①. 压缩列表 - zipList
- ①. ZipList是一种特殊的"双端链表",由一系列特殊编码的连续内存块组成。可以在任意一端进行压入/弹出操作,并且该操作的时间复杂度为O(1) (oxff:11111111)
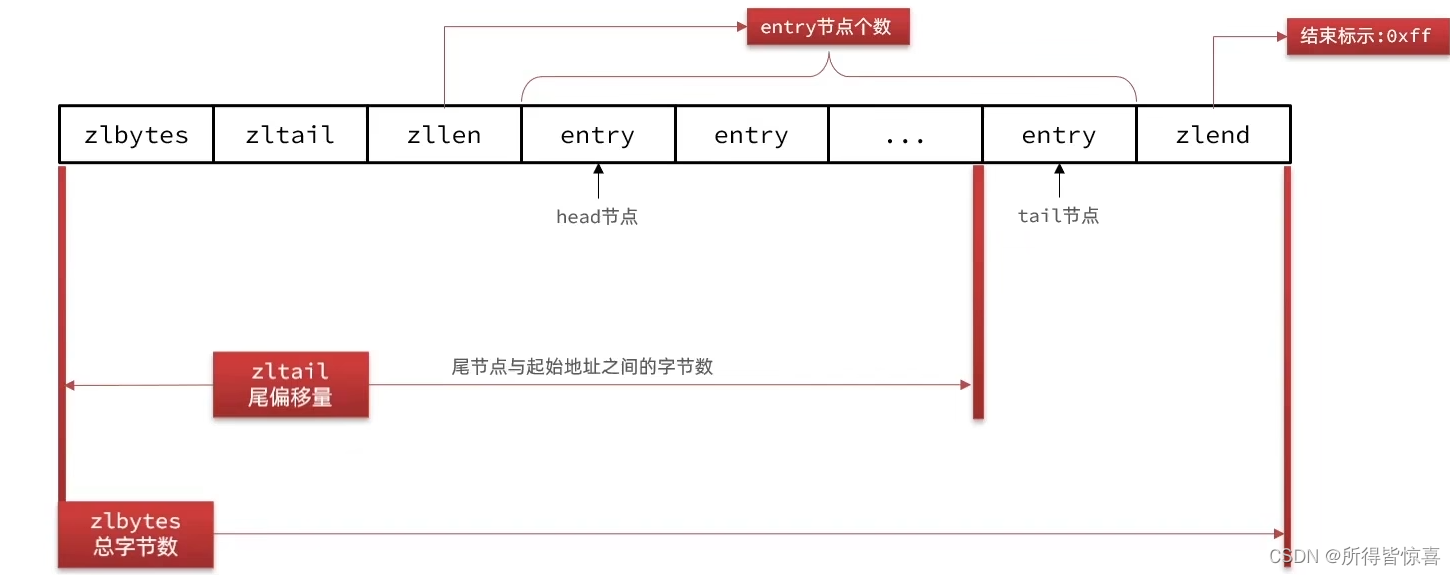
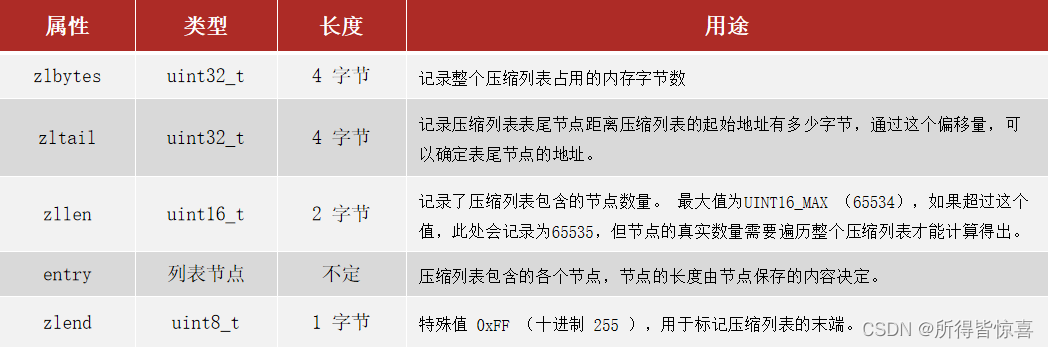
typedef struct zlentry {
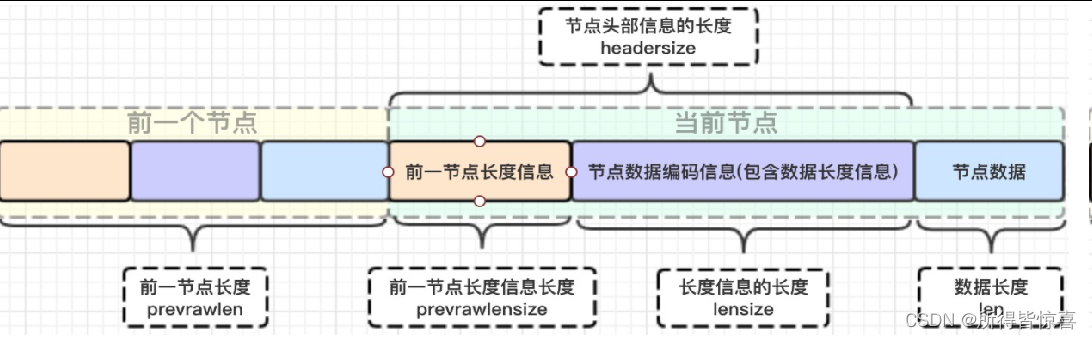
unsigned int prevrawlensize; /* 上一个链表节点占用的长度*/
unsigned int prevrawlen; /* 存储上一个链表节点的长度数值所需要的字节数 */
unsigned int lensize; /* 存储当前链表节点长度数值所需要的字节数*/
unsigned int len; /* 当前链表节点所占用长度 */
unsigned int headersize; /* 当前链表节点的头部大小:prevrawlensize + lensize. */
unsigned char encoding; /* 编码方式*/
unsigned char *p; /* 压缩链表以字符串的形式保存,该指针指向当前节点起始位置 */
} zlentry;
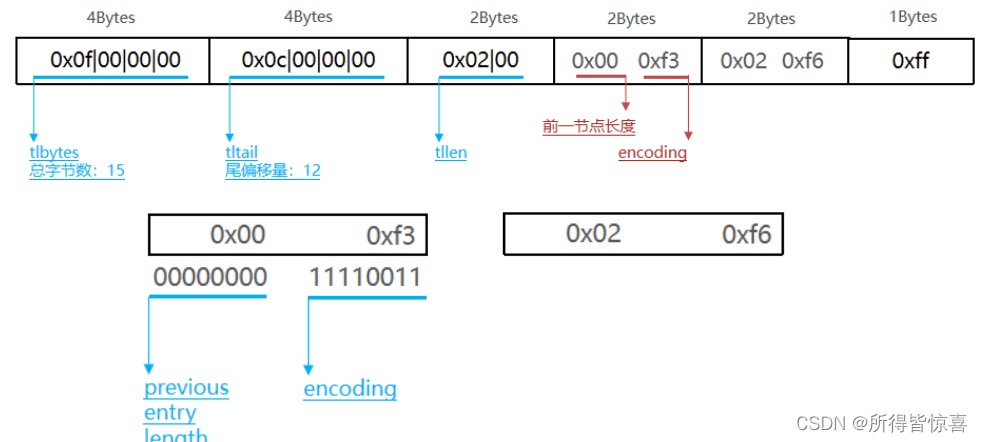
- ②. ZipList中的Entry并不像普通链表那样记录前后节点的指针,因为记录两个指针要占用16个字节,浪费内存。而是采用了下面的结构
- previous_entry_length:前一节点的长度,占1个或5个字节
如果前一节点的长度小于254字节,则采用1个字节来保存这个长度值
如果前一节点的长度大于254字节,则采用5个字节来保存这个长度值,第一个字节为0xfe,后四个字节才是真实长度数据 - encoding:编码属性,记录content的数据类型(字符串还是整数)以及长度,占用1个、2个或5个字节
- contents:负责保存节点的数据,可以是字符串或整数

-
③. ZipListEntry中的encoding编码分为字符串和整数两种:如下所示④⑤所示
-
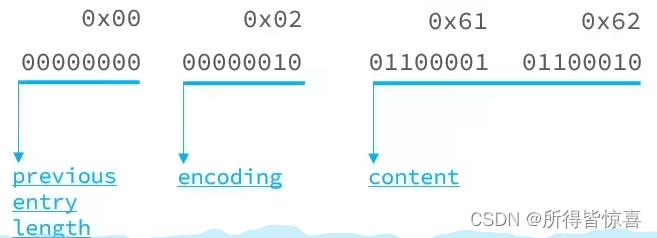
④. 字符串:如果encoding是以"00"、"01"或者"10"开头,则证明content是字符串
例如,我们要保存字符串:"ab"和 “bc”


-
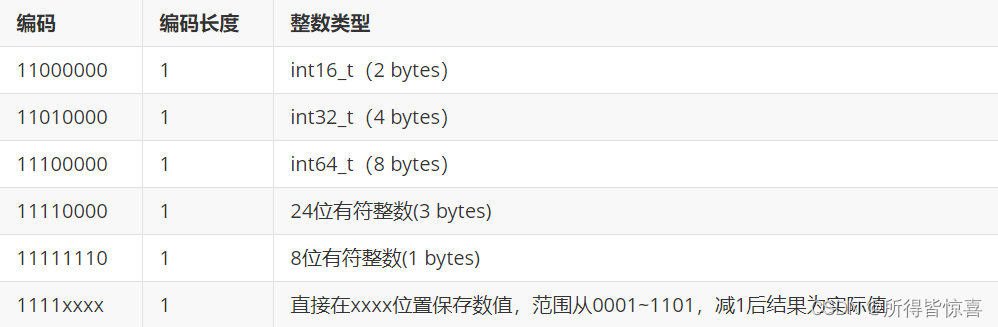
⑤. 整数:如果encoding是以"11"开始,则证明content是整数,且encoding固定只占用1个字节
例如,一个ZipList中包含两个整数值:“2"和"5”
-
⑥. ZipList的连锁更新问题
- ZipList的每个Entry都包含previous_entry_length来记录上一个节点的大小,长度是1个或5个字节:
如果前一节点的长度小于254字节,则采用1个字节来保存这个长度值
如果前一节点的长度大于等于254字节,则采用5个字节来保存这个长度值,第一个字节为0xfe,后四个字节才是真实长度数据 - 现在,假设我们有N个连续的、长度为250~253字节之间的entry,因此entry的previous_entry_length属性用1个字节即可表示,如图所示: 这个时候在头节点插入一个254byte的entry


- ⑦. ZipList特性:
- 压缩列表的可以看做一种连续内存空间的"双向链表"
- 列表的节点之间不是通过指针连接,而是记录上一节点和本节点长度来寻址,内存占用较低
- 如果列表数据过多,导致链表过长,可能影响查询性能
- 增或删较大数据时有可能发生连续更新问题
- ⑧. 明明有链表了,为什么出来一个压缩链表?
- 普通的双向链表会有两个指针,在存储数据很小的情况下,我们存储的实际数据的大小可能还没有指针占用的内存大,得不偿失。ziplist是一个特殊的双向链表没有维护双向指针: prev next;而是存储上一个entry的长度和当前entry的长度,通过长度推算下一个元素在什么地方
- 链表在内存中一般是不连续的,遍历相对比较慢,而ziplist可以很好的解决这个问题
- 头节点里有头节点里同时还有一个参数len,和string类型提到的SDS 类似,这里是用来记录链表长度的。因此获取链表长度时不用再遍历整个链表,直接拿到len值就可以了,这个时间复杂度是 O(1)
②. 快递列表 - QuickList
-
①. 问题1:ZipList虽然节省内存,但申请内存必须是连续空间,如果内存占用较多,申请内存效率很低。怎么办?
为了缓解这个问题,我们必须限制ZipList的长度和entry大小。 -
②. 问题2:但是我们要存储大量数据,超出了ZipList最佳的上限该怎么办?
我们可以创建多个ZipList来分片存储数据 -
③. 数据拆分后比较分散,不方便管理和查找,这多个ZipList如何建立联系?
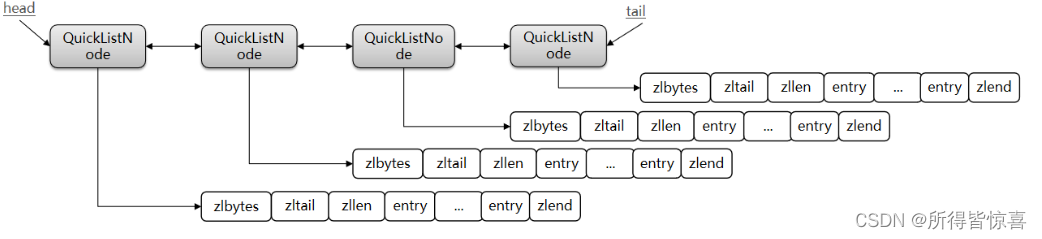
Redis在3.2版本引入了新的数据结构QuickList,它是一个双端链表,只不过链表中的每个节点都是一个ZipList
-
④. 为了避免QuickList中的每个ZipList中entry过多,Redis提供了一个配置项:list-max-ziplist-size来限制
- 如果值为正,则代表ZipList的允许的entry个数的最大值
- 如果值为负,则代表ZipList的最大内存大小,分5种情况:(其默认值为 -2)
-1:每个ZipList的内存占用不能超过4kb
-2:每个ZipList的内存占用不能超过8kb
-3:每个ZipList的内存占用不能超过16kb
-4:每个ZipList的内存占用不能超过32kb
-5:每个ZipList的内存占用不能超过64kb

- ⑤. ziplist压缩配置:list-compress-depth 0:表示一个quicklist两端不被压缩的节点个数。这里的节点是指quicklist双向链表的节点,而不是指ziplist里面的数据项个数,参数list-compress-depth的取值含义如下:
- 0: 是个特殊值,表示都不压缩。这是Redis的默认值
- 1: 表示quicklist两端各有1个节点不压缩,中间的节点压缩
- 2: 表示quicklist两端各有2个节点不压缩,中间的节点压缩
- 3: 表示quicklist两端各有3个节点不压缩,中间的节点压缩
依此类推…
-
⑥. 以下是QuickList的和QuickListNode的结构源码:

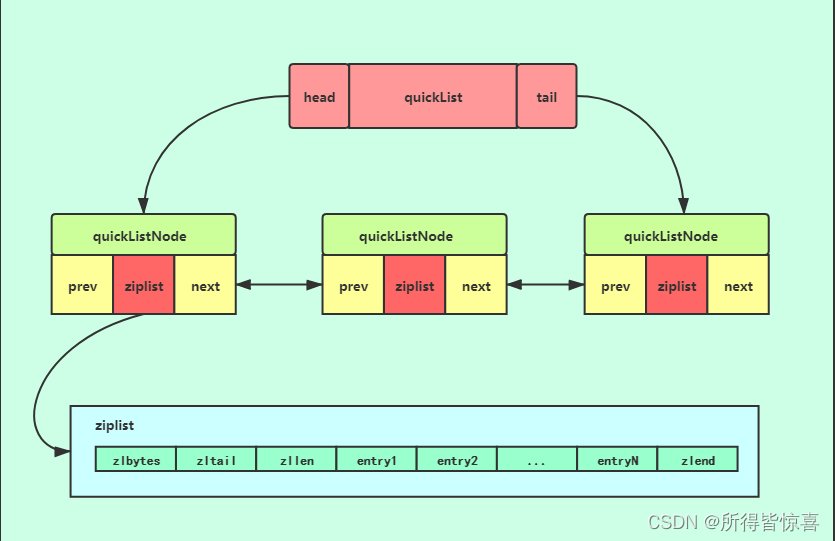
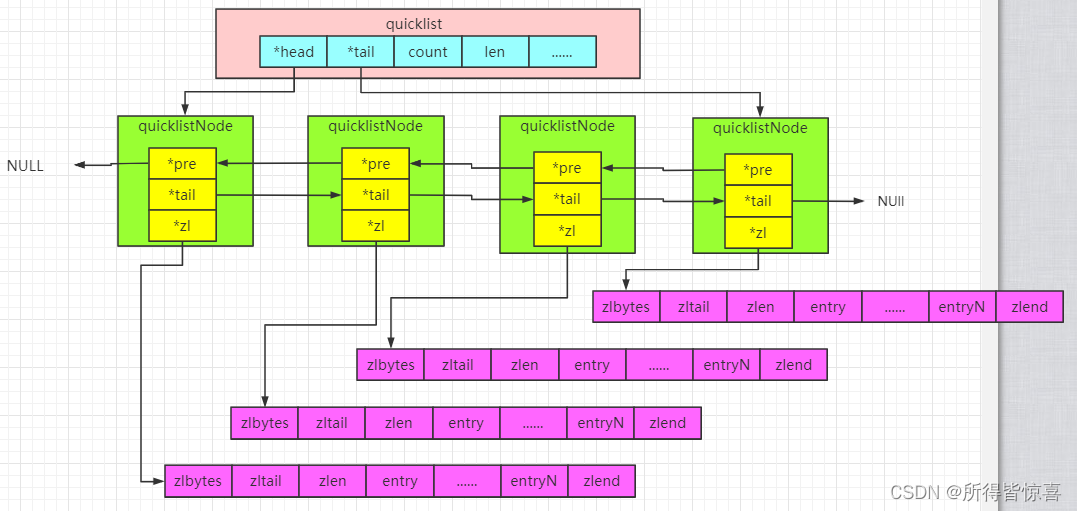
-
⑦. 我们接下来用一段流程图来描述当前的这个结构
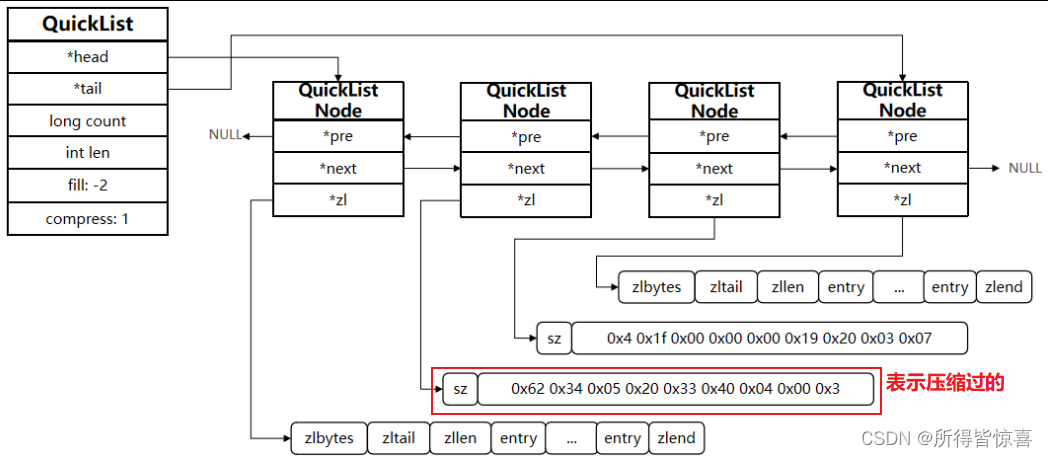
-
⑧. QuickList的特点:
- 是一个节点为ZipList的双端链表
- 节点采用ZipList,解决了传统链表的内存占用问题
- 控制了ZipList大小,解决连续内存空间申请效率问题
- 中间节点可以压缩,进一步节省了内存
③. 跳表 - SkipList
- ①. 跳表是什么?跳表是可以实现二分查找的有序链表
- skiplist是一种以空间换取时间的结构
- 由于链表,无法进行二分查找,因此借鉴数据库索引的思想,提取出链表中关键节点(索引),先在关键节点上查找,再进入下层链表查找。提取多层关键节点,就形成了跳跃表
-
②. 为什么要引入跳表?解决了哪些问题,you see see
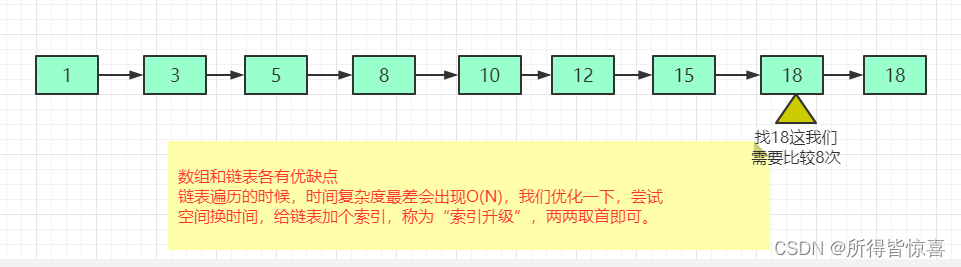
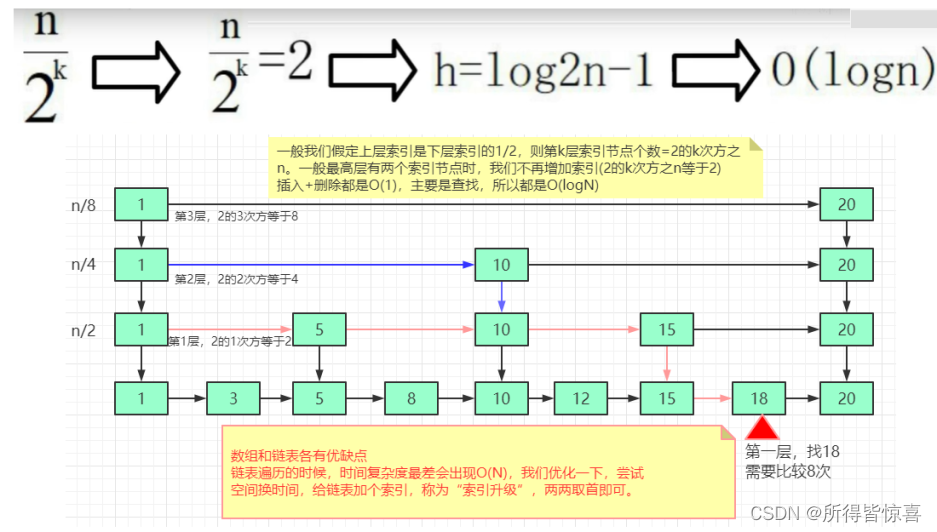
-
③. 简单计算下 - 很重要 - 理解
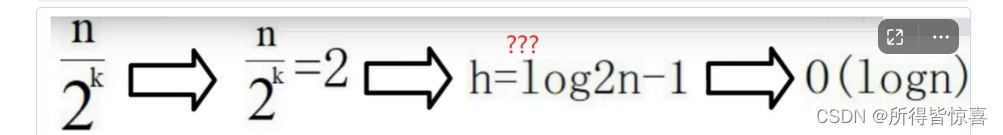
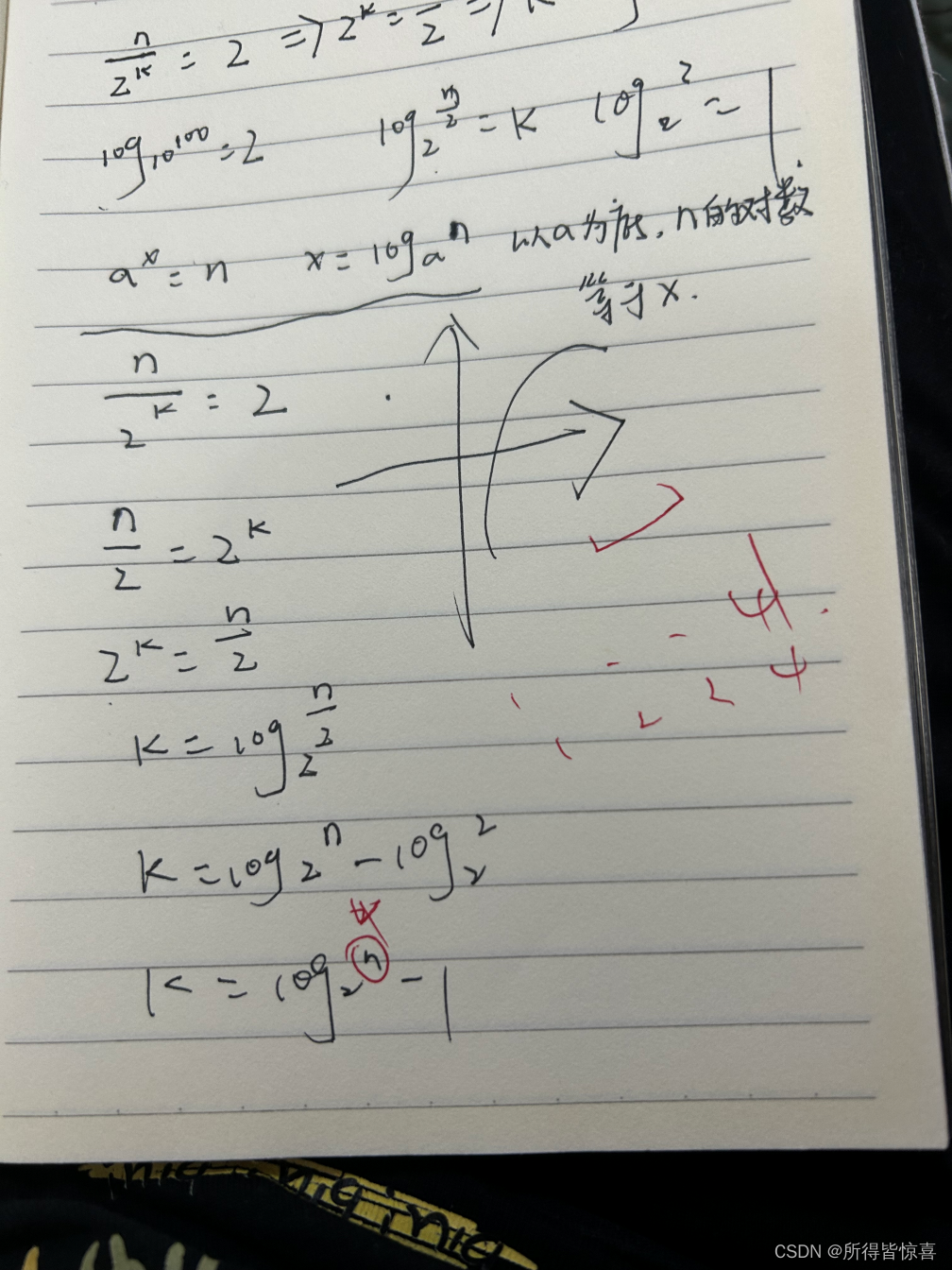
-
④. 最后得出结论: h = log2(N)-1,时间复杂度为O(logN)
-
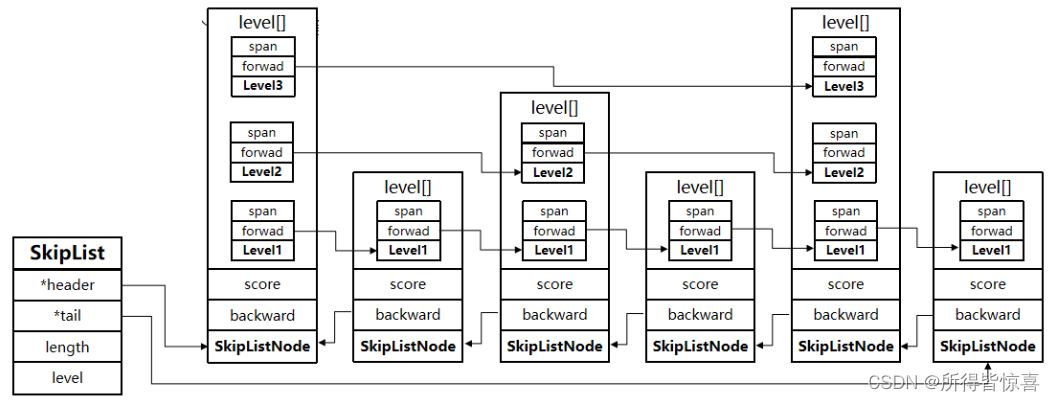
⑤. 源码分析
zskiplist:
header:指向跳跃表中节点的头指针,跳跃表中的节点定义为zskiplistNode,跳跃表实际上也是一个链表,所以会有一个头结点
tail:指向跳跃表中节点的尾指针
length:跳跃表中节点的数量
level:跳跃表的层级
zskiplistNode:
ele:一个sds类型的变量,存储实际的数据
score:存储数据的分值,跳跃表就是按照这个分值进行排序的
backward:一个指向前一个节点的指针,为了便于从后往前查找
zskiplistLevel:一个层级数组,因为跳跃表可以有多层,每一层中都有一个指向当前层级中的下一个节点的指针forward和span跨度,跨度代表了当前层级里面,当前节点与下一个节点直接跨越了几个节点
// 跳跃表
typedef struct zskiplist {
// 指向跳跃表的头尾指针
struct zskiplistNode *header, *tail;
// 长度
unsigned long length;
// 层级
int level;
} zskiplist;
//跳跃表中的节点结构定义
typedef struct zskiplistNode {
// 存储的元素
sds ele;
// 分值
double score;
// 后向指针,指向当前节点的前一个节点
struct zskiplistNode *backward;
// 层级数组
struct zskiplistLevel {
// 指向当前层级中的下一个节点
struct zskiplistNode *forward;
// 跨度
unsigned long span;
} level[];
} zskiplistNode;
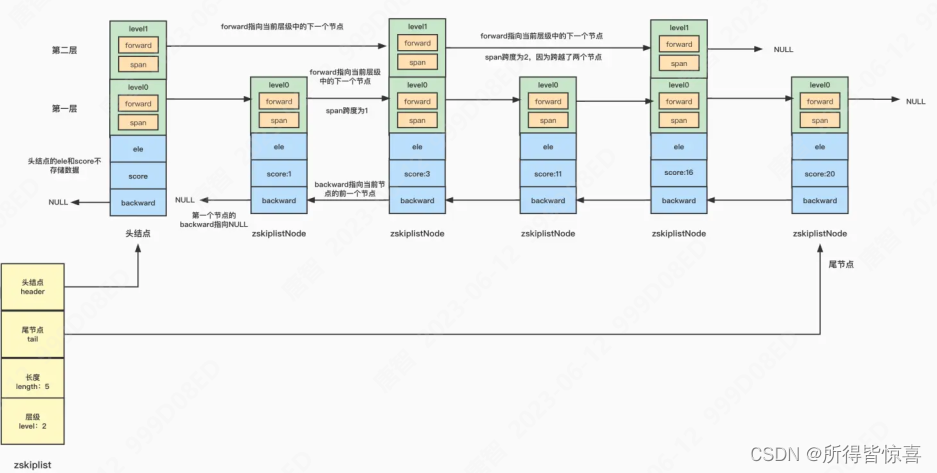
- ⑥. SkipList的特点:
- 跳跃表是一个双向链表,每个节点都包含score(分数)和ele(内容)值
- 节点按照score值排序,score值一样则按照ele字典排序
- 每个节点都可以包含多层指针,层数是1到32之间的随机数
- 不同层指针到下一个节点的跨度不同,层级越高,跨度越大