Tabla de contenido
2. Interpretación de las preguntas del concurso
3. Método de resolución de problemas
Código de parte de la segunda pregunta
I. Resumen
Esta competencia es la primera vez que nuestro equipo participa en modelos matemáticos financieros. Aunque hemos realizado ejercicios relacionados con las preguntas de la Copa A del Área de la Gran Bahía 2020 antes de la competencia, todavía tenemos algunos problemas con las preguntas de modelos matemáticos financieros extenuantes. Pero afortunadamente, después de 7 días de arduo trabajo, todavía completamos las cuatro preguntas. Los resultados oficiales de la competencia se publicaron el mes pasado. Nuestro equipo ganó el tercer premio. Para mí personalmente, ya es un muy buen resultado (porque no No tengo ninguna esperanza de ganar el premio al principio hhhhh).
Así que echemos un vistazo a estas cuatro preguntas :)
2. Preguntas e Interpretación
1. Detalles de la competición
La dificultad de la pregunta B en esta competencia no es alta, y el título de la competencia general es "Construcción de estrategias de asignación de activos basadas en el ciclo macroeconómico".
Hay cuatro preguntas en total, como se muestra en la siguiente figura:

Además, el autor de la pregunta también proporciona los conjuntos de datos relevantes necesarios para resolver el problema. Los archivos de conjuntos de datos son aproximadamente los siguientes:
(Anexo 1: Datos de Indicadores Macroeconómicos (Preguntas 1 y 2))

(Apéndice 2: Datos de mercado de los principales índices de activos (Preguntas 3 y 4))

2. Interpretación de las preguntas del concurso
Por ejemplo, las cuatro preguntas se pueden dividir en tres partes:
La primera parte es el análisis y clasificación de los datos macroeconómicos y el pronóstico de las condiciones económicas futuras (preguntas 1 y 2).
La segunda parte es realizar un análisis de correlación basado en los datos de los principales índices de activos en los que se puede invertir (la tercera pregunta).
La tercera parte es la aplicación combinada de la primera y la segunda parte. La conclusión de la situación macroeconómica de China en los próximos 5 años dibujada en la primera parte y los resultados del análisis de la correlación de datos del índice de activos a gran escala en la segunda. parte son utilizados por el marco del reloj de Merrill Lynch Determinar cómo combinar grandes categorías de activos para la inversión.
Cabe señalar que los datos proporcionados por el autor de la pregunta no necesitan usarse en su totalidad, pero deben filtrarse y reutilizarse de acuerdo con el método de modelado matemático utilizado por el individuo.
3. Método de resolución de problemas
1. Primera pregunta
Análisis del tema: para la primera pregunta, primero determine el rango de tiempo de 2001 a 2021 y seleccione el PIB en la contabilidad económica nacional y la oferta monetaria en el banco y la moneda de los datos del indicador macroeconómico El índice M2 se utiliza como indicador para dividir el estado económico, y se calculan la tasa de crecimiento del PIB y la tasa de inflación.Los cuatro estados económicos divididos por el marco del reloj de Merrill Lynch se pueden medir utilizando los dos indicadores anteriores.

(Figura: teoría del marco del reloj de Merrill Lynch)
Datos aplicados y fórmula del algoritmo: Calcular la tasa de crecimiento del PIB y la oferta monetaria M2 en función de datos preparados como el PIB, M2 (oferta monetaria amplia) y la tasa de inflación real (año) en el Anexo 1 Índice de tasa de crecimiento. Debido a las limitaciones del tema, solo los datos relacionados con el desempeño macroeconómico en los 20 años de 2001 a 2021 se seleccionan como indicadores de división.


Si la tasa de crecimiento del PIB es superior al 10 %, se considera un crecimiento alto, de lo contrario, se considera un crecimiento bajo; si la tasa de inflación es superior al 6 %, se considera una inflación alta, de lo contrario, se considera una inflación baja .
Entonces, después del cálculo, podemos obtener la tasa de crecimiento del PIB y la tasa de inflación. A través de estos dos indicadores, escribimos un programa en Python para clasificar los últimos 20 años de acuerdo con el marco del reloj de Merrill Lynch. El resultado se muestra en la siguiente figura:
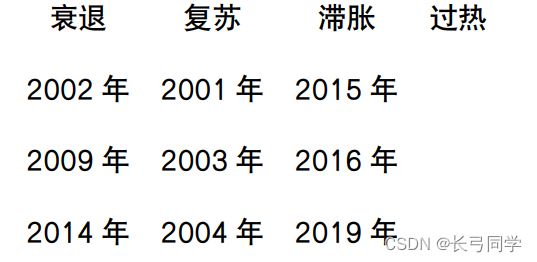
De acuerdo al resumen de los resultados de clasificación de todos los años, los años en etapa de recesión de 2001 a 2021 son: 2002, 2009, 2014, 2017; los años en etapa de recuperación son: 2001, 2003, 2004, 2005, 2006, 2007, 2008, 2010, 2011, 2012, 2013, 2018, 2021; Años en estanflación: 2015, 2016, 2019, 2020; No hubo años en fase de sobrecalentamiento.
Código de la primera pregunta:
def classify(GDP,CPI):
data1 = pd.DataFrame(GDP)
data2 = pd.DataFrame(CPI)
#print(data1.iloc[0,0])
GDP_speed_up = []
M_tongbi = []
tongzhanglv = []
drop = []
recover = []
overheat = []
stagflation =[]
for i in range(21):
then_year = data1.iloc[i+1,1]
ago_year = data1.iloc[i,1]
zhengzhang = ((then_year - ago_year)/ago_year)*100
GDP_speed_up.append(zhengzhang)
for j in range(11,253,12):
M_tb = data2.iloc[j,6]
M_tongbi.append(M_tb)
for k in GDP_speed_up:
for z in M_tongbi:
tongzhang = z - k
tongzhanglv.append(tongzhang)
break
print(GDP_speed_up)
print(tongzhanglv)
year = [2001,2002,2003,2004,2005,2006,2007,2008,2009,2010,2011,2012,2013,2014,2015,2016,2017,2018,2019,2020,2021]
for a in range(0,len(GDP_speed_up)):
if (GDP_speed_up[a]<15 and tongzhanglv[a]<6):
drop.append(year[a])
elif (GDP_speed_up[a]>15 and tongzhanglv[a]<6):
recover.append(year[a])
elif (GDP_speed_up[a]>15 and tongzhanglv[a]>6):
overheat.append(year[a])
else :
stagflation.append(year[a])
return drop,recover,overheat,stagflation
def divide(drop_1,recover_1,overhead_1,staflation_1):
index = pd.date_range('2001','2021')
print(index)
2. La segunda pregunta
Análisis del tema: De acuerdo con la tasa de crecimiento del PIB calculada en la primera pregunta, el índice de precios al consumidor IPC se usa para calcular la tasa de inflación de los productos básicos en moneda, y la tasa de interés de depósito actual (mensual) se usa para calcular la tasa de interés para simular y predecir el desarrollo macroeconómico de China en los próximos cinco años El algoritmo LSTM predice el crecimiento económico, la inflación y las tasas de interés en los próximos cinco años utilizando una ventana móvil de serie de tiempo con un año como intervalo de tiempo.
Dado que la segunda pregunta requiere que predigamos datos futuros, necesitamos usar el algoritmo LSTM para modelar.Al igual que los métodos de aprendizaje automático como CNN, necesitamos realizar tres pasos de preprocesamiento de datos, entrenamiento de modelos y predicción de datos para construir nuestro algoritmo matemático. modelo y escribir código.
Preprocesamiento de datos: Dado que estos datos son datos de series de tiempo, es necesario unificar sus sellos de tiempo, mediante la observación se encuentra que todos los datos han tendido a ser estables desde 1988 (sin valores faltantes), por lo que los datos de 1988 a 2021 son seleccionado. . Además, dado que los datos del PIB y la tasa de inflación son de diciembre de cada año, dividimos los datos de oferta monetaria M2 y la tasa de interés de los depósitos a la vista en RMB, y extraemos los datos de diciembre de cada año, para lograr uniformidad en el tiempo. . Guarde el marco de datos como una matriz bidimensional y luego realice esta conversión de diferencias, convierta los datos de la serie temporal en un conjunto de aprendizaje supervisado y divida el conjunto de datos en un conjunto de entrenamiento y un conjunto de prueba, y use MinMaxScaler para escalar los datos a [-1,1] acelerar la convergencia.
Entrenamiento de modelo (selección de método): Es necesario usar un algoritmo de memoria para el entrenamiento de modelo. RNN (Recurrent Neural Network, RNN) puede realizar entrenamiento de modelo para datos ordenados, pero usarlo para entrenamiento de modelo causará el problema de la desaparición del gradiente. Por lo tanto , solo se puede realizar la memoria a corto plazo. Para resolver este problema, utilizamos LSTM (Long Short Term, LSTM), un algoritmo derivado de RNN. Este algoritmo puede aprender información dependiente a largo plazo, que es muy adecuada para resolver nuestro problema objetivo.
Pronóstico: en términos de pronóstico, adoptamos el pronóstico de ventana deslizante.
Resultado de la operación:
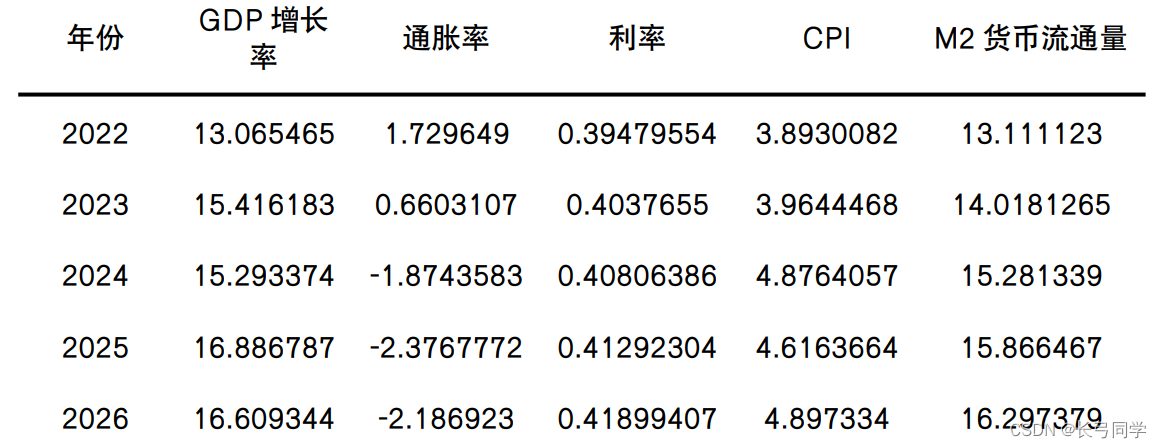
Con base en los resultados calculados combinados con el reloj de Merrill Lynch, se puede ver que el crecimiento económico de China en los próximos cinco años será alto, mientras que la inflación y las tasas de interés estarán en una situación de inflación baja y baja. , se estima que China estará en etapa de recuperación en los próximos cinco años .
Código de parte de la segunda pregunta:
#设置随机种子
numpy.random.seed(7)
df = pd.read_excel('./data/GDP_TZ.xlsx')
df.drop(['tongzhanglv'],axis=1,inplace=True)
df['Date']=pd.to_datetime(df['Date'],format='%Y')
# print(data.head())
df = df.set_index(['Date'], drop=True)
dataframe = pd.DataFrame(df)
# print(dataframe)
dataset = dataframe.values
dataset = dataset.astype("float64")
# print(dataframe.head())
#
#异常值检测
fig = plt.figure(1,figsize=(9,6))
ax = fig.add_subplot(111)
bp = ax.boxplot(dataset)
# print(bp['fliers'][0].get_ydata())
# plt.show()
#需要将数据标准化到0-1
scaler = MinMaxScaler(feature_range=(0,1))
dataset = scaler.fit_transform(dataset)
#分割训练集与测试集
train_size = int(len(dataset)*0.75)
test_size = len(dataset)-train_size
# print(test_size)
train,test = dataset[0:train_size,:],dataset[train_size:len(dataset),:]
trainX,trainY = create_dataset(train,look_back)
testX,testY = create_dataset(test,look_back)
print(trainX)
print(trainY)
#创建一个LSTM模型
model = Sequential()
model.add(LSTM(4,input_shape=(1,look_back)))
model.add(Dense(1))
model.compile(loss='mean_squared_error',optimizer='adam')
trainX= trainX.reshape(trainX.shape[0],1,trainX.shape[1])
# trainY= trainY.reshape(trainY.shape[0],1,trainY.shape[0])
model.fit(trainX,trainY,epochs=100,batch_size=3,verbose=2)3. La tercera pregunta:
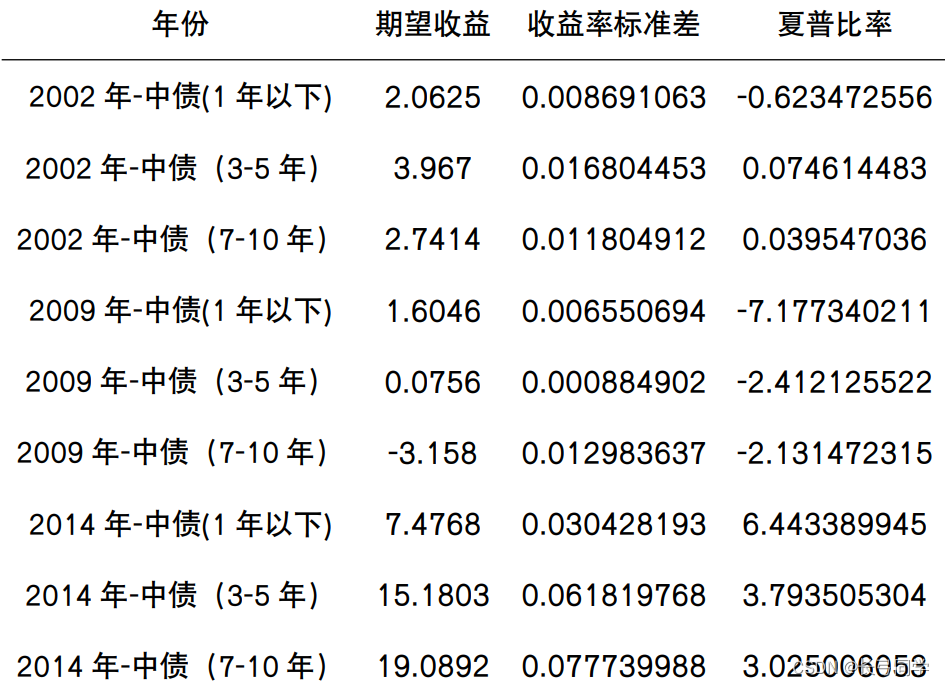
Análisis del problema: es necesario utilizar las cuatro condiciones de división del estado económico divididas de acuerdo con el marco del reloj de Merrill Lynch en la primera pregunta para calcular las características de riesgo-rendimiento (rentabilidad esperada, desviación estándar de la rentabilidad) de los principales índices de activos en el Anexo 2 bajo varios estados económicos, relación de Sharpe). Utilice el coeficiente de Pearson para calcular el coeficiente de correlación entre los principales índices de activos y utilice el mapa de calor para representar la importancia entre los principales índices de activos.
Coeficiente de Pearson:
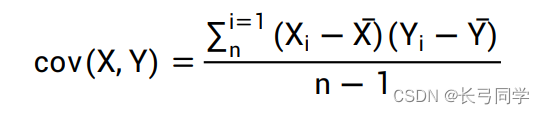
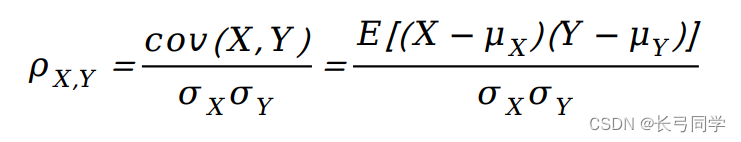
Calcule los resultados y trace un mapa de calor:
(p. ej., características de rentabilidad-riesgo en una economía en recesión)
(mapa de calor)

Se calcula que el coeficiente de correlación entre ChinaBond-Comprehensive Wealth (3-5 años) y ChinaBond-Comprehensive Wealth (7-10 años) es el más alto. De los resultados del cálculo, podemos ver que el coeficiente de correlación de los principales índices de activos entre las mismas categorías Mayor que el coeficiente de correlación del índice entre diferentes categorías.
Código para la tercera pregunta:
def divide():
data1 = pd.read_excel(path3)
data_dalei = pd.DataFrame(data1)
data_dalei.set_index('time',inplace=True)
stats = ['stock1','stock2','stock3','stock4','goods1','goods2','bond1','bond2','bond3','cash1']
data_dalei.reindex(columns=stats)
return data_dalei
def drop(drop_1):
xiapu = []
expect_profit = []
biaozhun = []
data_dalei = divide()
for x1 in drop_1:
data_x_1 = []
for i in range(6,9):
data_dalei_drop_2 = data_dalei[str(x1)].iloc[:,i]
#计算期望收益
data_expect_profit = data_dalei_drop_2[-1]-data_dalei_drop_2[0]
#计算夏普比率:
for i1 in range(1,len(data_dalei_drop_2)):
data = ((data_dalei_drop_2[i1]-data_dalei_drop_2[i1-1])/data_dalei_drop_2[i1-1])*100
data_x_1.append(data)
data_x1 = pd.Series(data_x_1)
sharp = cal_sharp(data_x1,rf = 3)
#计算收益率标准差
#平均收益:avg
qiuhe = 0
x0 = 0
for k in range(1,len(data_dalei_drop_2)):
data2 = (data_dalei_drop_2[k]-data_dalei_drop_2[k-1])
qiuhe = qiuhe + data2
avg = qiuhe/(len(data_dalei_drop_2)-1)
#当天收益:then
for k1 in range(1,len(data_dalei_drop_2)):
data3 = (data_dalei_drop_2[k1]-data_dalei_drop_2[k1-1])
x = (data3-avg)**2
x0 = x0 + x
biaozhunci = math.sqrt(x0/(len(data_dalei_drop_2)-1))
xiapu.append(sharp)
expect_profit.append(data_expect_profit)
biaozhun.append(biaozhunci)
M1 = pd.Series(expect_profit)
M2 = pd.Series(xiapu)
M3 = pd.Series(biaozhun)
M4 = pd.concat([M1,M2,M3],axis=1)
M4.to_excel('./data/dropnew.xlsx')
def recover(recover_1):
xiapu2 = []
expect_profit2 = []
biaozhun2 = []
data_dalei = divide()
for x2 in recover_1:
data_x_2 = []
data_x_3 = []
data_x= []
if int(x2) == 2001:
#计算夏普比率:
data_dalei_recover = data_dalei[str(x2)].iloc[:,5]
for i in range(1,len(data_dalei_recover)):
data = ((data_dalei_recover[i]-data_dalei_recover[i-1])/data_dalei_recover[i-1])*100
data_x.append(data)
data_x1 = pd.Series(data_x)
sharp = cal_sharp(data_x1,rf = 3)
#计算期望收益:
data_expect_profit = data_dalei_recover[-1]-data_dalei_recover[0]
#计算收益率标准差
qiuhe3 = 0
x_3 = 0
for aa in range(1,len(data_dalei_recover)):
data8 = (data_dalei_recover[aa]-data_dalei_recover[aa-1])
qiuhe3 = qiuhe3 + data8
avg3 = qiuhe3/(len(data_dalei_recover)-1)
for aa1 in range(1,len(data_dalei_recover)):
data9 = (data_dalei_recover[aa1]-data_dalei_recover[aa-1])
x_33 = pow(data9-avg3,2)
x_3 = x_3 +x_33
zhuanx = x_3/(len(data_dalei_recover))
biaozhuancha3 = math.sqrt(zhuanx)
xiapu2.append(sharp)
expect_profit2.append(data_expect_profit)
biaozhun2.append(biaozhuancha3)
elif int(x2) == 2004:
for kk in range(0,2):
#计算夏普比率:
data_dalei_recover = data_dalei[str(x2)].iloc[:,kk]
for kk1 in range(1,len(data_dalei_recover)):
data = ((data_dalei_recover[kk1]-data_dalei_recover[kk1-1])/data_dalei_recover[kk1-1])*100
data_x_2.append(data)
data_x2 = pd.Series(data_x_2)
sharp1 = cal_sharp(data_x2,rf = 3)
#计算期望收益:
data_expect_profit1 = data_dalei_recover[-1]-data_dalei_recover[0]
#计算收益率标准差
qiuhe2 = 0
x_2 = 0
for kk3 in range(1,len(data_dalei_recover)):
datam = (data_dalei_recover[kk3]-data_dalei_recover[kk3-1])
qiuhe2 = qiuhe2 +datam
avg2 = qiuhe2/(len(data_dalei_recover)-1)
for kk4 in range(1,len(data_dalei_recover)):
datan = (data_dalei_recover[kk4]-data_dalei_recover[kk4-1])
x_22 = pow(datan - avg2,2)
x_2 = x_2 + x_22
biaozhunca = math.sqrt(x_2/len(data_dalei_recover))
xiapu2.append(sharp1)
biaozhun2.append(biaozhunca)
expect_profit2.append(data_expect_profit1)
elif int(x2) == 2003:
#计算夏普比率:
data_dalei_recover = data_dalei[str(x2)].iloc[:,1]
for kk1 in range(1,len(data_dalei_recover)):
data = ((data_dalei_recover[kk1]-data_dalei_recover[kk1-1])/data_dalei_recover[kk1-1])*100
data_x_2.append(data)
data_x2 = pd.Series(data_x_2)
sharp1 = cal_sharp(data_x2,rf = 3)
#计算期望收益:
data_expect_profit1 = data_dalei_recover[-1]-data_dalei_recover[0]
#计算收益率标准差
qiuhe2 = 0
x_2 = 0
for kk3 in range(1,len(data_dalei_recover)):
datam = (data_dalei_recover[kk3]-data_dalei_recover[kk3-1])
qiuhe2 = qiuhe2 +datam
avg2 = qiuhe2/(len(data_dalei_recover)-1)
for kk4 in range(1,len(data_dalei_recover)):
datan = (data_dalei_recover[kk4]-data_dalei_recover[kk4-1])
x_22 = pow(datan - avg2,2)
x_2 = x_2 + x_22
biaozhunca = math.sqrt(x_2/len(data_dalei_recover))
xiapu2.append(sharp1)
biaozhun2.append(biaozhunca)
expect_profit2.append(data_expect_profit1)
else:
for kk2 in range(0,4):
data_dalei_recover_2 = data_dalei[str(x2)].iloc[:,kk2]
#计算期望收益
data_expect_profit2 = data_dalei_recover_2[-1]-data_dalei_recover_2[0]
print(f"期望收益{data_expect_profit2}")
#计算夏普比率:
for kk3 in range(1,len(data_dalei_recover_2)):
data = ((data_dalei_recover_2[kk3]-data_dalei_recover_2[kk3-1])/data_dalei_recover_2[kk3-1])*100
data_x_3.append(data)
data_x3 = pd.Series(data_x_3)
sharp2 = cal_sharp(data_x3,rf = 3)
print(f"夏普:{sharp2}")
#计算收益率标准差
#平均收益:avg
qiuhe1 = 0
x_1 = 0
for kk4 in range(1,len(data_dalei_recover_2)):
data4 = (data_dalei_recover_2[kk4]-data_dalei_recover_2[kk4-1])
qiuhe1 = qiuhe1 + data4
avg = qiuhe1/(len(data_dalei_recover_2)-1)
#当天收益:
for kk5 in range(1,len(data_dalei_recover_2)):
data5 = (data_dalei_recover_2[kk5] - data_dalei_recover_2[kk5-1])
x_11 = pow(data5-avg,2)
x_1 = x_1 + x_11
zhuan = x_1/len(data_dalei_recover_2)
biaozhunci2 = math.sqrt(zhuan)
print(f"标准差{biaozhunci2}\n")
qiuhe1 = 0
x_1 = 0
x_11=0
avg = 0
zhuan = 0
data5 = 0
print(f"期望收益{x2}{data_expect_profit2}")
print(f"夏普:{x2}{sharp2}")
print(f"收益率标准差{x2}{biaozhunci2}")
xiapu2.append(sharp2)
expect_profit2.append(data_expect_profit2)
biaozhun2.append(biaozhunci2)
K1 = pd.Series(expect_profit2)
K2 = pd.Series(xiapu2)
K3 = pd.Series(biaozhun2)
K4 = pd.concat([K1,K2,K3],axis=1)
K4.to_excel('./data/recovernew.xlsx')
def overhead(overhead_1):
data_dalei = divide()
for x3 in overhead_1:
data_dalei_overhear = data_dalei[str(x3)]
#没有经济过热的年份
def staflation(staflation_1):
xiapu3 = []
expect_profit3 = []
biaozhun3 = []
data_dalei = divide()
for x4 in staflation_1:
data_x_4 = []
data_dalei_stagflation = data_dalei[str(x4)].iloc[:,9]
#计算夏普比率:
for jj1 in range(1,len(data_dalei_stagflation)):
data1 = ((data_dalei_stagflation[jj1]-data_dalei_stagflation[jj1-1])/data_dalei_stagflation[jj1-1])*100
data_x_4.append(data1)
data_x4 = pd.Series(data_x_4)
sharp2 = cal_sharp(data_x4,rf = 3)
#计算收益期望:
data_expect_profit3 = data_dalei_stagflation[-1]-data_dalei_stagflation[0]
#计算收益率标准差:
qiuhe2 = 0
x_2 = 0
for jj2 in range(1,len(data_dalei_stagflation)):
data6 = (data_dalei_stagflation[jj2]-data_dalei_stagflation[jj2-1])
qiuhe2 = qiuhe2 + data6
avg2 = qiuhe2/(len(data_dalei_stagflation)-1)
for jj3 in range(1,len(data_dalei_stagflation)):
data7 = (data_dalei_stagflation[jj3]-data_dalei_stagflation[jj3-1])
x_x_1 = pow(data7-avg2,2)
x_2 = x_2 + x_x_1
zhuan1 = x_2/len(data_dalei_stagflation)
boapzhuncha3 =math.sqrt(zhuan1)
xiapu3.append(sharp2)
expect_profit3.append(data_expect_profit3)
biaozhun3.append(boapzhuncha3)
# print(f"夏普比率{sharp2}")
# print(f"收益期望{data_expect_profit3}")
# print(f"收益率标准差{boapzhuncha3}\n")
L1 = pd.Series(expect_profit3)
L2 = pd.Series(xiapu3)
L3 = pd.Series(biaozhun3)
L4 = pd.concat([L1,L2,L3],axis=1)
L4.to_excel('./data/stagflationnew.xlsx')
def cal_sharp(daily_returns: np.ndarray, rf=0, period=252):
"""计算夏普比率:(投资组合期望收益率 - 无风险收益) / 投资组合波动率"""
Er = daily_returns.sum() / len(daily_returns) - rf / period # 每日的平均收益 - 每日的无风险收益
sharp = Er / daily_returns.std() * math.sqrt(period)
return sharp
def xiangguanxing():
f = pd.read_excel(path3)
s = f.corr()
print(s)
ax = plt.subplots(1,1)
ax = sns.heatmap(s,vmax = 1,square=True,annot=True)
plt.xticks()
plt.yticks()
# sns.pairplot(f)
# # sns.pairplot(s,hue='sepal_width')
# pd.plotting.scatter_matrix(f,figsize=(12,12),range_padding=0.5)
plt.show()4. La cuarta pregunta
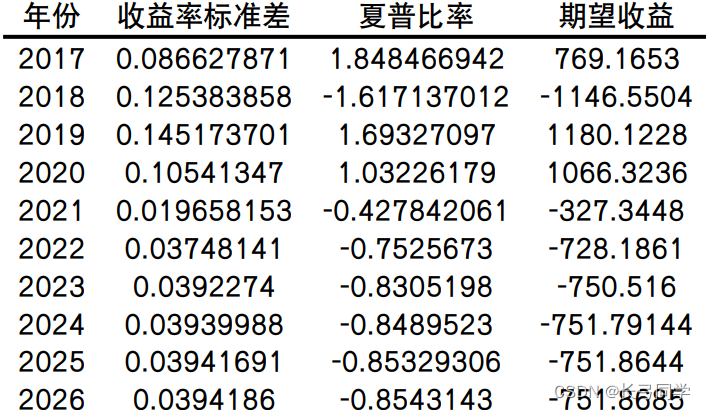
Análisis del tema: organice y combine 4 tipos de acciones, 3 tipos de bonos, 2 tipos de índices de materias primas y 1 tipo de fondo monetario, un total de 24 tipos de colocaciones y seleccione las características de riesgo-rendimiento de los últimos cinco años según al mapa de calor del coeficiente de correlación obtenido en la tercera pregunta, se pronostica que los portafolios de inversión más aptos para la etapa de recuperación en los próximos cinco años y con retornos altos son: SSE 50, CSI 300, South China Commodity Index , CSI-Comprehensive Wealth (3-5 años, 7-10 años), fondos del mercado monetario. Luego use el algoritmo LSTM para predecir las características de riesgo-rendimiento de la cartera de inversiones (el método se basa en la segunda pregunta).
(Dado que la cuarta pregunta es una aplicación integral de las primeras tres preguntas, no entraré en detalles aquí)
resultado de pronóstico:
(por ejemplo, resultados de predicción de las características de riesgo-rendimiento del CSI 300 para los próximos cinco años)
3. Resumen
La pregunta B utiliza principalmente el conocimiento de minería de datos y análisis de datos. La predicción de datos futuros utiliza el algoritmo LSTM de aprendizaje automático. Como excelente variante del modelo de RNN, LSTM hereda la mayoría de las características del modelo RNN y resuelve el problema de la El problema de desaparición de gradiente causado por la reducción gradual en el proceso de retropropagación de gradiente puede realizar el almacenamiento y la entrada de datos a largo plazo. Por lo tanto, agregarlo al algoritmo de ventana deslizante puede usarse bien para predecir datos durante un largo período de tiempo en el futuro.
Esta competencia ha sido muy fructífera para mí y puede considerarse como una experiencia de aprendizaje en el campo desconocido del modelado de datos financieros. En términos generales, la dificultad de la competencia no es demasiado alta y la competencia dura 8 días con mucha El tiempo, y la experiencia de la competencia es buena, es muy adecuado para las matemáticas financieras como juego de práctica.