可以加快梯度下降求解最优解的速度,减少迭代次数。
可以在一定程度上提高模型的训练效果:将不同数据的特征映射到同一维度上,防止有些数据的特征占主导。
回调函数是人与机器的一种很好的交互方式,可在训练过程中对epoch结果进行判断,而不必等到训练完成再判断。
一些常见的回调函数:
keras.callbacks.EarlyStopping :在监视到训练的质量改变不大时停止训练。常用参数:
monitor:观测质量的指标
min_delta:监测质量指标的最小改变值
patience:设定在几个epoch后观测指标没有改善,就停止训练
keras.callbacks.ModelCheckpoint :在每一个epoch后保存模型,也就是在一个地方保存模型的权重矩阵。常用参数:
filepath:保存模型文件的地址
save_best_only:当它为True时,最近一次最好的模型被保存且不会被其他不好的模型覆盖。
keras.callbacks.TensorBoard :将tensorboard可视化。常用参数:
keras.callbacks.ReduceLROnPlateau :当指标停止改善的时候,改变学习率
monitor:观测质量的指标
factor:改变率,若factor=0.1,则new_l = old_l * 0.1
patience:设定在几个epoch后观测指标没有改善,就改变学习率
在上一篇中,得到初始的训练数据、验证数据、测试数据后,对数据进行归一化处理:
from sklearn. preprocessing import StandardScaler
scaler = StandardScaler( )
x_train_scaled = scaler. fit_transform(
x_train. astype( np. float32) . reshape( - 1 , 1 ) ) . reshape( - 1 , 28 , 28 )
x_valid_scaled = scaler. transform( x_valid. astype( np. float32) . reshape(
- 1 , 1 ) ) . reshape( - 1 , 28 , 28 )
x_test_scaled = scaler. transform( x_test. astype( np. float32) . reshape(
- 1 , 1 ) ) . reshape( - 1 , 28 , 28 )
model = keras. models. Sequential( )
model. add( keras. layers. Flatten( input_shape= [ 28 , 28 ] ) )
model. add( keras. layers. Dense( 300 , activation= "relu" ) )
model. add( keras. layers. Dense( 100 , activation= "relu" ) )
model. add( keras. layers. Dense( 10 , activation= "softmax" ) )
model. compile ( loss= "sparse_categorical_crossentropy" ,
optimizer= "adam" ,
metrics= [ "accuracy" ] )
"""
构建模型也可以这样:
model = keras.models.Sequential([
keras.layers.Flatten(input_shape=[28,28]),
keras.layers.Dense(300,activation="relu"),
keras.layers.Dense(300,activation="relu"),
keras.layers.Dense(10,activation="softmax")
])
"""
logdir = os. path. join( "callbacks" )
if not os. path. exists( logdir) :
os. mkdir( logdir)
output_model_file = os. path. join( logdir, "fashion_mnist_model.h5" )
callbacks = [
keras. callbacks. TensorBoard( log_dir= logdir) ,
keras. callbacks. ModelCheckpoint( output_model_file, save_best_only= True ) ,
keras. callbacks. EarlyStopping( patience= 5 , min_delta= 1e - 3 ) ,
]
history = model. fit( x_train_scaled,
y_train,
epochs= 10 ,
validation_data= ( x_valid_scaled, y_valid) ,
callbacks= callbacks)
Train on 55000 samples, validate on 5000 samples
Epoch 1/10
32/55000 [..............................] - ETA: 33:43 - loss: 2.7747 - accuracy: 0.0625WARNING:tensorflow:Method (on_train_batch_end) is slow compared to the batch update (0.107569). Check your callbacks.
55000/55000 [==============================] - 9s 172us/sample - loss: 0.4575 - accuracy: 0.8336 - val_loss: 0.3593 - val_accuracy: 0.8728
Epoch 2/10
55000/55000 [==============================] - 8s 139us/sample - loss: 0.3522 - accuracy: 0.8704 - val_loss: 0.3343 - val_accuracy: 0.8802
Epoch 3/10
55000/55000 [==============================] - 8s 152us/sample - loss: 0.3180 - accuracy: 0.8812 - val_loss: 0.3289 - val_accuracy: 0.8816
Epoch 4/10
55000/55000 [==============================] - 8s 139us/sample - loss: 0.2929 - accuracy: 0.8909 - val_loss: 0.3305 - val_accuracy: 0.8838
Epoch 5/10
55000/55000 [==============================] - 7s 132us/sample - loss: 0.2744 - accuracy: 0.8963 - val_loss: 0.3458 - val_accuracy: 0.8814
Epoch 6/10
55000/55000 [==============================] - 7s 130us/sample - loss: 0.2566 - accuracy: 0.9043 - val_loss: 0.3298 - val_accuracy: 0.8870
Epoch 7/10
55000/55000 [==============================] - 7s 134us/sample - loss: 0.2436 - accuracy: 0.9089 - val_loss: 0.3166 - val_accuracy: 0.8892
Epoch 8/10
55000/55000 [==============================] - 7s 133us/sample - loss: 0.2299 - accuracy: 0.9133 - val_loss: 0.3098 - val_accuracy: 0.8864
Epoch 9/10
55000/55000 [==============================] - 7s 132us/sample - loss: 0.2170 - accuracy: 0.9187 - val_loss: 0.3288 - val_accuracy: 0.8876
Epoch 10/10
55000/55000 [==============================] - 7s 131us/sample - loss: 0.2112 - accuracy: 0.9208 - val_loss: 0.3308 - val_accuracy: 0.8880
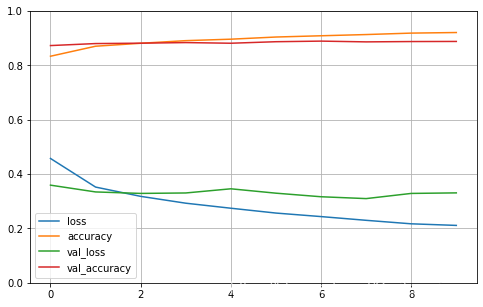
def plot_learning_curves ( history) :
pd. DataFrame( history. history) . plot( figsize= ( 8 , 5 ) )
plt. grid( True )
plt. gca( ) . set_ylim( 0 , 1 )
plt. show( )
plot_learning_curves( history)
model. evaluate( x_test_scaled, y_test, verbose= 2 )
10000/1 - 1s - loss: 0.2266 - accuracy: 0.8798
[0.36443468630313874, 0.8798]