ziplist
什么是ziplist?
顾名思义ziplist就是压缩链表, 压缩链表就是为节省内存而生的
因为Redis是基于内存的数据库, 所以读取或者写入的速度很快, 但由于内存资源有限, 所以我们要尽可能的节约内存, 于是Redis官方就创建出了ziplist这一节省内存的结构
ziplist结构
下面我们来看一下ziplist的结构
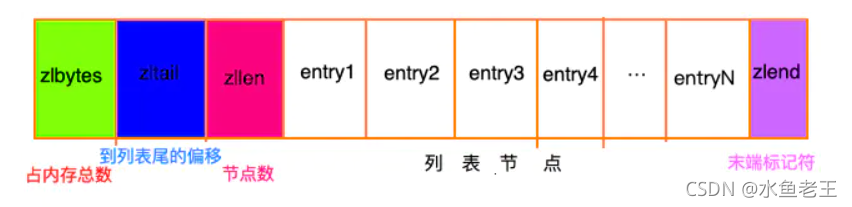
- zlbytes: ziplist的长度(单位: 字节),是一个32位无符号整数
- zltail: ziplist最后一个节点的偏移量,反向遍历ziplist或者pop尾部节点的时候有用。
- zllen: ziplist的节点(entry)个数
- entry : ziplist中间储存的节点
- zlend : 标记ziplist结尾
entry节点的结构
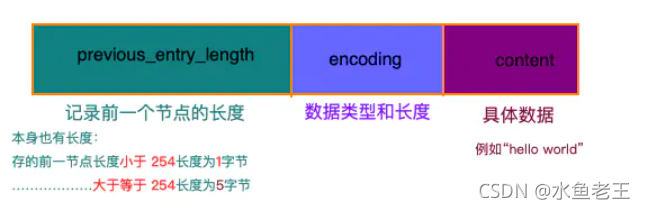
- previous-entry_length : 用来存储上一个节点的长度, 当前以节点的长度小于254字节时, 本身的长度为1字节, 当前一节点的长度大于等于254时,自身长度为5字节
- encoding : 编码 不同类型的编码代表这个节点存储的内容和长度是什么
- content : 内容, 这里就是具体存储数据的地方
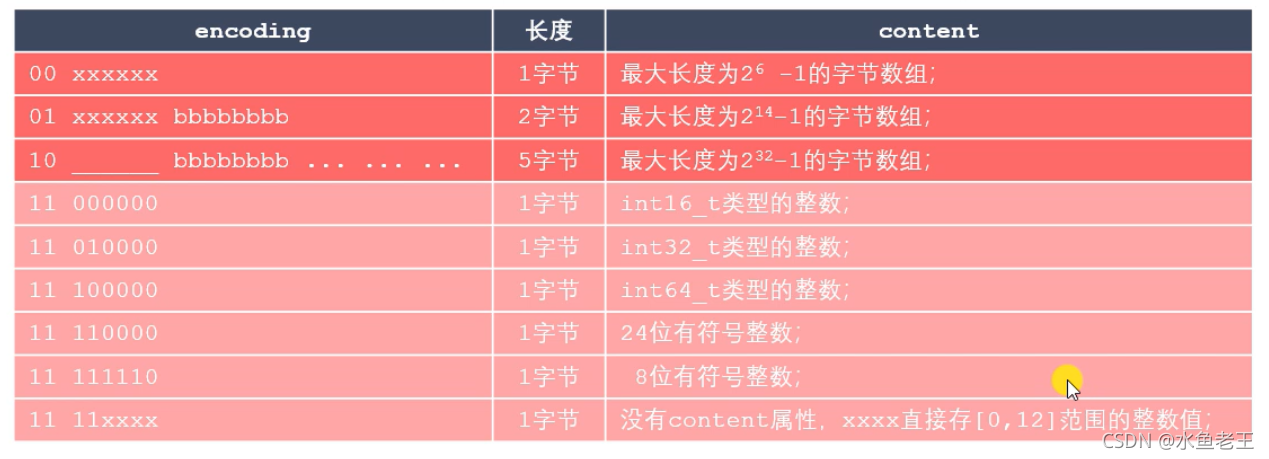
encoding按照下图规则来可以看出来具体content存储的是什么
添加或者删除引起的连锁更新
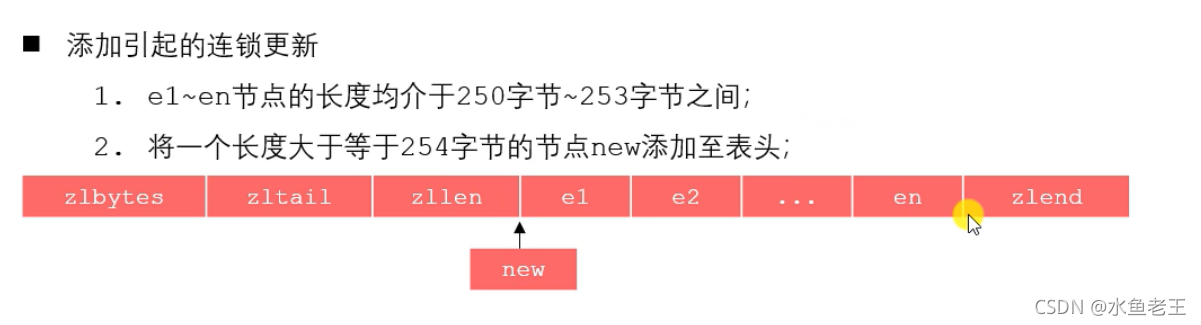
e1~en节点的长度均介于250 ~253之间, 当我在头部新加了一个节点他的长度是254字节, 那么e1就要更新他的previous_entry_length属性, 要把原来1字节更新为5字节, 这样一更新, e2也要更新e1的长度, 这样就引起了连锁反应

当big节点长度大于等于254时, small节点的存储前一节点长度的大小是5字节, 但我们将small节点删除后, e1存储前一个节点的长度就不够了, 这样就需要更新, e1一更新, e2也要更新, 这样就又发送了连锁反应
连锁更新造成的影响:
- 在最坏情况下连锁更新对ziplist执行了N次重新分配
- 每次重新分配需要O(N)的时间, 那么就消耗了O(N^2)的时间
当然连锁更新出现的概率很低, 并且当节点较少时, 出现连锁更新对性能影响不大