Table of contents
- 1 Introduction
- 2. The GT high-speed interface solution I have here
- 3. The most detailed interpretation of GTX network
- 4. Design thinking framework
- 5. vivado project 1-->2-way SFP transmission
- 6. vivado project 2-->1 channel SFP transmission
- 7. Board debugging and verification
- 8. Benefits: Acquisition of engineering codes
1 Introduction
I am ashamed to say that I have played FPGA before if I have never played GT resources. This is a sentence said by a big guy at CSDN, and I firmly believe it. . .
GT resources are an important selling point of Xilinx series FPGAs, and they are also the basis for high-speed interfaces. Whether it is PCIE, SATA, MAC, etc., GT resources are required for high-speed serialization and deserialization of data. Different FPGA series of Xilinx have different GT resource type, the low-end A7 has GTP, K7 has GTX, V7 has GTH, and the higher-end U+ series has GTY, etc. Their speed is getting higher and higher, and their application scenarios are becoming more and more high-end. . .
This article uses the GTX resource of Xilinx's Kintex7 FPGA and the PCIE resource based on XDMA to do video transmission experiments. There are two kinds of video sources, which correspond to whether the developer has a camera or not. One is to use a laptop to simulate HDMI video and IT6802 to decode it. The input HDMI is GRB for FPGA to use; if you don’t have a camera in your hand, or your development board doesn’t have an HDMI input interface, you can use the dynamic color bars generated inside the code to simulate the video of the camera; the selection of the video source is through ` at the top of the code The define macro definition is carried out, and the HDMI input is used as the video source by default; the GTX IP core is called, the codec module and data alignment module of the video data are written in verilog, and the two SFP optical ports on the development board hardware are used to transmit and receive data, and the FPGA receives After receiving the high-speed data sent by SFP, use FDMA to write the data into the DDR3 cache, then call XDMA to read the data in DDR3, and then send the data to the computer host through XDMA through the PCIE2.0 bus, and use QT on the computer side The machine receives and displays images; this blog provides 2 sets of vivado project source code, the difference between the 2 sets of projects is whether to use 1 SFP optical port for sending and receiving or two 2 SFP optical ports for sending and receiving;
This blog describes in detail the design scheme of FPGA GTX 8b/10b encoding and decoding PCIE video transmission. The engineering code can be comprehensively compiled and debugged on the board, and can be directly ported to the project. It is suitable for students and postgraduate project development, and is also suitable for on-the-job engineers to learn Improvement, which can be applied to high-speed interfaces or image processing fields in medical, military and other industries;
provide complete and smooth engineering source code and technical support;
the method of obtaining engineering source code and technical support is at the end of the article, please be patient to the end ;
disclaimer
This project and its source code are partly written by myself, and partly obtained from public channels on the Internet (including CSDN, Xilinx official website, Altera official website, etc.). The project and its source code are limited to the personal study and research of readers or fans, and commercial use is prohibited. If the legal issues caused by the commercial use of readers or fans for their own reasons have nothing to do with this blog and the blogger, please use it with caution. . .
2. The GT high-speed interface solution I have here
My homepage has a FPGA GT high-speed interface column, which includes video transmission routines and PCIE transmission routines for GT resources such as GTP, GTX, GTH, and GTY, among which GTP is based on A7 series FPGA development boards, and GTX is based on K7 or ZYNQ series FPGA development board is built, GTH is built based on KU or V7 series FPGA development board, GTY is built based on KU+ series FPGA development board; the following is the column address:
click to go directly
3. The most detailed interpretation of GTX network
The most detailed introduction to GTX must be Xilinx's official "ug476_7Series_Transceivers", we use this to interpret:
I have put the PDF document of "ug476_7Series_Transceivers" in the data package, and there is a way to obtain it at the end of the article; the
FPGA model of the development board I used It is Xilinx Kintex7 xc7k325tffg676-2; it has 8 channels of GTX resources, 2 of which are connected to 2 SFP optical ports, and the sending and receiving speed of each channel is between 500 Mb/s and 10.3125 Gb/s. GTX transceivers support different serial transmission interfaces or protocols, such as PCIE 1.1/2.0 interface, 10 Gigabit network XUAI interface, OC-48, serial RapidIO interface, SATA (Serial ATA) interface, digital component serial interface (SDI) etc;
GTX basic structure
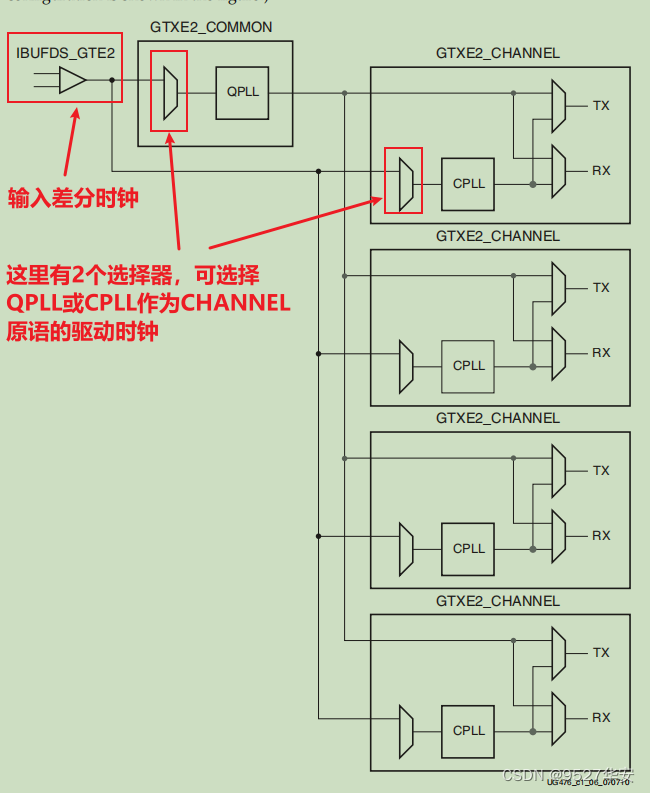
Xilinx uses Quad to group serial high-speed transceivers. Four serial high-speed transceivers and a COMMOM (QPLL) form a Quad. Each serial high-speed transceiver is called a Channel (channel). The figure below shows four The schematic diagram of the GTX transceiver in the Kintex7 FPGA chip: "ug476_7Series_Transceivers" page 24; the
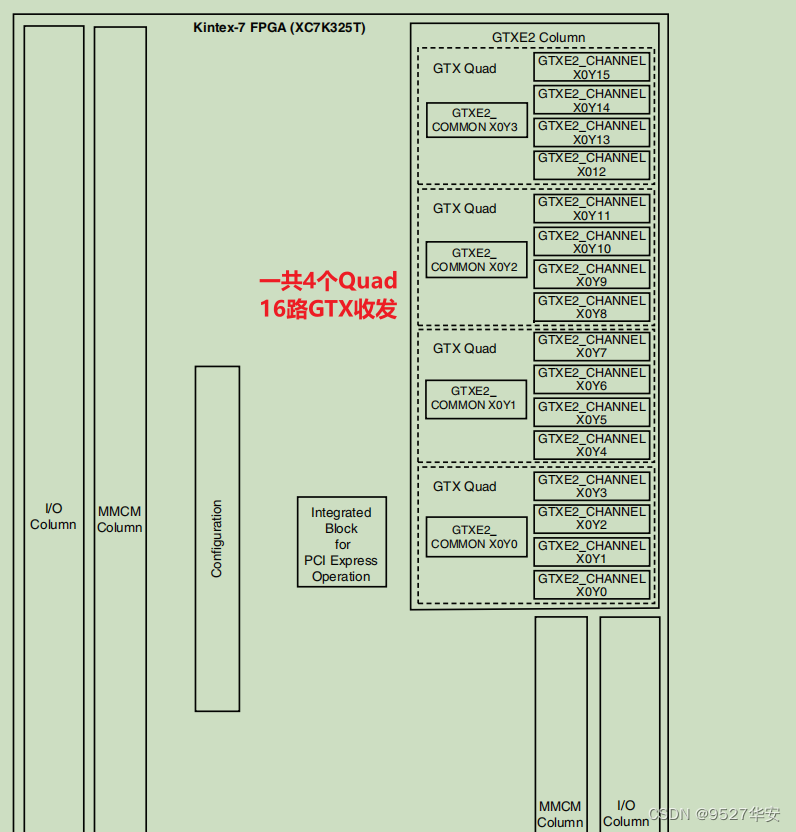
specific internal logic block diagram of GTX is shown below, which consists of four transceiver channels GTXE2_CHANNEL primitives and a GTXE2_COMMON primitive. Each GTXE2_CHANNEL includes a transmitting circuit TX and a receiving circuit RX. The clock of GTXE2_CHANNEL can come from CPLL or QPLL, which can be configured in the IP configuration interface; "ug476_7Series_Transceivers" page 25;
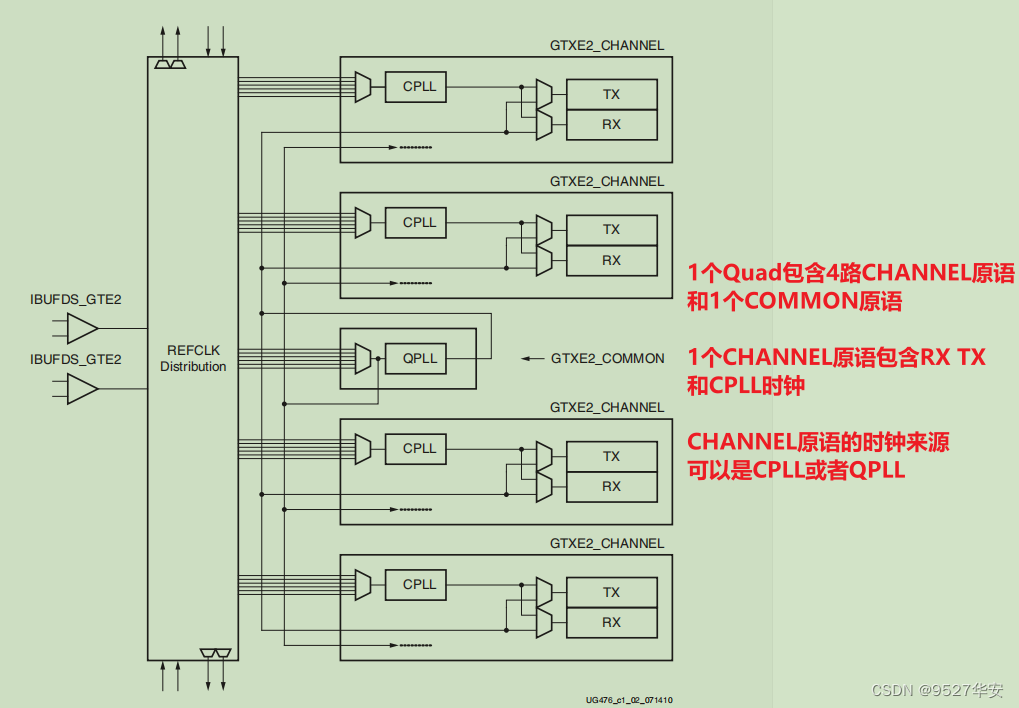
The logic circuit of each GTXE2_CHANNEL is shown in the figure below: "ug476_7Series_Transceivers" page 26;
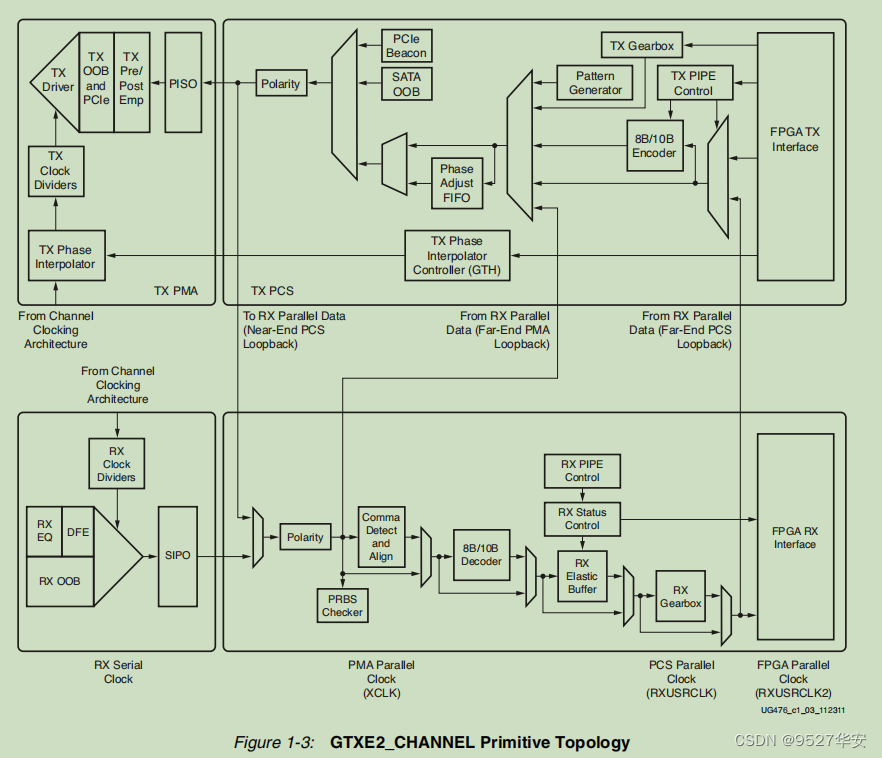
the function of the sending end and receiving end of GTXE2_CHANNEL is independent, and both are composed of PMA (Physical Media Attachment, physical media adaptation layer) and PCS (Physical Coding Sublayer , physical coding sublayer) consists of two sublayers. The PMA sublayer includes high-speed serial-to-parallel conversion (Serdes), pre-/post-emphasis, receiving equalization, clock generator and clock recovery circuits. The PCS sublayer includes circuits such as 8B/10B codec, buffer, channel bonding, and clock correction.
It doesn’t make much sense to say too much here, because if you haven’t done a few big projects, you won’t understand what’s inside. For first-time users or fast users, more energy should be focused on the calling and use of IP cores , I will also focus on the call and use of the IP core later;
GTX send and receive processing flow
First, the user logic data enters a sending buffer (Phase Adjust FIFO) after being encoded by 8B/10B. This buffer is mainly used for clock isolation between the two clock domains of the PMA sublayer and the PCS sublayer, and solves the clock rate matching and phase adjustment between the two. For the problem of difference, the parallel-to-serial conversion (PISO) is performed through high-speed Serdes. If necessary, pre-emphasis (TX Pre-emphasis) and post-emphasis can be performed. It is worth mentioning that if you accidentally cross-connect the TXP and TXN differential pins during PCB design, you can make up for this design error through polarity control (Polarity). The receiving end and the sending end process are opposite, and there are many similarities, so I won’t go into details here. It should be noted that the elastic buffer of the RX receiving end has clock correction and channel binding functions. Every function point here can write a paper or even a book, so here you only need to know a concept, and you can use it in a specific project, or the same sentence: For the first time or want to use it quickly For those who are concerned, more energy should be focused on the calling and use of IP cores.
Reference clock for GTX
The GTX module has two differential reference clock input pins (MGTREFCLK0P/N and MGTREFCLK1P/N), which can be selected by the user as the reference clock source of the GTX module. On the general A7 series development board, there is a 148.5Mhz GTX reference clock connected to MGTREFCLK0 as the reference clock of GTX. The differential reference clock is converted into a single-ended clock signal by the IBUFDS module and entered into the QPLL or CPLL of GTXE2_COMMOM to generate the required clock frequency in the TX and RX circuits. If the TX and RX transceiver speeds are the same, the TX circuit and the RX circuit can use the clock generated by the same PLL. If the TX and RX transceiver speeds are not the same, the clocks generated by different PLL clocks need to be used. Reference clock Here, the GT reference routine given by Xilinx has been done very well, and we don’t need to modify it when we call it; the reference clock structure diagram of GTX is as follows: "ug476_7Series_Transceivers" page 31;
GTX transmit interface
Pages 107 to 165 of "ug476_7Series_Transceivers" introduce the sending process in detail, and most of the content can be ignored by users, because the manual basically talks about his own design ideas, leaving the user's operable interface and Not many, based on this idea, we focus on the interface that needs to be used in the sending part left to the user when instantiating GTX;
Users only need to care about the clock and data of the sending interface. This part of the interface of the GTX instantiation module is as follows:
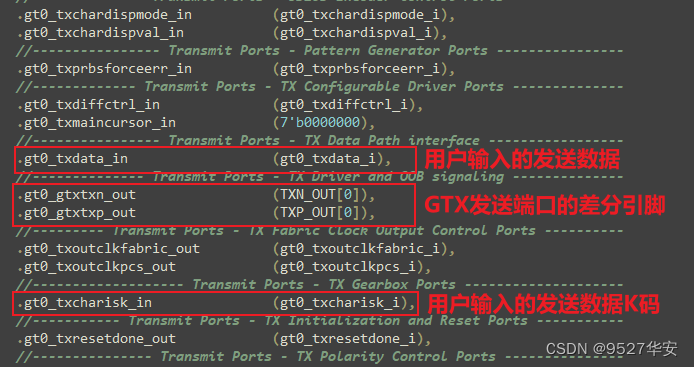
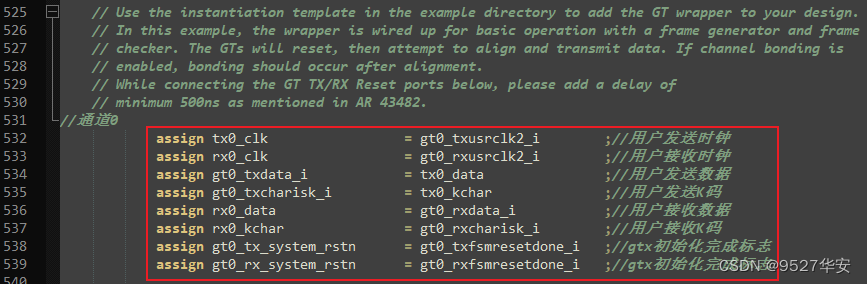
In the code, I have re-bound and made the top layer of the module for you. The code part is as follows:
GTX receiving interface
Pages 167 to 295 of "ug476_7Series_Transceivers" introduce the transmission process in detail, and most of the content can be ignored by users, because the manual basically talks about his own design ideas, leaving the user's operable interface and Not many, based on this idea, we will focus on the interfaces that the user needs to use in the sending part of the GTX instantiation; the
user only needs to care about the clock and data of the receiving interface. The interface of this part of the GTX instantiation module is as follows:
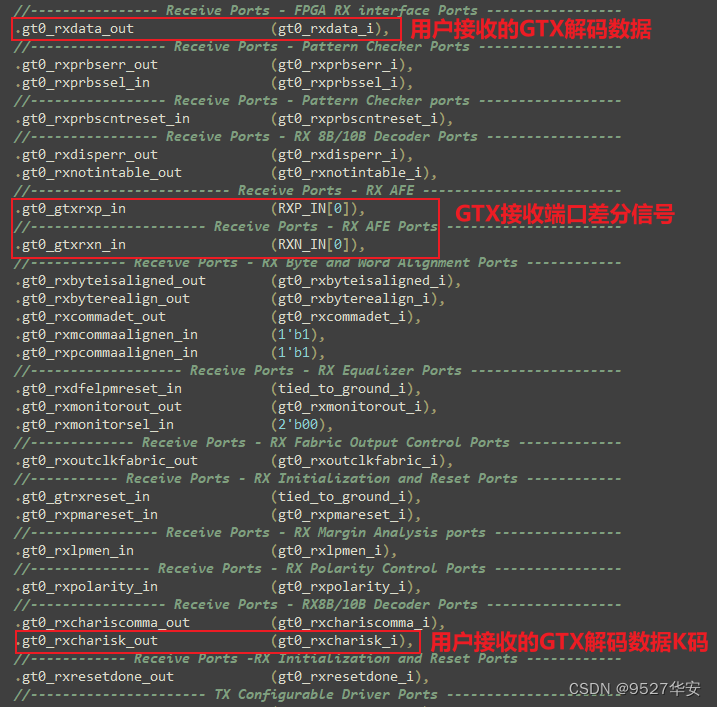
In the code, I have rebinded for you and made it to the top level of the module, the code part is as follows:
Call and use of GTX IP core
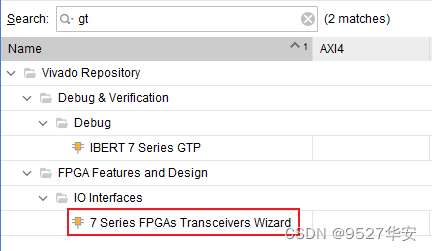
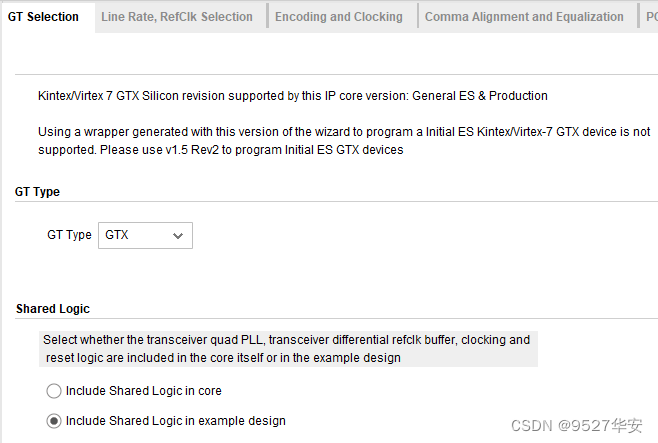
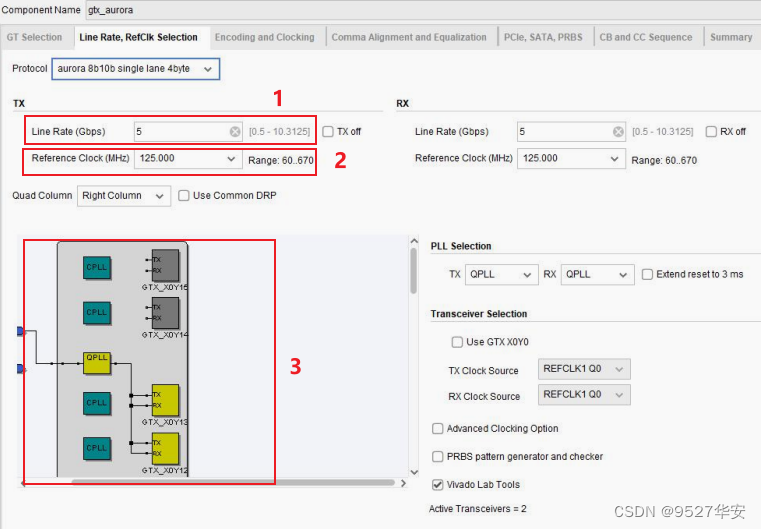
Here is an explanation of the labels in the above picture:
1: Line rate. According to your own project requirements, the range of GTX is 0.5 to 10.3125G. Since my project is video transmission, it can be within the range of GTX rate. In this example 2
: Reference clock, this depends on your schematic diagram, it can be 80M, 125M, 148.5M, 156.25M, etc., my development board is 125M; 4: GTX group
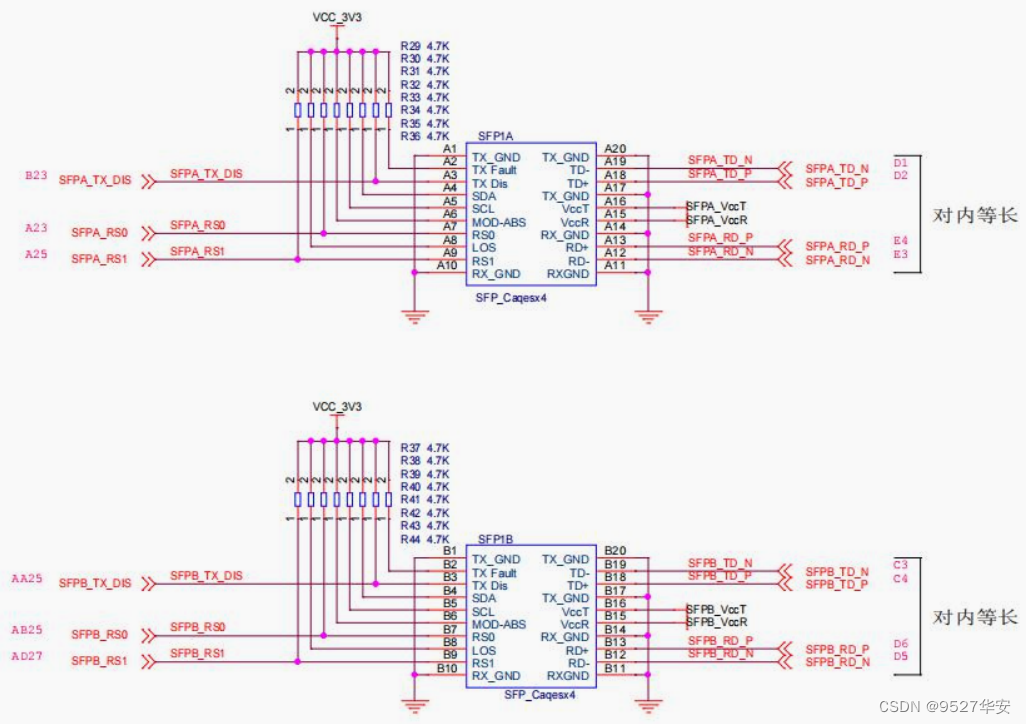
binding, this is very Important, there are two references for his binding. It is your development board schematic diagram, but the official reference "ug476_7Series_Transceivers". The official GTX resources are divided into multiple groups according to different banks. Since the GT resources are Xilinx series FPGAs The dedicated resources of GTX occupy a dedicated Bnak, so the pins are also dedicated, so how do these GTX groups and pins correspond? The description of "ug476_7Series_Transceivers" is as follows: the red box is the FPGA pin corresponding to the schematic diagram of my development board; the

schematic diagram of my board is as follows:
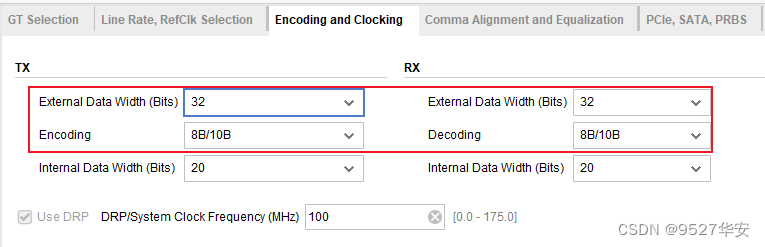
select the 8b/10b codec with an external data bit width of 32bit, as follows
: It is K code detection:
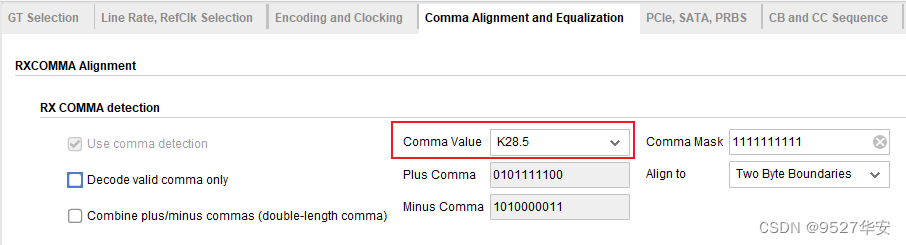
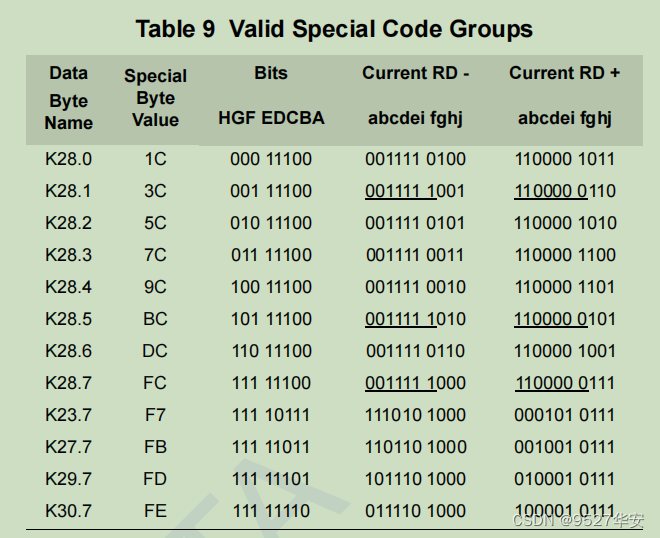
choose K28.5 here, which is the so-called COM code, and the hexadecimal system is bc. It has many functions, and it can represent idle disordered symbols and data misalignment marks. It is used to mark data misalignment. , the 8b/10b protocol defines the K code as follows:
the following is clock correction, that is, the elastic buffer corresponding to the internal receiving part of GTP;
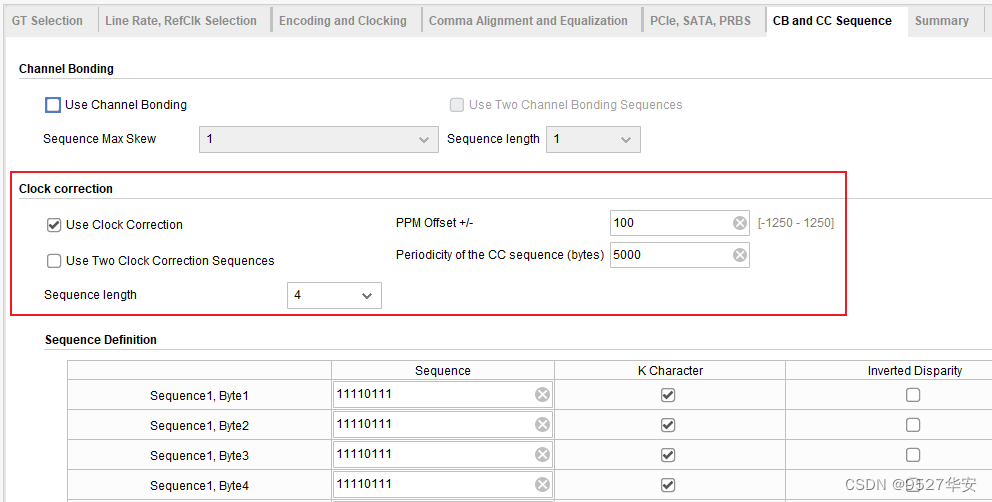
here is a concept of clock frequency offset, especially when the clock sources of the sending and receiving parties are different, set here The frequency offset is 100ppm, and it is stipulated that the sender sends a 4-byte sequence every 5000 data packets, and the elastic buffer of the receiver will decide to delete or insert a sequence according to the 4-byte sequence and the position of the data in the buffer. One byte in the 4-byte sequence, the purpose is to ensure the stability of the data from the sending end to the receiving end, and eliminate the influence of clock frequency offset;
4. Design thinking framework
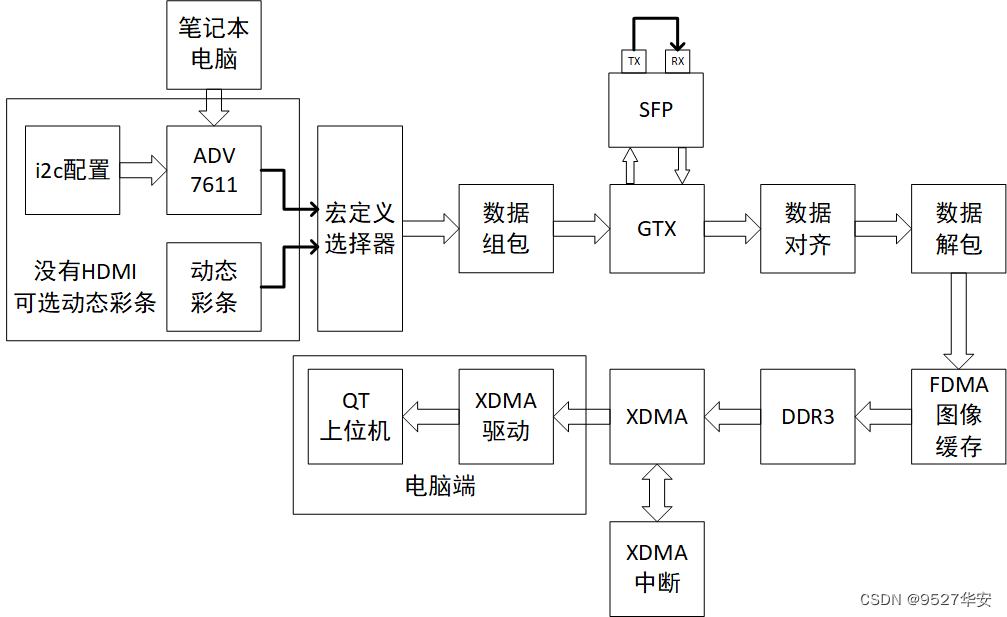
This blog provides 2 sets of vivado project source code. The difference between the 2 sets of projects is whether to use 1 SFP optical port for sending and receiving or two 2 SFP optical ports for sending and receiving; using 1 SFP optical port for sending and receiving is to connect the RX of SFP with optical fiber and TX; using 2 SFP optical ports for sending and receiving is to connect the RX of one SFP and the TX of another SFP with optical fiber; the framework of the design idea is as follows: the block diagram of using 2 SFP optical ports is as follows: the block diagram of using 1 SFP optical port is as
follows
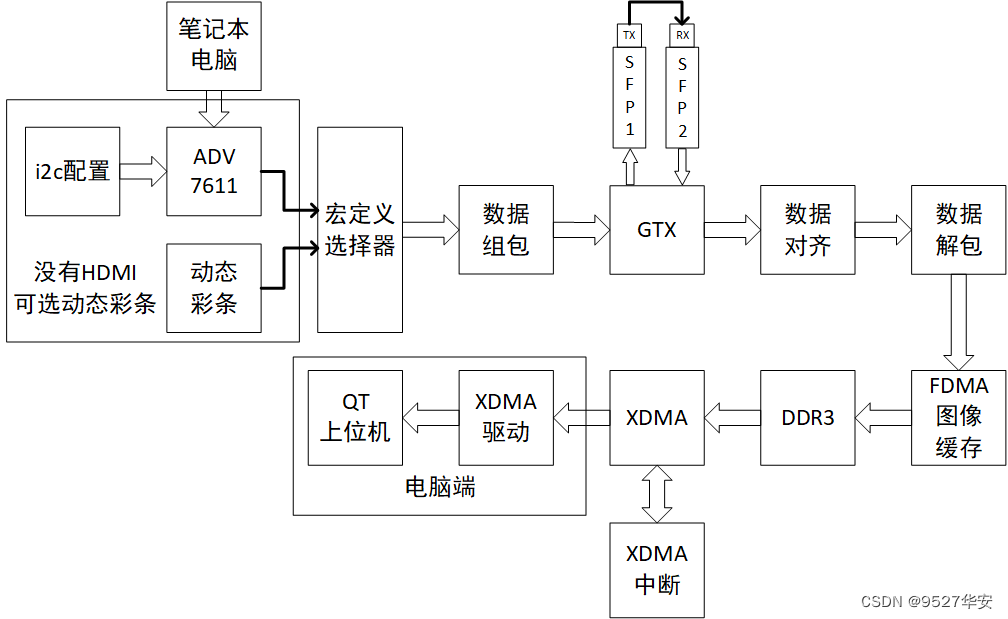
:
Video source selection
There are two types of video sources, corresponding to whether the developer has a camera or not. If you have a camera in your hand, or your development board has an HDMI input interface, use the HDMI input as the video input source. I use it here It is a notebook analog HDMI video, and the ADV7611 decoding chip decodes HDMI; if you do not have a camera in your hand, or your development board does not have an HDMI input interface, you can use the dynamic color bars generated inside the code to simulate camera video, and the dynamic color bars are moving pictures. , can completely simulate video; the default is to use HDMI input as the video source; the
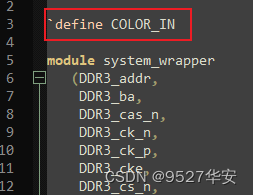
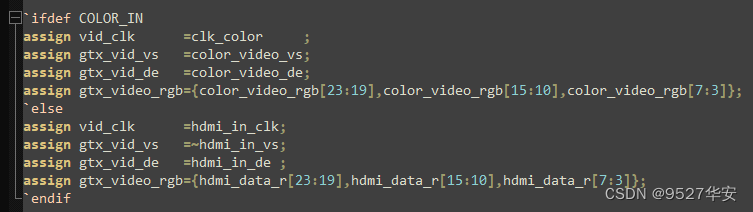
selection of the video source is carried out through the `define macro definition at the top level of the code ; The video is a dynamic color bar; when (not commenting) define COLOR_IN, the input source video is HDMI input;
ADV7611 decoding chip configuration and acquisition
The ADV7611 decoding chip requires i2c configuration to be used. The two parts of ADV7611 decoding chip configuration and acquisition are implemented with verilog code modules. The code location is as follows: the code is
configured as 1920x1080 resolution;
dynamic color bar
The dynamic color bar can be configured as videos with different resolutions. The border width of the video, the size of the dynamic moving square, and the moving speed can all be parameterized. I configure the resolution here as 1920x1080, the code position of the dynamic color bar module and the top-level interface and Instantiated as follows:

video packet
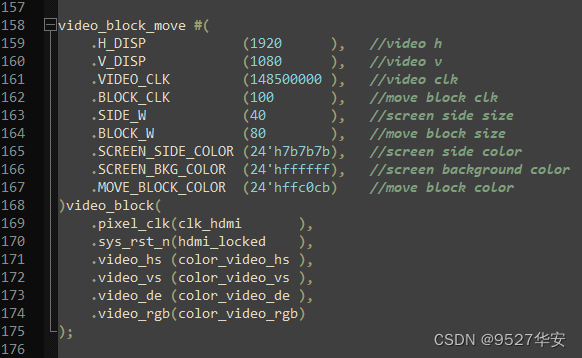
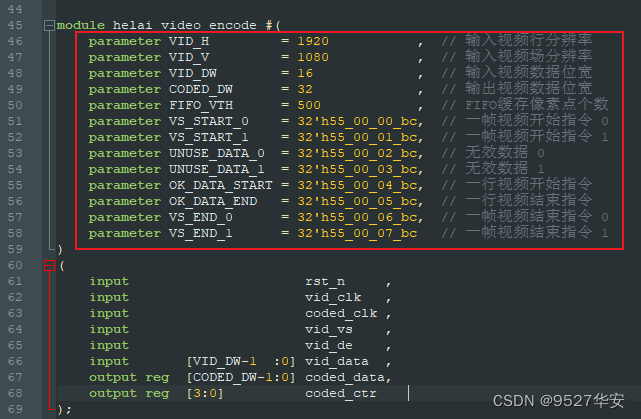
Since the video needs to be sent and received through the aurora 8b/10b protocol in GTX, the data must be packaged to adapt to the aurora 8b/10b protocol standard; the code position of the video data package module is as follows: first, we store the 16bit video in the
FIFO , when a line is full, it will be read from the FIFO and sent to GTX for transmission; before that, a frame of video needs to be numbered, which is also called an instruction. When GTX packs, it sends data according to a fixed instruction. The command restores the video field synchronization signal and video effective signal; when the rising edge of a frame of video field synchronization signal arrives, send a frame of video start instruction 0, and when the falling edge of a frame of video field synchronization signal arrives, send a frame Video start command 1, send invalid data 0 and invalid data 1 during the video blanking period, number each line of video when the video valid signal arrives, first send a line of video start command, and then send the current video line number, when a line of video is sent After completion, send a line of video end command. After sending a frame of video, first send a frame of video end command 0, and then send a frame of video end command 1; so far, a frame of video is sent. This module is not easy to understand. So I made detailed Chinese comments in the code. It should be noted that in order to prevent the Chinese comments from being displayed out of order, please use the notepad++ editor to open the code; the instructions are defined as follows: instructions can be changed arbitrarily, but the lowest byte must be
bc ;
GTX aurora 8b/10b
This is to call GTX to do the data encoding and decoding of the aurora 8b/10b protocol. I have already made a detailed overview of GTX before, so I won’t talk about it here; the code location is as follows:
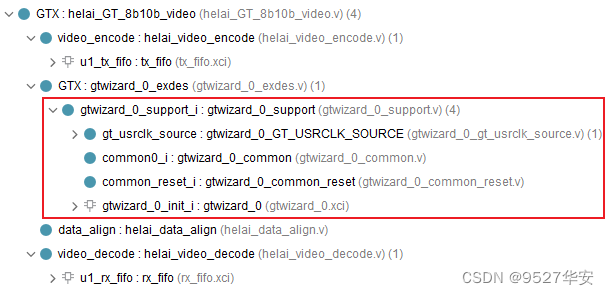
data alignment
Since the aurora 8b/10b data transmission and reception of GT resources naturally has data misalignment, it is necessary to perform data alignment processing on the received decoded data. The code position of the data alignment module is as follows: The K code control character format I defined is: XX_XX_XX_BC, so
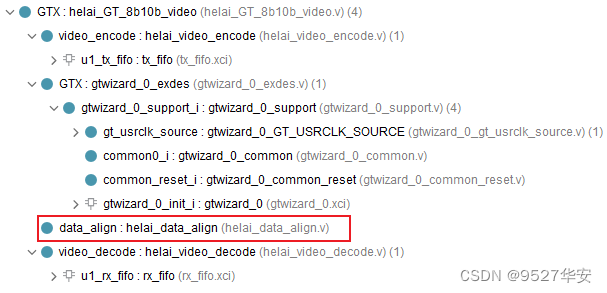
use One rx_ctrl indicates whether the data is a K-code COM symbol;
rx_ctrl = 4'b0000 indicates that the 4-byte data has no COM code;
rx_ctrl = 4'b0001 indicates that [7: 0] in the 4-byte data is a COM code;
rx_ctrl = 4'b0010 means [15: 8] in the 4-byte data is the COM code;
rx_ctrl = 4'b0100 means the [23:16] in the 4-byte data is the COM code;
rx_ctrl = 4'b1000 means the 4-byte [31:24] in the data is the COM code;
based on this, when the K code is received, the data will be aligned, that is, the data will be patted and combined with the new incoming data. This is the basis of FPGA Operation, no more details here;
Video data unpacking
Data unpacking is the reverse process of data packet packaging, and the code position is as follows:
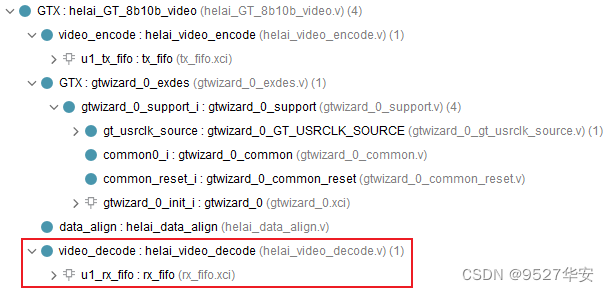
When GTX unpacks, it restores the video field synchronization signal and video effective signal according to fixed instructions; these signals are important signals for the subsequent image cache;
so far, the data enters and exits GTX The part has been finished, and the block diagram of the whole process is described in the code, as follows:
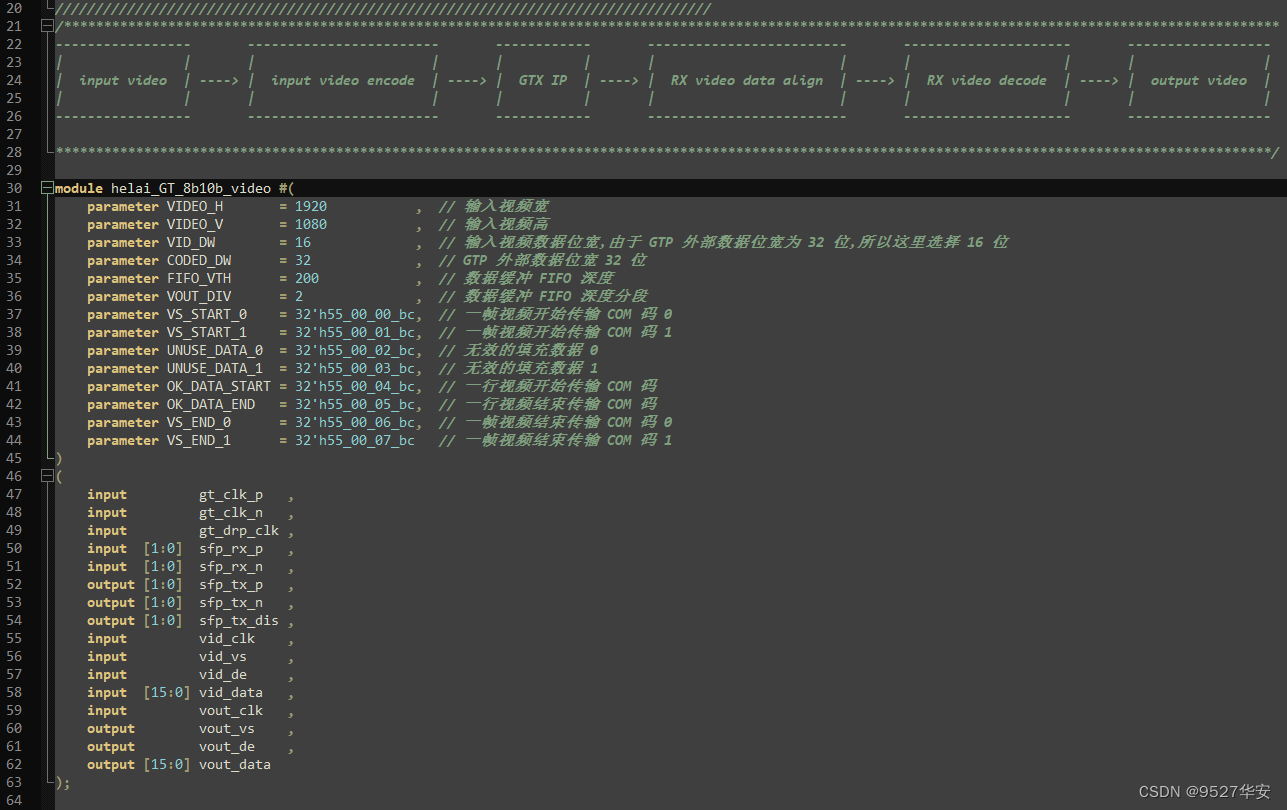
image cache
Old fans who often read my blog should know that my routine for image caching is FDMA. Its function is to send images to DDR for 3 frame buffers and then read them out for display. The purpose is to match the clock difference between input and output and improve output. Video quality, but only the function of writing to DDR3 is used here, and reading is useless, because XDMA does what it does when reading; about FDMA, please refer to my previous blog, blog address: click to go directly
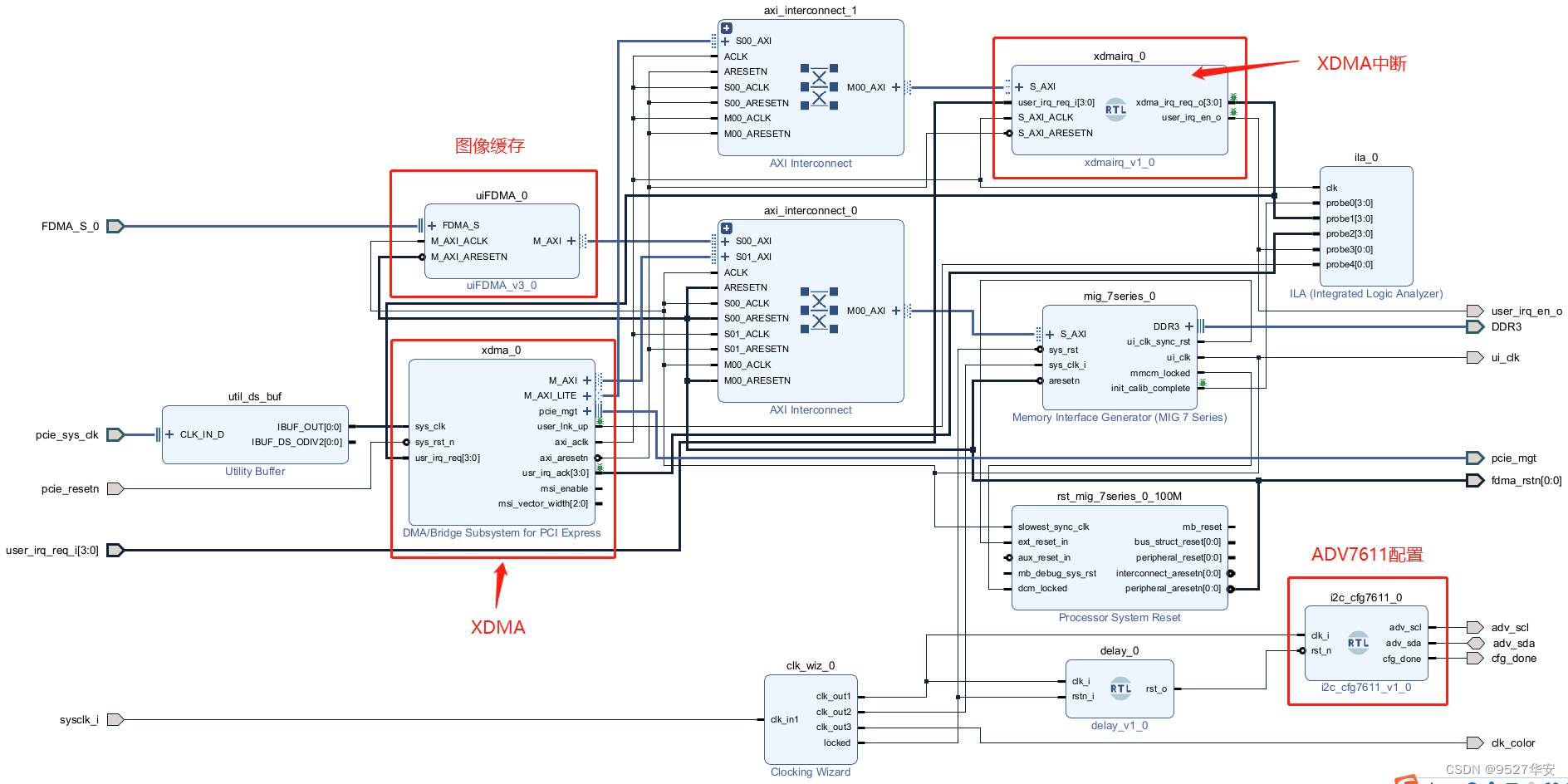
The use of XDMA and its interrupt mode
This design uses Xilinx's official XDMA solution to build a PCIE communication platform based on Xilinx series FPGAs, and uses the XDMA interrupt mode to communicate with the QT host computer, that is, the QT host computer implements data interaction with the FPGA through software interrupts; XDMA will receive from the SFP The received video is read from DDR3 and sent to the host computer through the PCIE bus. The host computer runs QT host computer software, and the QT software receives the image data sent by PCIE through on-off mode and displays the image in real time;
The key to this design is that we have written an XDMA interrupt module. This module is used to cooperate with the driver to handle interrupts. xdma_inter.v provides an AXI-LITE interface. The host computer reads and writes the registers of xdma_inter.v by accessing the user space address. The module registers the interrupt bit number in the interrupt bit input by user_irq_req_i, and outputs it to XDMA IP. When the driver of the upper computer responds to the interrupt, write the xdma_inter.v register in the interrupt to clear the processed interrupt. The code location of the DMA interrupt module is as follows:
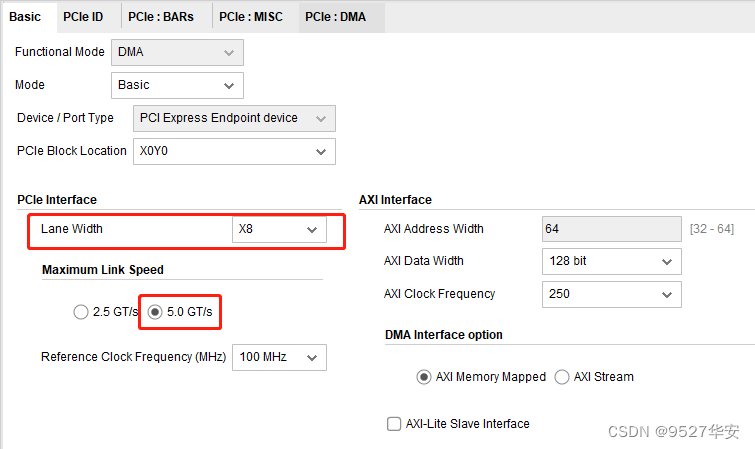
XDMA configuration is X8 mode, 5G line rate, as follows:
For XDMA-based PCIE applications, please refer to my PCIE communication column, column address: click to go directly
QT host computer and its source code
QT host computer This program uses VS2015 + Qt 5.12.10 to complete the development software environment of the host computer. The QT program calls the official XDMA API to realize data interaction with the FPGA in interrupt mode. This routine implements reading and writing speed measurement and provides QT host computer The path of the software and its source code is as follows:

The screenshot of QT source code is as follows:
5. vivado project 1–>2 SFP transmission
Development board FPGA model: Xilinx–Kintex7–xc7k325tffg900-2;
development environment: Vivado2022.2;
input: HDMI or dynamic color bars, resolution 1920x1080@60Hz;
output: PCIE2.0 X8;
application: 2-way SFP GTX 8b/10b Codec PCIE video transmission;
the project Block Design is as follows:
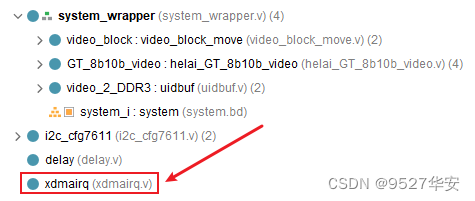
the project code structure is as follows:

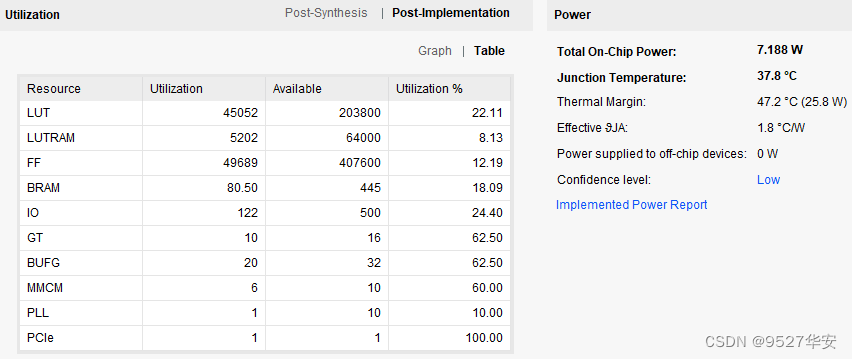
FPGA resource consumption and power consumption estimation after comprehensive compilation is as follows:
6. vivado project 2–>1 channel SFP transmission
Development board FPGA model: Xilinx–Kintex7–xc7k325tffg900-2;
development environment: Vivado2022.2;
input: HDMI or dynamic color bars, resolution 1920x1080@60Hz;
output: PCIE2.0 X8;
application: 1 channel SFP GTX 8b/10b Codec PCIE video transmission;
the project Block Design is as follows:
the project code structure is as follows:
FPGA resource consumption and power consumption estimation after comprehensive compilation is as follows:
7. Board debugging and verification
fiber optic connection
Project 1: The fiber connection method for 2-way SFP transmission is as follows:

Project 2: The fiber connection method for 1-way SFP transmission is as follows:

static demo
The following takes project 1: 2-way SFP transmission as an example to show the output effect after HDMI input:
when GTX runs at 5G line rate, the output is as follows:

8. Benefits: Acquisition of engineering codes
Benefits: Obtaining the engineering code
The code is too large to be sent by email, and it is sent by a certain degree network disk link. The
method of data acquisition: private, or the V business card at the end of the article.
The network disk information is as follows: