Tabla de contenido
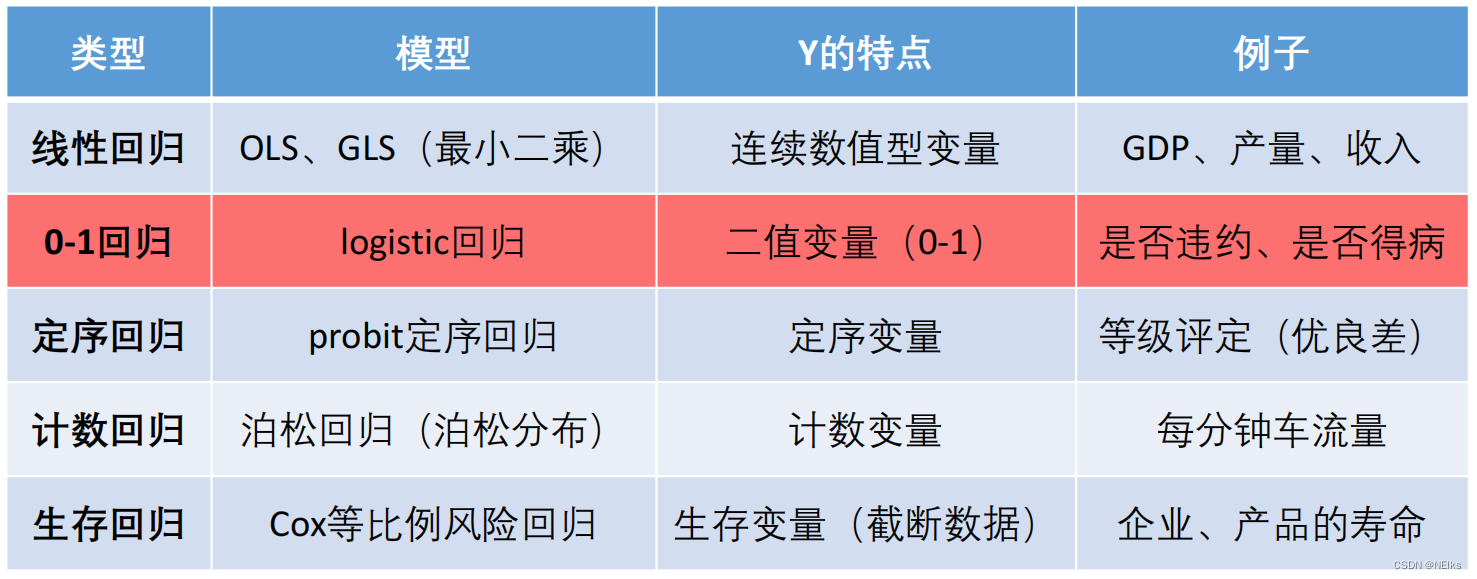
regresión logística regresión logística
Modelo de probabilidad lineal (LPM)
Spss resuelve la regresión logística
Configuración de regresión paso a paso
Las variables independientes tienen variables categóricas.
Mala predicción: agregue término cuadrado/término de interacción
Cómo determinar el modelo correcto: validación cruzada
Análisis discriminante lineal de Fisher.
Problema de clasificación múltiple
Análisis discriminante de Fisher.
regresión logística regresión logística
01 La regresión logística se puede usar para la regresión, es decir, cuando la variable dependiente es una variable categórica , se puede usar la regresión logística:
trate y como la probabilidad de que ocurra un evento, y> = 0,5 significa que ocurre; y <0,5 significa que ocurre No sucede.
Modelo de probabilidad lineal ( LPM )
Si utiliza directamente el modelo lineal anterior para la regresión:
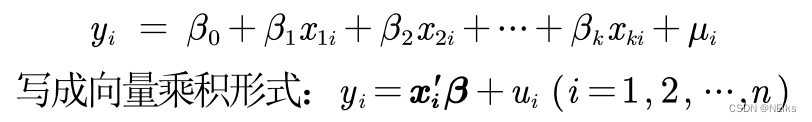
Problemas con el modelo anterior :
- Como y sólo puede tomar 0/1, existe un problema de endogeneidad:

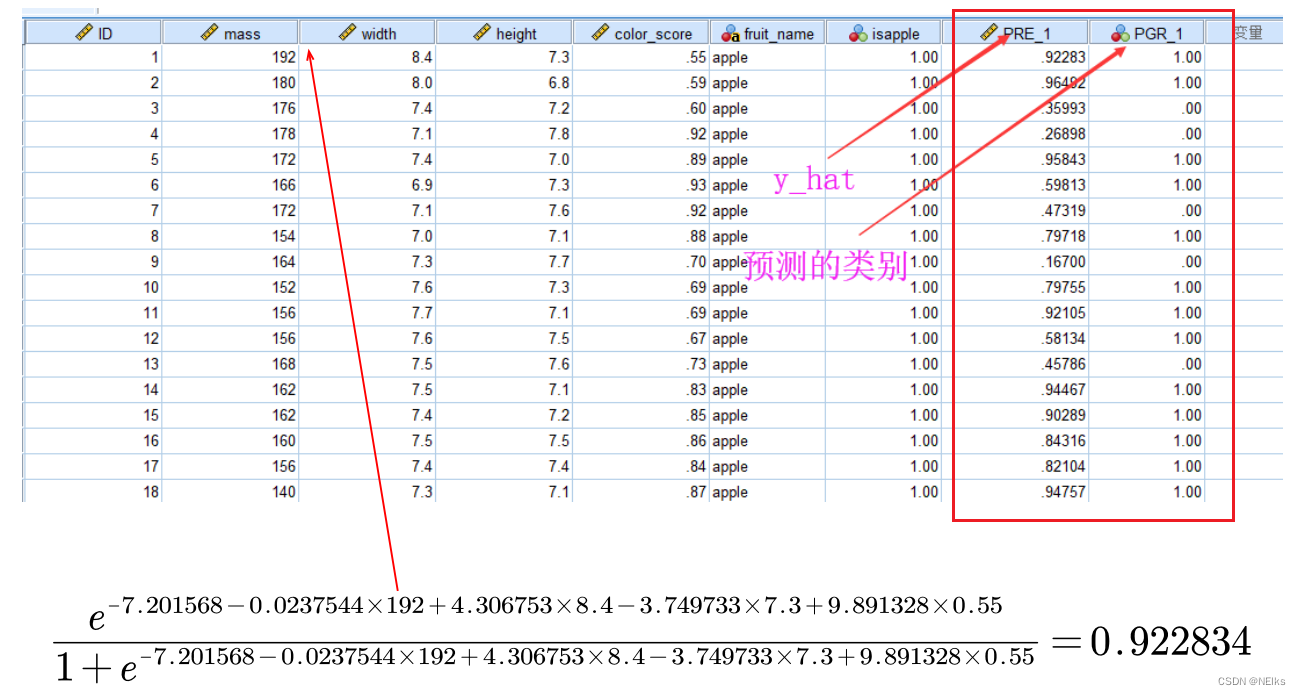
- y_hat, es decir, el valor predicho de y es probabilidad (más adelante se explicará por qué y_hat puede entenderse como "la probabilidad de que ocurra y = 1" . Lógicamente hablando, debería estar entre 0 y 1, pero el valor previsto y_hat < 0 o > ocurrirá 1 situación poco realista
Por lo tanto, se necesita una función de conexión para limitar el valor entre 0 y 1 :

¿Por qué y_hat puede entenderse como "la probabilidad de que ocurra y = 1" ? Según el modelo de distribución de dos puntos,

Cómo elegir la función de conexión (dos tipos de regresión) :
① Regresión probit de la función de densidad acumulada de distribución normal estándar ② Regresión logística de la función sigmoidea

(El contenido del cuadro rojo está incluido en el documento)

f1=@(x) normcdf(x); % 标准正态分布的累积分布函数
fplot(f1, [-4,4]); % 在-4到
4上画出匿名函数的图形
hold on;
grid on;
f2=@(x) exp(x)/(1+exp(x));
fplot(f2, [-4,4]);
legend('标准正态分布的cdf','sigmoid函数','location','SouthEast')Cómo resolver el modelo después de sumar la función de conexión (es decir, encontrar el coeficiente βi ) : no escrito en su totalidad

Después de encontrar el número desconocido β en el modelo, cómo predecir a qué clase pertenece la muestra a clasificar :
Sustituya los datos conocidos de xi de la muestra a probar en el modelo para encontrar y_hat. Si y_hat >= 0.5, se considera que y=1 , y la muestra pertenece a la clasificación correspondiente a y=1 (Principio: comprenda y_hat como la probabilidad de que ocurra y = 1)

(El contenido del cuadro rojo está incluido en el documento)
Spss resuelve la regresión logística
paso
Primero convierta la variable dependiente (categoría de clasificación) en una variable categórica (variable ficticia) :
Crear variables ficticias en SPSS: Transformación de la barra de herramientas - Crear variables ficticias - Introducir el nombre raíz
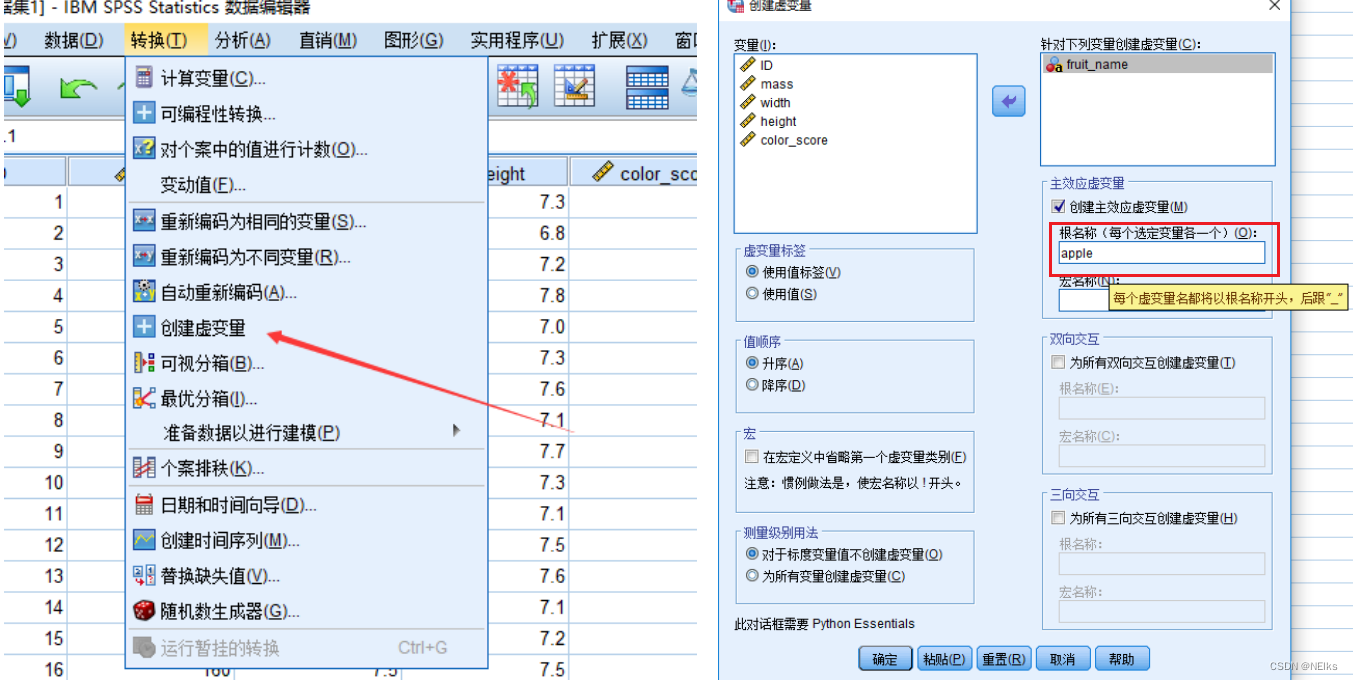 En la "Vista de variables" en la parte inferior, puede ver variables, modificar nombres de variables, etc.
En la "Vista de variables" en la parte inferior, puede ver variables, modificar nombres de variables, etc.
Regresión logística de SPSS: Análisis - Regresión - Logística binaria ; agregue covariables y variables independientes; si hay variables categóricas , haga clic en Clasificación - Covariables categóricas para crear variables ficticias; al guardar , verifique la probabilidad y el grupo en el grupo de valores predichos ; puede elija realizar una regresión paso a paso en las opciones ; si el número de muestras es demasiado pequeño, puede hacer clic en muestreo de autoservicio
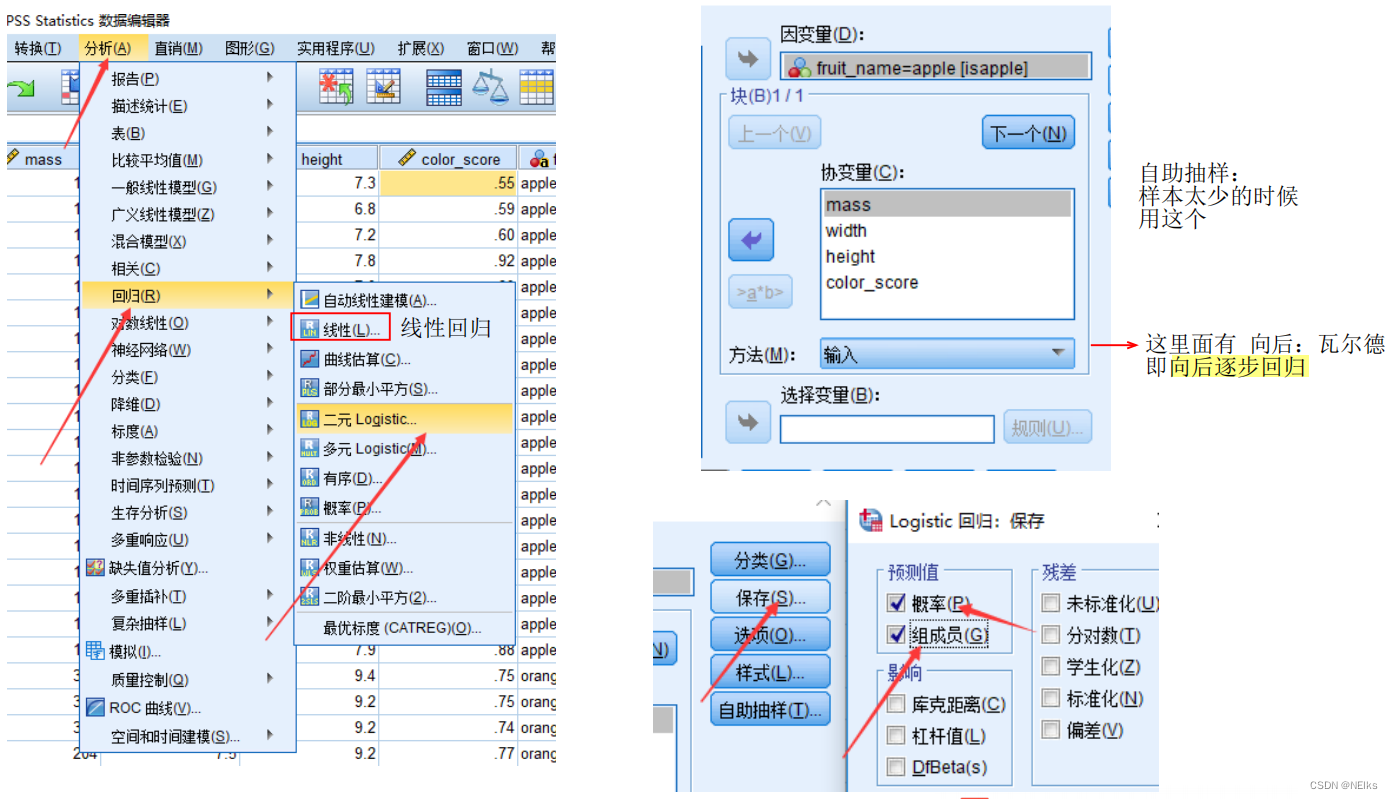
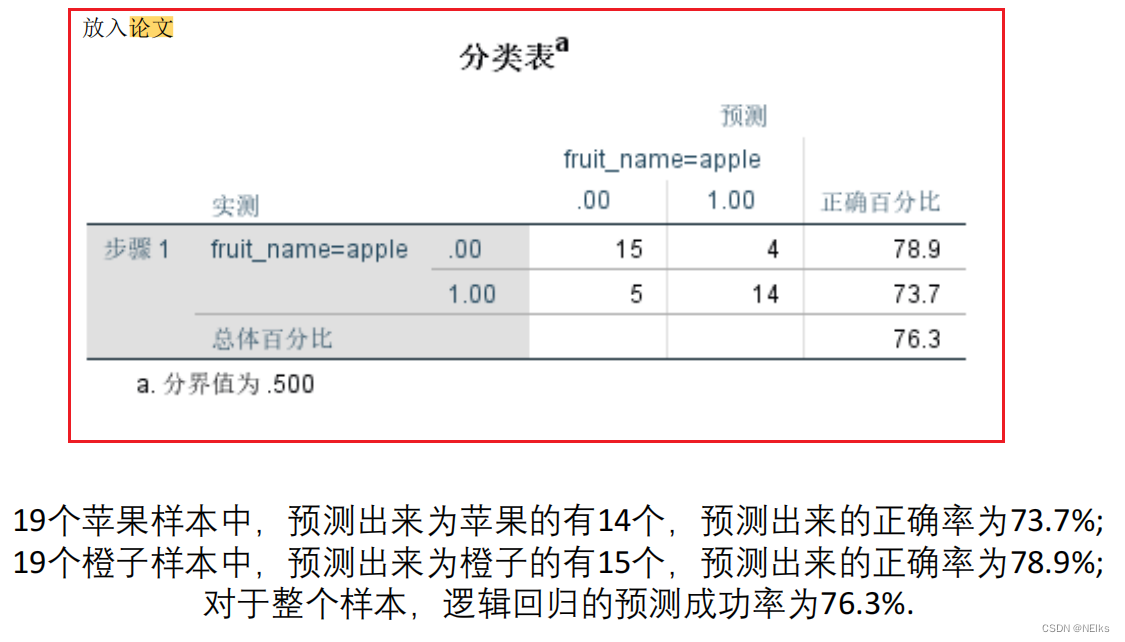
Vea la tabla de resultados: la tabla de clasificación y la tabla de coeficientes de regresión logística se colocan en el documento.

Configuración de regresión paso a paso

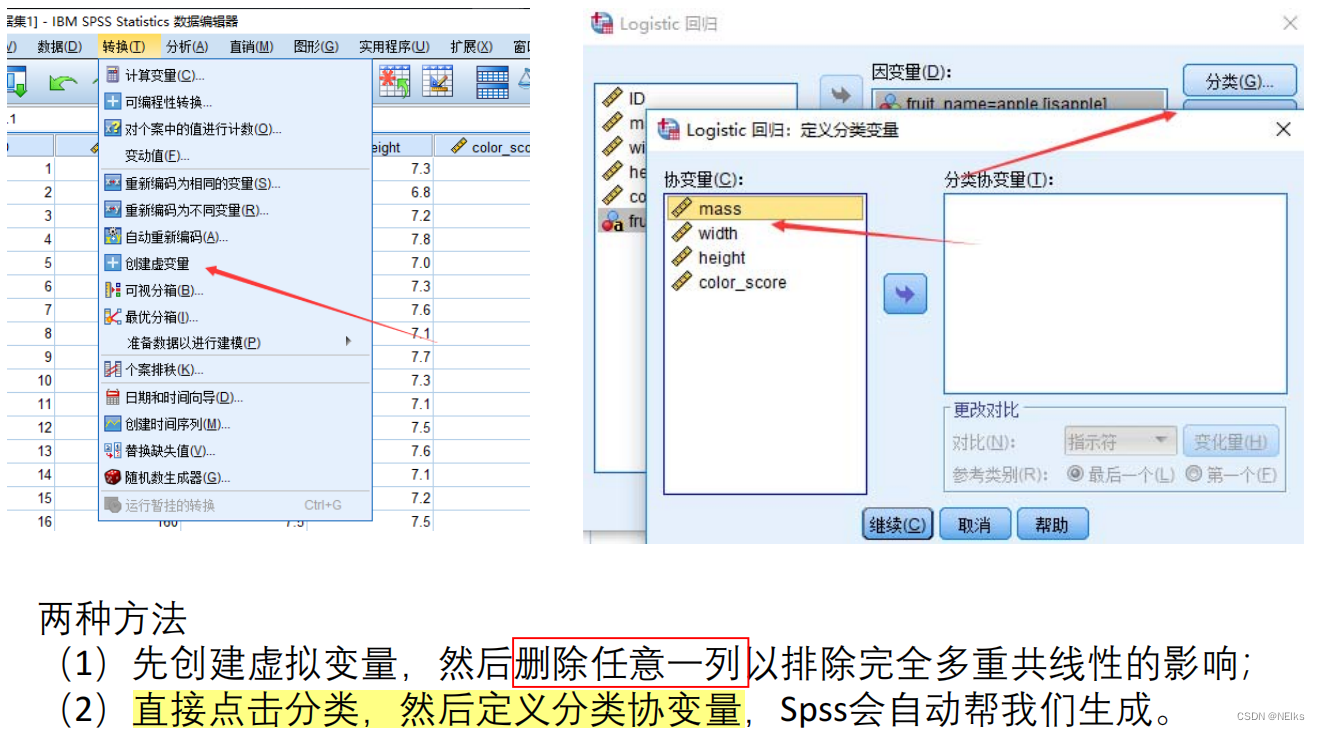
Las variables independientes tienen variables categóricas.
Añadir a covariables categóricas
Mala predicción: agregue término cuadrado/término de interacción
Agregue una nueva columna de término al cuadrado (a todos los argumentos de este ejemplo se les agrega un término al cuadrado):

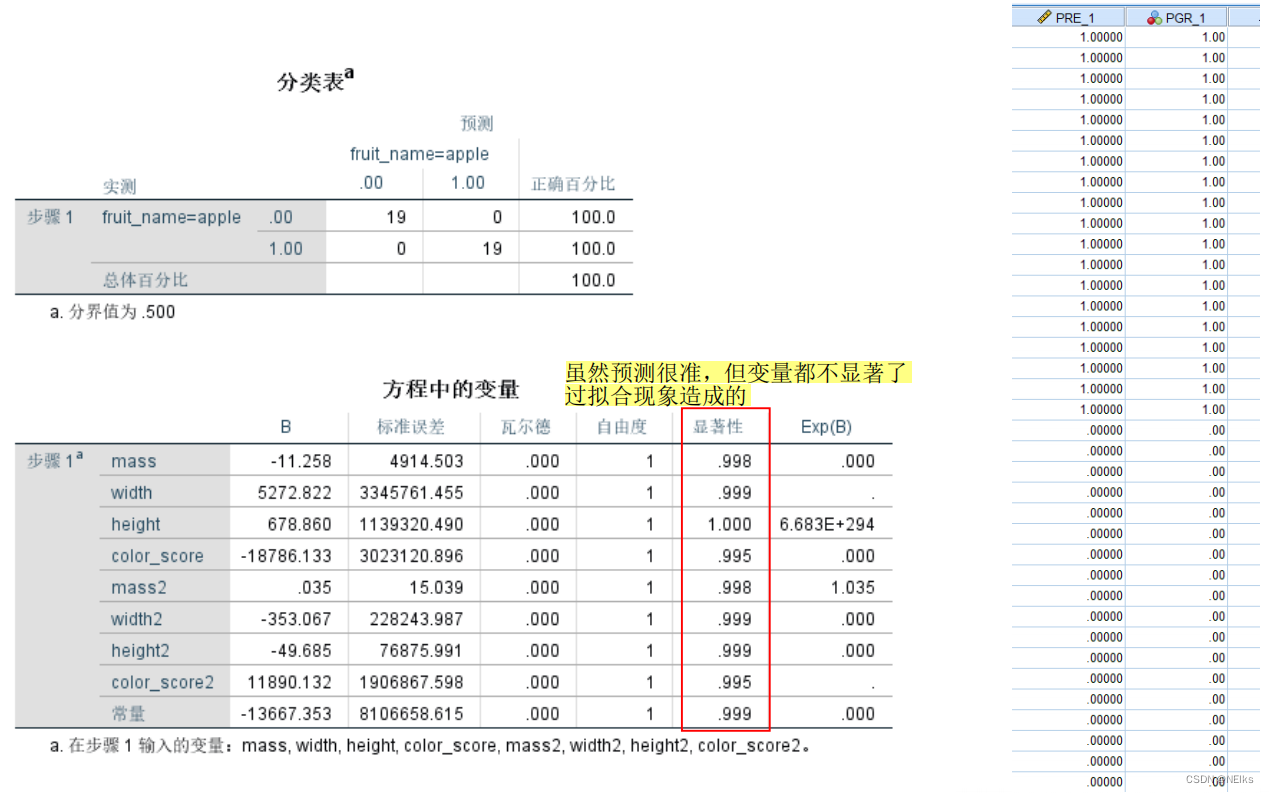
Fenómeno de sobreajuste

Cómo determinar el modelo correcto: validación cruzada
Si ahora tenemos el modelo 1 y el modelo 2 con el término cuadrado agregado, cuál es más exacto para medir:
Divida los datos en un grupo de entrenamiento y un grupo de prueba , use los datos del grupo de entrenamiento para estimar el modelo y use los datos del grupo de prueba para verificar los resultados de predicción del modelo. Seleccione aleatoriamente algunos
de los datos originales como grupos de prueba para ver qué modelo predice con mayor precisión para eliminar el azar. Para influir en el impacto, puede seleccionar aleatoriamente más grupos de prueba y realizar varios entrenamientos y pruebas más, y finalmente calcular la precisión promedio de cada modelo . Este paso es transversal validación.
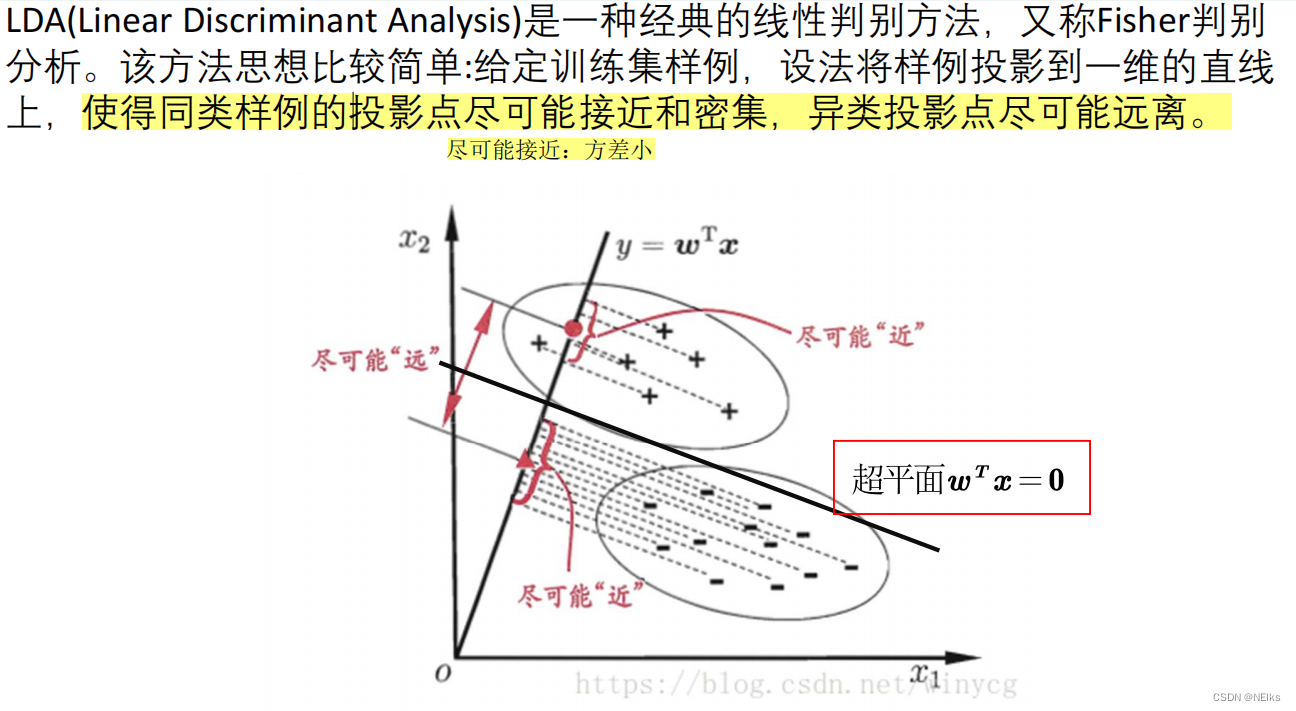
Análisis discriminante lineal de Fisher.
Idea: encontrar un hiperplano para separar diferentes tipos de puntos. Los puntos de proyección de muestras similares deben ser lo más cercanos y densos posible, y los puntos de proyección de muestras heterogéneas deben estar lo más lejos posible.
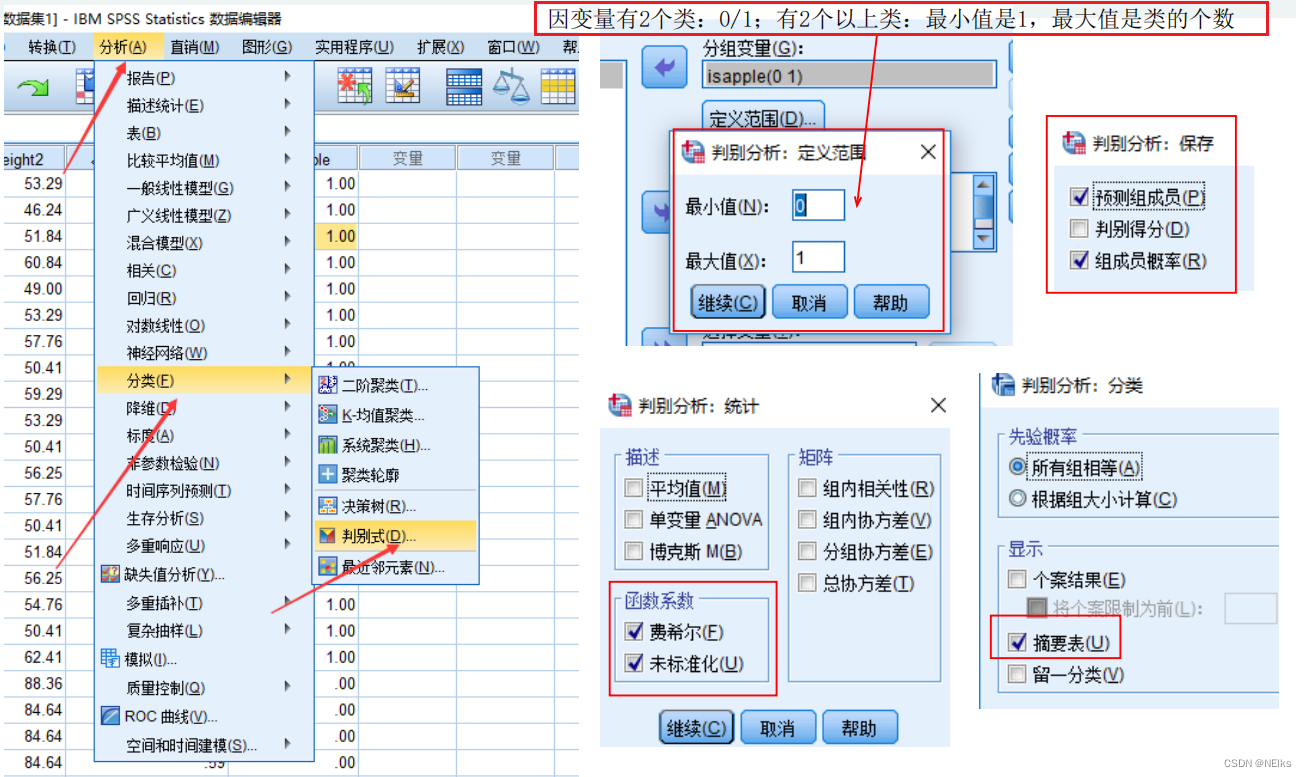
Operaciones SPSS
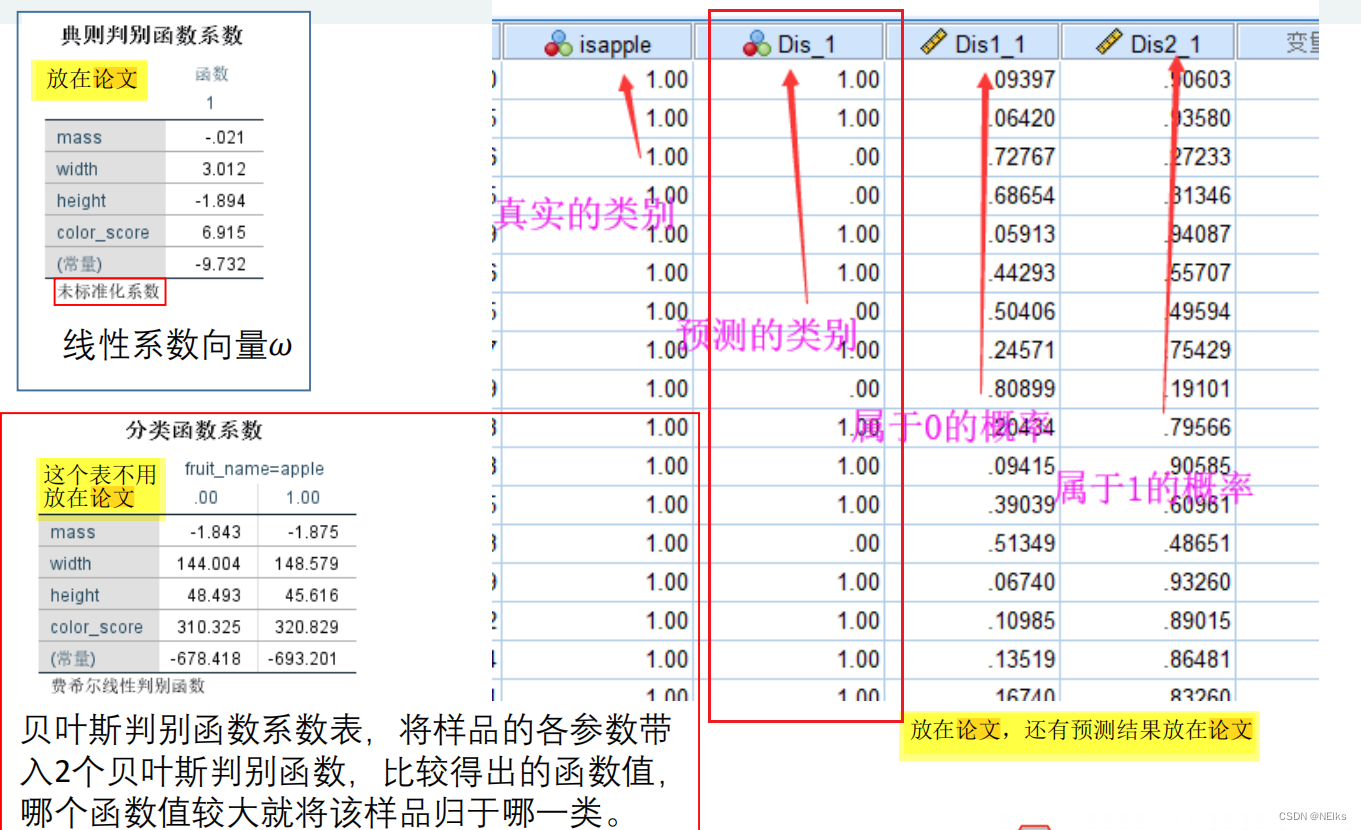
resultado:
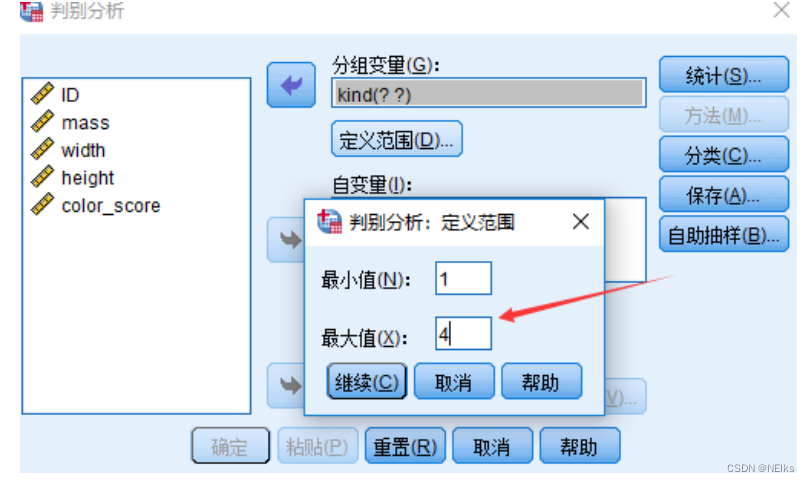
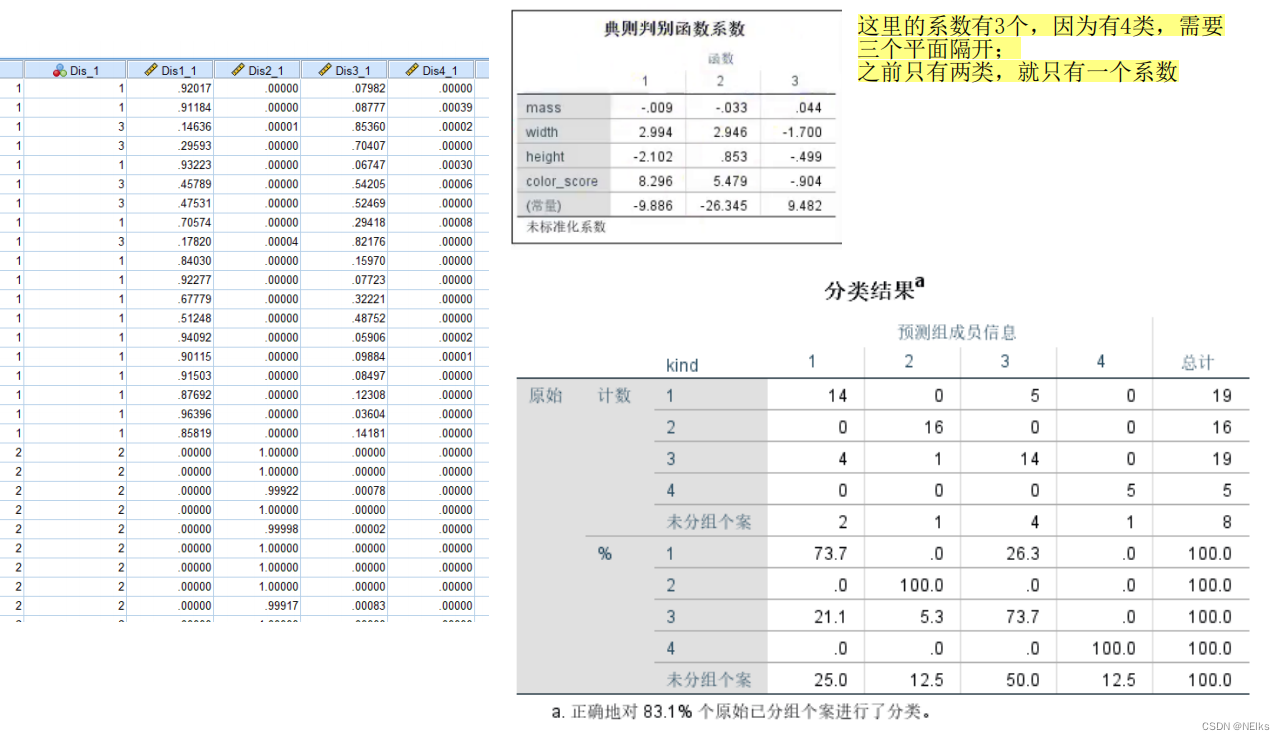
Problema de clasificación múltiple
Generar números categóricos para variables dependientes: en excel - Reemplazo

Análisis discriminante de Fisher.
https://blog.csdn.net/z962013489/article/details/79918758
Simplemente ajuste el rango de la variable dependiente:
Regresión logística
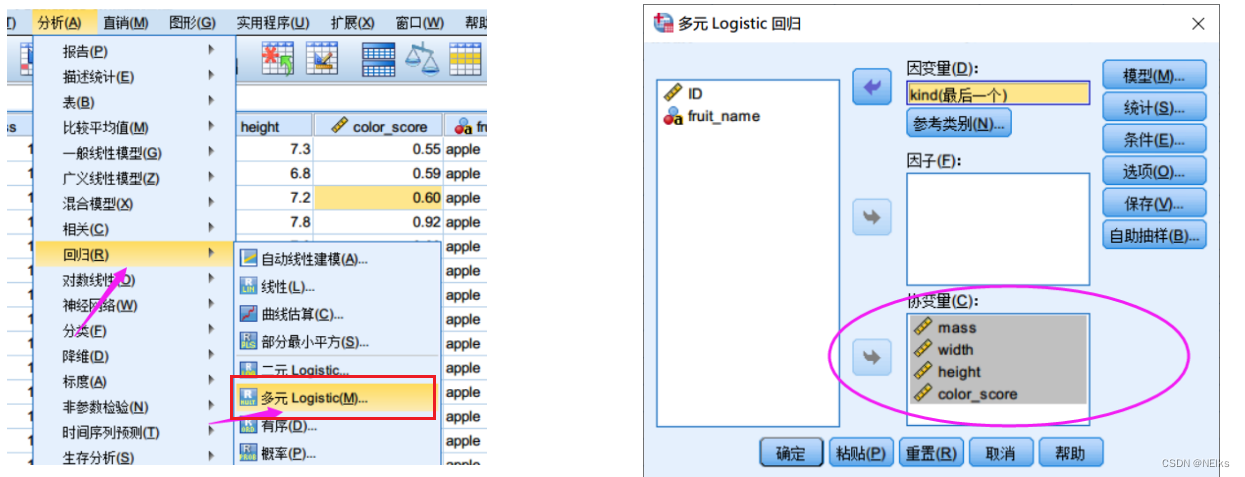


La diferencia entre factores y covariables en SpssFactor: se refiere a variables categóricas, como género, educación, etc.Covariables: se refiere a variables continuas, como área, peso, etc.