every blog every motto: The unexamined life is not worth living
0. 前言
续上节。实战fashion_mnist数据集,数据归一化。
1. 代码部分
1. 导入模块
import matplotlib as mpl
import matplotlib.pyplot as plt
%matplotlib inline
import numpy as np
import sklearn
import pandas as pd
import os
import sys
import time
import tensorflow as tf
from tensorflow import keras
print(tf.__version__)
print(sys.version_info)
for module in mpl,np,pd,sklearn,tf,keras:
print(module.__name__,module.__version__)

2. 读取数据与查看
2.1 读取数据
fashion_mnist = keras.datasets.fashion_mnist
# print(fashion_mnist)
(x_train_all,y_train_all),(x_test,y_test) = fashion_mnist.load_data()
x_valid,x_train = x_train_all[:5000],x_train_all[5000:]
y_valid,y_train = y_train_all[:5000],y_train_all[5000:]
# 打印格式
print(x_valid.shape,y_valid.shape)
print(x_train.shape,y_train.shape)
print(x_test.shape,y_test.shape)
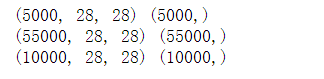
2.1 查看数据最大最小值
print(np.max(x_train),np.min(x_train))

3. 数据归一化与验证
3.1 数据归一化
# 数据归一化
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
# x_train:[None,28,28] -> [None,784]
x_train_scaled = scaler.fit_transform(x_train.astype(np.float32).reshape(-1,1)).reshape(-1,28,28)
x_valid_scaled = scaler.transform(x_valid.astype(np.float32).reshape(-1,1)).reshape(-1,28,28)
x_test_scaled = scaler.transform(x_test.astype(np.float32).reshape(-1,1)).reshape(-1,28,28)
3. 2查看归一化后的最大最小值
print(np.max(x_train_scaled),np.min(x_train_scaled))
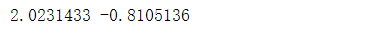
4. 模型搭建
# tf.keras.models.Sequential()
# 构建模型
# 创建对象
"""model = keras.models.Sequential()
model.add(keras.layers.Flatten(input_shape=[28,28]))
model.add(keras.layers.Dense(300,activation='sigmoid'))
model.add(keras.layers.Dense(100,activation='sigmoid'))
model.add(keras.layers.Dense(10,activation='softmax'))"""
# 另一种写法
model = keras.models.Sequential([
keras.layers.Flatten(input_shape=[28,28]),
keras.layers.Dense(300,activation='sigmoid'),
keras.layers.Dense(100,activation='sigmoid'),
keras.layers.Dense(10,activation='softmax')
])
#
model.compile(loss='sparse_categorical_crossentropy',optimizer='sgd',metrics=['accuracy'])
5. 开始训练
# 开始训练
history = model.fit(x_train_scaled,y_train,epochs=10,validation_data=(x_valid_scaled,y_valid))
6. 结果展示
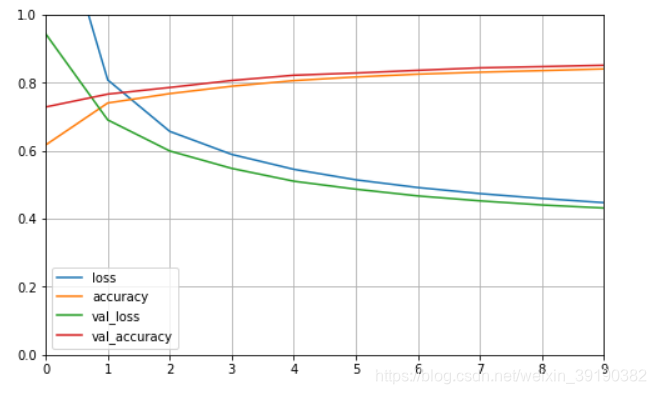
# 画图
def plot_learning_curves(history):
pd.DataFrame(history.history).plot(figsize=(8,5))
plt.grid(True)
plt.gca().set_ylim(0,1)
plt.show()
plot_learning_curves(history)
7. 测试集上
model.evaluate(x_test_scaled,y_test)