Directorio de artículos
Ideas de preguntas
(Compartir en CSDN tan pronto como salgan las preguntas de la competencia)
https://blog.csdn.net/dc_sinor?type=blog
1. Introducción: sobre la detección de anomalías
Detección de anomalías (detección de valores atípicos) en los siguientes escenarios:
- Preprocesamiento de datos
- Detección de virus troyanos
- Pruebas de productos de fabricación industrial
- Inspección de tráfico de red
Espera, hay un papel importante. Dado que en los escenarios anteriores, la cantidad de datos anormales es una pequeña parte, los algoritmos de clasificación como SVM y la regresión logística no son aplicables porque:
El algoritmo de aprendizaje supervisado es adecuado para una gran cantidad de muestras positivas y una gran cantidad de muestras negativas, hay suficientes muestras para que el algoritmo aprenda sus características y las nuevas muestras en el futuro son consistentes con la distribución de muestras de entrenamiento.
El siguiente es el ámbito de aplicación de los algoritmos relacionados con la detección de anomalías y el aprendizaje supervisado:
detección anormal
- Fraude de tarjeta de credito
- Detección anormal de productos de fabricación.
- Detección de anomalías en la máquina del centro de datos
- detección de intrusos
aprendizaje supervisado
- Identificación de correo no deseado
- categorías de noticias
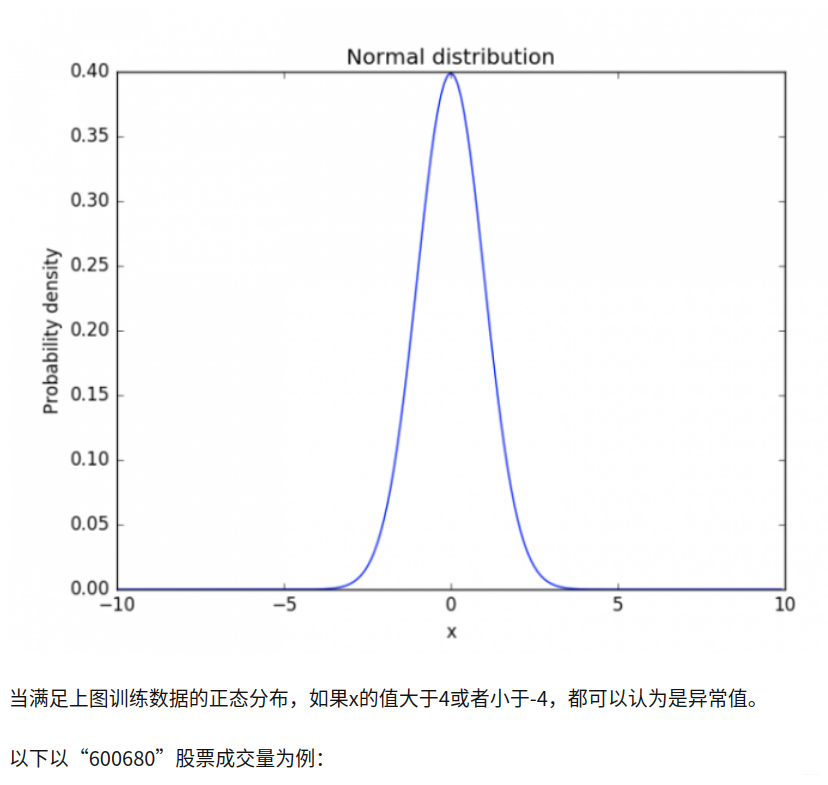
2. Algoritmo de detección de anomalías

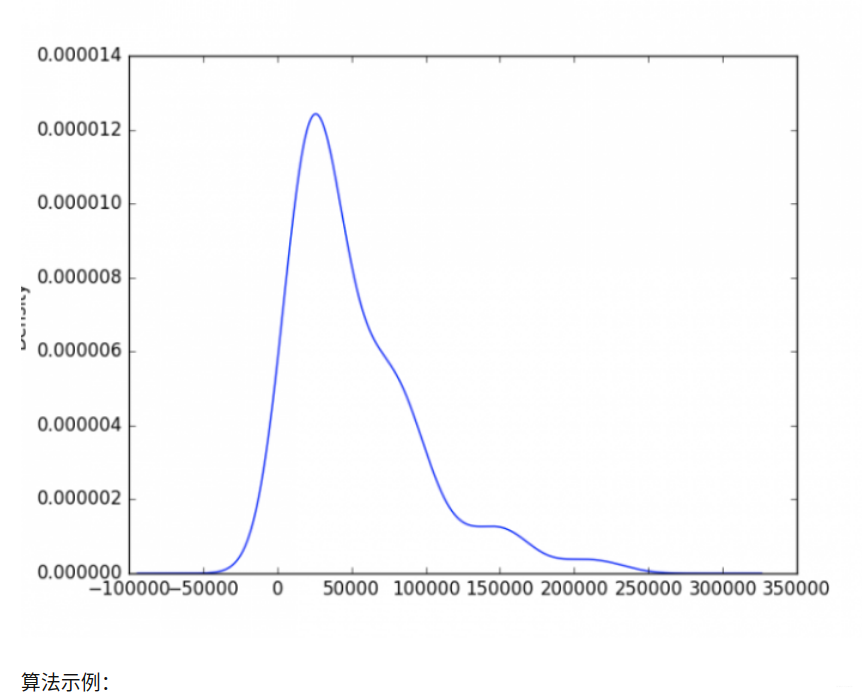
import tushare
from matplotlib import pyplot as plt
df = tushare.get_hist_data("600680")
v = df[-90: ].volume
v.plot("kde")
plt.show()
En los últimos tres meses, si el volumen de transacciones es superior a 200.000, puede considerarse anormal

2. Análisis de diagrama de caja
import tushare
from matplotlib import pyplot as plt
df = tushare.get_hist_data("600680")
v = df[-90: ].volume
v.plot("kde")
plt.show()
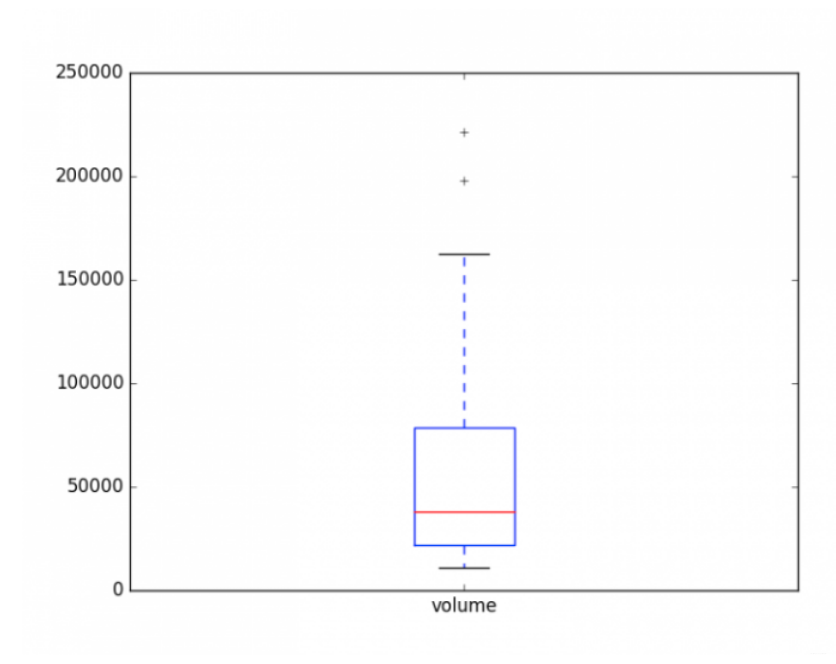
En general, se puede saber que si el volumen de negociación de las acciones es inferior a 20,000, o el volumen de negociación es superior a 80,000, ¡debe estar más atento!
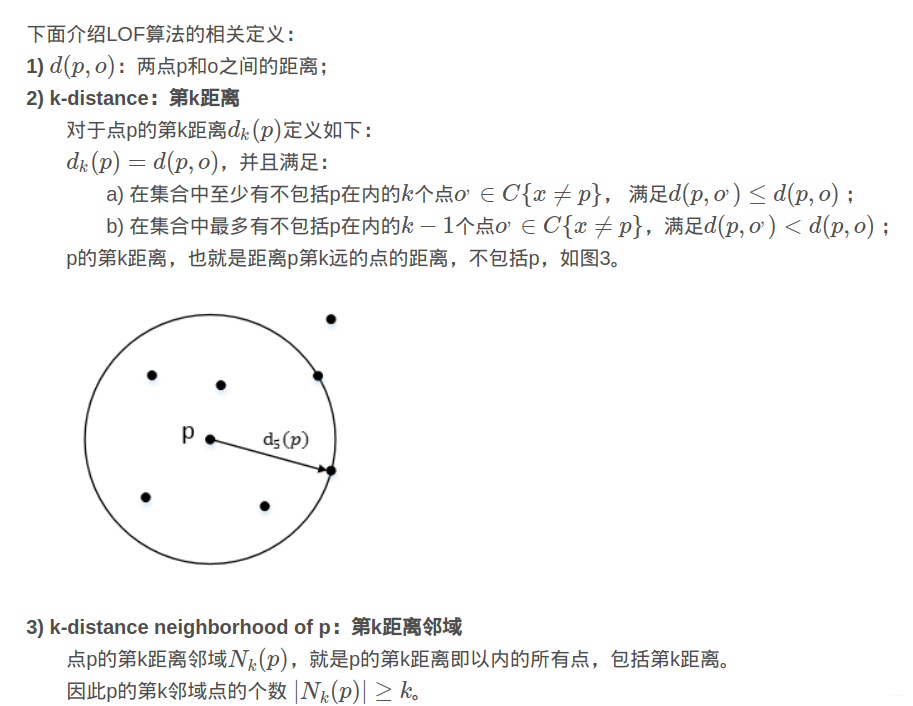
3. Basado en distancia/densidad
Un algoritmo típico es: "Algoritmo de factor de valor atípico local-Factor de valor atípico local", que introduce "k-distancia, k-ésima distancia", "k-distancia vecindad, k-ésima distancia vecindad", "distancia de alcance, distancia alcanzable" y "densidad de accesibilidad local, densidad de alcance local" y "factor de valor atípico local, factor de valor atípico local" para encontrar valores atípicos.
Siéntalo visualmente, como se muestra en la Figura 2, para los puntos del conjunto C1, el espaciado, la densidad y la dispersión generales son relativamente uniformes y pueden considerarse como el mismo grupo; para los puntos del conjunto C2, también pueden ser considerado como un conglomerado. Los puntos o1 y o2 están relativamente aislados y pueden considerarse puntos anormales o puntos discretos. La pregunta ahora es cómo darse cuenta de la generalidad del algoritmo, que puede satisfacer la identificación de valores atípicos de C1 y C2, que tienen distribuciones de densidad muy diferentes. LOF puede lograr nuestro objetivo.

4. Basado en la idea de división
Un algoritmo típico es "Bosque de Aislamiento, Bosque de Aislamiento", la idea es:
Supongamos que usamos un hiperplano aleatorio para dividir (split) el espacio de datos (espacio de datos), un corte puede generar dos subespacios (imagínese cortar un pastel en dos con un cuchillo). Después de eso, continuamos usando un hiperplano aleatorio para cortar cada subespacio y el ciclo continúa hasta que solo hay un punto de datos en cada subespacio. Intuitivamente hablando, podemos encontrar que esos cúmulos con alta densidad pueden cortarse muchas veces antes de que dejen de cortarse, pero esos puntos con baja densidad pueden detenerse fácilmente en un subespacio muy temprano.
El flujo del algoritmo de esto es el proceso de usar el hiperplano para dividir el subespacio y luego construir un árbol binario similar:

import numpy as np
import matplotlib.pyplot as plt
from sklearn.ensemble import IsolationForest
rng = np.random.RandomState(42)
# Generate train data
X = 0.3 * rng.randn(100, 2)
X_train = np.r_[X + 1, X - 3, X - 5, X + 6]
# Generate some regular novel observations
X = 0.3 * rng.randn(20, 2)
X_test = np.r_[X + 1, X - 3, X - 5, X + 6]
# Generate some abnormal novel observations
X_outliers = rng.uniform(low=-8, high=8, size=(20, 2))
# fit the model
clf = IsolationForest(max_samples=100*2, random_state=rng)
clf.fit(X_train)
y_pred_train = clf.predict(X_train)
y_pred_test = clf.predict(X_test)
y_pred_outliers = clf.predict(X_outliers)
# plot the line, the samples, and the nearest vectors to the plane
xx, yy = np.meshgrid(np.linspace(-8, 8, 50), np.linspace(-8, 8, 50))
Z = clf.decision_function(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.title("IsolationForest")
plt.contourf(xx, yy, Z, cmap=plt.cm.Blues_r)
b1 = plt.scatter(X_train[:, 0], X_train[:, 1], c='white')
b2 = plt.scatter(X_test[:, 0], X_test[:, 1], c='green')
c = plt.scatter(X_outliers[:, 0], X_outliers[:, 1], c='red')
plt.axis('tight')
plt.xlim((-8, 8))
plt.ylim((-8, 8))
plt.legend([b1, b2, c],
["training observations",
"new regular observations", "new abnormal observations"],
loc="upper left")
plt.show()
