ziplist-压缩的双向链表
一、数据结构
其数据结构如下图表示(取自redis,src/ziplist.c源码)
<zlbytes><zltail><zllen><entry><entry><zlend>
| 4-bytes |
zlbytes:整个ziplist所占用的字节数
zltail:最后一个entry的偏移值
zllen:ziplist的entry的数量
zlend:ziplist的尾部,用255表示
entry:数据结构
| header | data |
| length of previous entry | data header | data |
length of previous entry: 前一个entry所占的字节长度
1.当小于254字节的时候,length of previous entry为1字节
2.当大于等于254字节时候,length of previous entry为5字节,
第一个字节为254,后四个字节表示所占字节长度
data header:主要有两大类,字符串和数字,下面来自src/ziplist.c描述:
* |00pppppp| - 1 byte
* String value with length less than or equal to 63 bytes (6 bits).
* |01pppppp|qqqqqqqq| - 2 bytes
* String value with length less than or equal to 16383 bytes (14 bits).
* |10______|qqqqqqqq|rrrrrrrr|ssssssss|tttttttt| - 5 bytes
* String value with length greater than or equal to 16384 bytes.
* |11000000| - 1 byte
* Integer encoded as int16_t (2 bytes).
* |11010000| - 1 byte
* Integer encoded as int32_t (4 bytes).
* |11100000| - 1 byte
* Integer encoded as int64_t (8 bytes).
* |11110000| - 1 byte
* Integer encoded as 24 bit signed (3 bytes).
* |11111110| - 1 byte
* Integer encoded as 8 bit signed (1 byte).
* |1111xxxx| - (with xxxx between 0000 and 1101) immediate 4 bit integer.
* Unsigned integer from 0 to 12. The encoded value is actually from
* 1 to 13 because 0000 and 1111 can not be used, so 1 should be
* subtracted from the encoded 4 bit value to obtain the right value.
* |11111111| - End of ziplist.
整数:前两位设置为1
如:
|11000000| - 16位整数
|11010000| - 32位整数
|11100000| - 64位整数
等
字符串:
|00pppppp| - 小于等于63字节数的字符串
|01pppppp|qqqqqqqq| - 需要两字节来表示data header, 小于等于16383字节数的字符串
|10______|qqqqqqqq|rrrrrrrr|ssssssss|tttttttt| - 需要5字节来表示data reader,大于16383字节数的字符串使用该格式
尾部:全部设置为11111111
1.ziplist可以通过data header计算出当前entry的结束位置,也就能得到下一个entry的起始位置,正向遍历
2.ziplist可以通过length of previous entry计算出上一个entry的起始位置,反向遍历
因此ziplist可以当做双向链表来使用。
二、查询
1.ziplistFind:
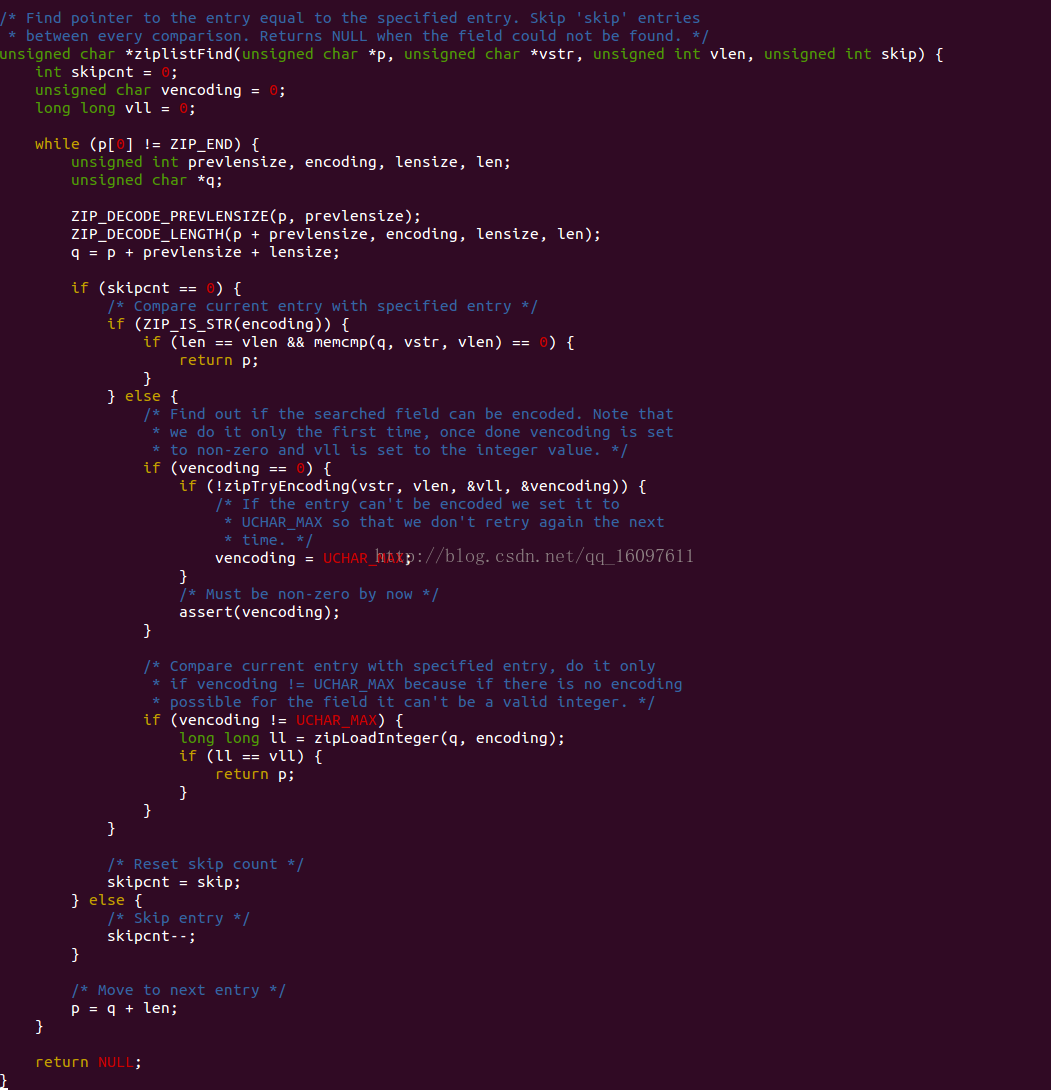
2.其中函数定义,这里说下skip参数的意义,ziplist除了会被list使用外,还会被hashmap和sorted set使用:
而其中的hasmap是key-value数据结构,那么对于ziplist如何存储呢,答案是key和value相邻存储,
如:
|key1-entry|value1-entry|key2-entry|value2-entry|,那么对于hashmap要查询key是否存在的时候,便需要每次跳过1个entry进行查询了,
因此这里的skip便是用在这里的,普通链表遍历skip=0即可

3.这里是解析当前的entry的头部信息,其中prevlensize为length of previous entry的占用字节数,lensize为data header的占用字节数,
因此q = p + prevlensize + lensize的q为当前entry的data起始位置

4.如果当前的p为字符串类型,则比较其字符串内容是否相等,相等即返回

5.如果当前的p为整数类型,那么便会比较其数值是否相等,相等即返回

三、插入数据
四、删除数据
