Ziplist 是由一系列特殊编码的内存块构成的列表, 一个 ziplist 可以包含多个节点(entry), 每个节点可以保存一个长度受限的字符数组(不以 \0 结尾的 char 数组)或者整数, 包括:
字符数组
- 长度小于等于 63 (26−1)字节的字符数组
- 长度小于等于 16383 (214−1) 字节的字符数组
- 长度小于等于 4294967295 (232−1)字节的字符数组
整数
- 4 位长,介于 0 至 12 之间的无符号整数
- 1 字节长,有符号整数
- 3 字节长,有符号整数
- int16_t 类型整数
- int32_t 类型整数
- int64_t 类型整数
构成
area |<---- ziplist header ---->|<----------- entries ------------->|<-end->|
size 4 bytes 4 bytes 2 bytes ? ? ? ? 1 byte
+---------+--------+-------+--------+--------+--------+--------+-------+
component | zlbytes | zltail | zllen | entry1 | entry2 | ... | entryN | zlend |
+---------+--------+-------+--------+--------+--------+--------+-------+
^ ^ ^
address | | |
ZIPLIST_ENTRY_HEAD | ZIPLIST_ENTRY_END
|
ZIPLIST_ENTRY_TAIL
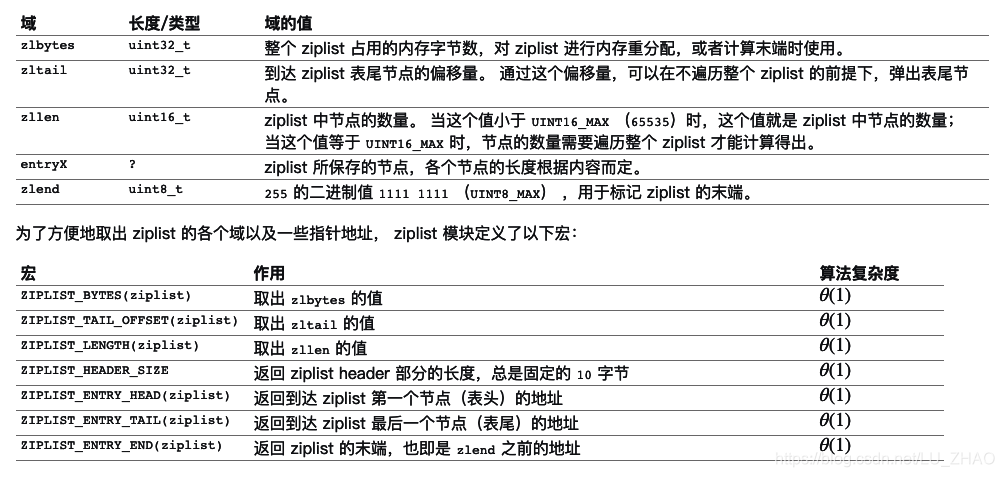
以下是用于操作 ziplist 的函数:
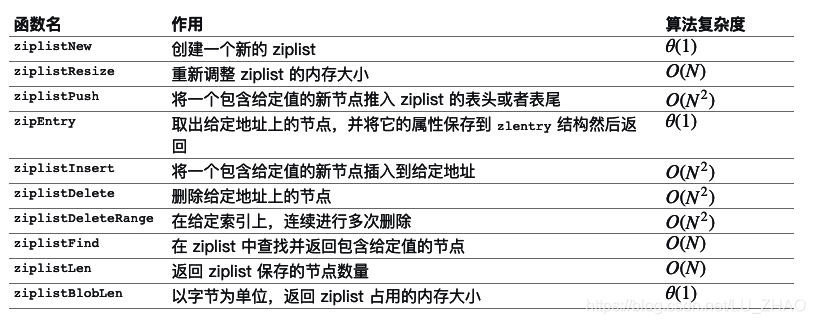
节点的构成
area |<------------------- entry -------------------->|
+------------------+----------+--------+---------+
component | pre_entry_length | encoding | length | content |
+------------------+----------+--------+---------+
pre_entry_length 记录了前一个节点的长度,通过这个值,可以进行指针计算,从而跳转到上一个节点。
根据编码方式的不同, pre_entry_length 域可能占用 1 字节或者 5 字节:
- 1 字节:如果前一节点的长度小于 254 字节,便使用一个字节保存它的值。
- 5 字节:如果前一节点的长度大于等于 254 字节,那么将第 1 个字节的值设为 254 ,然后用接下来的 4 个字节保存实际长度。
encoding 和 length
encoding 和 length 两部分一起决定了 content 部分所保存的数据的类型(以及长度)。
其中, encoding 域的长度为两个 bit , 它的值可以是 00 、 01 、 10 和 11 :
00 、 01 和 10 表示 content 部分保存着字符数组。
11 表示 content 部分保存着整数。
以 00 、 01 和 10 开头的字符数组的编码方式如下:


content 部分保存着节点的内容,类型和长度由 encoding 和 length 决定。
以下是一个保存着字符数组 hello world 的节点的例子:
area |<---------------------- entry ----------------------->|
size ? 2 bit 6 bit 11 byte
+------------------+----------+--------+---------------+
component | pre_entry_length | encoding | length | content |
| | | | |
value | ? | 00 | 001011 | hello world |
+------------------+----------+--------+---------------+
encoding 域的值 00 表示节点保存着一个长度小于等于 63 字节的字符数组, length 域给出了这个字符数组的准确长度 —— 11 字节(的二进制 001011), content 则保存着字符数组值 hello world 本身(为了方便表示, content 部分使用字符而不是二进制表示)。
以下是另一个节点,它保存着整数 10086 :
area |<---------------------- entry ----------------------->|
size ? 2 bit 6 bit 2 bytes
+------------------+----------+--------+---------------+
component | pre_entry_length | encoding | length | content |
| | | | |
value | ? | 11 | 000000 | 10086 |
+------------------+----------+--------+---------------+
encoding 域的值 11 表示节点保存的是一个整数; 而 length 域的值 000000 表示这个节点的值的类型为 int16_t ; 最后, content 保存着整数值 10086 本身(为了方便表示, content 部分用十进制而不是二进制表示)。
创建新 ziplist
area |<---- ziplist header ---->|<-- end -->|
size 4 bytes 4 bytes 2 bytes 1 byte
+---------+--------+-------+-----------+
component | zlbytes | zltail | zllen | zlend |
| | | | |
value | 1011 | 1010 | 0 | 1111 1111 |
+---------+--------+-------+-----------+
^
|
ZIPLIST_ENTRY_HEAD
&
address ZIPLIST_ENTRY_TAIL
&
ZIPLIST_ENTRY_END
将节点添加到末端
将新节点添加到 ziplist 的末端需要执行以下三个步骤:
- 记录到达 ziplist 末端所需的偏移量(因为之后的内存重分配可能会改变 ziplist 的地址,因此记录偏移量而不是保存指针)
- 根据新节点要保存的值,计算出编码这个值所需的空间大小,以及编码它前一个节点的长度所需的空间大小,然后对 ziplist 进行内存重分配。
- 设置新节点的各项属性: pre_entry_length 、 encoding 、 length 和 content 。
- 更新 ziplist 的各项属性,比如记录空间占用的 zlbytes ,到达表尾节点的偏移量 zltail ,以及记录节点数量的 zllen 。
将节点添加到某个/某些节点的前面
现在,新的 new 节点取代原来的 prev 节点, 成为了 next 节点的新前驱节点, 不过, 因为这时 next 节点的 pre_entry_length 域编码的仍然是 prev 节点的长度, 所以程序需要将 new 节点的长度编码进 next 节点的 pre_entry_length 域里, 这里会出现三种可能:
- next 的 pre_entry_length 域的长度正好能够编码 new 的长度(都是 1 字节或者都是 5 字节)
- next 的 pre_entry_length 只有 1 字节长,但编码 new 的长度需要 5 字节
- next 的 pre_entry_length 有 5 字节长,但编码 new 的长度只需要 1 字节
对于情况 1 和 3 , 程序直接更新 next 的 pre_entry_length 域。
如果是第二种情况, 那么程序必须对 ziplist 进行内存重分配, 从而扩展 next 的空间。 然而,因为 next 的空间长度改变了, 所以程序又必须检查 next 的后继节点 —— next+1 , 看它的 pre_entry_length 能否编码 next 的新长度, 如果不能的话,程序又需要继续对 next+1 进行扩容。。。
这就是说, 在某个/某些节点的前面添加新节点之后, 程序必须沿着路径挨个检查后续的节点,是否满足新长度的编码要求, 直到遇到一个能满足要求的节点(如果有一个能满足,则这个节点之后的其他节点也满足), 或者到达 ziplist 的末端 zlend 为止, 这种检查操作的复杂度为 O(N2) 。
不过,因为只有在新添加节点的后面有连续多个长度接近 254 的节点时, 这种连锁更新才会发生, 所以可以普遍地认为, 这种连锁更新发生的概率非常小, 在一般情况下, 将添加操作看成是 O(N) 复杂度也是可以的。
删除节点
删除节点和添加操作的步骤类似,删除操作也可能会引起连锁更新。
