Ziplist 是由一系列特殊编码的内存块构成的列表, 哈希键、列表键和有序集合键初始化的底层实现皆采用 ziplist。学习ziplist结构意义重大,本篇试着剖析ziplist的结构。
本着学习的目的,快速掌握重点,这里放弃实现ziplist所有编码结构,以短字符串(长度<=63)编码为例来说明ziplist的结构。
一个典型的ziplist结构分布如下:
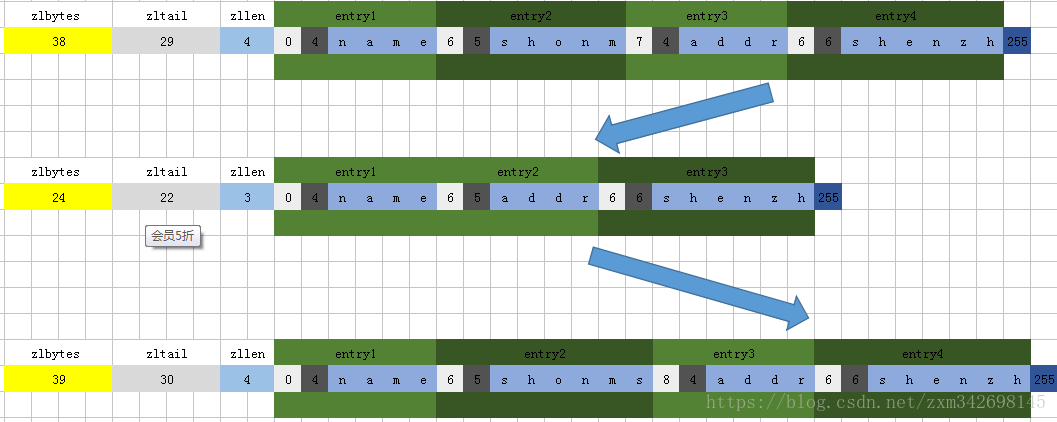
area |<---- ziplist header ---->|<----------- entries ------------->|<-end->| size 4 bytes 4 bytes 2 bytes ? ? ? ? 1 byte +---------+--------+-------+--------+--------+--------+--------+-------+ component | zlbytes | zltail | zllen | entry1 | entry2 | ... | entryN | zlend | +---------+--------+-------+--------+--------+--------+--------+-------+ ^ ^ ^ address | | | ZIPLIST_ENTRY_HEAD | ZIPLIST_ENTRY_END | ZIPLIST_ENTRY_TAIL以两组数据(name,shonm),(addr,shenzh)为例,下面是数据示意图:

可以看到数据与数据之间是紧密相连的,field后面是value。而且feild和value是经一次命令加入进来的。
每个表节点entry由previous_entry_length 、 encoding 、 content 三个部分组成:

节点的 previous_entry_length 属性以字节为单位, 记录了压缩列表中前一个节点的长度。对于简单字符串这个值得长度为1字节。
节点的 encoding 属性记录了节点的 content 属性所保存数据的类型以及长度。对于简单字符串,该属性占一个字节。其中高2bit为0,表示长度小于63字节的字符串,后6字节表示字符串长度,所以字符串长度最多为1<<6。
节点的 content 属性负责保存节点的值, 节点值可以是一个字节数组或者整数,这里只考虑是字节数组。 值的类型和长度由节点的 encoding 属性决定。
数据的添加可以在头或尾添加,其中在尾部添加实现较为简单,复杂读也更低。因为数据结构中有指向最后一个entry的指针,计算该entry的长度len,然后往后偏移len个字节。再扩容要写的数据即可。
对已有field再次设置value时会修改field对应的value值,他的实现为,删除field后面对应的value entry的空间,然后再在该field entry后面插入新的value entry。删除entry空间的具体实现为,把后面的数据整体向前移动,然后减小空间。插入数据的具体实现为,先扩充所需的空间大小,然后整体移动后面的数据往后偏移,示意图为:
下面的代码基本实现了数据的添加和删除:
https://github.com/shonm520/test_redis
// test_ziplist.cpp : 定义控制台应用程序的入口点。
//
#include "stdafx.h"
#include <stdlib.h>
#include <string.h>
#include <assert.h>
#define ZIP_END 255
#define ZIPLIST_HEAD 0
#define ZIPLIST_TAIL 1
#define ZIP_BIGLEN 254
#define ZIP_STR_06B (0 << 6)
#define ZIP_STR_MASK 0xc0
#define uchar unsigned char
#pragma pack(1)
struct ZipList {
unsigned int zlbytes;
unsigned int zltail;
unsigned short zllen;
uchar* getEntryHead() {
return (uchar*)(this + 1);
}
uchar* getEntryEnd() {
return (uchar*)((uchar*)(this) + zlbytes - 1);
}
};
#pragma pack()
typedef struct zlentry {
unsigned int prevrawlensize, prevrawlen;
unsigned int lensize, len;
unsigned int headersize; /* 当前节点 header 的大小, 等于 prevrawlensize + lensize */
unsigned char encoding;
unsigned char *p;
} zlentry;
ZipList *ziplistNew(void);
ZipList *ziplistPush(ZipList* zl, unsigned char *s, unsigned int slen, int where);
unsigned char *ziplistIndex(ZipList* zl, int index);
unsigned char *ziplistNext(ZipList* zl, unsigned char *p);
unsigned char *ziplistPrev(uchar *zl, uchar *p);
unsigned int ziplistGet(uchar *p, uchar **sval, unsigned int *slen, long long *lval);
ZipList *ziplistInsert(ZipList*zl, uchar *p, uchar *s, unsigned int slen);
ZipList *ziplistDelete(ZipList *zl, uchar **p);
uchar *ziplistDeleteRange(uchar *zl, unsigned int index, unsigned int num);
unsigned int ziplistCompare(uchar *p, uchar *s, unsigned int slen);
uchar *ziplistFind(uchar *p, uchar *vstr, unsigned int vlen, unsigned int skip);
unsigned int ziplistLen(uchar *zl);
int zipPrevEncodeLength(uchar*, int len);
int zipEncodeLength(uchar*, int encoding, int len);
uchar *ziplistResize(uchar *zl, unsigned int len);
unsigned int zipRawEntryLength(uchar *p);
ZipList *__ziplistDelete(ZipList *zl, uchar *p, unsigned int num);
ZipList* __ziplistInsert(ZipList* zl, uchar* p, uchar* s, unsigned int slen);
int zipPrevLenByteDiff(uchar *p, unsigned int len);
ZipList *__ziplistCascadeUpdate(ZipList* zl, uchar* p);
void zipPrevEncodeLengthForceLarge(uchar*p, unsigned int len);
zlentry zipEntry(uchar* p);
uchar* ptrMoveOffset(void* ptr, int offset) {
return (uchar*)ptr + offset;
}
int getOffsetPtr(void* p1, void* p2) {
return (uchar*)p1 - (uchar*)p2;
}
ZipList* ziplistNew() {
unsigned int bytes = sizeof(ZipList)+1;
ZipList* zlist = (ZipList*)malloc(bytes);
zlist->zlbytes = bytes;
zlist->zltail = sizeof(ZipList);
zlist->zllen = 0;
*(uchar*)(zlist + 1) = ZIP_END;
return zlist;
}
int hashTypeSet(ZipList* zlist, char* field, char* value) {
int updata = 0;
uchar* fptr = ziplistIndex(zlist, 0);
if (fptr != NULL) {
fptr = ziplistFind(fptr, (uchar*)field, strlen(field), 1);
if (fptr != NULL) {
uchar* vptr = ziplistNext(zlist, fptr); // 定位到域的值
assert(vptr != NULL);
updata = 1;
zlist = ziplistDelete(zlist, &vptr); // 删除旧的键值对
zlist = ziplistInsert(zlist, vptr, (uchar*)value, strlen(value)); //在删除的地方上添加value
}
}
if (!updata) {
zlist = ziplistPush(zlist, (uchar*)field, strlen(field), 1);
ziplistPush(zlist, (uchar*)value, strlen(value), 1);
}
return updata;
}
ZipList *ziplistInsert(ZipList *zl, uchar *p, uchar *s, unsigned int slen) {
return __ziplistInsert(zl, p, s, slen);
}
ZipList* __ziplistInsert(ZipList* zl, uchar* p, uchar* s, unsigned int slen) {
int curLen = zl->zlbytes;
int encoding = 0;
int prevLen = 0;
if (p[0] != ZIP_END) {
zlentry entry = zipEntry(p);
prevLen = entry.prevrawlen;
}
else { //从尾部插入
uchar *ptail = (uchar*)zl + zl->zltail;
if (ptail[0] != ZIP_END) {
prevLen = zipRawEntryLength(ptail);
}
}
int reqlen = slen;
reqlen += zipPrevEncodeLength(NULL, prevLen); //计算pre_entry_length的长度
reqlen += zipEncodeLength(NULL, encoding, slen); //计算encoding和length的长度
int nextdiff = (p[0] != ZIP_END) ? zipPrevLenByteDiff(p, reqlen) : 0;
int offset = getOffsetPtr(p, zl); // p - (uchar*)zl;
zl = (ZipList*)ziplistResize((uchar*)zl, zl->zlbytes + reqlen);
p = ptrMoveOffset(zl, offset); // (()uchar*)zl + offset;
if (p[0] != ZIP_END) {
memmove(p + reqlen, p - nextdiff, curLen - offset - 1 + nextdiff);
zipPrevEncodeLength(p + reqlen, reqlen); //把飘移后节点的prevLen置为飘移位移的长度
zl->zltail = zl->zltail + reqlen;
zlentry tail = zipEntry(p + reqlen);
if (p[reqlen + tail.headersize + tail.len] != ZIP_END) {
zl->zltail = zl->zltail + nextdiff;
}
}
else {
zl->zltail = getOffsetPtr(p, zl); // p - (uchar*)zl;
}
//开始写entry
int off = zipPrevEncodeLength(p, prevLen);
p = ptrMoveOffset(p, off);
off = zipEncodeLength(p, encoding, slen);
p = ptrMoveOffset(p, off);
if (encoding == 0) {
memcpy(p, s, slen);
}
zl->zllen = zl->zllen + 1;
return zl;
}
ZipList* ziplistPush(ZipList* zl, uchar* s, unsigned int slen, int where) {
uchar* p = (where == ZIPLIST_HEAD) ? zl->getEntryHead() : zl->getEntryEnd();
return __ziplistInsert(zl, p, s, slen);
}
ZipList *ziplistDelete(ZipList *zl, uchar **p) {
/* 因为 __ziplistDelete 时会对 zl 进行内存重分配
* 而内存充分配可能会改变 zl 的内存地址
* 所以这里需要记录到达 *p 的偏移量
* 这样在删除节点之后就可以通过偏移量来将 *p 还原到正确的位置 */
size_t offset = *p - (uchar*)zl;
zl = __ziplistDelete(zl, *p, 1);
*p = (uchar*)zl + offset;
return zl;
}
ZipList *__ziplistDelete(ZipList *zl, uchar *p, unsigned int num) {
zlentry first = zipEntry(p);
unsigned int deleted = 0;
for (int i = 0; p[0] != ZIP_END && i < num; i++) {
p += zipRawEntryLength(p);
deleted++;
}
unsigned int totlen = p - first.p; /* totlen是所有被删除节点总共占用的内存字节数 */
if (totlen > 0) {
int nextdiff = 0;
if (p[0] != ZIP_END) {
/* 执行到这里,表示删除节点之后仍然有节点存在 */
/* 因为位于被删除范围之后的第一个节点的 header 部分的大小
* 可能容纳不了新的前置节点,所以需要计算新旧前置节点之间的字节数差
* T = O(1) */
nextdiff = zipPrevLenByteDiff(p, first.prevrawlen);
p -= nextdiff; /* 如果有需要的话,将指针 p 后退 nextdiff 字节,为新 header 空出空间 */
zipPrevEncodeLength(p, first.prevrawlen); /* 将 first 的前置节点的长度编码至 p 中 */
zl->zltail = zl->zltail - totlen;
zlentry tail = zipEntry(p);
if (p[tail.headersize + tail.len] != ZIP_END) {
zl->zltail = zl->zltail + nextdiff;
}
memmove(first.p, p, (zl->zlbytes - (p - (uchar*)zl) - 1)); /* 从表尾向表头移动数据,覆盖被删除节点的数据 */
}
else {
zl->zltail = (first.p - (uchar*)zl) - first.prevrawlen;
}
size_t offset = first.p - (uchar*)zl; /* 缩小并更新ziplist的长度 */
zl = (ZipList*)ziplistResize((uchar*)zl, zl->zlbytes - totlen + nextdiff);
zl->zllen -= deleted;
p = (uchar*)zl + offset;
/* 如果 p 所指向的节点的大小已经变更,那么进行级联更新
* 检查 p 之后的所有节点是否符合 ziplist 的编码要求 */
if (nextdiff != 0)
zl = __ziplistCascadeUpdate(zl, p);
}
return zl;
}
ZipList *__ziplistCascadeUpdate(ZipList* zl, uchar* p) {
size_t curlen = zl->zlbytes, rawlen, rawlensize;
size_t offset, noffset, extra;
uchar *np;
zlentry cur, next;
while (p[0] != ZIP_END) {
cur = zipEntry(p);
rawlen = cur.headersize + cur.len;
rawlensize = zipPrevEncodeLength(NULL, rawlen);
if (p[rawlen] == ZIP_END) break;
next = zipEntry(p + rawlen);
if (next.prevrawlen == rawlen) break;
if (next.prevrawlensize < rawlensize) {
offset = p - (uchar*)zl;
extra = rawlensize - next.prevrawlensize;
zl = (ZipList*)ziplistResize((uchar*)zl, curlen + extra);
p = (uchar*)zl + offset;
np = p + rawlen;
noffset = np - (uchar*)zl;
if (((uchar*)zl + zl->zltail) != np) {
zl->zltail = zl->zltail + extra;
}
memmove(np + rawlensize, np + next.prevrawlensize, curlen - noffset - next.prevrawlensize - 1);
zipPrevEncodeLength(np, rawlen);
p += rawlen;
curlen += extra;
}
else {
if (next.prevrawlensize > rawlensize) {
/* 执行到这里,说明 next 节点编码前置节点的 header 空间有 5 字节
* 而编码 rawlen 只需要 1 字节
* 但是程序不会对 next 进行缩小,
* 所以这里只将 rawlen 写入 5 字节的 header 中就算了。
* T = O(1) */
zipPrevEncodeLengthForceLarge(p + rawlen, rawlen);
}
else {
/* 运行到这里,
* 说明 cur 节点的长度正好可以编码到 next 节点的 header 中
* T = O(1) */
zipPrevEncodeLength(p + rawlen, rawlen);
}
/* Stop here, as the raw length of "next" has not changed. */
break;
}
}
return zl;
}
void zipPrevEncodeLengthForceLarge(uchar*p, unsigned int len) {
if (p == NULL) return;
/* 设置5字节的长度标志 */
p[0] = ZIP_BIGLEN;
/* 写入len */
memcpy(p + 1, &len, sizeof(len));
}
int zipPrevLenByteDiff(uchar *p, unsigned int len) {
/* 我来举个例子吧,如果编码前置节点需要5个字节,而编码当前节点需要1个字节,那么返回值是4 */
unsigned int prevlensize;
/* 取出编码原来的前置节点长度所需的字节数 */
prevlensize = (p[0] < ZIP_BIGLEN ? 1 : 5);
/* 计算编码len所需的字节数,然后进行减法操作 */
return zipPrevEncodeLength(NULL, len) - prevlensize;
}
int zipPrevEncodeLength(uchar* p, int len) {
if (p == NULL) {
return 1;
}
else {
p[0] = len;
return 1;
}
}
int zipEncodeLength(uchar* p, int encoding, int rawlen) {
uchar len = 1;
uchar buf[5];
if (encoding == 0) { //字符串
if (rawlen < 0x3f) {
if (!p) return len;
buf[0] = ZIP_STR_06B | rawlen;
}
}
memcpy(p, buf, len);
return len;
}
uchar *ziplistResize(uchar *zl, unsigned int len) {
zl = (uchar*)realloc(zl, len);
((ZipList*)zl)->zlbytes = len;
zl[len - 1] = ZIP_END;
return zl;
}
uchar* ziplistIndex(ZipList* zl, int index) {
uchar* p;
if (index < 0) {
}
else {
p = zl->getEntryHead();
while (p[0] != ZIP_END && index--) {
p += zipRawEntryLength(p);
}
}
return (p[0] == ZIP_END || index > 0) ? NULL : p;
}
int hashTypeGet(ZipList* zl, char* field, uchar** vstr, unsigned int* vlen) {
uchar* fptr = ziplistIndex(zl, 0);
uchar* vptr = NULL;
if (fptr != NULL) {
fptr = ziplistFind(fptr, (uchar*)field, strlen((char*)field), 1);
if (fptr != NULL) {
vptr = ziplistNext(zl, fptr);
}
}
if (vptr != NULL) {
ziplistGet(vptr, vstr, vlen, NULL);
return 0;
}
return -1;
}
uchar *ziplistNext(ZipList* zl, uchar *p) {
if (p[0] == ZIP_END) { /* p 已经指向列表末端 */
return NULL;
}
p += zipRawEntryLength(p); /* 指向后一节点 */
if (p[0] == ZIP_END) {
return NULL;
}
return p;
}
unsigned int zipRawEntryLength(uchar *p) {
zlentry entry = zipEntry(p);
return entry.prevrawlensize + entry.lensize + entry.len;
}
uchar *ziplistFind(uchar *p, uchar *vstr, unsigned int vlen, unsigned int skip) {
int skipcnt = 0;
uchar vencoding = 0;
long long vll = 0;
while (p[0] != ZIP_END) { /* 只要未到达列表末端,就一直迭代 */
zlentry entry = zipEntry(p);
uchar* q = p + entry.headersize;
if (skipcnt == 0) {
if (entry.encoding == 0) {
if (entry.len == vlen && memcmp(q, vstr, vlen) == 0) {
return p;
}
}
skipcnt = skip;
}
else {
skipcnt--;
}
p = q + entry.len; /* 后移指针,指向后置节点 */
}
return NULL; /* 没有找到指定的节点 */
}
unsigned int ziplistGet(uchar *p, uchar **sstr, unsigned int *slen, long long *sval) {
if (p == NULL || p[0] == ZIP_END) return 0;
if (sstr) *sstr = NULL;
zlentry entry = zipEntry(p);
if (entry.encoding == 0) { /* 节点的值为字符串,将字符串长度保存到 *slen ,字符串保存到 *sstr */
if (sstr) {
*slen = entry.len;
*sstr = p + entry.headersize;
}
}
return 1;
}
zlentry zipEntry(uchar* p) {
zlentry e;
e.prevrawlensize = (p[0] < ZIP_BIGLEN ? 1 : 5);
if (e.prevrawlensize == 1) {
e.prevrawlen = p[0];
}
e.encoding = *(p + e.prevrawlensize);
if (e.encoding < ZIP_STR_MASK) {
e.encoding &= ZIP_STR_MASK;
}
if (e.encoding == 0) { //根据编码求len的字节长度和len的值
e.lensize = 1;
e.len = *(p + e.prevrawlensize) & 0x3F;
}
e.headersize = e.prevrawlensize + e.lensize;
e.p = p;
return e;
}
int _tmain(int argc, _TCHAR* argv[])
{
ZipList* zl = ziplistNew();
hashTypeSet(zl, "name", "shonm");
hashTypeSet(zl, "addr", "shenzh");
hashTypeSet(zl, "name", "shonm2");
unsigned int len = 0;
uchar* ret = NULL;
hashTypeGet(zl, "age", &ret, &len);
return 0;
}
参考:
http://redisbook.readthedocs.io/en/latest/compress-datastruct/ziplist.html