激活函数
在普通的DNN中,如果不使用激活函数,相当于激活函数是f(x) = x。无论有多少隐藏层,输出的都是输入的线性组合,只能运用于线性分类。与没有隐藏层的效果相当,这就是原始的感知机。所以引入了非线性激活函数,增加神经网络的非线性。
常见激活函数:
(1)sigmoid函数

在逻辑回归中使用的激活函数,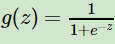 。
。
它的优点在于求导方便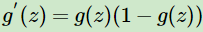 。
。
但是有三大缺点:
1、容易出现gradient vanishing:可以看到sigmoid在很大或者很小的情况下梯度趋近于0。而神经网络的反向传播过程是一个链式法则,是当前层的导数是之前各层导数的乘积,结果可能会很接近0。同时,sigmoid的导数最大值为0.25,这可能在反向传播层数较多的情况下被压缩为极小的数值,这也导致模型收敛过慢。
2、不是zero-centered:导致输入下一层神经元的数值全为正。
 由于
由于![]() ,
,![]() 的符号取决于
的符号取决于![]() 的符号,这导致ω的梯度始终为正或者负,意味着ω一直朝着某个方向变化,这就是一个之字形(zig-zag)的更新走势,这导致收敛过程非常缓慢。比如ω1的梯度一直为正,ω2的梯度一直为负:
的符号,这导致ω的梯度始终为正或者负,意味着ω一直朝着某个方向变化,这就是一个之字形(zig-zag)的更新走势,这导致收敛过程非常缓慢。比如ω1的梯度一直为正,ω2的梯度一直为负:
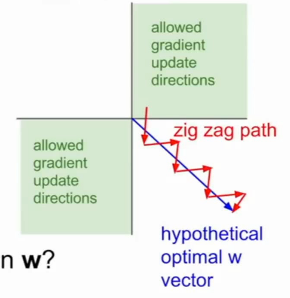
3、幂运算相对耗时
(2)tanh函数


解决了zero-centered的问题,但是梯度消失和幂运算的问题仍然存在。
(3)ReLU函数

ReLU虽然在正区间和负区间都是线性,但是它整体不是线性的,因为不是一条直线。这就使它拥有了非线性的特性,效果类似于划分和折叠空间,组合多个就可以任意划分空间。
优点:
1、在正区间解决了梯度消失的问题。
2、在梯度下降中,收敛远快于sigmoid和tanh。
3、计算速度快
缺点:
1、输出不是zero-centered。
2、Dead Relu问题:假设初始化的一批ω为小方差,均值在+0.1附近。若设置了一个较大的学习率,导致这批ω的分布发送了变化,假设变为了一个小方差,均值在-0.1附近的高斯分布。这可能导致下一次训练时大部分RELU的输入为负值,输出为0。这时候无法通过反向传播得到一个梯度,通过随机梯度下降无法更新参数,RELU被“关闭”,参数再也无法得到更新。死区问题发生时某个参数在整个数据集上都陷入了负半区,避免的方式是让正负尽量平衡,而不是全置为正。
(4)Leaky ReLU函数
![]()

为了解决ReLU“关闭”的问题,提出了该激活函数,前半段设为非0。但是实际上并没有完全证明它比ReLU更好。
(5)ELU函数
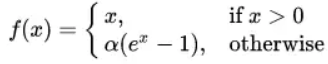

ELU也是为了解决ReLU的问题提出的。它是zero-centered,输出均值接近0。但是由于幂函数的存在可能计算量稍大。类似Leaky ReLU,实际上并没有完全证明它优于ReLU。
小结
训练神经网络使用ReLU时要注意初始化和学习率的设置。可以尝试使用Leaky ReLU和ELU函数,但是不推荐使用tanh和sigmoid。
梯度下降家族 BGD, SGD, MBGD
批量梯度下降法(BGD : Batch Gradient Descent)
梯度下降法的最常见形式,在更新参数时使用所有的样本来进行更新。
比如线性回归的损失函数为
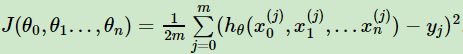
则对θ_i求偏导
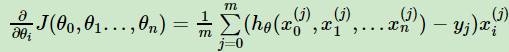
则θ_i的更新表达式为
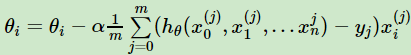
由于有m个样本,这里就用了m个样本的梯度数据。
优点:
- 一次迭代运用了所有样本进行计算,实现了并行。
- 全数据集确定的方向能更好代表样本总体。当目标函数为凸函数时,BGD一定能够得到全局最优。
缺点:
- 当样本数目m很大时,每迭代一步都需要对所有样本进行计算,训练过程会很慢。
随机梯度下降法(SGD : Stochastic Gradient Descent)
没有用所有的m个样本的数据,而是仅仅选取一个样本j来求梯度,对应的更新公式为:
![]()
和批量梯度下降法是两个极端,一个采用所有数据来梯度下降,一个用一个样本来梯度下降。
优点:
- 随机梯度下降法训练速度很快,而批量梯度下降法在样本量很大的时候训练速度不能让人满意。
- 对于准确度来说,随机梯度下降法仅仅用一个样本决定梯度方向,导致解很有可能不是最优。对于收敛速度来说,随机梯度下降法一次迭代一个样本,导致迭代方向变化很大,不能很快的收敛到局部最优解。
小批量梯度下降法(MBGD : Mini-batch Gradient Descent)
前面两种算法的折中,也就是对于m个样本,采用x个样本子集来进行迭代,1<x<m。根据样本的数据可以调整这个x的值,对应的更新公式为:
优点:
- 通过矩阵运算,每次在一个batch上优化参数并不会比单个数据慢太多。
- 每次使用一个batch可以大大减少收敛所需要的迭代次数,同时可以使收敛到的结果更加接近梯度下降的效果。
- 可实现并行化
梯度下降法与牛顿法相比:梯度下降只涉及到一阶导,而牛顿法涉及到二阶导(海森矩阵)。牛顿法/拟牛顿法涉及到二阶的海森矩阵的逆矩阵或伪逆矩阵求解,所以每次迭代的时间更长(计算复杂度更大),不过比梯度下降法更容易收敛(迭代更少次数)。
为什么牛顿法比梯度下降收敛更快?可以理解为梯度下降是找到每一步下降最快的方向,“只顾眼前利益”。而牛顿法是用二次曲面去拟合当前的局部曲面,“看的更远”。所以最后牛顿法收敛更快。
关于梯度爆炸
由于在深层网络或循环网络中,误差梯度可在更新中累积,变成非常大的梯度,然后导致网络权重的大幅更新,并因此使得网络变得不稳定。在极端情况下,权重值的绝对值变得非常大,以至于溢出,导致NaN值。网络层之间的梯度重复相乘导致的指数级增长会产生梯度爆炸。
如何确定是否出现梯度爆炸?
- 训练过程中模型梯度快速变大
- 模型不稳定,导致更新过程中损失出现显著变化
- 训练过程中,模型权重变成NaN
如何修复梯度爆炸问题?
- 重新设计网络模型,通过设计层数更少的网络,使用更小的批尺寸(batch_size)。在循环神经网络中,在更少的先前时间步上进行更新(沿时间的截断反向传播)。
- 使用ReLU激活函数。
- 使用长短期记忆网络。使用长短期记忆单元(LSTM)和相关的门类型神经元结构可以减少梯度爆炸问题。采用LSTM单元数是适合循环神经网络的序列预测的最新最好实践。
- 使用梯度截断。如果使用非常深且批尺寸较大的多层感知器网络和输入序列较长的LSTM中仍有可能出现梯度爆炸,这时可以检查和限制梯度的大小(是否超过阈值,如果超过便将梯度设置为阈值),这就是梯度截断。
- 权重正则化。由于梯度下降会导致权重异常增大,因此可检查网络权重的大小,并惩罚产生较大权重值的损失函数,通常使用的是L1惩罚项(权重绝对值)或L2惩罚项(权重平方)。
Batch size对学习网络的影响
在合理地范围内,增大batch_size的好处:
a. 内存利用率提高了,大矩阵乘法的并行化效率提高。
b. 跑完一次 epoch(全数据集)所需的迭代次数减少,对于相同数据量的处理速度进一步加快。
c. 在一定范围内,一般来说 Batch_Size 越大,其确定的下降方向越准,引起训练震荡越小。
盲目增大batch_size的坏处:
a. 内存利用率提高了,但是内存容量可能撑不住了。
b. 跑完一次 epoch(全数据集)所需的迭代次数减少,要想达到相同的精度,其所花费的时间大大增加了,从而对参数的修正也就显得更加缓慢。
c. Batch_Size 增大到一定程度,其确定的下降方向已经基本不再变化。
