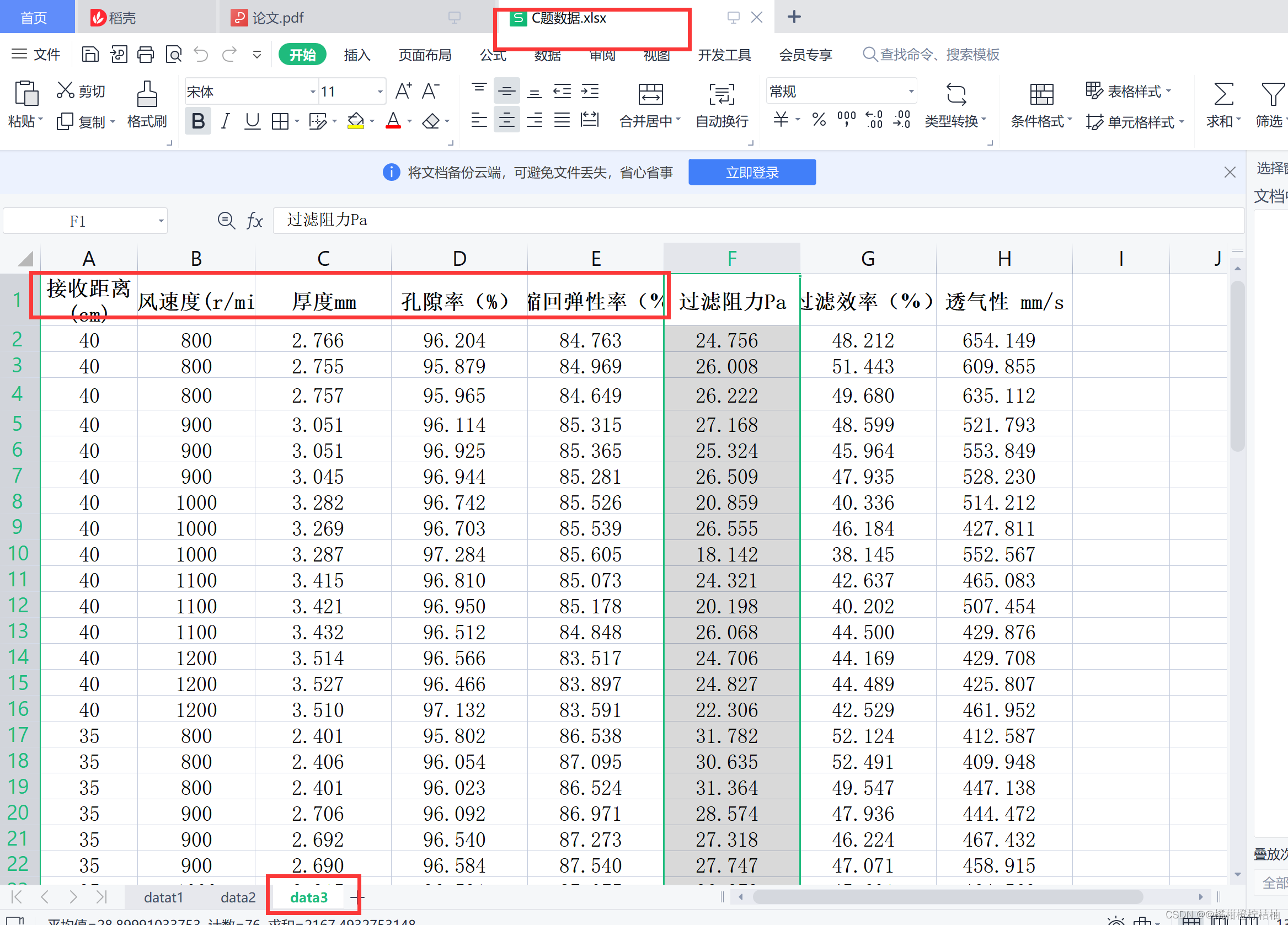
 resultado:
resultado:
2.3 Predicción multiobjetivo MultiOutputRegressor
import pandas as pd
from sklearn.tree import DecisionTreeRegressor#决策树
#第一步正常读取数据:
data=pd.read_excel('C题数据.xlsx',sheet_name=2)
chuli=data.iloc[:,:5]
chuli.columns=['接收距离','热风速度','厚度','孔隙率','压缩回弹性率']
#chuli
#第二步:提取变量
X=chuli.drop(['压缩回弹性率','孔隙率','厚度'],axis=1)
y=chuli['压缩回弹性率']
#X
#第三步:分割数据
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test= train_test_split(X, y, test_size= 0.2, random_state=0)
#第四步:建立决策树模型、训练模型
model= DecisionTreeRegressor(max_depth=2) # 设树深度为2
dtr_fit = model.fit(x_train, y_train)
#第五步:读取我们需要预测的数据,整理好了自己下载:test.xlsx
test1=pd.read_excel('test.xlsx')
#test1
#第六步:使用训练好的模型预测数据
ya=dtr_fit.predict(test1)
print(pd.DataFrame(ya,columns=['压缩回弹性率']))
#display(pd.DataFrame(ya,columns=['压缩回弹性率']))
#第七步:重新读取变量值
X2=chuli.drop(['压缩回弹性率','孔隙率','厚度'],axis=1)
y2=chuli[['压缩回弹性率','孔隙率','厚度']]
#y2
#第八步:对提取到的数据做分割
from sklearn.model_selection import train_test_split
x_train2, x_test2, y_train2, y_test2= train_test_split(X2, y2, test_size= 0.2, random_state=0)
#第九步:采用对输入多输出模型,结合XGBoost算法模型进行训练(如果你觉得效果不够好,自行修改XGBoost参数)
from sklearn.multioutput import MultiOutputRegressor
from xgboost import XGBRegressor
mor = MultiOutputRegressor(XGBRegressor(objective='reg:linear'))
mor.fit(x_train2, y_train2)
#mor
#第十步:预测
pre=mor.predict(test1)
print(pd.DataFrame(pre,columns=['压缩回弹性率','孔隙率','厚度']))
resultado:
